







 本文介绍了OneFlow如何通过后向重计算(gradient/activation checkpointing)实现在深度学习训练中的亚线性内存优化,大幅降低显存占用。文章详细阐述了亚线性内存优化的用法、设计原理,以及代码实现过程,包括在前向过程中删除中间激活特征,后向过程重计算恢复,并展示了在GPT-2模型上的效果。
本文介绍了OneFlow如何通过后向重计算(gradient/activation checkpointing)实现在深度学习训练中的亚线性内存优化,大幅降低显存占用。文章详细阐述了亚线性内存优化的用法、设计原理,以及代码实现过程,包括在前向过程中删除中间激活特征,后向过程重计算恢复,并展示了在GPT-2模型上的效果。

撰文 | 赵露阳
2016年,陈天奇团队提出了亚线性内存优化相关的“gradient/activation checkpointing(后向重计算)”等技术[1],旨在降低深度学习训练过程中的中间激活(activation)带来的显存占用。Checkpointing技术属于亚线性内存优化的一种,除此之外还有CPU offload等技术(CPU offload在微软Deepspeed框架中被广泛使用)。
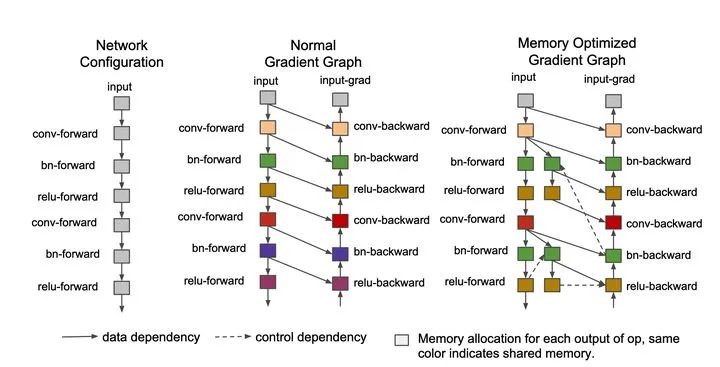
CPU offload将暂时用不到的GPU内存换入到CPU内存中存储,待需要时再取出,主要开销是来自于CPU和GPU之间的拷贝,会占用传输带宽(PCIE带宽),属于以传输换空间。而Checkpointing核心在于以时间换空间:通过计算图分析技术来实施Inplace操作以及内存共享优化(Memory sharing),在每个mini-batch的前向过程中删除一些暂时用不到的中间激活特征以降低内存占用,并在后向过程中需要时借助额外的前向计算恢复它们。
在OneFlow中,Checkpointing的实现主要是通过静态内存复用的方式,前向Tensor的生命周期结束后,其余Tensor可以复用这块内存,从而起到内存复用、节省内存的效果。
OneFlow目前支持了“gradient/activation checkpointing”(后向重计算)以实现亚线性内存优化,且对算法开发者非常友好,使用方式很简单:针对需要优化的网络部分,用一行代码将其包裹在“Checkpointing”的scope范围内即可,系统内部会针对此scope区域内的网络做分析并在训练过程中自动进行Checkpointing内存优化。
本文主要内容为以下3点:
-
1.亚线性内存优化的用法
-
2.亚线性内存优化的设计
-
3.代码解读
其中:1.将介绍如何在OneFlow中开启试用亚线性内存优化;2.将介绍OneFlow中亚线性内存优化是如何设计的及其原理;3.将从代码入手,剖析具体实现过程。
1
亚线性内存优化的用法
OneFlow中开启亚线性内存优化的方式如下:
# 用法:
with flow.experimental.scope.config(checkpointing=True):
# your net work, such as :
# input layernorm
norm1 = layernorm("layernorm_1", h)
# attention
h = h + self.attn(norm1)
# output layernorm
norm2 = layernorm("layernorm_2", h)
# mlp
h = h + self.mlp(norm2)用上述代码包裹后,此scope区域内的网络,在整个前向过程中只会保存一份input tensor的内存,从input到最后输出h,这之间所有中间特征tensor的内存都不会被保存,后向过程需要时从input开始进行(前向的)重计算。
我们在多个网络上进行了开启/关闭checkpointing的显存占用测试,以GPT-2为例,具体是在每个Transformer Layer内都使用checkpointing = True scope标记重计算的部分。
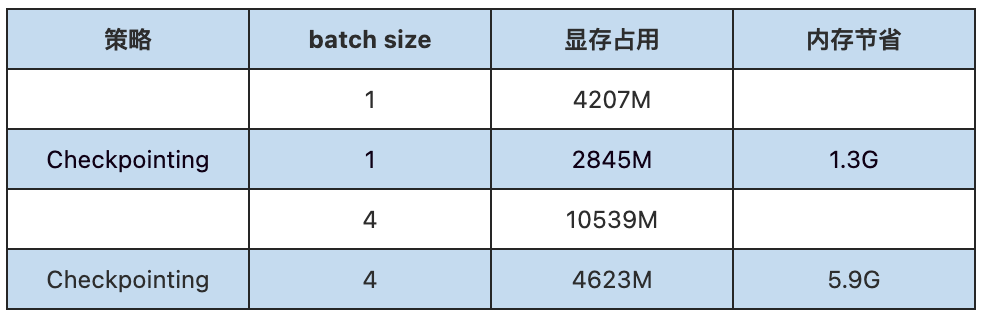
可以看见,开启checkpointing后会大幅降低GPT-2训练时的显存占用,在batch size = 4 时,内存节省超过50+%。
2
亚线性内存优化的设计
在系列文章《深度解析:让你掌握OneFlow框架的系统设计(上篇、中篇、下篇)》中,我们介绍了OneFlow中的OpNode/OpGragh抽象以及建立在这之上的Actor、SBP抽象等系统设计,正是这些良好的系统设计和抽象使得OneFlow在多种任务下都有着优秀的表现。
OneFlow的Job任务在逻辑图编译期会基于由OpNode构成的Job逻辑图(OpGragh),进行一系列pass的系统优化过程,每个pas
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









