










CUDA硬件实现分析(二)------规行矩步
------GPU的革命
序言:换位思考。当今的生活,节奏快,任务忙。慢慢的忽略了身边的很多事,很多人。再加上接受“高等”教育的人越来越多,“有自己思想的”人越来越多,慢慢的都习惯从自己的思维角度来思考问题,尤其是读工科的学生更是喜欢按照自己的角度来思考问题。慢慢的忽略了换位思考。有很多朋友说学工科的人都喜欢走极端。或许这个就像金庸小说里面少林高僧给两个偷学少林武功的人的建议。在忙碌的生活和紧张的工作中,找个时间,能让自己停下来,想想做过的事情,让自己忙碌的脚步,休息一会儿。往往在team开发中,遇到问题的时候,就需要沟通和交流,但是沟通和交流的基础就是换位思考。在一个平等的环境中的沟通和交流才能算真正意义上的思想的交流。其实学工科的时候有一个小窍门,那就是找规则。有既定的规则,那就是定理和定义。如果你能找到新规则,那就是新发现,可以写paper。我们遇到新东西的时候,也最好在自己的既有思维中找到影子,找到相同的规则。这样就可以很好的学习新东西。不过往往学工科的思维比较有规则性,在加上平时看的工科的书都是规则性太强,长此以往很容易形成偏执的性格。平时就需要多看一些能扩展思维的书籍,或许能消减一些戾气吧。
正文:前面已经讲解了很多概念上的东西,其实CUDA的最重要的两个东西,就是线程和内存。只要掌握了这两个东西,CUDA的东西也就很简单了。它的编写语言是C扩展的,所以,就当C语言用就行了,只是主要它的特殊的几个标志就ok了。前面讲解了线程和内存的模型,大概,应该,似乎,可以在你的脑海里面有一个概念了吧。只要有这个概念,我的文章的目的就达到了。前面的《CUDA硬件实现分析(一)------安营扎寨-----GPU的革命》已经讲解了线程在CUDA的具体运行过程。下面我们一起来看看内存在CUDA的硬件实现中的一些规定。这也比较合理吧,大军安营扎寨了,就应该颁布规则制度,只有了解CUDA的规则制度,才能真正的把各个线程都管理好。才能在这个平台上让程序高效的运行。
这里我们先明确几个
一.Threads,Warps, Blocks 1. 一个warp最多有32个threads。只有在总线程少于32的时候,才可能在一个warp里面少于32个线程。 2. 每一个block最多有16个warp。就是说一个一个block里面最多有512个thread。 3. 每一个Block在同一个SM上执行,也就是同一个block的warp都在同一个SM上运行。 4. G80有16个SM。 5. 所以最少16个blocks才能占全所有的SM。 6. 如果资源(看看前面讲解的线程都要从device哪里分什么资源)够线程分,一个SM上面可以跑多余一个block的线程。就是同时可以跑2个,3……个block的线程。
二.访问速度 Register—HW 一个时间周期 Shared Memory------HW一个时钟周期 Local Memory --- DRAM,no cache,慢 Global Memory --- DRAM, no cache,慢 Constant Memory --- DRAM, cached, 1……10s……100s个周期,这个和cache的locality有关。 Texture Memory --- DRAM,cached, 1……10s……100s个周期,这个和cache的locality有关。 Instruction Memory(不可见)--- DRAM,cached
三.CUDA程序架构 如图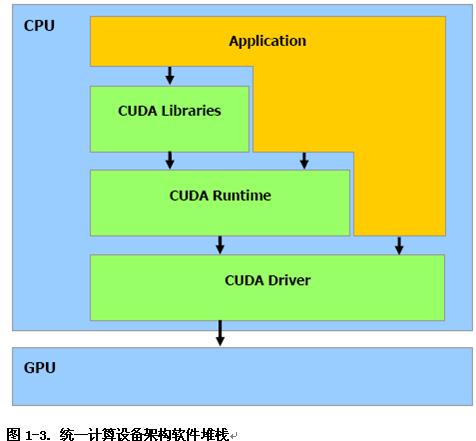
四.语言扩展 单从学习语言来说,我到觉得应该精学一种,然后其他的就触类旁通了。在学习新语言的时候,要想快速的入门,也有诀窍。1.变量的定义方式。2.函数的定义方式。3.逻辑控制方式(if,loop……)。只要把这3个东西弄明白了,管他啥新的语言,20分钟就可以入门……然后入门都可以了,那要慢慢的更入的研究,那就得看你对这门语言的了解了。其实万变不离其中。其实从计算机编程语言的角度出发,就是定义一些数据,然后对数据进行操作,so……学习语言就从这个角度入手,那就很简单了。像java或者C#等一些语言比C语言多的新的特性不外乎就是方便你开发而已。
所以我们这里再来说说CUDA的语言,不外乎就是扩展了C语言,为了方便在GPU显卡上运行,规定一个特定环境。就定义一些特定的变量,说明他们是在GPU上的。这里有说明内存,和函数,是在GPU上的……so,这样一来,CUDA就扩展了C语言的变量分配定义和函数定义。
