







本文简要介绍CVPR 2024录用论文“DIBS: Enhancing Dense Video Captioning with Unlabeled Videos via Pseudo Boundary Enrichment and Online Refinement ”的主要工作。论文提出了一种用于密集视频字幕(Dense video captioning, DVC[1])的新的预训练框架Dive Into the BoundarieS(DIBS),它详细阐述了从未标记视频中提高生成的事件字幕及其相关伪事件边界的质量。通过利用大语言模型(LLM)的功能生成丰富的面向DVC的字幕,并在几个精心设计的目标下优化了相应的伪边界。此外,论文还提出一种新的在线边界细化策略,该策略在训练过程中迭代地提高了伪边界的质量。该方法在YouCook2和ActivityNet标准DVC数据集上取得了显著进步,在指标上都优于之前最先进的Vid2Seq[2],仅使用了用于Vid2Seq[2]预训练的0.4%的未标记视频数据就实现了这一点。

论文链接:https://arxiv.org/abs/2404.02755
研究背景
随着视频数据的爆炸式增长,视频理解技术日益受到关注,其中,DVC任务因其对视频内容的深度解读和结构化表达而显得尤为重要。DVC旨在对未剪辑视频中的所有事件进行精确的时间定位和详细的文本描述,为用户提供更丰富、细致的视频内容理解。然而,高质量的视频事件标注数据极为匮乏,严重限制了DVC技术的进一步发展。
研究动机
现有的DVC方法主要依赖于有限的标注数据集进行训练,虽取得一定进展,但受制于数据量和标注质量,性能提升遇到瓶颈。为克服这一难题,部分研究尝试利用含有字幕的未标注视频进行预训练,以期利用大量未充分利用的资源。然而,直接将原始字幕转化为事件描述和边界的做法,由于字幕信息往往包含大量非事件相关的内容,可能导致生成的标签数据包含大量噪声,无法充分挖掘未标注视频的潜在价值。因此,迫切需要一种新方法,能在大规模未标注视频中高效地生成高质量的事件标签,以突破现有方法的性能限制。
方法介绍
为应对上述挑战,本文提出Dive Into the BoundarieS (DIBS)框架,创新性地结合大型语言模型和优化算法,从大规模未标注视频中生成高质量事件标签,推动DVC等核心任务的进步。DIBS框架的关键组成部分包括:
事件描述生成:如下图所示不同于Vid2Seq[2]直接使用原始字幕作为事件描述,DIBS利用大型语言模型(LLM),通过精心设计的任务提示,从视频字幕中提取出丰富、准确的事件描述候选。这一过程过滤掉了字幕中的无关信息和噪声,确保生成的事件描述更为聚焦、精确。
事件描述生成
如下图所示不同于Vid2Seq[2]直接使用原始字幕作为事件描述,DIBS利用大型语言模型(LLM),通过精心设计的任务提示,从视频字幕中提取出丰富、准确的事件描述候选。这一过程过滤掉了字幕中的无关信息和噪声,确保生成的事件描述更为聚焦、精确。
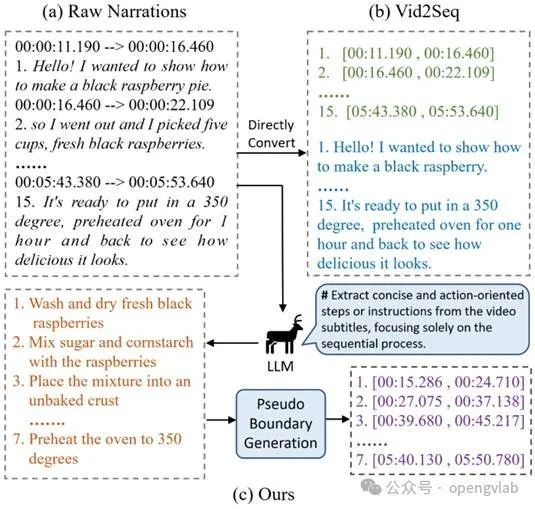
伪边界生成与优化
DIBS采用新颖的边界生成与优化算法,根据事件描述与视频帧之间的相似度构建相似度矩阵,生成与每个描述对应的伪事件边界,并在多个目标下进行优化,确保边界质量,详细流程可以参考下面的伪代码。相比之下,Vid2Seq[2]的边界生成过程相对直接,对边界质量的精细化优化不足,可能导致生成的边界不够精确。

