








一、课前准备
让我们一起来打开Jupyter Notebook,来到第115个分享示例中,打开示例中的Readme文档,初步了解下OpenVINO的异步API(本次示例所用到的最新代码模块可在github notebook相应仓库中拉取,并且完成相关依赖库的安装)。

OpenVINO推理任务分成同步和异步两种部署模式,这两种部署模式也对应着图中的Sync API和Async API。同步模式是指我们在推理任务中是以线程阻塞的方式进行部署,也就意味着如果当前进程中有推理任务正在被执行,其他任务需要等到该推理任务结束以后才能被执行。
异步模式则是指推理任务可以和其他的线程任务并行执行,来提升资源利用率,特别是在视频流的处理的场景下,异步模式可以在进行前一帧数据处理的同时,同步完成对后一帧数据的读取以及解码等一系列操作,显著提升推理过程中数据处理的吞吐量。
接下来让我们一起打开Notebook,通过Open Model Zoo中的预训练模型人体检测模型来完成我们代码模组演示。
二、代码演示
首先,通过Model Download工具组件去下载这个模型,并且指定模型精度为FP16。

下载完成以后会在本地的model文件夹中生成模型文件,然后我们需要和往常的OpenVINO Runtime部署任务一样,初始化推理引擎,并且加载模型,获取模型中对于输入数据layout的要求,包括不同的维度信息、对于输入图片的长宽高要求等等。
接着,我们需要根据刚才获取的输入数据的要求,分别对模型进行前处理和后处理,进行定义。前处理主要是将BGR的通道转化成RGB,然后对图片进行reshape,以及将它的layout进行转置等一系列比较常规的前处理任务。
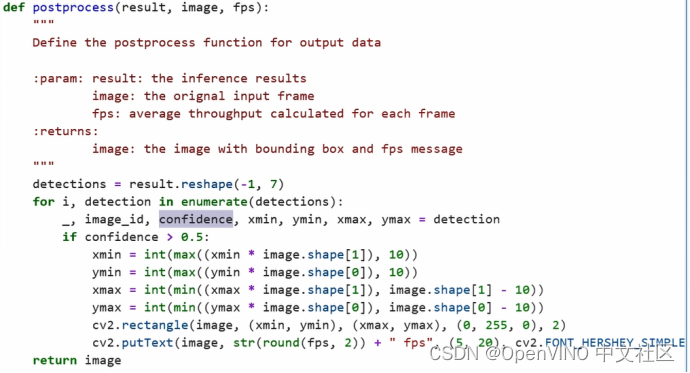
后处理主要是将模型的output输出的原始数据转化成我们的置信度,也就是这个画面中的某一个位置上是否有这样置信度以及人体的位置信息,并将它的坐标点还原到原始画面中,进行展示,通过Open CV的rectangle工具组件以及 putText,分别将画面中的人体的位置坐标信息给它画框,以及将当前画面中的吞吐量信息直观的呈现画面中。
当完成前后处理任务定义以后,接下来会引入这次用到的示例视频。
同步模式和异步模式的差别对比-同步模式
首先来看同步模式,这段伪代码很好地展示了同步模式下,我们是怎样去处理视频任务的。

一般而言,首先会定义一个while循环不断的读取画面中的每一帧,然后我们会将画面中的每一帧送入到当前的推理请求中,并执行推理任务。
当这个推理任务完成以后,我们会将这一帧的画面连通Bounding Box也就是推理结果,一起进行可视化呈现。当这一轮任务结束以后,我们再去读取下一帧,周而复始地完成对整个视频流的分析任务。
回到代码模块,上面描述的while循环可以对应到下方代码的while循环。

如代码所示,首先我们会进行视频帧的读取,本次读取也是用到了Notebook中预先定义的 VideoPlayer的视频读取模块读取视频中的每一帧,然后将每一帧送到前处理模块中,进行对图像的前处理操作,以及将我们 recess以后的画面送到推理请求中进行推理。

