







神经信息处理系统大会(Neural Information Processing Systems, NeurIPS)是国际人工智能顶会之一,今天为大家介绍通用视觉团队的中稿论文之一Foundation Model is Efficient Multimodal Multitask Model Selector,一作为我团队与上海交通大学的2023级联培博士孟繁青同学,指导老师 罗平教授,邵文琪博士。
模型优选,指的是给定数据集以及一簇预训练模型后,选择一个最适合的预训练模型可以在下游任务上微调后得到最好的结果。尤其在大模型蓬勃发展的今天,模型优选能作为多任务处理模型TaskMatrix 的高效API选择器。在迁移学习的框架下,一个最简单的手段是把所有的预训练模型全部进行微调,最后选择最适合的那一个,但是微调的时间与物力成本过高。所以这一任务的难点在于如何准确且高效的完成多个预训练模型的下游任务效果预测。现有工作 都聚焦于特定任务的模型优选,比如图像分类。且由于方法设计包括了任务的先验信息,无法有效的扩展到其他任务比如图像描述等。为了解决这个问题,我们提出EMMS(Efficient Multimodal Multitask Model Selector)。EMMS是一个高效的多模态多任务预训练模型选择器,可以快速为包括图像分类,图像描述,视觉,文本问答,视觉定位任务等任务选择最合适的预训练模型,已被NeurIPS 2023会议接收,代码已在Github开源。

论文:
https://arxiv.org/abs/2308.06262
代码:
我们的贡献主要如下
-
我们提出了一种通用的预训练模型的下游任务性能估计技术,即高效多任务模型选择器(EMMS)。EMMS配备了基础模型提供的统一标签嵌入和简单的加权线性平方回归 (WLSR),可以快速、有效地评估预训练模型在各种下游任务中的可迁移性。
-
我们提出了一种新颖的交替最小化算法,有效地求解WLSR,我们证明了该算法的收敛性并提供了算法的加速版本。
-
对 24 个数据集的 5 个下游任务进行的广泛实验证明了EMMS的有效性。具体来说,EMMS 在图像识别,视觉定位任务,图像描述,视觉问答和文本问答方面实现了 9.0%、26.3%、20.1%、54.8%、12.2% 的性能提升,同时与通过我们的标签嵌入增强的最先进方法LogME 相比,带来 5.13×, 6.29×, 3.59×, 6.19× 和 5.66× 的加速。
-
相比于其他方法,EMMS首次实现了通用的多任务多模态模型优选算法。
方法详述
在本节中,我们介绍高效多任务模型选择器(EMMS)。我们认为统一多任务模型优选问题的关键是统一不同任务中的标签格式,为了克服标签格式多样化的困难,EMMS 采用基础模型将各种标签转换为的统一标签嵌入。通过将多个基础模型提供的标签嵌入视为真实标签的噪声版本,EMMS 可以在简单加权线性平方回归(WLSR)框架下计算可转移性度量。同时我们设计了一种交替最小化算法来有效地求解 WLSR。
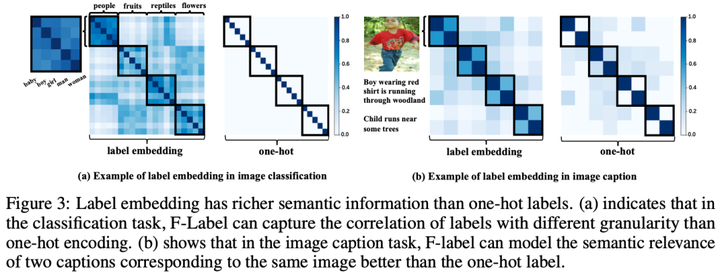
标签嵌入
一般来说,标签嵌入应该对语义信息进行编码,使得语义相似度较低的两个标签被分组的机会较低。 一种常见的方案是将 标签z表示为 one-hot 向量。 然而,one-hot 表示无法在图像描述任务中的文本格式的标签等。所以 我们将不同格式的标签视为文本序列,可以通过预训练的基础模型进行编码,记为F-Label。 与one-hot 标签相比,F-Label 具有多项优势。 首先,它嵌入了比one-hot标签更丰富的语义信息,从而可以准确地建模不同标签之间的语义关系。其次,与one-hot 标签相比,F-label可以在多种任务中获得。 我们使用多个基础模型提取F-label,借助F-Labels,可以在多任务场景下建立模型选择。
加权线性回归


求解算法以及加速算法
上述的优化问题可以表述为经典的二阶锥规划(简称为SOCP )。 然而,我们问题中的过多数据导致变量维度过大,导致标准求解器效率低下。所以,我们希望找到问题的平滑结构并设计交替最小化算法以实现快速计算。 如下图算法所示,我们分别固定 和 来优化另一个,直到函数值收敛。 具体来说,当我们固定时,整个问题就退化为关于的最小二乘问题。 当我们固定时,我们还需要在单纯形约束下解决关于的最小二乘问题。
虽然图中左边算法保证了收敛,但是由于两级循环,有点耗时,我们优化了这部分,并在很短的时间内达到了类似的结果。由于最小二乘解非常快,我们对 和 执行最小二乘,然后迭代地用显式 Sparsemax 变换替换单纯形上的投影。 快速求解器在下图算法(右)中进行了说明。 我们通过实验验证了其收敛性,并发现该方法实现了令人印象深刻的加速并且同样具备很好的效果。

