








撰文 | 杨军
每一代NV GPU的发布都会给业界带来新的想象空间。作为AI系统(这里主要代指深度学习系统)方向的从业者,最关心的自然是每一代GPU能够为AI系统领域带来哪些新的变量。
从之前NV GPU的甲方消费者,转变为现在的乙方提供者,视角变化让自己可以从不同角度来看待这个问题。这里会以深度学习系统的发展踪迹为应用载体,来回顾NV GPU架构的历史变迁。
整个回顾会从最早应用于深度学习计算加速的GTX 580开始,直到最新的Ampere架构。对每一代GPU的回顾会从以下几个方面展开:
-
单设备硬件架构
-
跨设备硬件架构
-
AI workload及应用场景的演进
-
AI软件栈的演进
-
生态发展
首先来看Fermi,这也是第一款应用于代表性深度学习加速场景(AlexNet)的GPU架构。
1
Fermi
Fermi是支持CUDA的第三代GPU架构,第一代是2006年推出的G80架构(公开材料没有查询到G80的whitepaper,相对详细一些的分析可以参见anandtech的文章:https://www.anandtech.com/show/2116/5),第二代是2008年推出的GT200架构(类似G80,在NV官网上已经找不到类似Fermi的whitepaper,倒是在一些分析网站上有一些关联内容,比如beyond3d的文章https://www.beyond3d.com/content/reviews/51/8和anandtech的文章https://www.anandtech.com/show/2549)。
从Fermi时代开始,Tesla产品线的每一代GPU的whitepaper都提供了公开下载的链接,里面提到了大量的架构技术细节。这篇回顾文章正是以这些whitepaper为基础展开。在Fermi的这篇whitepaper里提到了这样一段话,读来让人感慨颇深:
When designing each new generation GPU, it has always been the philosophy at NVIDIA to improve both existing application performance and GPU programmability; while faster application performance brings immediate benefits, it is the GPU’s relentless advancement in programmability that has allowed it to evolve into the most versatile parallel processor of our time. It was with this mindset that we set out to develop the successor to the GT200architecture.(来源:https://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf)
以hindsight式的视角来看,将可编程性放在和性能相齐的位置是一个重要的决策。因为可编程性的改善对于提升NV GPU的网络效应和用户切换成本,至关重要。
在俞军的《产品方法论》里提到了用户价值=新体验-旧体验-切换成本。这个公式也适用于GPGPU这种To B性质的产品。以NV当前代际GPU代指新体验,上一代GPU代指旧体验,性能提升相当于在强化新体验,可编程性相当于在减少切换成本。以NV GPU代指旧体验,竞品代指新体验,这个公式同样成立,只不过可编程性相当于增加竞品的切换成本,性能提升相当于减少竞品提供的增益价值。
在接下来的历代GPU架构回顾过程中,我们可以看到NV一以贯之地坚持践行这个理念,不断通过性能和可编程性(包括用于提升AI开发者生产效率的努力也归结为广义的可编程性)的提升来强化自己产品相较于上代产品和竞品的用户增益价值。
任何事物都有其两面性。所以,对可编程性的重视也存在风险,可能成为制约NV发展的阿喀琉斯之踵。从Google在2016年推出TPU开始(从开创AI DSA硬件先河的角度,引爆这一拨AI硬件技术演进大趋势的寒武纪也成立于2016年),行业里涌现出大量的AI芯片Start-up。
