







🌵说说由来
🚚情景再现💨
朋友:“xx,你能帮我爬取一些图片吗?我想用来做图像识别的训练数据”
我:“可以呀,你有数据源吗?”
朋友:“没有……,对了,最好是圆形的图片”
我:“圆形的图片?我刚找了一下,很少有图片是圆形的……”
朋友:“没事,我会PS,到时候我再弄吧”
某年某月某日,有一位做图像识别功能的朋友突然找到了我,想让我爬取多种类型的图片,需要圆形的。圆形⁉️这……,当时我的技术水平还没有那么高,有过想通过代码将下载好的图片批量变为圆形,但是,终究还是停留在“想”的这一层……
重点是,那时的我,对网站不熟悉,找了二十几分钟才发现百度图片上搜索出的图片可按规律爬取😭技术水平不够高,不会使用多线程爬取图片的操作,于是花了一个半小时左右的时间写出一个勉强能爬取图片的代码……
而这个代码每次运行只能下载一种类型的图片……关键是他要的是十几种类型的图片,你能想像每次运行,输入名字,等待几分钟,再重新运行,再输入名字,再等待几分钟……这一次两次没啥,十几次就有点……

后来,将爬取下的图片发给他之后就把那代码丢在一边了……
再后来,良心发……哦!不,突然发现我好像可以将这个代码升级了,这是啥!这是能力!这是自信!这是……

👉总之,它升级了!!!多线程爬取!!!还能变圆!!!
🔈想要知道它变成啥样了,请往下看👇
🌴代码实现
🌼代码功能
功能:用户可输入多种不同种类的图片名称、对应的图片数量、是否将图片变为圆形,代码根据用户输入的内容进行多线程爬取百度图片。
🌼使用模块
- selenium模块:selenium是python的一个第三方库,对外提供的接口可以操控浏览器。本次使用该模块主要是用来控制滚动条进行网页的刷新,更新出更多的图片,再获取图片的跳转链接;
- time模块:网页缓冲的作用;
- requests模块:向图片跳转链接发送请求,获取真正的href(链接)
- lxml模块:主要使用该模块中的etree函数,将html类型转换成element元素;
- os模块:创建文件夹,供图片保存;
- PIL模块:图像处理库,主要将爬取下来的图片剪裁成圆形
- threading模块:利用此模块实现多线程操作。
🌼实现效果

