







本文作者:谢志军,某互联网金融证券公司,算法工程师
写在前面
YOLO系列模型实现了对现实世界广泛物体的边界框识别,最新的开源多模态大模型(MLLM)/视觉语言模型(VLM)宣称能够给出特定物体的边界框坐标。笔者测试了一些常规图片并询问MLLM图中常见物体,如动物、车辆等,基本都能识别出来,给出物体之间大致的位置关系。
不同于YOLO单薄的模型层,MLLM的vision encoder的transformer层通常较厚,且较好地对齐了大模型LLM的token表达,因此对复杂的图形或人为定义图形,可能存在潜在的识别定位能力,如果猜测成立,后面必将产生许多非常有意思的应用。
捕获启明之星
老股民都知道股市行情里的K线图,K线图里的启明之星(又称早晨之星、黎明之心、希望之星)正如字面含义一般给人光明之感。哪些股票在忍受着黎明前的黑暗,哪些看到了上涨的曙光,从过往到近期的股价表现,你需要一双阅遍千股的眼睛。现在我们用多模态大模型打造这双慧眼,从繁杂的K线图中找到最亮的启明之星。
笔者根据某股一个月内的股价信息构造了K线图形态数据,看微调后的MLLM能不能捕获启明之星。
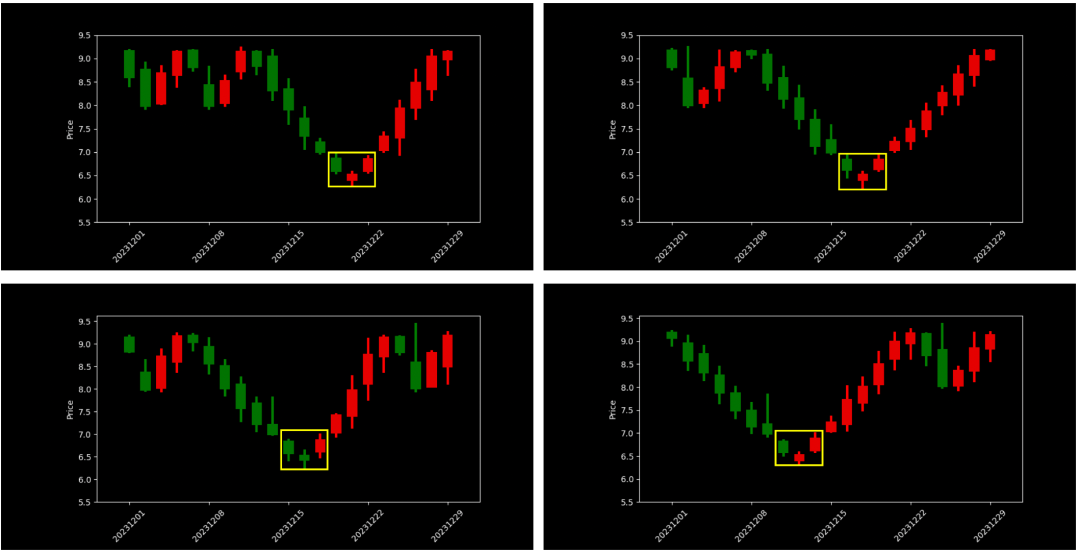
显然,MLLM能干这活。
图片尺寸与边界框识别
从事后诸葛亮的角度看,一开始的时候,笔者测试众多MLLM,要么只能输出图形的大致方位或位置的比例关系,要么输出的边界框坐标错的离谱,驴唇不对马嘴,始终不能给出准确的边界框坐标。
笔者重新审视了一般开源MLLM的视觉编码过程:在InternVL2多模态大模型的图片编码过程中,一张图片选择最佳的预定义切割比例成小patch,分辨率不满足ViT要求大小的会适当变形拉伸至其倍数(有些MLLM是填充token至其倍数),再加上原图缩小的比例图,共同输入vision encoder作为图片特征信息。
可以发现,原图和小patch拼接回去的图片已经不一样了,意味着MLLM看到的图片与原图有一点点形变上的不同,因此MLLM输出的边界框坐标相比原图产生了位移,这是导致边界框坐标不准确的根本原因之一。
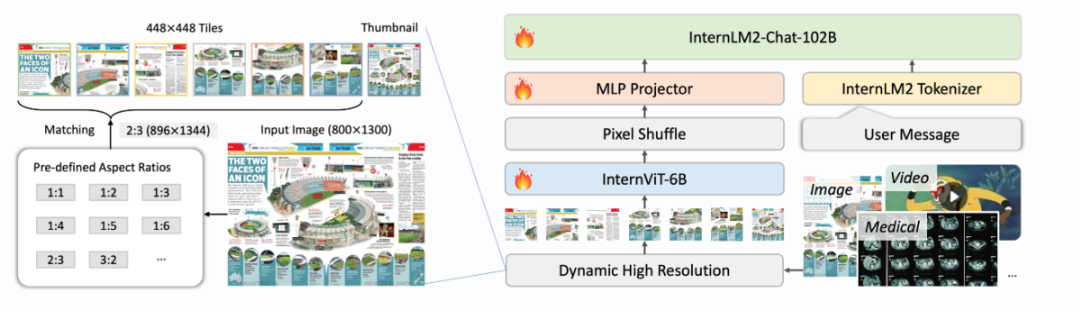
(论文地址:https://arxiv.org/pdf/2404.16821)
第二代的MLLM通常支持任意长宽比或分辨率,对于MLLM推理普通图片和定性描述prompt来说,图片尺寸是否严格符合ViT要求大小的倍数并不重要,例如图片中的一头熊,即便稍微拉伸变形,只要满足熊的体态特征,预测时大概率就还是熊。
对于精度要求比较高的边界框识别来说,任何拉伸变形,除非能找到图片encode完整forward过程的变形参数,才能将预测出的边界框坐标进行backward还原,获得最终正确的边界框坐标。
