







无数次在界面程序中用到字符串与各种类型的数值之间的格式转换,今天在此统一总结一下,之后会在本文继续更新。
CString 转 float
CString str = _T("12.32");
float fVal = atof(str);出错,C2664: ‘atof’: cannot convert parameter 1 from ‘CString’ to ‘const char* ‘, 原因是 UNICODE 工程下的 LPCTSTR 不是 const char *;
建议代码:
CString str = _T("12.32");
float fVal = _tstof(str);补充说明:
double atof(const char * str);
double _wtof(const wchar_t *str); 其中,atof是非unicode版本,接受参数为 const char*; _wtof是unicode版本,接受宽字符参数;
而上述建议代码中 _tstof 实际就是一个宏:
#define _ttof _wtof
#define _tstof _wtof
#define _tstol _wtol
#define _tstoll _wtoll
#define _tstoi _wtoi
#define _tstoi64 _wtoi64在VC++6.0的老版本中,即便将工程设置为UNICODE模式,也不能用 _wtof 实现 CString到float的转换,若用此函数则只能转换第一个字符,余下的字符均无法正确转换,此时可以用 _wtol 实现CString到float的转换。
CString str = _T("12.34");
float fPGrade = _wtol(str);如此,fPGrade的值便为浮点型的 12.34
CString 转 int
在tchar.h文件中有专门用于字符串转换的一系列宏函数,正如上面宏定义所列,以下作简要摘录:
/* String conversion functions */
#define _tcstod wcstod
#define _tcstof wcstof
#define _tcstol wcstol
#define _tcstold wcstold
#define _tcstoll wcstoll
#define _tcstoul wcstoul
#define _tcstoull wcstoull
#define _tcstoimax wcstoimax
#define _tcstoumax wcstoumax
#define _tcstoi64 _wcstoi64
#define _tcstoui64 _wcstoui64
#define _ttof _wtof
#define _tstof _wtof
#define _tstol _wtol
#define _tstoll _wtoll
#define _tstoi _wtoi
#define _tstoi64 _wtoi64
#define _tcstod_l _wcstod_l
#define _tcstof_l _wcstof_l
#define _tcstol_l _wcstol_l
#define _tcstold_l _wcstold_l
#define _tcstoll_l _wcstoll_l
#define _tcstoul_l _wcstoul_l
#define _tcstoull_l _wcstoull_l
#define _tcstoi64_l _wcstoi64_l
#define _tcstoui64_l _wcstoui64_l
#define _tcstoimax_l _wcstoimax_l
#define _tcstoumax_l _wcstoumax_l
#define _tstof_l _wtof_l
#define _tstol_l _wtol_l
#define _tstoll_l _wtoll_l
#define _tstoi_l _wtoi_l
#define _tstoi64_l _wtoi64_l
#define _itot_s _itow_s
#define _ltot_s _ltow_s
#define _ultot_s _ultow_s
#define _itot _itow
#define _ltot _ltow
#define _ultot _ultow
#define _ttoi _wtoi
#define _ttol _wtol
#define _ttoll _wtoll
#define _ttoi64 _wtoi64
#define _i64tot_s _i64tow_s
#define _ui64tot_s _ui64tow_s
#define _i64tot _i64tow
#define _ui64tot _ui64towC2W
MultiByteToWideChar
在这里封装一个C2W函数实现由多字节字符串向宽字节字符串的转换:
bool C2W(const char* str, wchar_t* wstr)
{
int len = MultiByteToWideChar(CP_OEMCP, 0, str, -1, wstr, 0);
return len == MultiByteToWideChar(CP_OEMCP, 0, str, -1, wstr, len);
}其中宏 CP_OEMCP 的定义如下:
//
// Code Page Default Values.
