









首先我们先来看一下淘宝搜索商品的页面,这里以糖炒板栗为例:
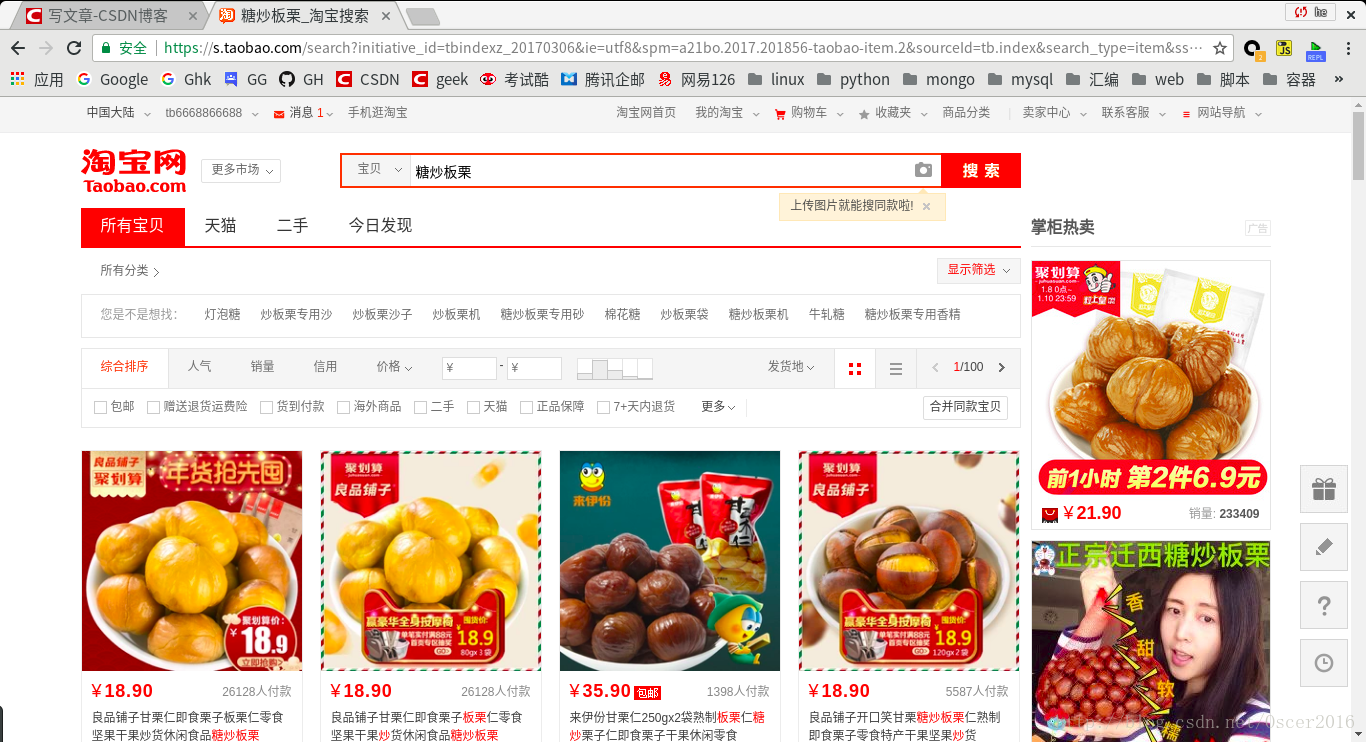
可以看到搜索到了很多糖炒板栗,显示有100页,但真正搜索到的商品超过了100页,给用户只显示前100页,后面编写的爬虫只爬取前50页,url构造这里就不讲了,之前的博客已经讲过了,需要更多可以自己更改页数,然后我们检查网页元素,找到商品链接并复制,然后在网页源代码里查找,结果如下:
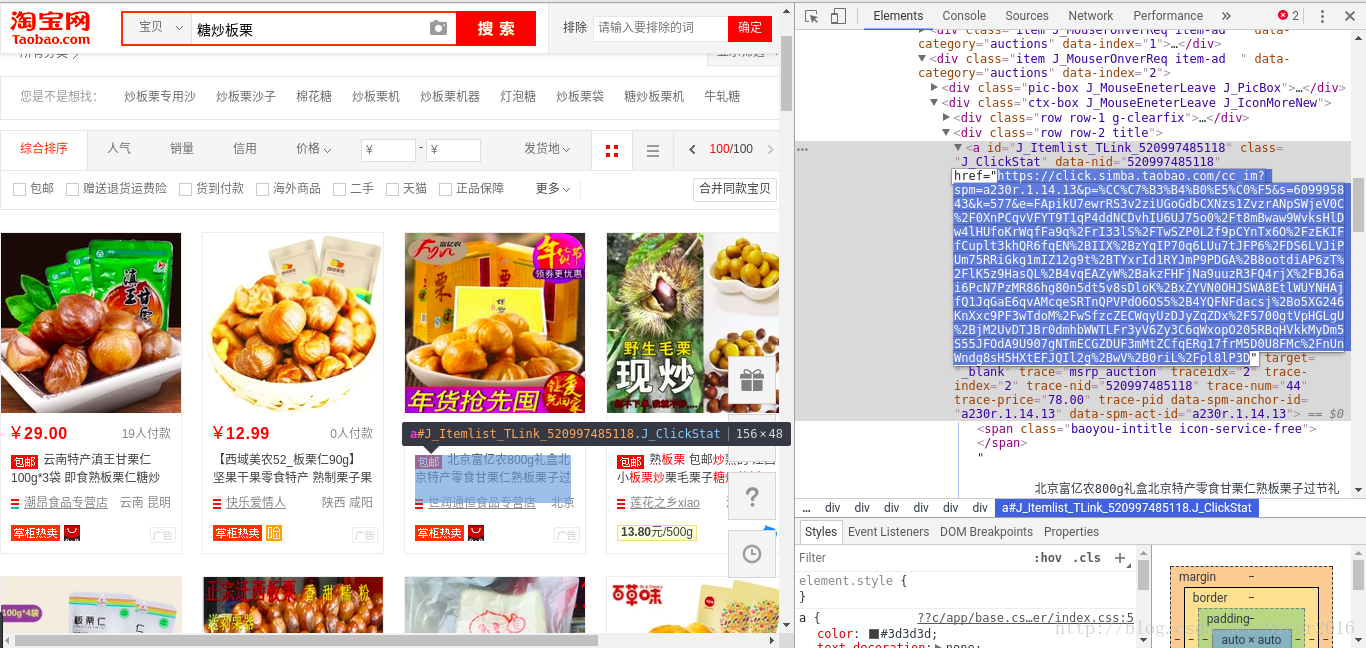
发现并没有找到,说明该数据是动态加载的,那我们是不是应该去js动态加载的数据中去找呢?答案是没必要,虽然可以这样找,但是效率很低。这里介绍另一种方法,仔细观察商品详情页的链接,你会发现有一个参数是id,如果搜索结果页的网页源码里有这些商品的id,那我们不就可以直接构造url了,带着这种思路,我们进行如下操作:
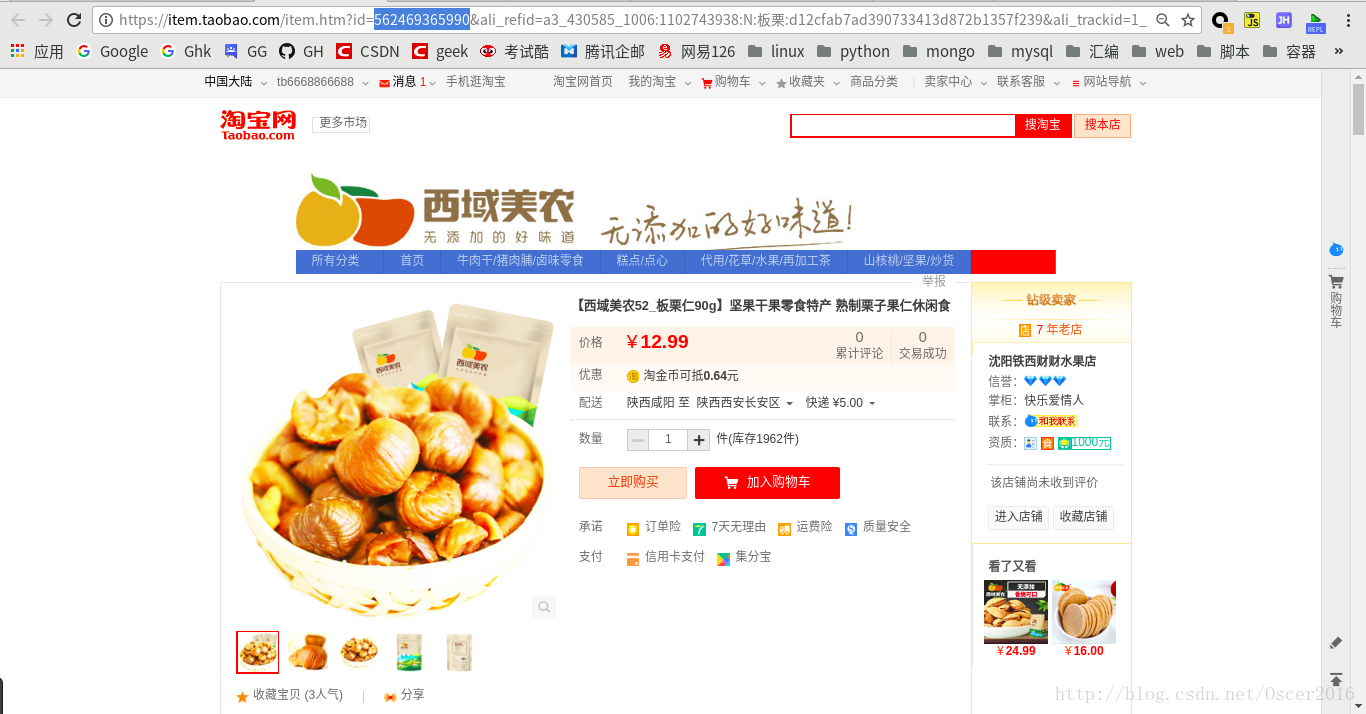

我们发现,这种思路是正确的,在网页源代码里确实找到了该商品的id,然后我们进行如下操作:

按照这种规则可以找到44个搜索结果,正好是淘宝搜索结果页一页的商品数,于是,我们就可以构造出商品详情页的url,仔细观察搜索结果,你会发现在淘宝网搜索的结果里面,包含了大量天猫商城的商品,而这两个网站详情页的抓取规则又不相同,所以,在最后应分别处理这两个网站的商品。这次的评论内容,我们将采用json反序列化来抽取评论数据,说到这里,我们再来介绍一个谷歌的JSON-handle插件吧,如下图所示:

启用这个插件后,网页上的json数据就会很友好的显示出来,这里我们以天猫商城商品的评论数据为例:
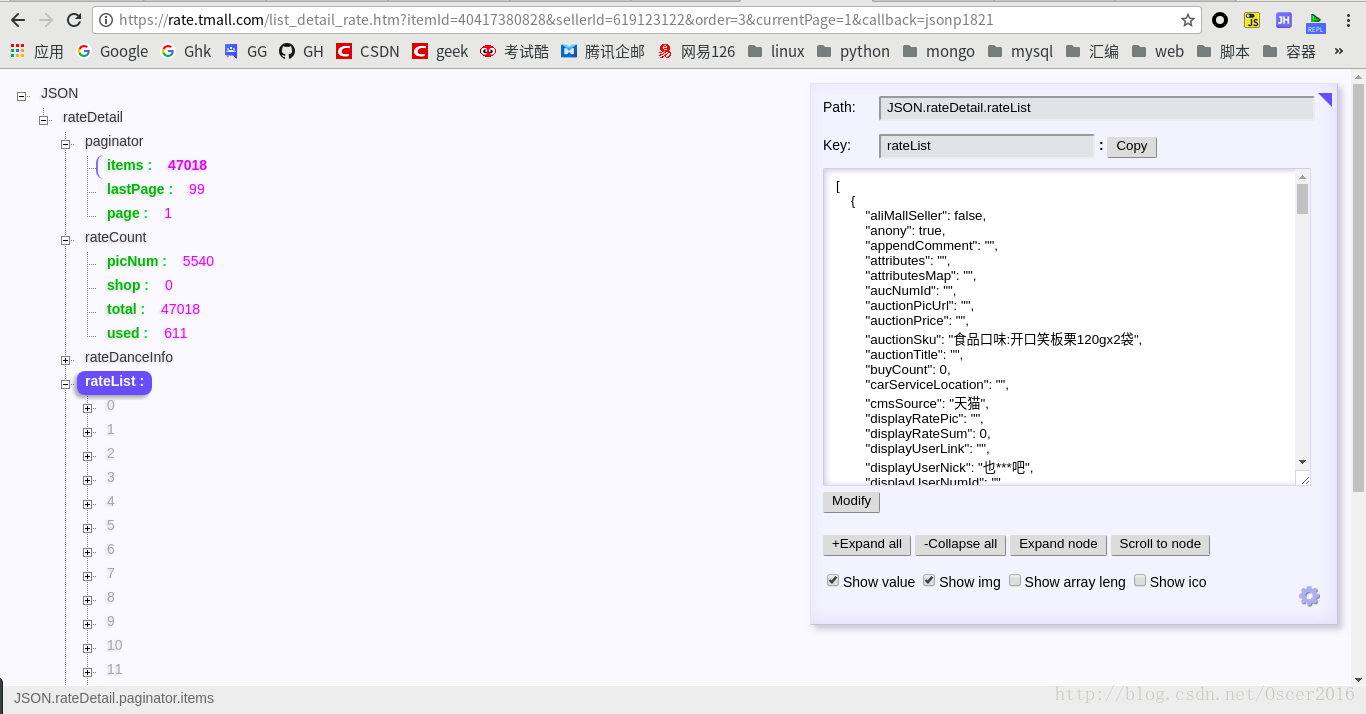
这样我们就很容易看到这个页面上的所有数据,比如总评价数,总评价页数,当前评价页码,还有评论数据rateList,里面包含评价内容,评价时间,以及回复等,可以看到一页有20个评价,因为评价内容太长,下面编写的爬虫只爬取评价首页的前5条评价内容及评价时间,下面正式开始编写爬虫代码,Scrapy创建项目请参考前面的博客,这里直接编写具体代码文件:
1. 编写 settings.py :
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
'Accept':'application/json, text/plain, */*',
'Accept-Language':'zh-CN,zh;q=0.3',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Connection':'keep-alive',
}2. 编写要抽取的数据域 (items.py) :