为了不跳入这个坑再从坑里爬起来,笔者直接使用符合ViT要求大小倍数的图片进行训练和推理,这样就不涉及变形之说了。
以上是本文的背景知识和目标工作,下面进入实战环节。
准备工作
MLLM选择
考虑在合适的prompt下,MLLM宣称能识别图中实体并能输出准确坐标,即边界框识别。因此我们构造特定领域的图文对话数据集,微调MLLM,以使其获得该领域的精准识别能力。
笔者对比了多模态大模型(截止时间2024-09-26)各项能力,综合训练和部署框架,最后选择InternVL2系列模型。

为什么是启明之星
为什么是启明之星,或者为什么要识别K线图的某个特定形态。
一般的,有哪些知识喂给模型,模型就拥有哪类知识。
大多MLLM对封闭图形的描述识别和边界框识别能力,在构造训练数据时就已经有意无意间覆盖了。封闭图形,例如动植物、车辆、行人、生活用品等具体实体,是我们身边常见物体,同时相当一部分的LLM世界知识也关注于此,从图形的易得性和LLM知识的关联性,MLLM天生对这些封闭图形的理解比较深刻。
对开放式图形,除了MLLM刻意强调文字识别OCR能力而喂足了数据集,MLLM对于人为定义的开放式图形的识别能力,是否会因缺乏训练数据量而打折扣,或者由强大的泛化推理能力补足了知识缺陷,需要我们进一步验证。
同时,常规的多模态测评数据[1],考虑了样本的代表性和全面性,人为定义的开放式图形相当于某个垂直领域,用常规测评集很难反映MLLM在垂直领域的能力。
本文选择了K线图的启明之星[2]形态,考察MLLM在这类特定图形领域的边界框识别能力。
K线启明之星,形态特点:启明星包含三根k 线,第一根k 线是一根长实体的阴线,第二根k 线为向下跳空的小实体k 线,阴阳线、十字星均可。第三根k 线是一根实体阳线,且收盘价显著地向上穿入第一根阴线实体的内部,这就是典型的启明星形状,被视为底部反转的信号,所以启明星又称之为早晨之星、黎明之心、希望之星。
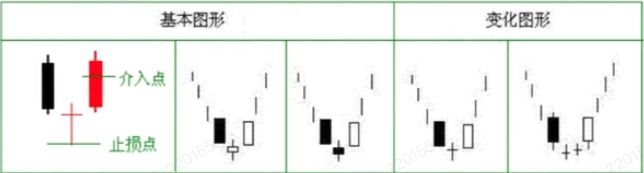
避免人工标注图片
后知后觉的看,全参微调MLLM,训练数据量在千以内,效果比较差。这意味着训练的图文数据,如果是由人工标注的少量样本,对实验效果将是一场灾难。如果你不是土豪,没有标注团队,用不起GPT4等高贵LLM来审核,最重要的,你没有时间和精力来统筹一切,就避免人工标注这个活吧,尽可能的自动化构建数据集。
自动化构建数据集,很容易保障边界框坐标的准确性,但缺乏多样性。为了尽可能提升多样性并保证准确性,本文根据启明之星的形态特点,模仿真实K线数据和走势,设计了三种K线形态:一折二折三折。
