







规约问题
串行规约问题
问题分析
首先来分析一个简单的规约问题,假设我们此时有一个简单数组
size=8;
int array[size]={1, 2, 3, 4, 5, 6, 7, 8};
我们的目的是计算数组的和,也就是array[0]+array[1]+…+array[9],一般可以用如下简单的循环实现
int i;
int sum = 0;
for(i=0;i<size;i++)
{
sum+=array[i];
}
printf("%d",sum);
/* output: 36*/
我们可以思考一下,如果使用递归呢?你会怎么实现。
我们可以将这个长度为10的数组思考成一堆节点
将这棵树反过来看(从上往下看),则我们要将一个长度为8的数组进行规约相加。
第一步:先计算数组的依次两个位置的和,即相加8/2=4次
array[0]+array[1]=3
array[2]+array[3]=7
array[4]+array[5]=11
array[6]+array[7]=15
我们将他们按照顺序保存在原数组中,也就是
array[0]=3
array[1]=7
array[2]=11
array[3]=15
第二步:按照第一步的方法接着计算,此时只计算下标0-4,
也就是
array[0]=array[0]+array[1]=10
array[1]=array[2]+array[3]=26
第三步:仍然按照之前的方法,也就是
array[0]=array[0]+array[1]=36
得出结果
串行代码实现过程
以此类推,我们可以定义一个范围值为int函数recursiveReduce,这个函数的参数如下
int recursiveReduce(int *data,const int size)
那么按照我们分析的思路,要想计算前size个值规约总和得先计算前size个的前一半和后一半的值的规约总和并相加,我们可以开始写我们的函数体了。
1.我们很容易想到如果数组的长度为1,那么这个函数的返回值很明显就是数组的第一个元素,那么可以如下
int recursiveReduce(int *data,const int size){
if(size==1){
return data[0];
}
}
2.我们现在开始按照之前的思路开始进行第一步操作,也就是将数组的相邻元素两两相加,相加size/2次,并保存在数组的前一半
int recursiveReduce(int *data,const int size){
if (size==1){
return data[0];
}
int const stride =size/2;
for (int i=0; i<stride;i++)
{
data[i]+=data[i+stride];
}
}
3.仍旧按照之前的分析,我们按照第二步程序运行完后,需要做的是计算第二步也就是将数组前一半的元素相加再保存到前一半的前一半位置的数组中,那么可以接着补充函数,最后得到总代码
总代码
int recursiveReduce(int *data,const int size){
if (size==1){
return data[0];
}
int const stride =size/2;
for (int i=0; i<stride;i++)
{
data[i]+=data[i+stride];
}
return cpuRecursiveReduce(data,stride);
}
并行规约
关于GPU的grid和block的概念
首先在gpu中,我们需要阐明一些关于grid和block的概念
在gpu中,线程是按照如图所示的块保存的

在GPU的一个kennel中有若干的gird,一个grid中有若干个block,具体数量需要在代码中自己设置,grid和block的极限数量与GPU的硬件配置有关系。
我们先讨论一个grid以及grid中的一个block
在一个gird中可以有若干个block,可以通过blockIdx.x和blockIdx.y来得到block的在一个grid中的坐标
而在一个block中可以有若干个thread,可以通过threadIdx.x和threadIdx.y来得到thread在一个block中的坐标
借助GPU这个特性,我们可以通过thread的坐标,来区分每个thread,并给他们分配不同的任务
普通并行规约问题
我们先思考最简单的情况
我们有一个grid,一个gird中只有一个block,一个block里只有一行thread,一行正好有8个thread
也就是如图所示
我们可以分配任务,将数组位置i和位置i+1相加的任务分配给thread i,例如要将值保存到array[0]+array[1]的任务分配给thread0,要把将值保存到array[2]+array[3]的任务分配给thread2。并且为了之后运算的方便,与串行不同,我们决定将每次相加得到的和存放在数组下标等于线程下标的地方,也就是array[0]=array[0]+array[1],array[2]=array[2]+array[3]
可以通过查看下图,更直观的体会任务的分配
对于部分线程的浪费(未使用)我们先不予理睬之后再解决
普通并行代码简单实现过程
有了线程任务分配的思路我们就可以开始写我们的代码了
首先在main函数中分配数据空间,并设置我们grid和block的尺寸。
/* 设置grid和block的尺寸 */
dim3 block(8,1);
dim3 gird(1,1);
int dataSize=8;
int nBytes=dataSize*sizeof*(int);
int *d_data,*d_odata,*gpuRef,h_data;
/********************************************
* 我们使用d_data保存数据
* 用d_odata保存规约的最终结果
* 为了对比结果的正确,我们需要与串行的结果进行对比
* 所以分配了h_data来保存串行的数据
* 以及gpuRef来接受GPU的最终结果
*
* cudaMalloc为 GPU的内存分配方法
********************************************/
cudaMalloc((void **)&d_data,nBytes);
cudaMalloc((void **)&d_odata,sizeof(int));
h_data=malloc(nBytes);
gpuRef=malloc(nBytes);
int i;
