








本文深入探讨了检索增强生成(RAG)技术在AI工作流中的应用,特别是OpenAI的o1系列模型和Google的Gemini 1.5模型在长上下文RAG任务中的性能,分析了不同模型在长上下文RAG任务中的失败模式,为开发者构建RAG系统提供了宝贵参考。
(本文由OneFlow编译发布,转载请联系授权。原文:https://www.databricks.com/blog/long-context-rag-capabilities-openai-o1-and-google-gemini)
来源|Databricks
翻译|张雪聃、林心宇
OneFlow编译
题图由SiliconCloud平台生成
检索增强生成(RAG)是Databricks的客户希望在自身数据上定制AI工作流的主要应用场景。大语言模型(LLM)发布的速度非常快,许多客户都想获得最新的指导,以构建最佳的RAG流水线。在之前的博客文章中(LLM的长上下文RAG性能,https://www.databricks.com/blog/long-context-rag-performance-llms),我们在13种流行的开源和商用LLM上进行了超过2000次的长上下文RAG实验,以揭示它们在各种领域特定数据集上的表现。发布这篇博客后,我们收到了许多请求,希望对更多顶尖模型进行进一步的基准测试。
九月,OpenAI发布了GPT o1,依靠额外的推理时计算来增强“推理”能力。我们很想看看这些新模型在我们内部基准测试中会有怎样的表现;增加推理时计算是否会带来显著提升?
我们设计了评估套件,对长上下文的RAG工作流进行压力测试。Google Gemini 1.5模型是唯一具备200万词元上下文长度的顶尖模型,我们对Gemini 1.5模型(5月发布)的表现感到兴奋。200万词元大致相当于一个包含数百篇文档的小型语料库;在这种情况下,开发者构建自定义AI系统时,原则上可以完全跳过检索和RAG,直接将整个语料库包含在LLM上下文窗口中。这些超长上下文模型真的能替代检索吗?
随后,我们对新的顶尖模型OpenAI o1-preview、o1-mini以及Google Gemini 1.5 Pro和Gemini 1.5 Flash进行了基准测试。在进行这些额外实验后,我们发现:
-
在我们长上下文RAG基准测试中,OpenAI o1模型相比Anthropic和Google模型有持续提升,支持上下文长度最高可达128k词元。
-
尽管性能不如顶尖的OpenAI和Anthropic模型,但Google Gemini 1.5模型在极端上下文长度(最高达200万词元)下展现了稳定的RAG性能。
-
不同模型在长上下文RAG任务中表现出不同的失败模式。
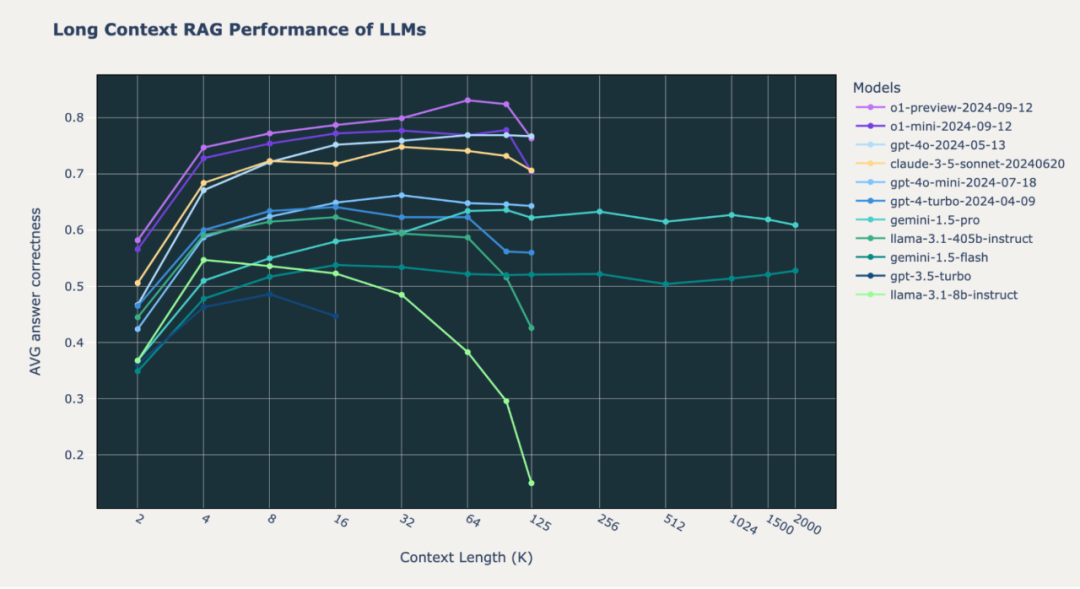
图1: 尖端模型在三个精选的RAG数据集(Databricks DocsQA、FinanceBench和Natural Questions)上的长上下文性能。上下文长度以千词元为单位,从2k到200万词元进行衡量。
1
前文回顾
我们设计了内部基准来测试尖端LLM的长上下文端到端RAG能力。基本设置如下:
-
从使用OpenAI的text-embedding-3-large嵌入的向量数据库中检索文档片段(chunk)。文档被分割为512词元的片段,步长为256词元。
-
通过在上下文窗口中包含更多检索文档来改变总词元数。我们将总词元数从2k增加到200万。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