一折二折三折
所谓一折二折三折,是一种对K线三种特定走势的动态随机模仿,包括:
-
随机选择一折(一个谷底)三种形式、两折(两个谷底)两个形式、三折(三个谷底)三个形式
-
随机生成21天股票价格数据(包括开盘价、收盘价、最高价和最低价),限定价格波动范围
-
随机滑动启明之星的时间窗口,规避极值,保证启明之星左侧或右侧至少有2天的数据
-
随机选择启明之星谷底形态:阳线、阴线、阳十字线、阴十字线
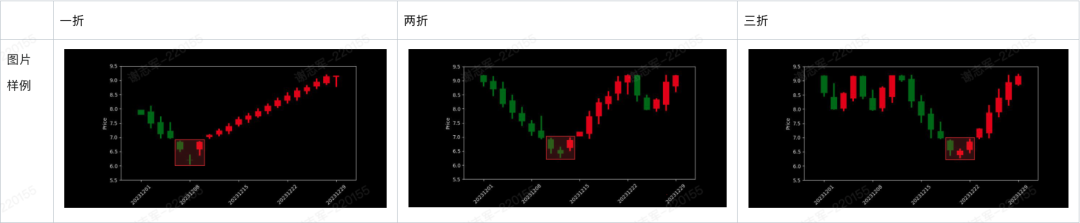
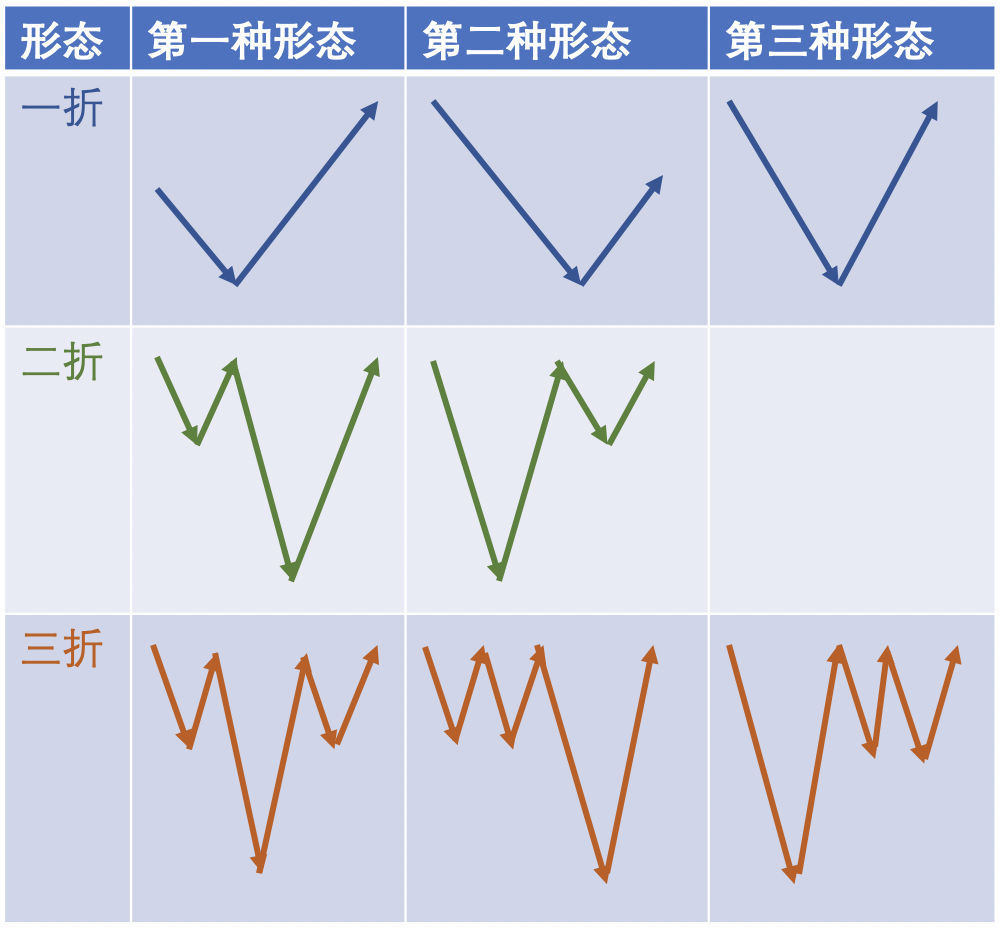
真实的股价走势数据远比想象的疯狂,有时最高价上影线或最低价下影线非常突兀,阳线或阴线时大时小,从一幅画或照片的角度看,显得非常杂乱。本文构建了一种比较中庸的K线走势,让人一目了然,也方便MLLM从中辨别。
构建好股价数据后,本文使用mplfinance显示并保存K线图。
mplfinance设定背景色、阳线与阴线的颜色、上影线和下影线的线宽、横纵坐标轴的上下限,统一设置图片大小为896x448的png格式。
文本对话数据
本文构建的文本对话数据共4万条,下面是一个样例:
{
"id": 0,
"image": "path_to_picture",
"width": 896,
"height": 448,
"conversations": [
{
"from": "human",
"value": "<image>\nAs a stock analysis expert, the user has provided you with the K-line chart pattern. Please identify the coordinates of the bounding box for the region: <ref>启明之星</ref>"
},
{
"from": "gpt",
"value": "<ref>启明之星</ref><box>[[550, 249, 630, 309]]</box>"
}
]
}通过启明之星指定MLLM要识别的K线目标形态,[[550, 249, 630, 309]]说明了该K线形态在图片中的坐标位置,其中前两位坐标(550, 249)是左上角坐标,后两位坐标(630, 309)是右下角坐标。
human角色的提问,随机在多样的中英文prompt生成。每个图片样本只有一轮对话。
实验情况
开启训练
笔者使用InternVL2自带的训练框架[3]。
在一台8卡A800 GPU服务器上分别训练InternVL2-8B和InternVL2-26B。

实验效果
