






常见、好用的爬虫框架有Scrapy、XPATH、CSS。具体可以参考以下链接。有哪些常见、好用的爬虫框架?Scrapy、XPATH、CSS框架一文详解 - 知乎 (zhihu.com)bhttps://zhuanlan.zhihu.com/p/384977608
本文主要介绍正则表达式相关知识与利用正则表达式进行爬虫数据采集。
正则表达式相关知识
正则表达式,顾名思义是通过规定规则进行匹配的方式,即完成规则制定、筛选与提取内容。与其他爬虫数据采集方式相比,正则表达式通过程序员制定的规则进行筛选匹配,匹配结果更加全面细致,但也更为复杂。
re.S这个模式下.代表所有符号,* 表示0个或多个,? 表示非贪婪模式(即以最低标准进行匹配),\d 代表数字,+ 代表有一个或多个,相应的\d+代表至少有一个数字,多的不限,\w 代表数字、字母、下划线,也可匹配到中文,\s 匹配空白字符,^ 取反即匹配不符合制定条件的部分。
下面举几个简单的匹配例子:
import re # 正则的包
strs = 'szdghsfl;ghslw363bb [迭代] ##$$¥¥bb 246g 。…… _h253445sfklzg 中文'
demo = re.compile('\d+', re.S)
lists = demo.findall(strs)
print(lists)
# 输出结果:['3', '6', '3', '2', '4', '6', '2', '5', '3', '4', '4', '5']
# 如果把demo的匹配规则'\d+?'改为'\d+'
# 输出结果:['363', '246', '253445'] 在贪婪模式下,会选择最大匹配
demo = re.compile('\w+', re.S)
# \w代表数字 字母下划线 无法匹配到空白字符 但可以匹配到中文
lists = demo.findall(strs)
print(lists)
# 输出结果:['szdghsfl', 'ghslw363bb', '迭代', 'bb', '246g', '_h253445sfklzg', '中文']
demo = re.compile('\s+', re.S)
# \s匹配到空白字符
lists = demo.findall(strs)
print(lists)
# 输出结果:[' ', ' ', ' ', ' ', ' ', ' ']练习1:找出strs里面的特殊字符,即除了数字、字母、下划线以及空格以外的其他字符。
demo = re.compile('[^\w\s]+', re.S)
lists = demo.findall(strs)
print(lists)
# 输出结果:[';', '[', ']', '##$$¥¥', '。……']
demo = re.compile('[^0-9a-zA-Z_\u4e00-\u9fa5\s]+', re.S)
lists = demo.findall(strs)
print(lists)
# 输出结果:[';', '[', ']', '##$$¥¥', '。……']练习2:匹配符合规则的且两个或多个连在一起的。
demo = re.compile('[^\w\s]{2}', re.S) # 匹配两个连在一起的
lists = demo.findall(strs)
print(lists)
# 输出结果:['##', '$$', '¥¥', '。…']
demo = re.compile('[^\w\s]{2,4}', re.S) # 匹配两个到四个连在一起的
lists = demo.findall(strs)
print(lists)
# 输出结果:['##$$', '¥¥', '。……']练习3:根据特殊符号取值。需要用到\进行转译。
demo = re.compile('\[(\w+)\]', re.S) #\转译 取方括号里面的值