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AccurateTaobaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
keywords = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
comment_data = scrapy.Field()
shop_name = scrapy.Field()
shop_link = scrapy.Field()
describe_score = scrapy.Field()
service_score = scrapy.Field()
logistics_score = scrapy.Field()3. 编写 piplines.py:
这里就不编写它了,直接打印在终端页面,如果需要存储文件或数据库,可以参考前面几篇博客,然后在settings.py文件中修改ITEM_PIPELINES即可。
4. 编写爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from accurate_taobao.items import AccurateTaobaoItem
from accurate_taobao.settings import DEFAULT_REQUEST_HEADERS
import re
import json
import urllib2
class SpiderAccuratetaobaoSpider(scrapy.Spider):
name = 'spider_accurate_taobao'
allowed_domains = ['taobao.com', 'tmall.com']
start_urls = ['https://www.taobao.com/']
def __init__(self, keywords=None, *args, **kwargs):
super(SpiderAccuratetaobaoSpider, self).__init__(*args, **kwargs)
print '您搜索的商品为:', keywords
self.keywords = keywords
self.start_urls = ['https://s.taobao.com/search?q=%s' % keywords]
def parse(self, response):
# 前50页
for i in range(50):
purl = response.url + "&s={}".format(str(i*44))
yield Request(url=purl, callback=self.goods)
def goods(self, response):
body = response.body.decode("utf-8","ignore")
patid = '"nid":"(.*?)"'