仅从硬件层面AI绝对算力来说,这些公司里已经出现了和NV当前主流产品性能on-par的产品,如果从performance per watt的角度来看,也已经出现了超过NV的若干竞品。其核心原因也跟NV需要关注可编程性和历史用户习惯的包袱有关,而新兴公司没有积累也同样没有包袱,所以可以在架构设计的空间里以适当牺牲通用可编程性为代价来寻找更适合于挖掘AI计算效率的设计权衡点。相关原理在《创新者的窘境》里也有提到,这也是考验某个领域里头部企业的地方。
回归正题。Fermi相较前两代架构,引入了比较大的架构变化:
-
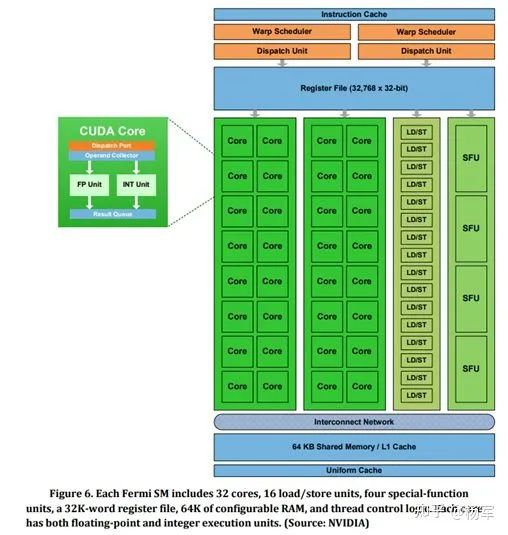
对流处理器(SM)进行了重新设计,包括:每个SM包含32个CUDA cores(这里需要提一下,CUDA core在概念上和通用计算的CPU core的性质其实是有差异的,不过并不影响从AI计算角度的讨论,所以在此先不展开)。每个SM里包括32浮点单元(FPU)和32个整数计算单元(INT Unit),16个Load/Store单元。4个特殊函数单元(SFU)。习惯上,我们会把FP32 ALU称为一个CUDA core,早期NV GPU因为INT 和 FP32 共享datapath,不能做ILP,所以那时候的CUDA core可以被认为包含一个INT和一个FP32 ALU。
-
对双精度算力进行了大幅提升。考虑到深度学习场景很少用到双精度计算,所以对这个细节不再展开。
-
引入了L1 cache,并增加了shared memory的容量。L1和shared memory的可配置总量是64KB,支持两种配置(48KB shared memory + 16KB L1或48KB L1 + 16KB L1)。shared memory从上一代的16KB增加到最多可达48KB。实际上,从Fermi开始,每一代GPU都会对shared memory,Register File,L1进行调整,支撑这些调整决策的是硬件推出后,通过和客户交互迭代所增加的对应用负载的理解,以及工艺进步带来了更多可供腾挪的片上硬件资源。
-
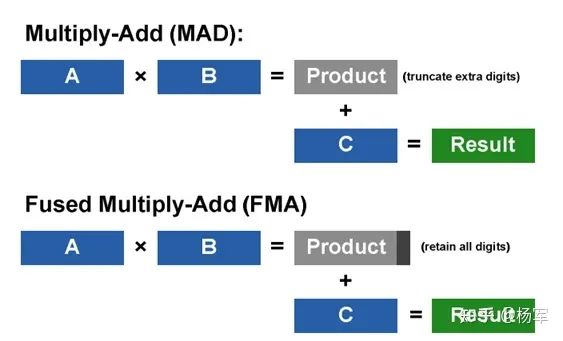
加入了对单精度浮点计算FMA的支持(Fermi之前的架构,支持双精度的FMA,对于单精度只支持MAD,FMA的精度更有保障,可参见这里的描述:https://en.wikipedia.org/wiki/Multiply%E2%80%93accumulate_operation),精度有了更高保障。
-
warp scheduler的数量从1增加到2,通过增加可调度发射的warp数量,来提升片上计算资源的利用率。Fermi的SM架构示意图如下(https://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA%27s_Fermi-The_First_Complete_GPU_Architecture.pdf)
引入了768KB的L2 cache。在Fermi之前,NV GPU是没有L2 cache的,从Fermi这一代开始,引入了L2 cache,并且随着代际演化,不断增加L2的尺寸。L2的引入,将之前需要由软件开发人员take的数据搬运优化的部分工作让渡给了硬件,从而部分减少了软件开发人员的心智负担。
对访存系统加入了ECC支持。对于ECC,我目前仍然怀疑其对于AI计算场景的必要性。因为我的认识是,AI计算过程本身可以通过系统层面的设计(比如阶段性的Checkpoint)来对冲ECC所针对修复检测的内存bits错误异常的影响,所以引入ECC这种会消耗访存带宽及存储资源的手段有些浪费。这也是我理解大量不包含ECC功能的桌面显卡能够应用在生产训练和推理集群的原因。
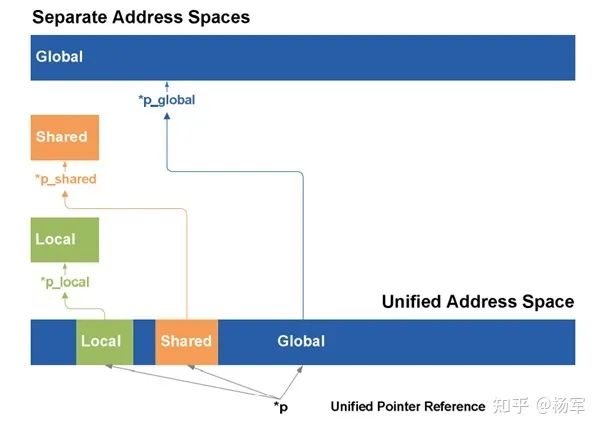
load/store地址位宽由32-bit提升到64-bit,为统一地址访问提供了基础条件。比如local memory,shared memory,global memory进行统一编址(参见下面的一张示意图)。
从AI系统的角度,NV在Fermi这一代并没有为AI计算场景进行任何针对性的设计,包括硬件和软件。其被应用在AlexNet上也更像是一个机缘巧合:Alex这样的算法科学家因为实际算法需求,在为钉子找锤子的过程中,发现GPU相较CPU更适合解决相关问题从而将其作为锤子引入进来。整个过程中NV的作用是相对passive的。这和当前NV在AI计算领域的主动和激进存在着巨大差异。
而在当时那个年代,为什么是NV GPU被选中作为锤子,而不是Intel CPU或AMD GPU?