经过几个小时的等待,模型全参微调完成,更新模型配置文件后,用LMDeploy部署InternVL2。
笔者挑选了部分新图片,选择不同prompt来让微调后的InternVL2预测启明之星的边界框坐标,效果见下表。
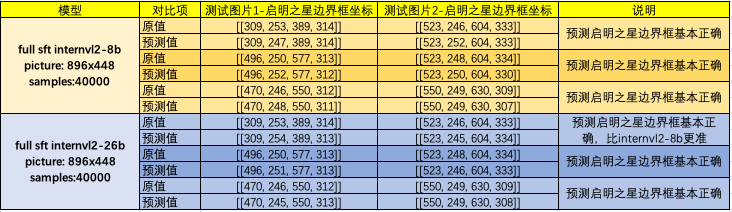
小结:
-
InternVL-8B和InternVL-26B基本能够准确识别启明之星的边界框坐标位置
-
InternVL-8B识别误差像素在0-6个内
-
InternVL-26B识别的更为精准,误差像素在0-2个内
不足之处
限于时间精力,本实验还有很多不足之处,包括但不限于:
-
实验选取的周期为21天,相对较短
-
多样性缺乏
- K线形态预测结果单一,均为预测一个启明之星,而不是预测多个或零个,或其他K线形态
- 训练集图片中启明之星为一个,缺乏多样性
- 启明之星左右的K线形态变化不够多(一折、二折、三折变化仍有限)
- 单边上涨或单边下降的形态,波动变化不够大(胆子不够大,变化要靠想象)
- 单边变化的形态可能有红三兵,这里也可以进行训练数据集构建、训练和预测
思考
通过上面的实验,基本验证了多模态大模型MLLM对开放式人为定义图形的边界框识别能力,有心的小伙伴可以此来做很多有意思的工作,本文抛砖引玉,乐见多模态大模型造福生活。
同时,对K线形态启明之星的边界框坐标识别,如果将来能够工程化和扩大化,有助于:
-
自动识别股票K线图的各类特定形态,形成对股票一段时间内的股价波动表现的客观准确描述,有利于C端客户根据K线图进行股价操作;
-
根据生成的股票股价K线形态描述,将图片特点转为文字,为后面以(K线)图搜(K线)图做好基础工作,实现精准搜索;
-
联动MACD、KDJ等股票技术面分析,实现股票量化因子自动化挖掘。
最后
在本实验结束后,笔者发现choice客户端,在指标管理-系统指标-五彩K线,已有K线形态定位。
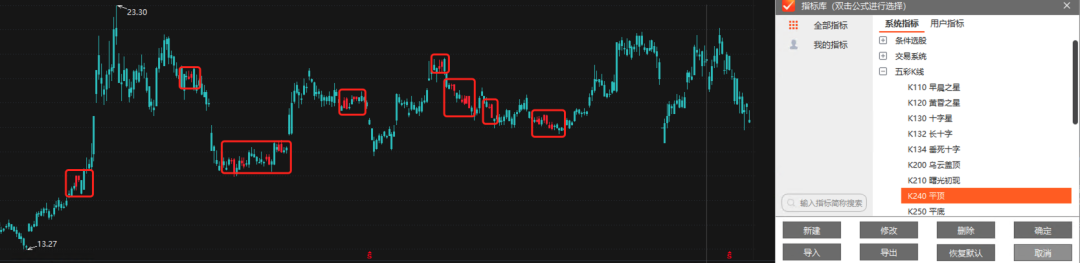
图 choice客户端的K线形态定位,红框是另外加上的
那么问题来了,这是一个新的机会吗?
参考资料
[1] 多模态测评数据:
https://zhuanlan.zhihu.com/p/701404377
[2] 启明之星:
https://baijiahao.baidu.com/s?id=1709778049770861821&wfr=spider&for=pc
[3] InternVL2自带的训练框架:















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