/* 让h_data[8]={1, 2, 3, 4, 5, 6, 7, 8} */
for(i=0;i<dataSize;i++){
h_data[i]=i+1;
}
/* GPU的数据复制方法 */
cudaMemcpy(&d_data,&h_data,nBytes,cudaMemcpyHostToDevice);
然后编写我们的GPU规约函数
__global__ void reduceNeighbored(int *g_idata,int *g_odata,unsigned int size);
由参数名很容易得知参数的含义
g_idata: 表示全局的包含数据的数组指针
g_odata: 表示全局的用来保存结果的数组的指针
size: 表示包含数据的数组的长度
我们按照我们的任务分配一步一步来,首先要得到线程的位置,然后才能通过下标来分配任务
__global__ void reduceNeighbored(int *g_data,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
}
简单重新思考一下串行时的计算过程
第一步:先计算数组的依次两个位置的和,即相加8/2=4次
array[0]+array[1]=3
array[2]+array[3]=7
array[4]+array[5]=11
array[6]+array[7]=15
我们将他们按照顺序保存在原数组中,也就是
array[0]=3
array[1]=7
array[2]=11
array[3]=15
第二步:按照第一步的方法接着计算,此时只计算下标0-4,也就是 array[0]=array[0]+array[1]=10
array[1]=array[2]+array[3]=26
第三步:仍然按照之前的方法,也就是
array[0]=array[0]+array[1]=36
得出结果
那么在并行中,我们可以通过循环来规划三个阶段
__global__ void reduceNeighbored(int *g_data,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
int i;
for(i=0;i<3;i++){
//thread(tid)在第i阶段的操作
}
}
我们可以很容易的发现规律,在第一次操作的时候线程的下标为2的倍数,第二次操作线程为4的倍数,第三次操作数为8的倍数。即第 i 次操作的线程下标应该为 2 i 2^{i} 2i的倍数,并且当三次操作结束之后规约的结果保存在g_data[0],那么很容易写出代码
__global__ void reduceNeighbored(int *g_data,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
int stride;
for(stride=1;i<blockDim.x;stride*=2){
if(tid%(2*stride)==0){
g_data[tid]+=g_data[tid+stride];
}
}
/* 我们设置thread0来进行结果的复制 */
if(tid==0){
*g_odata=g_data[0];
}
}
相信你一眼就能看出这段代码的问题,由于并行线程运行的不确定性,我们无法控制循环中所有线程所在的阶段保持一致。
很可能发生情况thread6所在的阶段stride还等于1,此时thread6还在计算g_data[6]+=g_data[7]
可是thread4所在的阶段stride=2,此时thread4已经在计算g_data[4]+=g_data[6]
这将会让结果与我们预期的并不一样。
好在NVDIA提供了一个原生的栅栏函数syncthreads用于线程的同步,对我们的代码进一步改进。
__global__ void reduceNeighbored(int *g_data,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
int stride;
for(stride=1;i<blockDim.x;stride*=2){
if(tid%(2*stride)==0){
g_data[tid]+=g_data[tid+stride];
}
/* 在每一步循环后加上栅栏,同步线程 */
__syncthreads();
}
/* 我们设置thread0来进行结果的复制操作 */
if(tid==0){
*g_odata=g_data[0];
}
}
普通并行代码的无耦合(关于grid和block的耦合)实现
考虑完简单的一个grid和一个block的情况我们现在要做的应该是降低耦合,现在假设我们的数据量一个长度为
2
11
2^{11}
211的一位数组,很显然GPU中的一个block中基本上达不到拥有这么多线程,那么我们就需要多个grid。
不妨设block中thread的数量为512,那么grid的数量应该等于
2
11
/
512
2^{11}/512
211/512,我们在程序中设置
dataSize=1<<12;
blocksize=512;
girdsize=dataSize/blocksize;
很显然这样会出问题,因为整型除法是向下取整,如果blocksize不是dataSize的约数,就会出问题
所以可以设置gridsize=(dataSize+blocksize-1)/blocksize;
和之前一样,现在main函数中分配数据空间,并设置我们grid和block的尺寸。并且由于我们grid的纬度不再是1,需要为我们保存gpu结果的数组分配空间,每一个位置保存一个grid得到的结果。
int size=1<<12;
int blocksize=512;
dim3 block(blocksize,1);
dim3 grid((size+block.x-1)/block.x,1);
size_t nBytes=size*sizeof(int);
int *h_idata=(int *)malloc(nBytes);
int *gpuRef=(int *)malloc(grid.x*sizeof(int));
int *tmp=(int*)malloc(nBytes);
int *d_idata=NULL;
int *d_odata=NULL;
for (int i=0;i<size;i++){
h_idata[i]=(int)(rand()&0xFF);
}
memcpy(tmp,h_idata,nBytes);