lists = demo.findall(strs)
print(lists)
# 输出:['迭代'] 即专门输出方括号中的匹配结果用正则表达式进行爬虫数据采集
本文以爬取顶点小说网站的小说内容为例,使用正则表达式进行爬虫数据采集。
爬取思路描述如下:
1. 分析网页结构
2. 选择想要爬取的小说,记录其书本链接
3. 爬取该小说每章链接
4. 分章节保存小说内容
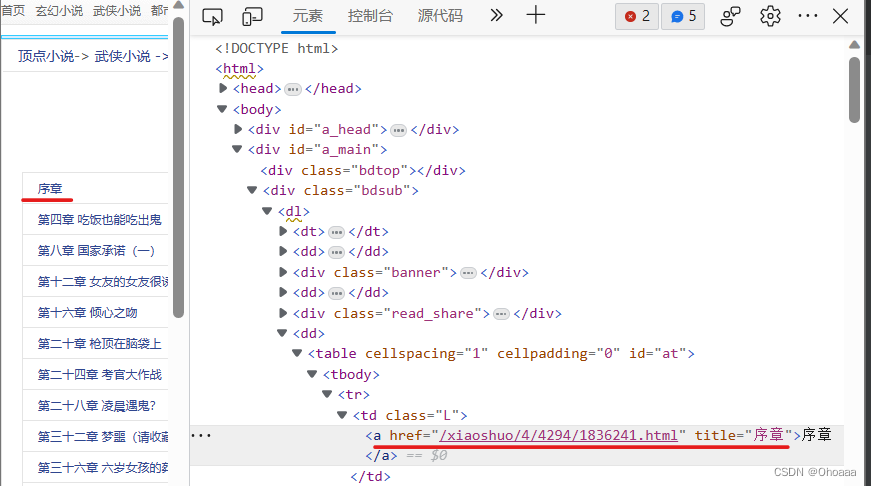
通过分析网页结构,每章的链接为:https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836241.html,可见的H5代码结构中显示的部分为xiaoshuopu.com/xiaoshuo/4/4294/1836241.html。据此,我们可以选择匹配规则为/xiaoshuo/\d+/\d+/\d+\.html。
尝试仅通过以上规则进行爬取。
import re # 正则的包
import requests # 发请求
# 猫魔御女
source = requests.get('https://www.xiaoshuopu.com/xiaoshuo/4/4294/').text
# 构造一个向服务器请求资源的Request对象(Request),并且get方法返回一个包含服务器资源的Response对象;
demo = re.compile('href="(/xiaoshuo/\d+/\d+/\d+\.html)"', re.S) # 制定正则规则
lists = demo.findall(source) # 进行匹配
print(lists)
'''''''''
输出结果:['/xiaoshuo/4/4294/1836241.html', '/xiaoshuo/4/4294/1836250.html', '/xiaoshuo/4/4294/1836259.html', '/xiaoshuo/4/4294/1836267.html', '/xiaoshuo/4/4294/1836273.html', '/xiaoshuo/4/4294/1836281.html', '/xiaoshuo/4/4294/1836289.html', '/xiaoshuo/4/4294/1836297.html', '/xiaoshuo/4/4294/1836305.html', '/xiaoshuo/4/4294/1836309.html', '/xiaoshuo/4/4294/1836316.html', '/xiaoshuo/4/4294/1836323.html',……]
有很多,这边将输出结果截取部分展示
'''''可以看到,输出结果为以列表形式并不是我们想要的每章的链接。此时,我们可以通过map方法将链接进行拼接,代码与输出结果见下。至此,我们完成小说章节链接的抓取。
chapter_link = list(map(lambda x: 'https://www.xiaoshuopu.com{}'.format(x), lists))
print(chapter_link)
'''''''''
输出结果:['https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836241.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836250.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836259.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836267.