//
#define CP_ACP 0 // default to ANSI code page
#define CP_OEMCP 1 // default to OEM code page
#define CP_MACCP 2 // default to MAC code page
#define CP_THREAD_ACP 3 // current thread's ANSI code page
#define CP_SYMBOL 42 // SYMBOL translations
#define CP_UTF7 65000 // UTF-7 translation
#define CP_UTF8 65001 // UTF-8 translation
先简单解释一下MultiByteToWideChar函数,在MSDN上有解释:MultiByteToWideChar是一种windows API 函数,该函数映射一个字符串到一个宽字符(unicode)的字符串。由该函数映射的字符串没必要是多字节字符组。
MultiByteToWideChar参数说明:
CodePage:指定执行转换的字符集,这个参数可以为系统已安装或有效的任何字符集所给定的值。你也可以指定其为下面的任意一值:
(1) CP_ACP:ANSI字符集;
(2) CP_MACCP:Macintosh代码页;
(3) CP_OEMCP:OEM代码页;
(4) CP_SYMBOL:符号字符集(42);
(5) CP_THREAD_ACP:当前线程ANSI代码页;
(6) CP_UTF7:使用UTF-7转换;
(7) CP_UTF8:使用UTF-8转换。
dwFlags:一组位标记用以指出是否未转换成预作或宽字符(若组合形式存在),是否使用象形文字替代控制字符,以及如何处理无效字符。你可以指定下面是标记常量的组合,含义如下:
(1) MB_PRECOMPOSED:通常使用预作字符——就是说,由一个基本字符和一个非空字符组成的
字符只有一个单一的字符值。这是缺省的转换选择。不能与MB_COMPOSITE值一起使用。
(2) MB_COMPOSITE:通常使用组合字符——就是说,由一个基本字符和一个非空字符组成的
字符分别有不同的字符值。不能与MB_PRECOMPOSED值一起使用。
(3) MB_ERR_INVALID_CHARS:如果函数遇到无效的输入字符,它将运行失败,
且GetLastErro返回ERROR_NO_UNICODE_TRANSLATION值。
(4) MB_USEGLYPHCHARS:使用象形文字替代控制字符。
组合字符由一个基础字符和一个非空字符构成,每一个都有不同的字符值。每个预作字符都有单一的字符值给基础/非空字符的组成。在字符è中,e就是基础字符,而重音符标记就是非空字符。