cudaMalloc((void **) &d_idata,nBytes);
cudaMalloc((void **) &d_odata,grid.x*sizeof(int));
cudaMemcpy(d_idata,h_idata,nBytes,cudaMemcpyHostToDevice);
那么在规约的过程中,我们需要通过thread的下标来反应对应到需要该线程处理的数据下标,并且我们需要创建局部变量idata来指向所在block要处理的数据开始的地址。
对于指向地址,由于数据量不是特别大,在代码中grid和block的纵坐标纬度都为一维,所以不需要考虑block和thread的纵坐标y。
我们先讨论block0,0:很明显对应的开始坐标为数据的0,结束为511,也就是blocksize-1。
而block1,0:对应的开始坐标为数据的512,紧随block0,0指向的数据的结束。
按照如上规律很容易知道,指向的数据的开始的下标等于blocksize*block的横坐标
用代码实现也就是(blockDim.x表示block在x轴方向的纬度)
index=blockIdx.x*blockDim.x;
所以对应于每个thread,它的下标应该就是index+threadIdx.x
所以可以在代码中设置变量idx
int idx=blockIdx.x*blockDim.x+threadIdx.x;
我们可以通过以上的数据来确定idata所指向的位置应该等于
int *idata=index+threadIdx.x;
并通过thread对应的数据下标idx来判断是否溢出
if(idx>=size){return;}
函数完整代码如下
__global__ void reduceNeighbored(int *g_idata,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
unsigned int idx=blockIdx.x * blockDim.x+threadIdx.x;
int *idata=g_idata+blockIdx.x*blockDim.x;
if (idx >= size){
return ;
}
for (int stride=1;stride<blockDim.x;stride*=2)
{
if ((tid%(2*stride))==0)
{
idata[tid]+=idata[tid+stride];
}
__syncthreads();
}
if (tid==0){
g_odata[blockIdx.x]=idata[0];
}
}
解决一些小问题
回忆之前的线程任务分配图
我们发现有很多线程并没有进行工作,术语中叫作线程束分化。
我们很明显发现,在所有阶段中对应数据数组下标不是2stride倍数的线程都没有分配到任务,那我们可以很轻易的修改代码,这次我们只设置一半的线程,并让这些线程对应的索引都乘2stride就好了,当然为了防止下标溢出,我们需要设置一个临界条件idx<blockDim.x。
改进代码为
__global__ void reduceNeighboredLess(int *g_idata,int *g_odata,unsigned int size)
{
unsigned int tid=threadIdx.x;
unsigned int idx=blockIdx.x * blockDim.x+threadIdx.x;
int *idata=g_idata+blockIdx.x*blockDim.x;
if (idx >= size){
return ;
}
for (int stride=1;stride<blockDim.x;stride*=2)
{
int index=2*tid*stride;
if (index<blockDim.x){
idata[index]+=idata[index+stride];
}
__syncthreads();
}
if (tid==0){
g_odata[blockIdx.x]=idata[0];
}
}
嵌套递归并行规约问题
GPU动态并行
接下来讨论嵌套的并行化规约。
所谓嵌套其实就是递归,核心思想就是父线程调用出子线程。
如图所示:每一行表示一组同级线程,并且每一行的线程0会调出子线程
具体可以参考动态并行
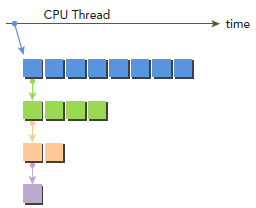
动态并行在规约中的使用
还是按照之前设置的blocksize为512,在每个grid中的第一阶段512个线程完成任务后,该grid中的thread0应该创建256个子线程来完成第二阶段的任务,以此类推,直到线程数等于1,那么就可以返回。
为了方便我们的代码,我们需要换一种规约思路以及任务分配思路,如下图
规约思路

任务分配思路
理清了思路就能很容易写出代码来
嵌套规约的代码如下所示
__global__ void gpuRecursiveReduce(int *g_idata,int *g_odata,const int iSize){
unsigned int tid=threadIdx.x;
int *idata=g_idata+blockIdx.x*blockDim.x;
int *odata=g_odata+blockIdx.x;
if (iSize==2 && tid==0){
g_odata[blockIdx.x]=idata[0]+idata[1];
return;
}
int iStride=iSize>>1;
if (iStride>1 && tid<iStride) {
idata[tid] += idata[tid + iStride];
}
__syncthreads();
if (tid==0){
gpuRecursiveReduce<<<1,iStride>>>(idata,odata,iStride);
cudaDeviceSynchronize();
}
__syncthreads();
}
为了保证线程同步多次用到了__syncthreads()函数,读者可以自行体会一下每一处同步的意图,以及不同步可能产生的后果
完整代码(包括main函数)
#include <stdio.h>
#include <cuda_runtime.h>
#include "../tool.h"
/* CHECK函数和GET_TIME函数都定义在tool.h文件中
* 读者临摹或复制粘贴时请自行删除相关代码*/
int cpuRecursiveReduce(int *data,const int size){