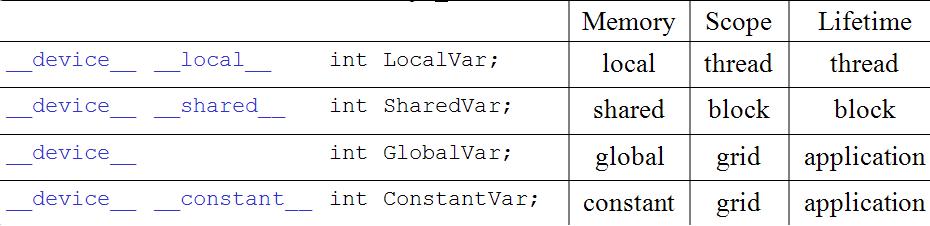 上面这张图是来之Fall 2007 syllabus,上面已经说得很清楚各个变量定义的时候的位置和生存周期。其实就是在C语言的常规变量的时候,定义了变量的位置而已。
上面这张图是来之Fall 2007 syllabus,上面已经说得很清楚各个变量定义的时候的位置和生存周期。其实就是在C语言的常规变量的时候,定义了变量的位置而已。
其中有一个约束限制,就是指针变量,在kernel里面的指针变量,只能指向从global上面分配的内存。
五.内建的变量 所谓内建,就是CUDA自己在kernel里面定义的一些变量。就像我们以前计算线程id的时候,就利用了他的自己的变量,dim3 gridDim;dim3 blockDim;dim3 blockIdx;dim3 threadIdx;注意gridDim,他的gridDim.z在现在的CUDA1.1版本中没定义。 内建变量,[u]char[1..4], [u]short[1..4], [u]int[1..4], [u]long[1..4], float[1..4] 就是构建了有4个变量的struct; uint4 param; ---》等价位一个struct里面有4个int。 int y = param.y; dim3 就是unit3这样的struct。
六.通用的数学函数
· pow, sqrt, cbrt, hypot
· exp, exp2, expm1
· log, log2, log10, log1p
· sin, cos, tan, asin, acos, atan, atan2
· sinh, cosh, tanh, asinh, acosh, atanh
· ceil, floor, trunc, round
但是这里要指出,有几个函数是不精确的,但是可以很快的运行:
– __pow
– __log, __log2, __log10
– __exp
– __sin, __cos, __tan
七.在host部分的运行库(CUDA Runtime )
1. 提供Device管理的api(有多个显卡的时候怎能来设置,这里我们还没讲当多显卡并行运行库)
2. 初始化调用的Runtime函数
3. 每一个host的线程(thread)只能调用一个device的函数在一个device上运行。就是同时不能有几个host(主机)线程在调用同一个device上的运行函数。
八.内存管理函数 我们讲了那么多的内存,下面就来看看到底是什么样的函数:
– cudaMalloc(),cudaFree();内存分配和释放(device上的)
– 内存copy:cudaMemcpy(), cudaMemcpy2D(), cudaMemcpyToSymbol(), cudaMemcpyFromSymbol();
九.线程同步函数
void __syncthreads();
同步同一个block里面的线程,让block里面的线程都允许到这一点的时候,就等待同一个block里面的其他线程,就像军训的时候,大家吃饭吃完了还不能一个个走,必须得一个桌子的人都吃完了才能走。还得列队一起走,呵呵,这就是同步。所以最好保证每一个kernel里面的处理都是很快的,这样才不会让其他thread等待太久,不然会挨骂的 - -!hoho
哥们来点实际的吧- - 肯定很多人都这么在吼了。嘿嘿,下面让我们看一段代码,example里面的transpose:
#define
BLOCK_DIM 16
// This kernel is optimized to ensure all global reads and writes are coalesced,
// and to avoid bank conflicts in shared memory. This kernel is up to 11x faster
// than the naive kernel below. Note that the shared memory array is sized to
// (BLOCK_DIM+1)*BLOCK_DIM. This pads each row of the 2D block in shared memory
// so that bank conflicts do not occur when threads address the array column-wise.