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836273.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836281.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836289.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836297.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836305.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836309.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836316.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836323.html', 'https://www.xiaoshuopu.com/xiaoshuo/4/4294/1836330.html',……]
只贴过来部分链接
'''''接下来,我们进行小说每章内容的抓取。先进行一个章节内容的爬取(抓取序章) 。一样的,首先分析网页结构。易知,章节题目保存在h1标签内,章节内容都保存在p标签内。匹配章节内容时,由于含有多个p标签,单纯使用p标签进行匹配定位并不够,因此我们加上前面的分支:div id="htmlContent",加强匹配规则。
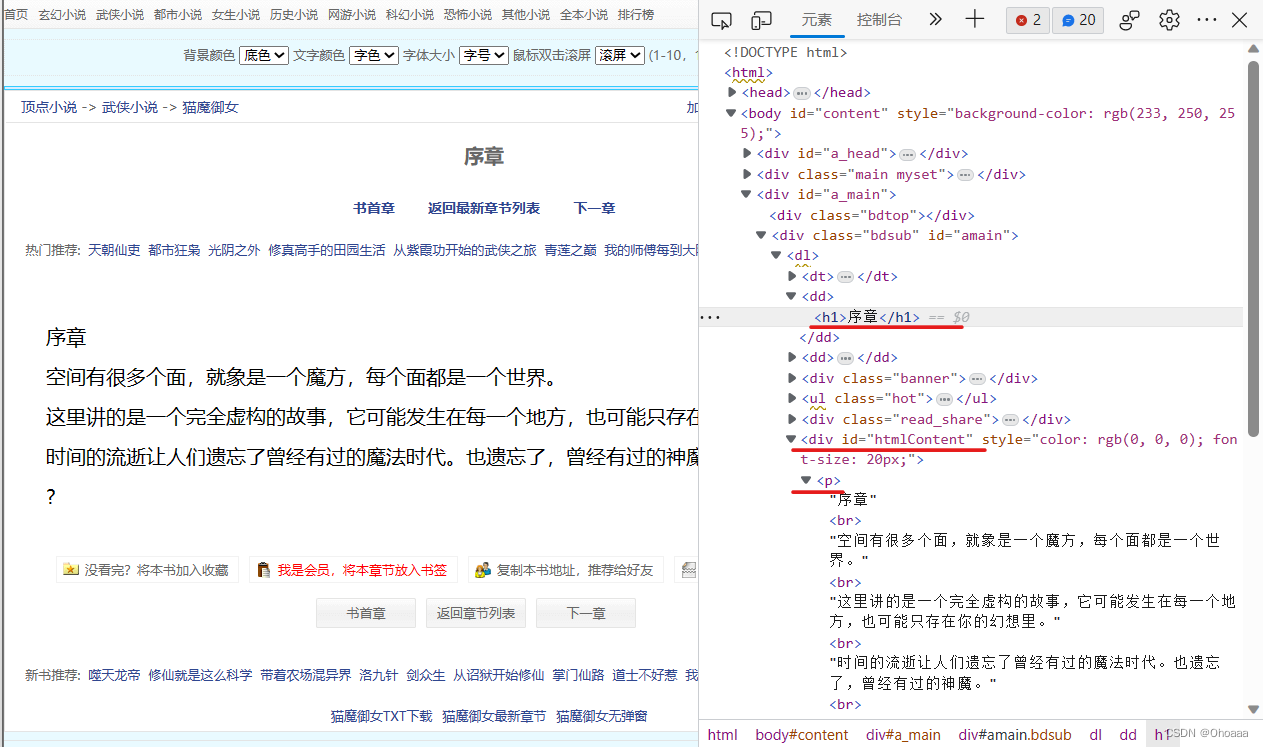
代码与运行结果如下:
chapter_url = chapter_link[0]
source = requests.get(chapter_url).text
demo = re.compile('<h1>(.*?)</h1>.*?<div id="htmlContent"><p>(.*?)</p></div>', re.S)
lists = demo.findall(source)
print('list:', lists)
'''''''''
输出结果: list: [('序章', '序章<br />空间有很多个面,就象是一个魔方,每个面都是一个世界。<br />这里讲的是一个完全虚构的故事,它可能发生在每一个地方,也可能只存在你的幻想里。<br />时间的流逝让人们遗忘了曾经有过的魔法时代。也遗忘了,曾经有过的神魔。<br />?')]
'''''可以看到,输出的列表分为两个部分,一个是标题,一个是内容。其中,内容部分含有<br />(相当于换行符),与文章内容混合在一起,需要进行下一步的处理,即将<br />换为换行符。代码与运行结果如下:
title = lists[0][0]
content = lists[0][1].replace('<br />', '\n') # 替换br 为\n(换行)
print(title)
print(content)
'''''''''
输出结果:
序章
序章
空间有很多个面,就象是一个魔方,每个面都是一个世界。
这里讲的是一个完全虚构的故事,它可能发生在每一个地方,也可能只存在你的幻想里。
时间的流逝让人们遗忘了曾经有过的魔法时代。也遗忘了,曾经有过的神魔。
?
'''''可以看到,与序章章节内容相符,至此,完成小说章节内容的爬取。接下来,我们需要将内容保存在本地。本文选择的保存格式为.txt。具体打开、写入函数的说明,参照下面博客。(65条消息) 【Python】python文件打开方式详解——a、a+、r+、w+、rb、rt区别_兔子爱读书的博客-CSDN博客![]() https://blog.csdn.net/ztf312/article/details/47259805