让我们穿越过历史的故纸堆,试图做一些推测。
在2006年的这篇文章(https://hal.inria.fr/inria-00112631/document)里,我们能够看到基于论文里的实验对比,Intel CPU上打开BLAS库,和NV GPU上的性能在on-par的水准,当时这个工作里并没有使用到CUDA,因为当年正是CUDA的元年。
有趣的是在,这篇文章的脚注里提到了除了在NVIDIA GeForce 7800 Ultra(https://www.techpowerup.com/gpu-specs/geforce-7800-gtx.c127),Intel Pentium 4(https://en.wikipedia.org/wiki/Pentium_4)上的性能实验之外,也准备加入ATI Radeon X1900(https://www.techpowerup.com/gpu-specs/radeon-x1900-xt.c454)上的实验结果。在2005年更早的一篇文章(https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1575717)里,能够看到在CPU, ATI GPU, NV GPU上同时进行MLP加速实验对比的一些数据,看起来当时还互有千秋。
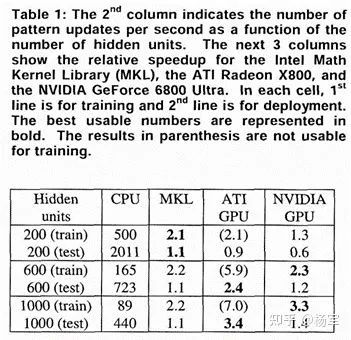
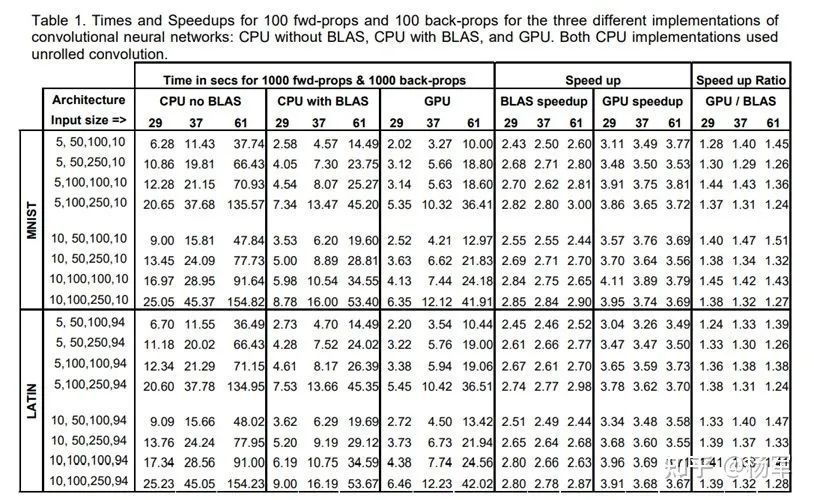
而在2011年的这篇文章(https://people.idsia.ch/~juergen/ijcai2011.pdf)里,基于CUDA实现的卷积操作,性能最多已经达到了Intel CPU上的60倍。当时使用的硬件是Intel Core i7-920(2.66GHZ)以及基于Fermi架构的GTX480/GTX580显卡。年代久远,实测评估已经不太现实,不过,从多个途径的数据cross check的结果(https://gadgetversus.com/processor/intel-core-i7-920-specs/, https://fiehnlab.ucdavis.edu/staff/kind/collector/benchmark/core-i7-vs-opteron, 还有https://www.overclock.net/threads/intel-and-amd-gflops-data-thread-looking-for-sandybridge-too.869018/)来看,i7-920 2.66GHZ的峰值算力大体在在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









