








撰文 | 郑建华
更新|赵露阳、王迎港
深度学习框架一般通过自动微分(autograd)机制计算梯度并反向传播。本文尝试通过一个简单的例子,粗浅地观察一下OneFlow的autograd的实现机制。
1
自动微分基础
自动微分相关的资料比较多,个人感觉自动微分的原理介绍(https://mp.weixin.qq.com/s/BwQxmNoSBEnUlJ1luOwDag)这个系列及其引用的资料对相关背景知识的介绍比较完整清晰。
下面分几种情况对梯度传播的原理做一些直观解释。
1.1 stack网络的梯度传播
以x -> f -> g -> z这个stack网络为例,根据链式法则:
∂z/∂x = ∂z/∂g * ∂g/∂f * ∂f/∂x实际运行时,在梯度反向传播过程中:
-
z将∂z/∂g传给g。
-
如果节点g有权重w需要计算梯度,就计算∂z/∂w = ∂z/∂g * ∂g/∂w。
-
g需要计算∂g/∂f,再乘以z传过来的梯度,将结果传给f。g只需要给f传递链式乘积的结果,不需要传递各项明细。
-
在训练阶段的前向计算时,g需要保存∂g/∂f计算依赖的中间结果、以供反向计算时使用。
-
其它节点的传播情况依次类推。
1.2 简单graph的梯度传播
以下面这个简单的graph拓扑为例。
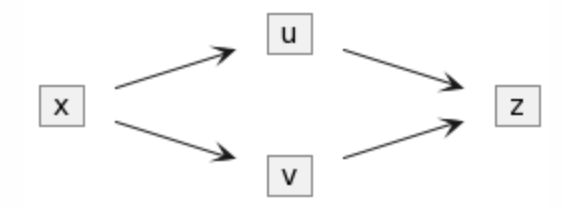
在继续之前,需要了解一下多元复合函数微分的基本公式。
下图中,u和v都是关于x和y的函数,z是关于u和v的函数。
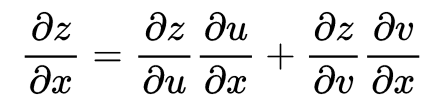
根据这个公式可以知道,z对x的梯度分别沿两条链路传播,z -> u -> x和z -> v -> x,节点x将两个梯度之和作为z对x的梯度。
1.3 复杂graph的梯度传播
再看一个拓扑稍微复杂点的例子:

上图可以视为x -> U -> L,其中U是e -> ... -> h的子图。f -> g的子图可以视为V。
对于节点h来说,它需要把梯度传给g和k。对节点e来说,它需要对f和k传来的梯度求和,才是∂L/∂e。这样,L对x的梯度,仍可以按链路拆解,一条链路前后节点间的梯度是乘积关系,传入的多条链路梯度是加和关系。
这篇博客(https://blog.paperspace.com/pytorch-101-understanding-graphs-and-automatic-differentiation/)中有一个几乎一样的拓扑图,给出了部分权重参数的梯度公式。
2
autograd中tensor相关的一些基本概念
2.1 叶子节点
OneFlow的autograd文档(https://docs.oneflow.org/en/master/basics/05_autograd.html)中介绍了leaf node和root node的概念。只有输出、没有输入的是leaf node,只有输入、没有输出的是root node。
个人理解,如果把weight、bias、data视为计算图的一部分,这些节点就是叶子节点(op不是叶子节点)。尤其是从反向计算图的视角(https://discuss.pytorch.org/t/what-is-the-purpose-of-is-leaf/87000/9)看,这些节点的grad_fn是空,反向传播到这些节点就会停止。
is_leaf和requires_grad有比较密切的关系,但二者又是独立的。PyTorch是这样解释的:(https://pytorch.org/docs/stable/generated/torch.Tensor.is_leaf.html#torch.Tensor.is_leaf)
-
requires_grad=false的节点都是叶子节点。比如data。
-
requires_grad=true的节点如果是用户创建的,也是叶子节点。比如weight和bias。
-
在梯度的反向计算过程中,只有叶子节点的梯度才会被填充。对于非叶子节点,如果要填充梯度信息,需要显式设置retain_grad=true。
-
requires_grad=true才会计算、填充梯度。比如y = relu(x),y是op创建的、不是叶子节点。但如果x需要计算梯度,则y.requires_grad==true。但不需要为y填充梯度。
关于叶子节点这个概念,目前找到的主要是直观描述,还没看到严格、清晰的定义。也可能是因为用户一般不会直接使用is_leaf(https://discuss.pytorch.org/t/what-is-the-purpose-of-is-leaf/87000/9),这个概念只是在阅读代码的时候才会涉及到。
下面的资料可以供进一步参考:
-
What is the purpose of `is_leaf`? (https://discuss.pytorch.org/t/what-is-the-purpose-of-is-leaf/87000)
-
叶子节点和tensor的requires_grad参数(https://zhuanlan.zhihu.com/p/85506092)
2.2 tensor detach
Tensor的detach方法(https://github.com/Oneflow-Inc/oneflow/blob/48e511e40e09551408c96722c09bd061ce320687/oneflow/core/framework/tensor_impl.cpp#L155)会创建一个新的tensor,新tensor的属性中
-
requires_grad = false
-
is_leaf = true
detach的意思是从grad的反向计算图中把tensor分离出来。新的tensor与原来的对象共享存储,但不参与反向图的拓扑构造。原有对象的requires_grad属性不变。
比如下面的代码,修改一个对象的数据,另一个对象的数据也会改变。
import oneflow as flow
y = flow.Tensor([1, 2, 3])
x = y.detach()
x[0] = 4
assert(y[0] == 4)3
示例代码
本文通过如下代码来观察OneFlow的autograd机制。
import oneflow as flow
# y is scalar
x = flow.tensor([-1.0, 2.0], requires_grad=True)
y = flow.relu(x).sum()
y.backward()
print(x.grad)
# y is not scalar
x = flow.tensor([-1.0, 2.0], requires_grad=True)
y = flow.relu(x)
y.backward(flow.Tensor([1, 1]))
print(x.grad)y.backward方法有两种接口:
-
如果y是一个标量(比如loss),不需要传递任何参数。
-
如果y是一个向量,需要传入一个与y的shape一致的向量作为参数。
为什么会有这种区别呢?下面几篇参考资料中对这个问题做了比较详细的解释。简单的说:
-
如果函数的输出是向量,在反向传播的过程中会造成梯度tensor shape的维度膨胀,实现复杂、性能差。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