__global__
void transpose(float *odata, float *idata, int width, int height)
{
__shared__ float block[BLOCK_DIM][BLOCK_DIM+1]; //(1)
// read the matrix tile into shared memory
unsigned int xIndex = blockIdx.x * BLOCK_DIM + threadIdx.x;
unsigned int yIndex = blockIdx.y * BLOCK_DIM + threadIdx.y;
if((xIndex < width) && (yIndex < height)) // (2)
{
unsigned int index_in = yIndex * width + xIndex;
block[threadIdx.y][threadIdx.x] = idata[index_in];
}
__syncthreads(); //(3)
// write the transposed matrix tile to global memory
xIndex = blockIdx.y * BLOCK_DIM + threadIdx.x;
yIndex = blockIdx.x * BLOCK_DIM + threadIdx.y;
if((xIndex < height) && (yIndex < width))
{
unsigned int index_out = yIndex * height + xIndex;
odata[index_out] = block[threadIdx.x][threadIdx.y];
}
}
是不是在代码面前都感觉是那么的亲切啊~嘿嘿,有时候看算法的书看久了以后,看到代码实现,那才叫亲切啊>_<!
下面对加红的3处代码分别讲解:
(1) shared__ float block[BLOCK_DIM][BLOCK_DIM+1]; 为啥要用shared啊?知道为啥不,快啊~shared在block里面,是大家公用的,不用再从global哪里调换。还记得军训的时候食堂吃饭的时候那个内存讲解吗?桌子上的菜,肯定比你从中间几个桶里面去拿菜要快啊~
(2) if((xIndex < width) && (yIndex < height)) 由于CUDA在生成线程的时候,是一块一块的生成的,所以有的时候,x和y有可能越界。数据都是均匀的分配到每一个block里面去的,很可能就会出现有的blcok里面分配到的数据不一定完整,要是想不明白的(先画图想想),等后面的章节,举例子说明。
(3) __syncthreads(); 同步,就是等每一个thread都运行到这里的时候,再接下来运行。这里也避免了数据访问的冲突。
(4) 还有一个得讲讲,为啥下面的还重新计算一下x和y,因为线程被挂起来了以后,重新进入warp的时候,分配的id就不一定是一样的了。这里就有点像铁打的营盘流水的兵,每一波人都可以分配到同一张桌子吃饭,但是不一定是上一波人了~。碗筷还是那些碗筷,位置还是那个位置,坐的人不一样了。(-----第四条是错误的,呵呵,好好想想,不然就看回复)
上面的都是C语言扩展库的东西,就是说,这些是扩展C语言的东东,只要是基于C语言的规则都可以运行的,不管是host还是device。
好了,今天要讲的部分应该差不多了,要是再写多一些,或者就有会像手册第4章那样,看了一半很多人就不想看了~- -!太长,lz 帖子太长,顶lz- -!我可不想看到这样的留言,hoho~
从小到大,我们听过好多规则,但是好多时候听进去的有多少?很多玩游戏的人,游戏的规则都不清楚- -ps,俺现在还不清楚StarCraft里面的某些兵的战斗力是多少 - -!就玩- -!小小的bs一下自己。只是为了消遣罢了·
我始终觉得自己不适合玩游戏,我也知道自己玩游戏不会完成专业玩家,so~还是老老实实做自己的工作,做一些能养活自己的事情,或许能让自己更充实一些。在游戏里面充实以后,或许在现实中就会空虚了- -!到时候就不是游戏人生,那就是人生被游戏了。呵呵。想起高中的数学老师,虽然在很多journal上发表了文章,也自己出版了数学的几本书了。但是和别人打麻将的时候总是输多赢少。问他为啥数学这么厉害,玩麻将不行~他说,我玩麻将的时候只是消遣,根本就没用脑袋想麻将这回事。
或许我们做事情的时候,就应该专注做自己的一些方面吧,只要坚持下来做了,做好了,做精了,那就够了。小时候就从长辈哪里听到,半灌水叮当响这样的词,或许我们更应该低调做人,高调做事吧。
Ps:说得都有点多了- -就当消遣。俺熬夜写这个也不容易啊,哈哈~>_<!lz,又没人逼你写。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