https://blog.csdn.net/ztf312/article/details/47259805
op = open('猫魔御女'+'.txt', 'a+')
# 权限 a+追加写入 w覆盖写入
op.write(book_title_content)
op.close()保存结果如下:
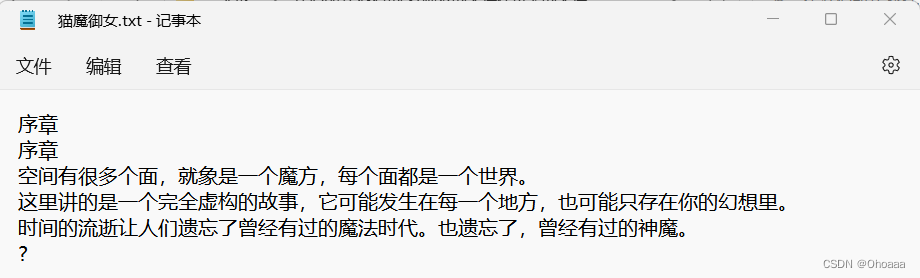
至此,我们已经完成所选小说章节链接的获取与每章内容的保存,接下来,我们只需将之前的操作整合,对章节链接列表进行遍历,循环调用内容获取与内容保存函数即可完成整本小说内容的抓取。由于小说内容较多,我们设置循环控制变量count,限制只抓取前10章内容。
完整代码与保存结果见下:
import re # 正则的包
import requests # 发请求
# 保存文件函数
def save_file(book_title_content, book_name='猫魔御女'): # 我的师傅每到大限才突破
file = open(book_name+'.txt', 'a+')
# 权限 a+追加写入 w覆盖写入
file.write(book_title_content)
file.close()
def details_page(urls):
source = requests.get(urls).text
demo = re.compile('<h1>(.*?)</h1>.*?<div id="htmlContent"><p>(.*?)</p></div>', re.S)
lists = demo.findall(source)
title = lists[0][0]
content = lists[0][1].replace('<br />', '\n') # 替换<br /> 为\n(换行)
title_content = title + '\n' + content + '\n\n'
print('正在抓取{}章节内容'.format(title))
save_file(title_content)
if __name__=='__main__':
# 猫魔御女
# https://www.xiaoshuopu.com/xiaoshuo/4/4294/
source = requests.get('https://www.xiaoshuopu.com/xiaoshuo/4/4294/').text
# 构造一个向服务器请求资源的Request对象(Request),并且get方法返回一个包含服务器资源的Response对象;
demo = re.compile('href="(/xiaoshuo/\d+/\d+/\d+\.html)"', re.S) # 制定正则规则
lists = demo.findall(source) # 进行匹配
# print(lists)
chapter_link = list(map(lambda x: 'https://www.xiaoshuopu.com{}'.format(x), lists))
count = 0 # 循环控制变量,控制获取前10章内容
for urls in chapter_link:
if count < 10:
details_page(urls)
count = count+1输出结果:(请不要在意一些有的没的路径细节)

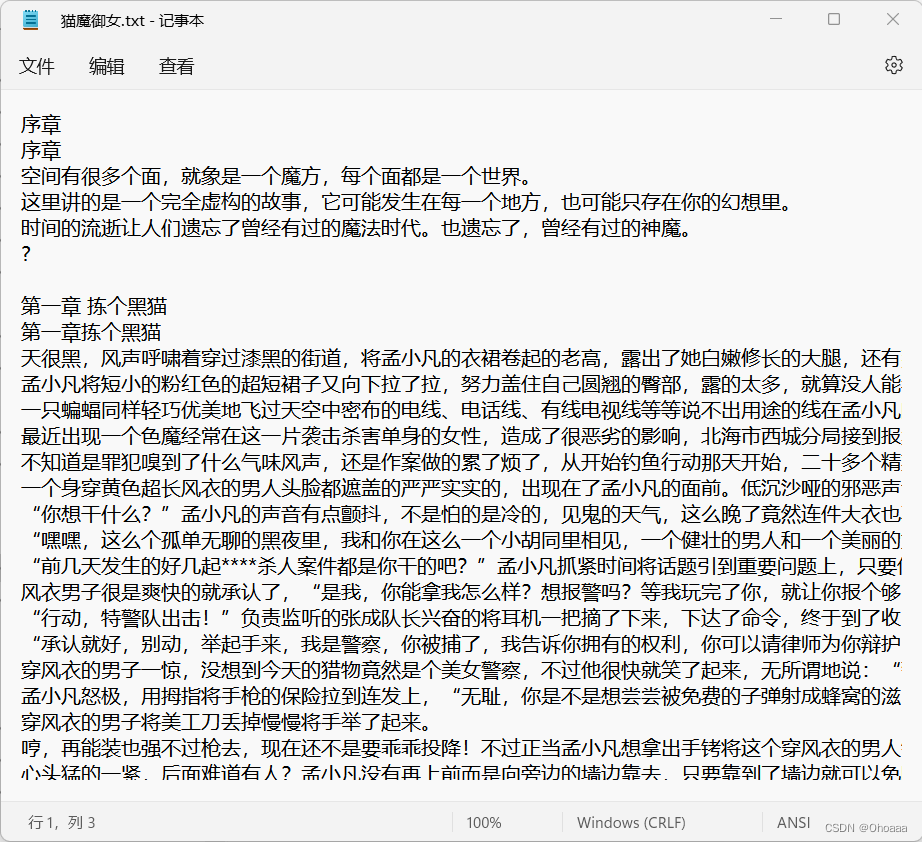
至此,完成本次抓取。
需要一点一点调试代码内容,一个模块的功能实现可以通过实例进行调整,之后封装成函数进行调用,使整个过程更加明确,思路更加清晰。















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