allid = re.compile(patid).findall(body)
for j in range(len(allid)):
thisid = allid[j]
url = "https://item.taobao.com/item.htm?id=" + str(thisid)
yield Request(url=url,callback=self.next)
def next(self, response):
item = AccurateTaobaoItem()
title = response.xpath('//h3[@class="tb-main-title"]/@data-title').extract()
goods_id = re.findall('id=(.*?)$', response.url)[0]
headers = DEFAULT_REQUEST_HEADERS
if not title:
mall = '天猫商城'
title = response.xpath('//div[@class="tb-detail-hd"]/h1/text()').extract()[0].encode('utf-8').strip()
headers['referer'] = "https://detail.tmall.com/item.htm"
purl = 'https://mdskip.taobao.com/core/initItemDetail.htm?&itemId={}'.format(goods_id)
req = urllib2.Request(url=purl, headers=headers)
res = urllib2.urlopen(req).read()
pdata = re.findall('"postageFree":false,"price":"(.*?)","promType"', res)
price = list(set(pdata))[0]
else:
mall = '淘宝商城'
title = title[0].encode('utf-8')
purl = "https://detailskip.taobao.com/service/getData/1/p1/item/detail/sib.htm?itemId={}&modules=price,xmpPromotion".format(goods_id)
headers['referer'] = "https://item.taobao.com/item.htm"
price_req = urllib2.Request(url=purl, headers=headers)
price_res = urllib2.urlopen(price_req).read()
pdata = list(set(re.findall('"price":"(.*?)"', price_res)))
price = ""
for t in pdata:
if '-' in t:
price = t
break
if not price:
price = sorted(map(float, pdata))[0]
comment_url = "https://rate.tmall.com/list_detail_rate.htm?itemId={}&sellerId=880734502¤tPage=1".format(goods_id)
data = urllib2.urlopen(comment_url).read().decode("GBK", "ignore")
cdata = '{' + data + '}'
jdata = json.loads(cdata)
comment_data = ''
for i in range(5):
comment_data += u"\n评价内容: " + jdata['rateDetail']['rateList'][i]['rateContent'] + u"\n评价时间:" + jdata['rateDetail']['rateList'][i]['rateDate']
item['keywords'] = self.keywords
item['title'] = title
item['price'] = price
item['comment_data'] = comment_data
item["link"] = response.url
print '\n商品名:', item['title']
print '此商品来自', mall
print '价格:', item['price']
print '商品链接:', item['link']
print '部分评价:', item['comment_data']
#yield item
5. 运行项目:
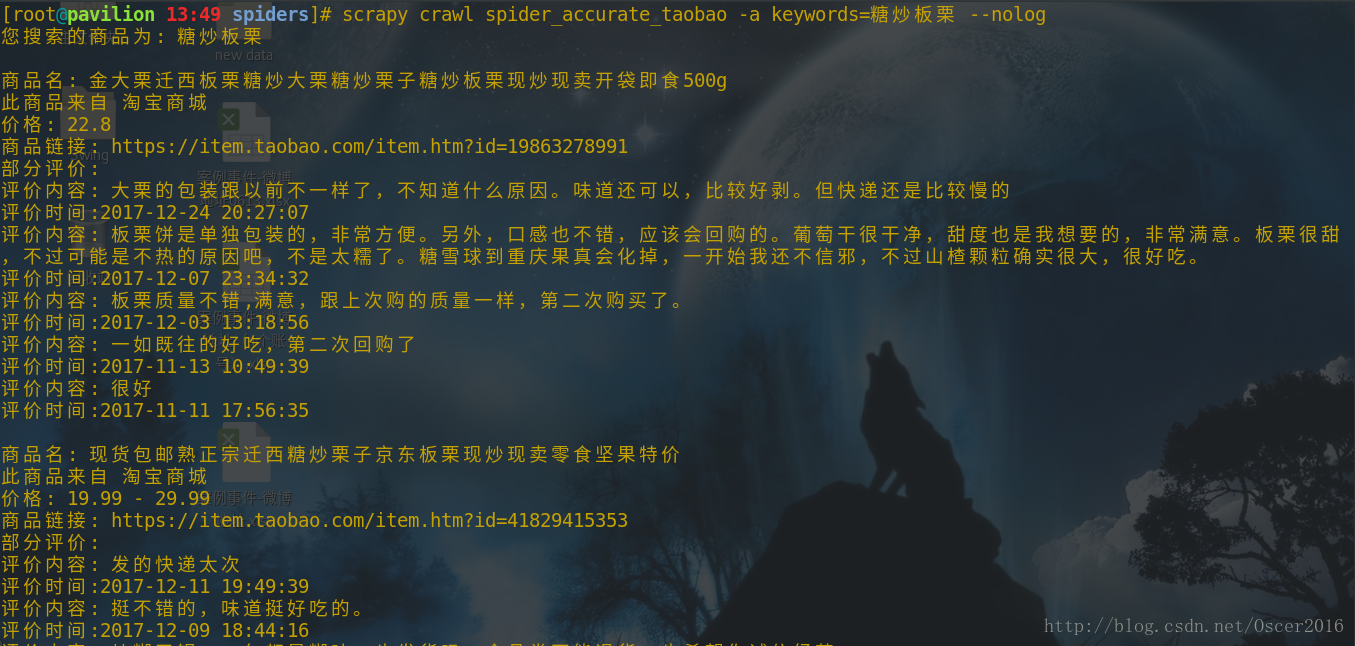
scrapy crawl spider_accurate_taobao -a keywords=糖炒板栗 --nolog运行结果如下图:















 5022
5022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