可以看到,在同步模式下,推理接口是infer这样的一个接口,然后我们通过output_tensor去获取原始的结果数据,当获取结果数据完成后,可以看到有一个时间戳的记录,我们会把结束的时间减去开始的时间(开始的时间就是while循环之前所定义的开始的时间),通过这两次时间的相减,那么我们就会得到所有视频流中累积处理的时长。
接着我们把累积的处理时长和所累积的处理的帧数相除,取导,就得到了平均FPS,也就是它的吞吐量。
最后,为了方便我们可以做一个可视化呈现。对当前的画面进行后处理,通过OpenCV的一些组件,然后进行可视化的展示。


运行一下这段代码,可以看到在画面中,人体被标记框给框出来了,同时在左上角会实时的呈现累计的平均FPS值。可以看到在同步模式下,我们的平均FPS是在20.14左右。
同步模式和异步模式的差别对比-异步模式
在异步模式下,同样有段伪代码。
由于在默认的情况下,同一时刻只能有一个推理请求被执行,所以我们会提前去申请两个推理请求,一个叫Next,一个叫Current,其中一个用来加载下一帧的数据,另外一个用来执行当前帧的推理任务。当前帧的推理任务结束以后,我们会将闲置的推理请求继续让它去加载下一帧或下下帧的推理数据。
从伪代码中也非常好理解,首先我们会抓取一帧画面,然后将这下一帧画面送到Next InferRequest,也就是下一次的推理请求中,并且启动我们的异步推理模式,然后同时等待上一次的推理结果。
当上一个InferRequest的推理结果产生以后,我们会对上一次InferRequest的推移结果进行一个可视化呈现,并且这个时候会发现 Current InferRequest因为已经完成了推理任务,所以是被闲置出来了。所以这时候我们会将这两个InferRequest进行交换,一边让闲置出来的资源,继续去周而复始的去处理下下帧的 frame输入数据的值。

来到真实代码模块中,我们提前分别申请了两个InferRequest,一个叫Current,一个叫Next,然后在同样While True的循环中,真实的代码和之前的伪代码是一一对应的,包括我们会抓取下一个next_frame,然后将这个next_frame送入到next_request,进行 async这样的推理请求。

同步模式是infer接口,但在异步下我们会调用 star_async这样一个异步的推理接口,然后我们会等待上一次的 curr_ request完成推理任务的执行,最后处理上一次的推理结果,并将它作为可视化呈现。
由于我们开启异步推理模式,调用这个接口以后,代码会立马return,而不会影响到我们后面代码的执行,所以我们在开始Start_async推理模式以后,后面的这一块后处理任务,包括视频的可视化呈现,都可以同步的去被执行。此时我们这样的一个推理任务会被加载到后续的推理队列中,等待前一个任务完成以后再顺序的执行。接下来我们就可以等待当前帧的推理结果结束以后,去获取结果数据就可以了。
这是异步模式的主要逻辑,我们会去交换两个infer request,最后去实现我们将闲置资源继续去处理下下帧数据的诉求和目的。

同样的运行一下示例的 Video,可以从肉眼直观的感受到视频帧数明显提升。异步模式的采集平均FPS的逻辑和方法和同步模式是一样的,也是在while循环去统计开始的时间戳,然后在 Current_inference结束以后去统计结束的时间戳,再对累积的frame,除以消耗的总时间,最终得到在async模式上的FPS值。

可以看到,在异步模式上,吞吐量的提升还是比较明显的,达到了27.39FPS,最后我们通过POT工具来可视化地呈现一下这两者的区别,在同步模式下平均的帧数在20左右,在异步模式下帧数达到了27,提升还是非常显著的。
所以,如果你是在处理一些连续的视频帧,或者是连续的推进任务之后,并且这两前后两帧的推理任务之间有一些重叠的工作,Nono非常推荐你去使用异步API接口来提升对于连续视频流的推理性能。















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