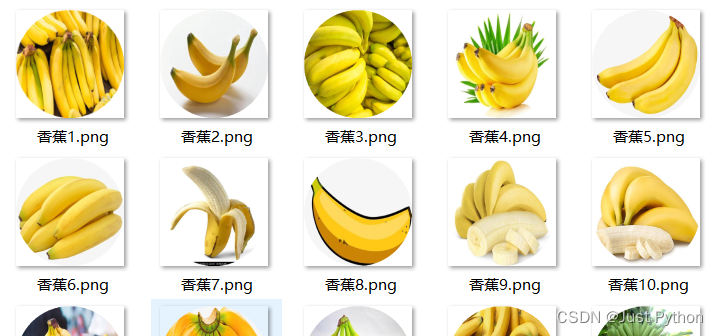

🌼源代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import requests
from lxml import etree
import os
from PIL import Image, ImageFile
import threading
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Baidu_photo(object):
def __init__(self, content, num, choice):
# 获取当前工作目录
self.cwd = os.getcwd()
# 用户输入想查询的内容
self.content = content
self.num = num
self.choice = choice
# 判断文件夹是否存在,不存在则创建
if not os.path.exists(f'{self.cwd}\\图片\\{self.content}'):
os.makedirs(f'{self.cwd}\\图片\\{self.content}')
# 设置无头模式
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# 创建driver对象
self.driver = webdriver.Chrome(options=options)
# 构建请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36'
}
# 调用下载图片的函数
self.user_choose()
self.driver.quit()
# 用户选择下载图片的数量,让网页加载完毕
def user_choose(self):
# 进入网页
self.driver.get('https://image.baidu.com/')
# 定位输入框,并输入内容
self.driver.find_element(By.ID, 'kw').send_keys(self.content)
# 点击搜索
self.driver.find_element(By.XPATH, '//*[@id="homeSearchForm"]/span[2]/input').click()
time.sleep(3)
while True:
# 第一次获取图片链接并比较
self.temp_href = self.driver.find_elements(By.XPATH, '//div[@class="imgpage"]//ul/li/a')
if self.num + 30 <= len(self.temp_href):
# 调用下载图片的函数
self.download_photo()
break
else:
# 循环将滚动条一下拉到底
self.driver.execute_script('document.documentElement.scrollTop=10000')
# sleep让滚动条反应一下
time.sleep(0.5)
def download_photo(self):
num = 0
j = 0
href = []
for i in range(self.num + 30):
href.append(self.temp_href[i].get_attribute('href'))
while num < self.num:
res = requests.get(href[j], headers=self.headers)
html = etree.HTML(res.content.decode())
src = html.xpath('//div[@id="srcPic"]/div/img/@src')
j += 1
if src == []:
continue
num += 1
res_1 = requests.get(src[0], headers=self.headers)
# 11、写入文件
with open(f'{self.cwd}\\图片\\{self.content}\\{self.content}{num}.png', 'wb') as f:
f.write(res_1.content)
if self.choice == '1':
self.photo_to_circular()
print(f'{self.content}的图片保存成功!')
else:
print(f'{self.content}的图片保存成功!')
# 将图片变为圆形
def photo_to_circular(self):
content = self.content
cwd = self.cwd
# 将图片变为矩形
def modify():
# 切换目录
os.chdir(f'{cwd}\\图片\\{content}')
# 遍历目录下所有的文件
for image_name in os.listdir(os.getcwd()):
# 打印图片名字
# print(image_name)
im = Image.open(os.path.join(f'{cwd}\\图片\\{content}', image_name))
# 需要设置rgb 并且将处理过的图片存储在别的变量下
im = im.convert('RGB')
# 重新设置大小(可根据需求转换)
rem = im.resize((320, 320))
# 对处理完的正方形图片进行保存
rem.save(os.path.join(f'{cwd}\\图片\\{content}', image_name))
def circle(img_path, times):
ima = Image.open(img_path).convert("RGBA")
size = ima.size
# 要使用圆形,所以使用刚才处理好的正方形的图片
r2 = min(size[0], size[1])
if size[0] != size[1]:
ima = ima.resize((r2, r2), Image.ANTIALIAS)
# 最后生成圆的半径
r3 = int(r2 / 2)
imb = Image.new('RGBA', (r3 * 2, r3 * 2), (255, 255, 255, 0))
pima = ima.load() # 像素的访问对象
pimb = imb.load()
r = float(r2 / 2) # 圆心横坐标
for i in range(r2):
for j in range(r2):
lx = abs(i - r) # 到圆心距离的横坐标
ly = abs(j - r) # 到圆心距离的纵坐标
l = (pow(lx, 2) + pow(ly, 2)) ** 0.5 # 三角函数 半径
if l < r3:
pimb[i - (r - r3), j - (r - r3)] = pima[i, j]
cir_file_name = times # 修改为自己需要的命名格式
# 输出路径
out_put_path = f'{cwd}\\图片\\{content}'
cir_path = out_put_path + '\\' + cir_file_name
imb.save(cir_path)
return
# 将图片变为正方形
modify()
# 针对需要处理的图片文件夹 进行批量处理,将矩形图片变为圆形
for root, dirs, files in os.walk(f'{cwd}\\图片\\{content}'): # 修改为图片路径
for file in files:
circle(os.path.join(root, file), file)
if __name__ == '__main__':
# 用户输入想查询的内容
content = input('请输入您想下载的图片(多种类下载请用空格隔开,例:马 香蕉)\n:').split(' ')
num = input('请输入下载图片的数量(多种类下载请用空格隔开,顺序应与查询内容一致)\n:').split(' ')
choice = input('是否将下载的图片剪裁为圆形(是输入1,否则输入0)(多种类下载请用空格隔开,顺序应与查询内容一致)\n:').split(' ')
threads = []
for i in range(len(content)):
t = threading.Thread(target=Baidu_photo, args=(content[i], int(num[i]), choice[i],))
threads.append(t)
for t in threads:
t.start()
🌾结束语
如果喜欢这篇文章,或者觉得这篇文章对你有帮助~可以点赞👍 收藏🌈 关注💖哦~~
👉你的支持,就是我更新的强大动力💪
peace~~

















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











