







 本文详细介绍了PyTorch、PaddlePaddle、MXNet、TensorFlow和OneFlow等深度学习框架的分布式训练原理、接口和示例,包括数据并行、模型并行的概念,以及多机通信库如NCCL的支持。此外,还总结了DLPerf踩坑经验,如多机通信问题、端口配置和加速比低的原因分析。最后,分享了GPU拓扑查看和NCCL相关知识。
本文详细介绍了PyTorch、PaddlePaddle、MXNet、TensorFlow和OneFlow等深度学习框架的分布式训练原理、接口和示例,包括数据并行、模型并行的概念,以及多机通信库如NCCL的支持。此外,还总结了DLPerf踩坑经验,如多机通信问题、端口配置和加速比低的原因分析。最后,分享了GPU拓扑查看和NCCL相关知识。
1.各框架分布式简介
1.Pytorch
从官方文档上我们可以看到,pytorch的分布式训练,主要是torch.distributed包所提供,主要包含以下组件:
- Distributed Data-Parallel Training (DDP)
- RPC-Based Distributed Training (RPC)
- Collective Communication (c10d)
其中,DDP提供了数据并行相关的分布式训练接口;RPC提供了数据并行之外,其他类型的分布式训练如参数服务器模式、pipeline并行模式,使用的是P2P点对点通信;而c10d是一个用于集合通信的库,作为DDP的组件为其提供服务。由于我们大多数的分布式训练需求,是基于DDP的,故下面内容不涉及RPC相关的训练。
接口
单机多GPU可以使用torch.nn.DataParallel接口或torch.nn.parallel.DistributedDataParallel接口。不过官方更推荐使用DistributedDataParallel(DDP);分布式多机情况下,则只能使用DDP接口。
DistributedDataParallel和 之间的区别DataParallel是:DistributedDataParallel使用multiprocessing,即为每个GPU创建一个进程,而DataParallel使用多线程。通过使用multiprocessing,每个GPU都有其专用的进程,这避免了Python解释器的GIL导致的性能开销。如果您使用DistributedDataParallel,则可以使用 torch.distributed.launch实用程序来启动程序
参考:Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel
底层依赖
Pytorch在1.6版本中,可以通过torch.nn.parallel.DistributedDataParallel来实现数据并行的分布式训练,DistributedDateParallel,简称DDP。
DDP的上层调用是通过dispatch.py实现的,即dispatch.py是DDP的python入口,它实现了 调用C ++库forward的nn.parallel.DistributedDataParallel模块的初始化步骤和功能;DDP的底层依赖c10d库的ProcessGroup进行通信,可以在ProcessGroup中找到3种开箱即用的实现,即 ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI。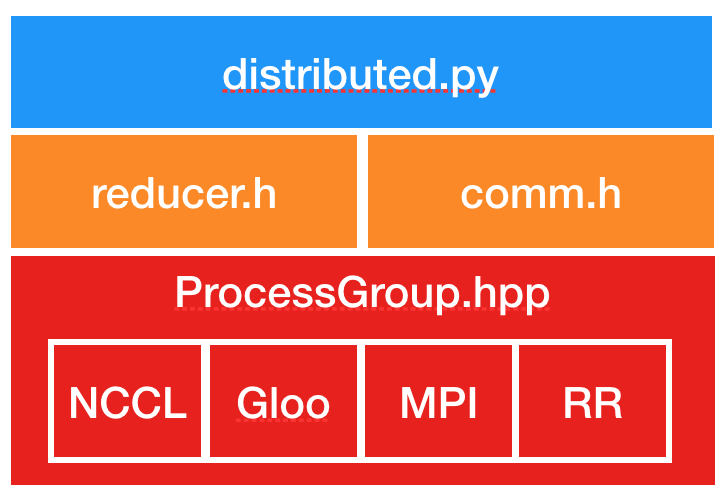
ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI这3种分布式通讯实现分别对应:
- Gloo
- NCCL
- MPI
即本质上,pytorch的分布式多机训练,依赖于以上这3种通信库。
分布式示例
我们以Pytorch官方仓库里的分布式训练源码为例,简单讲解下pytorch分布式训练相关方法和参数。
相关参数
分布式训练的入口是main.py,我们首先看下分布式设置相关的参数。
源码第59行:
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')
- –world-size 表示分布式训练中,机器节点总数
- –rank 表示节点编号(n台节点即:0,1,2,…,n-1)
- –multiprocessing-distributed 是否开启多进程模式(单机、多机都可开启)
- –dist-url 本机的ip,端口号,用于多机通信
- –dist-backend 多机通信后端,默认使用nccl
初始化进程组
分布式训练的第一步是需要设置分布式进程组,设置多机通信后端、本机ip端口号、节点总数、本机编号等信息。
源码129行:
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
将上述分布式相关参数,传递到torch.distributed.init_process_group并初始化用于训练的线程组;
**
创建模型
分布式训练时,模型需要用DDP进行包装。
源码153行:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
通过DDP接口创建一个多机model实例。
**
数据切分和DataLoader
多机的Dataloader和普通dataloader也有所区别,需要用DistributedSampler包装后再通过torch.utils.data.DataLoader实例化成Dataloader。
源码217行:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
通过DistributedSampler创建一个wapper,将数据集放入其中,再通过 torch.utils.data.DataLoader
创建可用于多机的Dataloader;
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