函数的缺省动作是转换成预作的形式。如果预作的形式不存在,函数将尝试转换成组合形式。
标记MB_PRECOMPOSED和MB_COMPOSITE是互斥的,而标记MB_USEGLYPHCHARS和MB_ERR_INVALID_CHARS则不管其它标记如何都可以设置。
lpMultiByteStr:指向将被转换字符串的字符。
cchMultiByte:指定由参数lpMultiByteStr指向的字符串中字节的个数。如果lpMultiByteStr指定的字符串以空字符终止,可以设置为-1(如果字符串不是以空字符中止,设置为-1可能失败,可能成功),此参数设置为0函数将失败。
lpWideCharStr:指向接收被转换字符串的缓冲区。
cchWideChar:指定由参数lpWideCharStr指向的缓冲区的宽字符个数。若此值为零,函数返回缓冲区所必需的宽字符数,在这种情况下,lpWideCharStr中的缓冲区不被使用。
补充:
如果ANSI代码页允许在不同的计算机上不相同,甚至在单台计算机上不一样,将会导致数据崩溃。为了代码页一致性,应用程序应该使用Unicode编码,如UTF-8或者UTF-16,而不是使用特殊的代码页,除了早期标准或者数据格式化不允许使用Unicode编码。在特殊情况下,有些函数不允许使用Unicode编码,应用程序应在协议允许的情况下在数据流中用合适的编码名称标识。在HTML、XML、HTTP等文件中都允许标识,但TEXT文本不允许这样做。
C2W使用实例
当我们在使用字符数组与CString类型的字符串进行比较时或必要进行字符数组到CString的转换时,可以用此函数:
char szName[20] = {"I love you, China!"};
TCHAR tchName[20];
CString str;
C2W(szName, tchName);
str = tchName; // 也可使用str.Format(_T("%s"), tchName);
AfxMessageBox(_T("str = ")+str); 看看直观的调试效果:
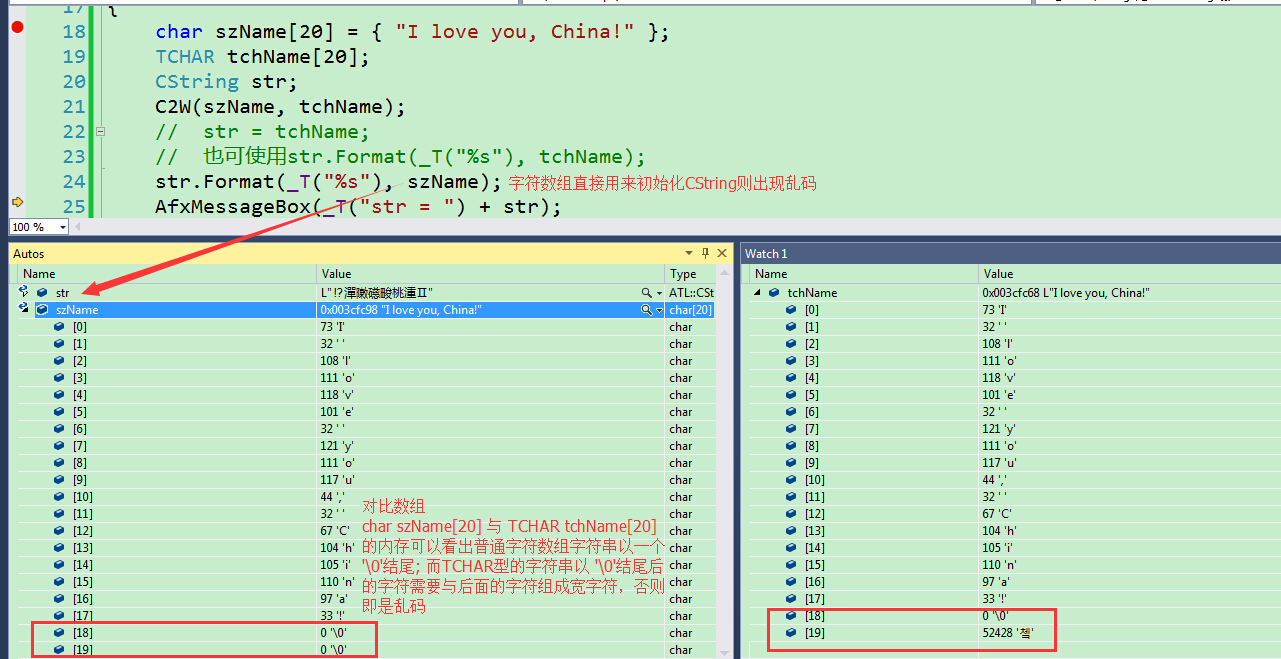
而TCHAR是一个宏,其定义如下:
// winnt.h
//
// UNICODE (Wide Character) types
//
#ifndef _MAC
typedef wchar_t WCHAR; // wc, 16-bit UNICODE character
#else
// some Macintosh compilers don't define wchar_t
