








作者|Pietro Casella、Patrik Liu Tran
翻译|贾川、徐佳渝、杨婷
语言(即读写能力)是人类最重要的发明,也是人类与其它物种的最大区别。语言使我们掌握了抽象推理,发展出了复杂思维,学会了与他人沟通交流。可以说,没有语言就不会有现代文明。
因此,未来几年大型语言模型(LLM)将极大地影响生成式AI的发展,ChatGPT的迅速普及就是很好的例证。此外,LLM还在多种场景得到应用,比如内容创建、代码生成、药物开发、翻译、搜索以及工作场所实用程序(例如会议转录和摘要)。
 LLM应用实例
LLM应用实例
总之,生成式AI的最新进展标志着AI已然迈进新时代。AI如今不再只是研究课题,而是成为了帮助人们解决实际问题的实用工具,在各行各业发光发热。因此,企业必须要重视AI的影响力。
面对AI的发展,企业要立即行动起来,维持自身竞争力。长期来看,未能与AI融合的公司将在这场竞争浪潮中日益落后,并逐渐消亡。对于企业来说,最关键的是要把控好AI的优势和成本,采取必要措施将AI纳入发展规划。未来几年将会是商业发展的黄金时期,新兴企业已如雨后春笋般出现。
本文主要关注LLM,包括LLM和模型相关技术概述,以及它们在实践中的应用。希望本文可以帮助从业者了解如何在业务中应用LLM,使行业潜在投资者全面了解这一领域,作出更好的投资决定。虽然我们提供的框架(例如各类AI公司的分类)适用于所有生成式AI,但这里还是以LLM示例为主。
(本文经授权后由OneFlow编译,译文转载请联系OneFlow获得授权。原文:https://aigeneration.substack.com/p/ais-next-frontier-building-and-investing)
1
从Transformer到ChatGPT
AI领域常有开创性论文发表,这些论文影响着行业的未来发展方向。LLM领域中,“Attention Is All You Need”就是这样一篇论文。
这篇文章由谷歌团队于2017年发表,在文中,他们提出了一种名为Transformer架构,简单来说,与当时的SOTA替代方案相比,Transformer架构具有高度并行性和计算效率,同时具有超高性能。
这意味着,采用Transformer架构的模型训练成本更低、速度更快,生成的模型性能更好。在不影响性能的情况下,这种低成本、高效的组合十分重要,它能够让我们利用更多的数据,训练更大的模型。
受Transformer启发,在Transformer架构的基础上,各类知名LLM层出不穷,例如:生成式预训练Transformer(GPT)模型、BERT以及XLNet。
有关GPT(1.0)和BERT的论文最早可以追溯到2018年。次年(即2019年)发表了第一篇关于XLNet的论文。尽管如此,直到2022年底,OpenAI推出ChatGPT后,LLM才进入大众视野,开始风靡于研究界之外。
ChatGPT推出后,不到一周的时间里,就收获了超百万用户。这种普及速度十分罕见,几乎超越了以前所有的科技产品。台上十分钟,台下十年功,所有的突破性成就必然来自于夜以继日的努力。基于GPT-3.5的ChatGPT是LLM领域多年以来的最重要的成就。实际上,ChatGPT的基础模型并不是最好的LLM,但却是目前最受欢迎的模型。
时间会证明一切。在我们看来,ChatGPT最重要的是作为PoC(为观点提供证据),向世界展示LLM的能力。尽管ChatGPT发布初期十分火爆,但我们不确定它能否成为主流LLM之一,在实际用例中获得广泛应用。原因如下:
1
基础模型vs专用模型

基础大型语言模型是在大量公开文本、数据(例如,维基百科、新闻文章、Twitter、在线论坛等)上进行训练的。模型训练数据话题广泛,内容繁杂,并不针对特定领域和任务,这类模型包括:GPT-3,Jurassic-1,Gopher和MT-NLG。
