







一、前言
该文章仅作为个人学习使用
二、正文
项目源代码:Python 迷你项目 - 使用 librosa 进行语音情感识别 - DataFlair (data-flair.training)
数据集:
Python 迷你项目
语音情感识别,有史以来最好的python小项目。最好的例子可以在呼叫中心看到。如果您注意到,呼叫中心员工从不以相同的方式说话,他们与客户推销/交谈的方式会随着客户而变化。现在,这也发生在普通人身上,但这与呼叫中心有什么关系?这是你的答案,员工从言语中识别客户的情绪,这样他们就可以改善他们的服务并转化更多的人。通过这种方式,他们正在使用语音情感识别。那么,让我们详细讨论这个项目。
语音情感识别是一个简单的 Python 迷你项目,您将使用 DataFlair 进行练习。之前,我向您解释与此迷你 python 项目相关的术语,请确保您将 Python 项目的完整列表添加为书签。
什么是语音情感识别?
言语情绪识别,缩写为SER,是试图从言语中识别人类情绪和情感状态的行为。这利用了这样一个事实,即声音通常通过语气和音调反映潜在的情感。这也是狗和马等动物用来理解人类情感的现象。
SER 很难,因为情绪是主观的,注释音频具有挑战性。
什么是天秤座?
librosa 是一个用于分析音频和音乐的 Python 库。它具有更扁平的封装布局、标准化的接口和名称、向后兼容性、模块化功能和可读代码。此外,在这个 Python 迷你项目中,我们演示了如何使用 pip 安装它(以及其他一些包)。
什么是 JupyterLab?
JupyterLab 是 Project Jupyter 的开源、基于 Web 的 UI,它具有 Jupyter Notebook 的所有基本功能,如笔记本、终端、文本编辑器、文件浏览器、丰富的输出等。但是,它还提供了对第三方扩展的改进支持。
若要在 JupyterLab 中运行代码,首先需要使用命令提示符运行它:
C:\Users\DataFlair>jupyter 实验室
这将在浏览器中为您打开一个新会话。创建一个新的控制台,然后开始键入代码。JupyterLab 可以一次执行多行代码;按 Enter 键不会执行您的代码,您需要按 Shift+Enter 键才能执行相同的代码。
言语情感识别 – 目标
使用 librosa 和 sklearn 库以及 RAVDESS 数据集构建一个模型来识别语音中的情感。
语音情感识别 – 关于 Python 迷你项目
在这个 Python 迷你项目中,我们将使用 librosa、soundfile 和 sklearn 等库来构建使用 MLPClassifier 的模型。这将能够识别声音文件中的情感。我们将加载数据,从中提取特征,然后将数据集拆分为训练集和测试集。然后,我们将初始化 MLPClassifier 并训练模型。最后,我们将计算模型的准确性。
数据集
对于这个 Python 迷你项目,我们将使用 RAVDESS 数据集;这是 Ryerson Audio-Visual Database of Emotional Speech and Song 数据集,可免费下载。该数据集有 7356 个文件,由 247 个人对情感有效性、强度和真实性进行了 10 次评分。整个数据集是来自 24 个参与者的 24.8GB,但我们降低了所有文件的采样率,您可以在此处下载。
先决条件
您需要使用 pip 安装以下库:
pip install librosa soundfile numpy sklearn pyaudio
如果您在使用 pip 安装 librosa 时遇到问题,可以尝试使用 conda。
语音情感识别 python 项目的步骤
1. 进行必要的进口:
导入 Librosa导入声音文件导入操作系统、glob、泡菜导入 numpy 作为 np来自 Sklearn。model_selection导入train_test_split来自 Sklearn。neural_network导入 MLPClassifier来自 Sklearn。指标导入accuracy_score
截图:

2. 定义一个功能extract_feature,以从声音文件中提取 mfcc、chroma 和 mel 特征。此函数采用 4 个参数 - 文件名和三个功能的三个布尔参数:
- MFCC的:Mel 频率倒谱系数,表示声音的短期功率谱
- 色度:涉及 12 种不同的音高等级
- 梅尔:梅尔频谱图频率
使用 soundfile 打开声音文件。SoundFile 使用 with-as,因此一旦我们完成,它就会自动关闭。从中读取并称之为 X。另外,获取采样率。如果色度为 True,则获取 X 的短时傅里叶变换。
设结果为空 numpy 数组。现在,对于这三个特征中的每个特征,如果存在,请从 librosa.feature 调用相应的函数(例如,mfcc 的 librosa.feature.mfcc),并获取平均值。从 numpy 调用函数 hstack() with result 和 feature 值,并将其存储在 result 中。hstack() 水平(以列式方式)按顺序堆叠数组。然后,返回结果。
#DataFlair - 从声音文件中提取特征(mfcc、chroma、mel)定义 extract_feature(file_name, MFCC, 色度, MEL):使用声音文件。SoundFile(file_name) sound_file:X = sound_file。读取(dtype=“float32”)sample_rate=sound_file。采样率如果色度:stft=np。ABS(天秤座。stft(X))结果=np。数组([])如果 MFCC:mfccs=np。意思是(librosa.功能。mfcc(y=X, sr=sample_rate, n_mfcc=40)。T,轴=0)结果=np。hstack((结果,MFCCS))如果色度:色度=NP。意思是(librosa.功能。chroma_stft(S=stft,sr=sample_rate)。T,轴=0)结果=np。hstack((结果,色度))如果梅尔:mel=np。意思是(librosa.功能。melspectrogram(X, sr=sample_rate)中。T,轴=0)结果=np。hstack((结果,mel))返回结果
截图:

3. 现在,让我们定义一个字典来保存 RAVDESS 数据集中可用的数字和情绪,以及一个列表来保存我们想要的那些——平静、快乐、恐惧、厌恶。
#DataFlair - RAVDESS 数据集中的情绪情绪={'01':'中性','02':'平静','03':'快乐','04':'悲伤','05':'生气','06':'恐惧','07':'厌恶','08':'惊讶'}#DataFlair - 要观察的情绪observed_emotions=['冷静', '快乐', '恐惧', '厌恶']
截图:

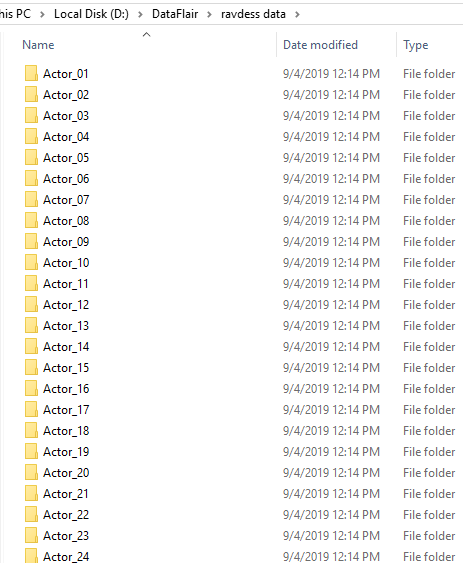
4. 现在,让我们使用函数 load_data() 加载数据——这将测试集的相对大小作为参数。x 和 y 是空列表;我们将使用 glob 模块中的 glob() 函数来获取数据集中声音文件的所有路径名。我们为此使用的模式是:“D:\\DataFlair\\ravdess data\\Actor_*\\*.wav”。这是因为我们的数据集如下所示:
截图:
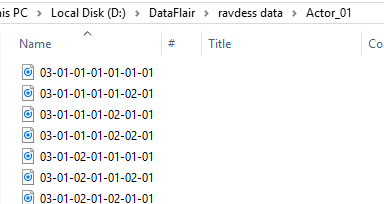
因此,对于每个这样的路径,通过拆分名称“-”并提取第三个值来获取文件的基名和情感:
截图:
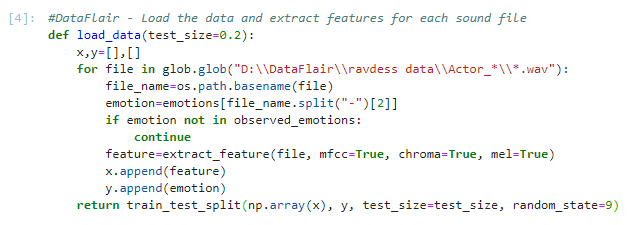
使用我们的情绪字典,这个数字被转化为一种情绪,我们的函数检查这种情绪是否在我们的observed_emotions列表中;如果没有,它将继续到下一个文件。它调用extract_feature并存储“feature”中返回的内容。然后,它将特征附加到 x,将情感附加到 y。因此,列表 x 包含特征,y 包含情感。我们用这些值、测试大小和随机状态值调用函数train_test_split,并返回该值。
#DataFlair - 加载每个声音文件的数据和提取要素def load_data(test_size=0.2):x,y=[],[]对于 glob 中的文件。glob(“D:\\DataFlair\\ravdess data\\Actor_*\\*.wav”):file_name=操作系统。路径。basename(文件)emotion=emotions[file_name.split(“-”)[2]]如果情绪不observed_emotions:继续feature=extract_feature(file, mfcc=True, chroma=True, mel=True)十。append(特征)y。append(emotion)返回 train_test_split(np.数组(x), y, test_size=test_size, random_state=9)
截图:
5. 是时候将数据集拆分为训练集和测试集了!让我们将测试集保留 25% 的所有内容,并为此使用 load_data 函数。
#DataFlair - 拆分数据集x_train,x_test,y_train,y_test=load_data(test_size=0.25)
截图:

6. 观察训练和测试数据集的形状:
#DataFlair - 获取训练和测试数据集的形状print((x_train.形状[0],x_test。形状[0]))
截图:

7. 并获取提取的特征数量。
#DataFlair - 获取提取的要素数print(f'提取的特征: {x_train.shape[1]}')
输出截图:

8.现在,让我们初始化一个MLP分类器。这是一个多层感知器分类器;它使用LBFGS或随机梯度下降来优化对数损失函数。与SVM或Naive Bayes不同,MLPClassifier具有用于分类的内部神经网络。这是一个前馈神经网络模型。
#DataFlair -初始化多层感知器分类器型号=MLP分类器(alpha=0.01,批量大小=256,=1e-08,隐藏层大小=(300,),learning_rate=“适应性”,max_iter=500)
截图:

9.拟合/训练模型。
#DataFlair -训练模型模型配合(x列,y列)
输出截图:

10.让我们预测测试集的值。这给了我们y_pred(测试集中特征的预测情绪)。
#DataFlair -预测测试集y_pred=模型。预测(x检验)
截图:

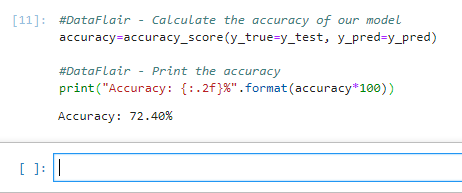
11.为了计算模型的精度,我们最后,我们将精确度四舍五入到小数点后两位,并打印出来。
#DataFlair -计算模型的准确性准确度=准确度分数(y_true=y_test,y_pred=y_pred)#DataFlair -打印精度打印(“精度:{:.2f}%”.格式(准确度 *100))
输出截图:
三、总结
在这个 Python 迷你项目中,我们学会了从语音中识别情绪。为此,我们使用了 MLPClassifier,并利用 soundfile 库来读取声音文件,并使用 librosa 库从中提取特征。如您所见,该模型的准确率为 72.4%。这对我们来说已经足够了。















 2295
2295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