// in a convenient location, or define it as a char
typedef unsigned short WCHAR; // wc, 16-bit UNICODE character
#endif
typedef WCHAR *PWCHAR, *LPWCH, *PWCH;
typedef CONST WCHAR *LPCWCH, *PCWCH;
// winnt.h
#ifdef UNICODE // r_winnt
#ifndef _TCHAR_DEFINED
typedef WCHAR TCHAR, *PTCHAR;
typedef WCHAR TBYTE , *PTBYTE ;
#define _TCHAR_DEFINED
#endif /* !_TCHAR_DEFINED */此定义在winnt.h中,由下往上看这段代码,TCHAR的意义就很清楚了,就是 16-位 宽度的UNICODE字符,可以直接用来对CString类型的变量赋值或格式化。
再来看看TCHAR在另一个文件 tchar.h 中的定义:
#ifndef _TCHAR_DEFINED
#if !__STDC__
typedef wchar_t TCHAR;
#endif /* !__STDC__ */
#define _TCHAR_DEFINED
#endif /* _TCHAR_DEFINED */
#define _TEOF WEOF
#define __T(x) L ## x
#define _T(x) __T(x) // 最常见的 _T("I love China")
#define _TEXT(x) __T(x)W2C
WideCharToMultiByte
反过来,用WideCharToMultiByte函数当然就是实现相反的功能,就不再解释,仅用其封装一个W2C函数如下:
bool W2C(const wchar_t* wstr, char* str)
{
int len = WideCharToMultiByte(CP_OEMCP, 0, wstr, -1, str, 0, 0, 0);
return len == WideCharToMultiByte(CP_OEMCP, 0, wstr, -1, str, len, 0, 0);
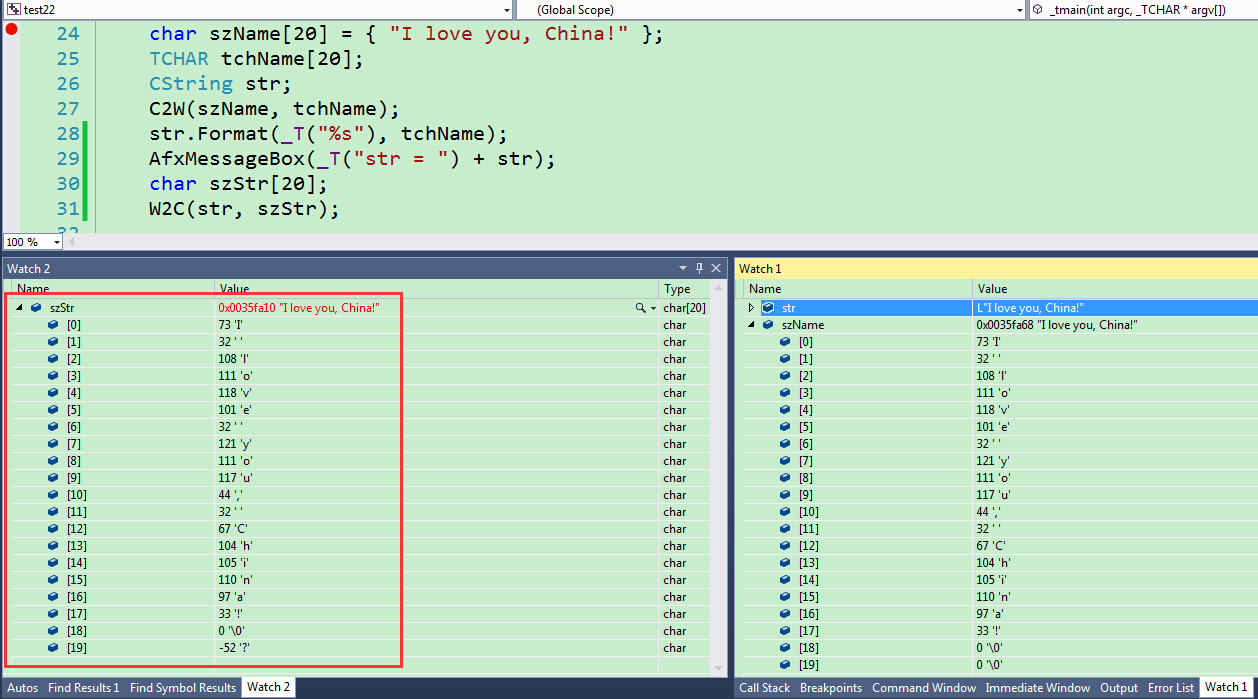
}使用示例如下:
char szString[20];
CString str(_T("I love you, China!"));
W2C(str, szString);看看直观的调试效果:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