if (size==1){
return data[0];
}
int const stride =size/2;
for (int i=0; i<stride;i++)
{
data[i]+=data[i+stride];
}
return cpuRecursiveReduce(data,stride);
}
__global__ void gpuRecursiveReduce(int *g_idata,int *g_odata,const int iSize){
unsigned int tid=threadIdx.x;
int *idata=g_idata+blockIdx.x*blockDim.x;
int *odata=g_odata+blockIdx.x;
if (iSize==2 && tid==0){
g_odata[blockIdx.x]=idata[0]+idata[1];
return;
}
int iStride=iSize>>1;
if (iStride>1 && tid<iStride) {
idata[tid] += idata[tid + iStride];
}
__syncthreads();
if (tid==0){
gpuRecursiveReduce<<<1,iStride>>>(idata,odata,iStride);
cudaDeviceSynchronize();
}
__syncthreads();
}
int main(int argc,char* argv[]){
int size=32;
int blocksize=32;
int gridsize=(size+blocksize-1)/blocksize;
size_t nBytes=size*sizeof(int);
int *hData,*diData,*doData,*gpuRef,cpuSum=0.0,gpuSum=0.0;
double start,finish,elapsed;
if (argc>1){
gridsize=atoi(argv[1]);
blocksize=(size+gridsize-1)/gridsize;
}
dim3 block(blocksize,1);
dim3 grid(gridsize,1);
hData=(int *)malloc(nBytes);
gpuRef=(int *)malloc(grid.x*sizeof(int));
CHECK(cudaMalloc((void**)&diData,nBytes));
CHECK(cudaMalloc((void**)&doData,grid.x*sizeof(int)));
for (int i=0;i<size;i++){
*(hData)=i;
}
CHECK(cudaMemcpy(diData,hData,nBytes,cudaMemcpyHostToDevice));
GET_TIME(start);
cpuSum=cpuRecursiveReduce(hData,size);
GET_TIME(finish);
elapsed=finish-start;
printf("calculate %d numbers,cpu cost %lf sc. result is %d\n",size,elapsed,cpuSum);
GET_TIME(start);
gpuRecursiveReduce<<<grid,block>>>(diData,doData,block.x);
CHECK(cudaDeviceSynchronize());
CHECK(cudaGetLastError());
GET_TIME(finish);
elapsed=finish-start;
CHECK(cudaMemcpy(gpuRef,doData,grid.x*sizeof(int),cudaMemcpyDeviceToHost););
for (int i=0;i<grid.x;i++){
gpuSum+=gpuRef[i];
}
printf("calculate %d numbers,gpu cost %lf sc. result is %d\n",size,elapsed,gpuSum);
return 0;
}
贴出结果
(base) $ nvcc -arch=sm_50 -rdc=true -c nestedReduce.cu
(base) $ nvcc -arch=sm_50 -dlink nestedReduce.o -o device_link.o
(base) $ g++ device_link.o nestedReduce.o -o reduce.out -L/usr/local/cuda-10.1/lib64 -lcudart -lcudadevrt
(base)$./reduce.out
calculate 32 numbers,cpu cost 0.000002 sc. result is 31
calculate 32 numbers,gpu cost 0.000196 sc. result is 31
动态并行出现的问题
由于嵌套的特殊性,在编译的过程中可能遇到问题,出现报错
error: calling a __global__ function("gpuRecursiveReduce") from a __global__ function("gpuRecursiveReduce") is only allowed on the compute_35 architecture or above
由于我是使用CMakeLists编译的,所以并没有可行的方法在CMakeLists中解决问题,故只能使用命令行来编译目标文件
(base) $ nvcc -arch=sm_50 -rdc=true -c nestedReduce.cu
(base) $ nvcc -arch=sm_50 -dlink nestedReduce.o -o device_link.o
(base) $ g++ device_link.o nestedReduce.o -o reduce.out -L{path} -lcudart -lcudadevrt
path中为自己电脑中cuda包lib64的路径
感谢阅读
感谢你花时间看到最后,祝你生活愉快每天开心!















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