实验结果
我们在不同的下游任务上评估我们的方法 EMMS,包括图像识别,视觉定位任务,图像描述,视觉问答和文本问答等,此外我们进行了详细的鲁棒性分析研究来分析我们的 EMMS。我们采用作为评价标准,其主要关心序列预测的准确性;参考标准是将预训练模型在给定下游任务上微调后按照结果排列的顺序,如果预测的顺序与参考标准越相似,则越高,计算公式如下:
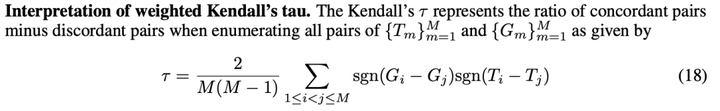
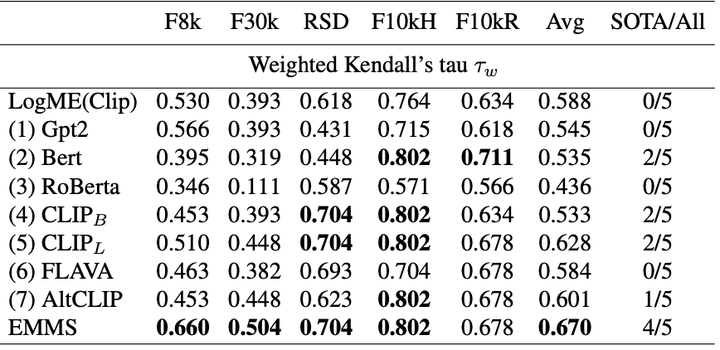
如表1所示,我们的EMMS在相对较短的时间内在11个目标数据集上实现了最佳平均,在9个目标数据集上实现了最佳。 例如,EMMS 在 Aircraft 和 VOC2007 上的排名相关性 分别优于 LogME 0.182 和 0.139,这表明我们的 EMMS 在测量预训练 ViT 模型的可迁移性方面的有效性。

如表 2 所示,每个数据集的 EMMS 在时间和效果上均明显领先于基线。 例如,EMMS 的性能优于 LogME,在 Flickr8k 和 Flickr30k 上的排名相关性 分别相对提高了 39% 和 37%。 此外,在这两个数据集上,EMMS 的时间相对于 LogME 减少了 83.7% 和 79.8%,这表明了我们算法的效率。 五个数据集的平均等级相关性 为 0.64,这表明 EMMS 有足够的置信度。

类似地,如表 2 所示,EMMS在文本问答以及视觉定位任务任务上, 在时间和效果上均明显领先于基线。

我们研究仅提供单一基础模型时 EMMS 受到的影响。 为此,进行了图像分类和图像描述的实验。 如表4所示,我们考虑使用单一基础模型的 EMMS,我们有几个观察结果。 (1)不同的下游任务更喜欢从不同的基础模型获得的F-Label。 没有一个基础模型在所有目标任务中占主导地位。 特别是,CLIP 并不是提取 F-Label的最佳模型。 (2) 对于图像描述任务,多模态基础模型比语言基础模型更适合提取 F -label。 (3)我们的EMMS可以通过结合从多个基础模型获得的F-Label来达到最佳结果。
与GPT4对比
我们将模型优选任务的定义,数据集的描述(包括数据集的规模,数据集包括的场景等),待选择预训练模型的描述(包括模型架构,常用领域,具体的组成等),发现根据纯文本信息,GPT4无法成功的完成模型优选任务,甚至其选择的结果是完全错误的。例如对于CIFAR10数据集的CNN预训练模型的模型优选,根据微调后的结果,其表现最好的预模型应当是ResNet-152,EMMS正确预测出了表现最好的模型是ResNet-152,然而GPT4预测最好的前三个模型分别是MobileNetV2,MobileNetV1,ResNet-34。本应该是效果最好的预训练模型ResNet34被GPT4预测到了最后一位。可见GPT4无法处理模型优选任务,说明了该任务的重要性,以及我们方法的必要性,有效性。

总结
如何快速有效地针对不同任务选择预训练模型是迁移学习领域的一个重要问题。本文提出了一种高效的多任务模型选择器(EMMS),可以应用于多种类型的任务。EMMS 使用标签嵌入的基础模型,以便将不同任务的不同标签格式转换为相同的形式,并将它们视为噪声标签。为了估计模型的可转移性,EMMS 将此问题建模为简单的加权线性回归,可以使用交替最小化算法来解决。与现有方法相比,EMMS首次实现了多任务场景下的模型选择,包括图像描述、问答和视觉定位任务等,速度快,效果好。
论文:
https://arxiv.org/abs/2308.06262
代码:















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









