








最近,OneFlow工程师成诚发布了一篇《GPT-3模型为何难以复现?这也许是分布式AI框架的最优设计》,文章非常详细地提到深度学习框架面临的分布式训练难题,相信算法工程师都会碰到,强烈建议读一读。
本文将重点梳理深度学习框架在支持大规模预训练模型时面临的技术挑战,以及当前各类框架的基本解决思路,帮助算法工程师对业界各类框架的分布式训练能力有更清晰的认知。
撰文 | 袁进辉
近年来,深度学习被广泛应用到各个领域,包括计算机视觉、语言理解、语音识别、广告推荐等。在这些不同领域中,一个共同的特点就是模型规模越来越大,比如GPT-3模型的参数量达到1750亿,即便拥有1024张80GB A100, 那么完整训练GPT-3的时长都需要1个月。大规模预训练模型及其训练成为业界尤为关注的热点。
那么,模型规模变大带来了哪些挑战?首先是硬件发展水平导致的内存墙问题。单一设备的算力及内存容量,受限于物理定律,持续提高芯片的集成越来越困难,难以满足大模型规模扩大的需要。为了解决算力增速不足的问题,人们考虑通过使用多节点集群进行分布式训练来提升算力,分布式训练则势在必行。
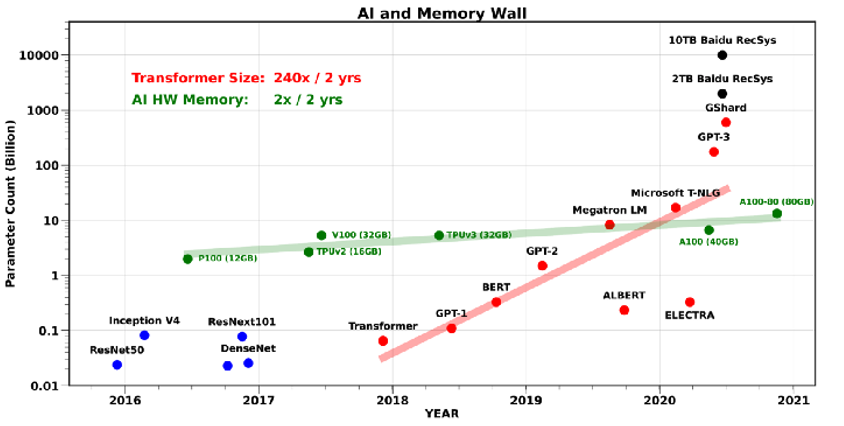
大型Transformer模型参数量和计算设备内存最近5年的增长速度
但是,简单的机器堆叠并不一定可以获取算力的增长,因为内存的带宽增长速率也大大落后于算力增长,跨计算设备之间的网络带宽更低,使得数据搬运成为整个训练的瓶颈,进而导致训练效率大大下降。
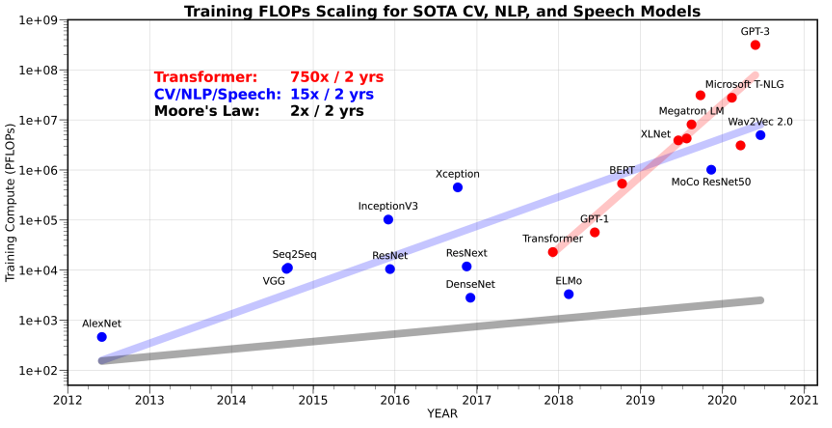
Transformer及计算机视觉、自然
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