此外,DIBS还引入了在线边界优化策略。在模型训练过程中,DIBS不仅生成伪事件边界,还通过迭代优化的方式不断精炼这些边界。具体来说,该策略包括以下几个关键步骤:
1. 多候选边界设定:在每个伪边界附近设置多个候选边界,为边界细化提供丰富的可能性空间。
2. 模型评估与边界更新:使用预训练的密集视频描述模型对这些候选边界逐一评估,依据评估结果,以迭代方式不断调整和优化伪边界,确保每次迭代后边界质量得到提升。
通过在线边界精炼机制,DIBS不仅生成初始的伪边界,还在训练过程中持续优化这些边界,使其更加贴近真实事件的发生时刻,从而显著提升了模型对事件定位的准确性。
实验结果
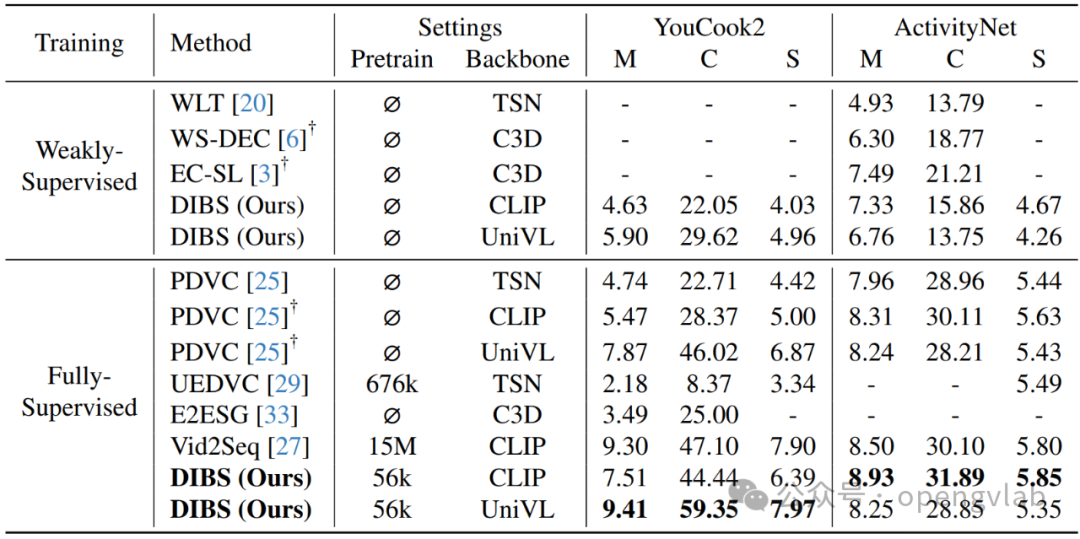
如下表所示,在YouCook2和ActivityNet等多个公开数据集中,DIBS框架在METEOR、CIDEr、SODA_c、Recall和Precision等多个评价指标上均超越了当前最先进的Vid2Seq[2]模型,树立了新的性能标杆。尤其值得一提的是,DIBS仅使用了Vid2Seq[2]预训练所用无标注视频数据的0.4%,却展现出如此卓越的性能,有力地证明了其在低资源条件下高效利用未标注数据的能力,尤其是在边界精炼方面带来的显著改进。
除了在相关数据集进行对比评测外,我们还可视化了预训练前后模型生成文本的丰富度。如下图所示,我们比较了有和没有我们提出的预训练的DIBS模型预测的字幕的词云,可以看出,预训练后的预测字幕比未经预训练的预测字幕显示出更丰富的词汇,突出了我们的方法在字幕生成多样化方面的成功。预训练后单词量的大小和多样性的变化表明,模型的细微理解有了显著改善,支持了我们关于预训练对丰富多样的密集视频字幕的好处的假设。

最后,为了进一步证明我们方法的有效性,在下图中我们针对YouCook2数据集上给出了DIBS的一些定性结果。我们可以从这些示例中看到,我们的DIBS可以预测准确的事件边界以及丰富的字幕。

综上,DIBS框架通过创新的事件描述生成方式(区别于Vid2Seq[2]的直接字幕转化)、伪边界生成与优化算法,以及独特的在线边界精炼策略,开创了视频理解领域利用大规模未标注视频资源的新路径。它不仅能够从未标注视频中提取出高质量事件标签,推动DVC等核心任务的发展,也为整个视频理解领域带来了新的机遇。
Reference
[1] Dense-Captioning Events in Videos, ICCV, 2017
[2] Vid2Seq[2]: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning, CVPR, 2023















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