目前,虽然建立在基础AI模型(如ChatGPT)之上的应用程序非常流行,但我们预计,专用于特定领域或任务的模型才能发挥出LLM的真正价值。因为与相同模型大小的基础模型相比,在专业领域里,专用模型的表现通常来说更好。这意味着,我们需要用更大的基础模型(这也意味着更高的推理成本和更大的内存占用)才有可能在专业领域实现与专业模型相同的性能。
专用模型比基础模型表现更好的原因之一与模型对齐有关,即LLM的输出与模型用户的目标和兴趣相对应的程度。更好的模型对齐意味着答案是正确且相关的,也就是说正确回答了模型请求的问题。由于专用模型仅关注特定领域或任务,因此与基础模型相比,专用领域模型的对齐程度通常更高。
我们有多种方式实现模型的专用化,其中之一就是利用专用领域或任务的数据来训练基础模型。比如,一个基础模型可以很好地回答银行相关的一般问题,然而,如果你想要打造一个专门针对银行的聊天机器人,那么这个通用模型的性能水平就不太够用了。这时,我们就可以利用银行业相关的数据集来训练这个模型,实现模型专业化。反过来,假如有一家银行想要在客服服务中应用聊天机器人,从而实现简单任务的自动化,此时银行可能会在实际客户服务对话的专门数据上进一步训练这个专业模型。像这样训练以后,LLM就能学会特定银行按照一定政策的行事方式,毕竟不同银行可能有不同的政策和指导方针。
因为专用模型针对的是特定任务,不涉及其它不相关的领域和任务,所以说,不需要用到很大的基础模型来进行进一步训练。使用更小的模型意味着更低的推理成本和更小的内存占用,也就是说,比最大的可用模型小得多的基础模型可能会成为专用基础模型的首选。
2
LLM如何改进?
为了更好地了解LLM的功能和局限性,我们首先要了解该如何改进它们。LLM的改进有三个主要驱动因素,分别是:体系结构改进、更大的模型、更多的训练数据。接下来我们将对这三方面进行逐一介绍。
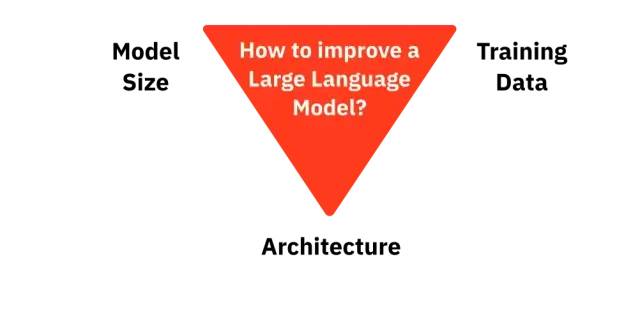
架构改进是关键,但很难取得突破
架构改进(例如2017年的Transformers架构)可以在不增加模型复杂度和训练数据量的情况下提升LLM性能。目前正在构建的多数SOTA性能LLM仍然是基于Transformer的网络架构(与2017年推出的架构非常相似)。尽管它具有已知的局限性(例如自注意导致的二次方时间和内存复杂性),但目前还没有广受认可的架构更新。话虽如此,人们一直在不断探索,试图改进架构,并为此推出了所谓的高效Transformers来消除已知局限。
对现有SOTA架构的渐进式改进(如高效Transformers)将逐年突破模型性能界限。此外,每隔一段时间,行业就会迎来突破性的架构改进(例如原始Transformer架构),这些改进代表着模型性能的跨越式提升。
与增加模型大小和训练数据量相比,改进模型架构较为困难。模型架构改进遵循传统研发模式,需要大胆创新,且无法保证结果,因此,LLM的此类性能改进最为棘手,同时也是架构渐进式提升与突破向社区发布和分享的标准。除了率先使用先进模型,这意味着这类提升不能作为长期优势去与其它构建LLM的公司或对手竞争。例如,OpenAI的LLM是以Google Brain 2017年发明并公开的Transformer为基础。
LLM改进经典做法:扩大模型规模
目前,为了提高LLM性能,人们将大部分精力放在了增加模型大小上面。2020年,OpenAI发表了一篇论文,提出了在增加模型尺寸与提高模型性能之间的扩展定律,论文的结论是:人们应该将大部分预算用于扩大模型规模。这篇论文直接推动了增大模型规模的浪潮。下图出自论
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









