







更新中。。。。。
监督学习
监督学习是指有目标变量或预测目标的机器学习方法,包括分类和回归。’
分类和回归的区别在于:而回归的目标变量是连续数值型的,如果预测鲍鱼的年龄,则可能是任意正数了。
回归
回归的目标变量是连续数值型的,通过回归方程来实现。
分类
分类的目标变量是离散的,例如某件事发生的可能值为有或无。
无监督学习
输入数据无标签则是无监督学习。
聚类算法
聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。
模型描述
以一次线性回归举例,函数h(x)=θ0+θ1x就是用于预测数据集中y关于x的线性函数。
代价函数
使得函数值h(x)与实际值y的差距尽可能小,也就是使h(x)与y的差值的平方尽可能小,求出这个平方值的函数就是代价函数。
因此代价函数就是平方误差函数。
梯度下降
梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。
通俗来说,就是不断改变θ0和θ1的值去减少代价函数的值,直到找到最小值,但是这个最小值是局部最优点。
对于线性回归方程来说,其代价函数总是这样一个弓状函数,因此总会存在全局最优点。

多元线性回归
上一章说到矩阵的相关知识,从多元线性回归开始,将矩阵与向量的概念融合进来。
在数据集中,一条数据可以当作一个向量。

由于多个变量的引入,因此表达式也具有多个变量。
多元梯度下降法
1、特征缩放。
下图中,左图的梯度下降的速度会由于特征的不一致性而减慢,如果是标准的圆形那么可以加快梯度下降的速度,因此我们需要对特征进行一定的缩放,如右图所示。

通常来说,我们可以把特征的取值约束到接近-1到+1的范围内,但也不用太过苛求数据的范围,只需要和正负1接近即可。
归一化处理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2IerEAVj-1600692515873)(C:\Users\shinelon\AppData\Roaming\Typora\typora-user-images\image-20200921143732511.png)]](https://img-blog.csdnimg.cn/20200921205053171.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1BBTkRPUkFfQQ==,size_16,color_FFFFFF,t_70#pic_center)
2、学习率α

学习率的确认是为了保证梯度下降法能够顺利的迭代。如果梯度下降法顺利运行的话,他的图形会和下图一样,每次迭代,J都会变小。(x轴为迭代次数,y轴为代价函数的值(也就是误差))

- 如果α太小,代价函数收敛太慢
- 如果α太大,代价函数的值可能会随着迭代次数的增加而增加
学习率α的取值

正规方程
正规方程是通过求矩阵的方式来计算函数的参数
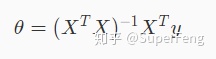
其中 X 是一个矩阵,这个矩阵的每一行都是一组特征值,y 是数据集结果的向量。
example:
数据集: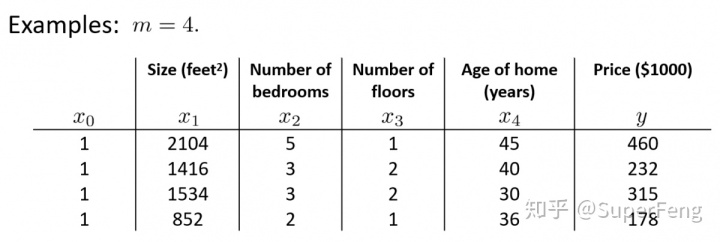
得出矩阵:
向量y:
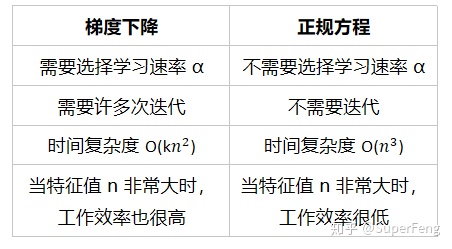
梯度下降法和正规方程的比较
python实现单变量梯度下降
实现单变量代价函数

import numpy as np
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
单变量梯度下降
# alpha是学习速率 iters是要执行的迭代次数
def gradientDescent(x, y, theta, alpha, iters):
# 生成一个零矩阵
temp = np.asmatrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
#
for i in range(iters):
error = (x * theta.T) - y
for j in range(parameters):
term = np.multiply(error, x[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(x)) * np.sum(term))
theta = temp
cost[i] = computeCost(x,y,theta)
return theta,cost
# 设置初始参数
alpha = 0.01
iters = 1500
g, cost = gradientDescent(x, y, theta,alpha,iters)
print(g)
print(cost)
#画误差迭代图
fig, ax = plt.subplots(figsize=(10,8))
ax.plot(np.arange(iters), cost, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
#预测35000和70000城市规模的小吃摊利润
# g就是计算出的θ
predict1 = [1,3.5]*g.T
print("predict1:",predict1)
predict2 = [1,7]*g.T
print("predict2:",predict2)
# x为data的population的分布,最大最小值均由data的Population列决定,一共生成100个点
x = np.linspace(data.Population.min(), data.Population.max(), 100)
f = g[0, 0] + (g[0, 1] * x)
#画图 分别是拟合的线性回归方程以及初始数据
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
# 大功告成!!!
输出:
>>> g
matrix([[-3.63029144, 1.16636235]])
>>> cost
array([6.73719046, 5.93159357, 5.90115471, ..., 4.48343473, 4.48341145,
4.48338826])
分类问题
二分类
二分类问题分为正类和负类,对于图中的数据而言,能把两拨数据分离的边界叫做决策边界

logistic回归
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有 w‘x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w‘x+b作为因变量,即y =w‘x+b,而logistic回归则通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b),然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。

逻辑回归使用了sigmoid函数,sigmoid函数本身也是Logistic function的一种形式,故此得名。逻辑回归是一种广义的线性回归分析模型,Sigmoid函数是逻辑回归的核心,通过Sigmoid函数将原本的线性回归问题转化成了一个类问题。

Logistic回归是用来解决二类分类问题的,如果要解决的问题是多分类问题呢?那就要用到softmax回归了,它是Logistic回归在多分类问题上的推广。此处神经网络模型开始乱入,softmax回归一般用于神经网络的输出层,此时输出层叫做softmax层。
logistic回归代价函数

代价方程可以简化为上图中最后一条式子,原因是对于二分类来说,当y=1,后面部分的式子为0;当y=0时,前半部分的式子为0。由此再进一步化简为

梯度:

过拟合问题
解决过拟合问题:
1 减少选取变量的数量
2 正则化
正则化:添加惩罚项,对变量进行约束

λ为正则化参数,控制拟合方程以及参数,动态平衡这两者的关系,使得方程在更好的拟合目标的同时将参数控制得更小。















 3274
3274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









