







决策树算法:
这里主要讲的是决策树分类,该算法主要从以下三个方面入手:
- 特征选择
- 决策树生成
- 剪枝
特征选择
特征选择就是通过比较属性,决定是否根据该属性分支:

有些属性对于判断结果影响不大,这样的属性就尽量不使用,而如何决定哪些属性合适,就有以下几种常见算法:
- 信息增益(Information Gain)
- 信息增益率(Information Gain Ratio)
- 基尼系数(Gini Index)
举例说明
这里主要以信息增益为例。
理论基础:
信息增益公式:
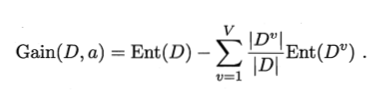
公式看不懂没关系,会计算使用就行。要使用信息增益,首先要了解熵,熵是表示一种不确定性,熵 (entropy) 的计算:
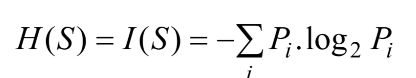
通过计算熵,从而获得信息增益(Information Gain),可判断是否通过某个属性划分子树。熵越大,数据集的纯度(purity)越小。
实际例子计算
首先还是从实际数据举例:

所有数据的entropy:


接下来使用第一个属性outlook作为分割数据的标准:
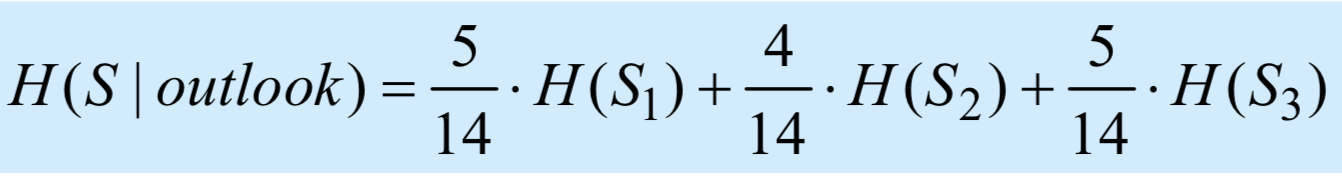
outlook有三种结果sunny,overcast,rainy,则需要计算他们各自的熵:

计算之后H(S | outlook) = 0.693bits,
信息增益G(S | outlook) = H(S) - H(S | outlook) =0.940 - 0.693 = 0.247bits
同理计算其他几个属性,使用信息增益最大的作为划分标准。
信息增益对可取值数目较多的属性有所偏好,为了避免这种偏好,则有了信息增益率:

除此之外,还有基尼系数,它通过基尼值产生:
基尼值:
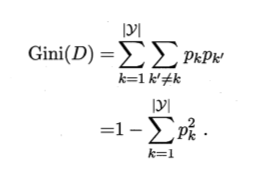
基尼系数:
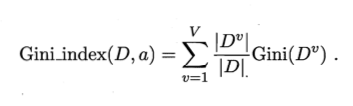
决策树生成
这里直接用代码演示,特征选择方式按照信息增益,即选择entropy
代码模拟:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
np.random.seed(42)
#导入数据,划分训练测试集
from sklearn.datasets import load_iris
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, stratify=iris.target, random_state=42)
#导入模型,判断标准为entropy熵
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy', random_state=42)
#训练,查看性能
tree.fit(X_train, y_train)
print("Accuracy on train set{:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set{:.3f}".format(tree.score(X_test, y_test)))
#可视化
from sklearn.tree import plot_tree
plot_tree(tree,filled=True)
plt.show()
树的生成图

决策边界绘制
由于是在二维平面上绘图,所以这里只取iris数据的前两列,对X进行一下处理,同时也会导致决策树分类器性能的改变:
绘图函数
def plot_boundary(clf, axes):
x1= np.linspace(axes[0], axes[1], 100)
x2= np.linspace(axes[0], axes[1], 100)
xx, yy = np.meshgrid(x1, x2)
x_new = np.c_[xx.ravel(), yy.ravel()]
y_pred = clf.predict(x_new).reshape(xx.shape)
plt.contourf(xx, yy, y_pred, alpha = 0.4, cmap=plt.cm.brg)
只选择前两列:
X_train, X_test, y_train, y_test = train_test_split(
iris.data[:,:2], iris.target, stratify=iris.target, random_state=42)
然后还是通过训练获得一个分类器tree:
plot_decision_boundary(tree, axes=[4, 8, 1.5, 5])
p1 = plt.scatter(X[y==0,0], X[y==0, 1], color='blue')
p2 = plt.scatter(X[y==1,0], X[y==1, 1], color='green')
p3 = plt.scatter(X[y==2,0], X[y==2, 1], color='red')
#设置注释
plt.legend([p1, p2, p3], iris['target_names'], loc='upper right')
plt.show()
绘图如下:

发现这个模型在训练集上效果很好,但测试集的效果差了一点。
剪枝
剪枝是防止过拟合的重要手段。这里使用一下预剪枝pre-prune来提高性能。剪枝本身分为预剪枝和后剪枝,预剪枝提前判断,可以避免生成整颗树,训练时间较短,但预剪枝可能会导致决策树过早的停止分裂,从而欠拟合。后剪枝相对训练时间较长,因为要生成整颗树,再自底向上地决定哪些地方需要剪枝。
预剪枝
这里将树的最大深度max_depth 限定,实现预剪枝效果。
tree = DecisionTreeClassifier(criterion='entropy', max_depth=4, random_state=42)
tree.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))
plot_tree(tree,filled=True)
plt.show()
结果如下:

在训练集上效果变好了,说明这个剪枝操作很ok。
预剪枝的决策边界:

参考文献
[1] 机器学习(周志华 著)














 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









