









C4.5决策树——剪枝的问题
一。先说点什么
今天是周日,作为实习生在公司不加班,只想多学点什么。同时对未来也是有点迷茫,就说这么多吧。
二。切入主题
1.为什么要剪枝
剪枝的目的是避免C4.5生成的决策树出现过拟合的问题,过拟合是对训练样本过拟合,出现过拟合的原因可能是因为样本数量太少等。决策树过拟合在外形上表现为树的结构相对较复杂。一棵过拟合的树在泛化能力的表现上很差,也就是说这样的树对于训练集的准确率很高但是对于测试集或者未来的数据表现就很差。Quinlan教授实验并得出结论:
教授试验,在数据集中,过拟合的决策树的错误率比经过简化的决策树的错误率要高。
现在的问题在于如何在原生的过拟合决策树的基础上,生成简化版的决策树?可以通过剪枝的方法来简化过拟合的决策树。剪枝可以分为两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning),下面我们来详细学习下这两种方法:
PrePrune:预剪枝,及早的停止树增长,
及早停止树增长的方法包括 1)节点内的数据都已经完全属于同一类别
2) 节点内测数据样本数低于某一阀值
3) 所有的属性都已经被分裂过
PostPrune:后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
其实剪枝的准则是如何确定决策树的规模,可以参考的剪枝思路有以下几个:
PostPrune:后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
其实剪枝的准则是如何确定决策树的规模,可以参考的剪枝思路有以下几个:
a:使用训练集合(Training Set)和验证集合(Validation Set),来评估剪枝方法在修剪结点上的效用
2:使用所有的训练集合进行训练,但是用统计测试来估计修剪特定结点是否会改善训练集合外的数据的评估性能,如使用Chi-Square(Quinlan,1986)测试来进一步扩展结点是否能改善整个分类数据的性能,还是仅仅改善了当前训练集合数据上的性能。
c:使用明确的标准来衡量训练样例和决策树的复杂度,当编码长度最小时,停止树增长,如MDL(Minimum Description Length)准则。就像大家经常说的,一个真理或者理论,肯定是越简单的表达方式越接近真实。
2:使用所有的训练集合进行训练,但是用统计测试来估计修剪特定结点是否会改善训练集合外的数据的评估性能,如使用Chi-Square(Quinlan,1986)测试来进一步扩展结点是否能改善整个分类数据的性能,还是仅仅改善了当前训练集合数据上的性能。
c:使用明确的标准来衡量训练样例和决策树的复杂度,当编码长度最小时,停止树增长,如MDL(Minimum Description Length)准则。就像大家经常说的,一个真理或者理论,肯定是越简单的表达方式越接近真实。
2.剪枝的具体方法介绍
以上面提到的思路a为借鉴,错误率降低剪枝(ERP)
错误率降低剪枝考虑将树上的每个节点做修剪的候选对象,决定是否修剪这个节点有如下步骤组成:
1):删除以此节点为根的子树
2):让这个节点变为叶子结点
3):赋予这个节点关联的训练数据的最常见分类(例如通过这个借点的类有A,B,C,统计发现这个节点的叶结点更多是A,则被叶结点替换后选则A类)
4):当当这样修剪后验证集的性能没有比原来树的差时,才正真的删除这个节点,或者说以叶结点代替子树。
因为训练集合的过拟合,使得验证集合数据能够对其进行修正,反复进行上面的操作,从底向上的处理节点,删除那些能够最大限度的提高验证集合的精度的节点,直到进一步修剪有害为止(有害是指修剪会减低验证集合的性能)。
REP是最简单的后剪枝方法之一,不过在数据量比较少的情况下,REP方法却是较少使用。因为训练数据集合中的特性在剪枝过程中被忽略,所以在验证数据集合比训练数据集合小的多时,要注意这个问题。而且数据量较少的话,我们还要分出训练集好验证集,这也是个考验。
尽管REP有这个缺点,不过REP仍然作为一种基准来评价其它剪枝算法的性能。它对于两阶段决策树学习方法的优点和缺点提供了了一个很好的学习思路。由于验证集合没有参与决策树的创建,所以用REP剪枝后的决策树对于测试样例的偏差要好很多,能够解决一定程度的过拟合问题,效用不是很明显。
尽管REP有这个缺点,不过REP仍然作为一种基准来评价其它剪枝算法的性能。它对于两阶段决策树学习方法的优点和缺点提供了了一个很好的学习思路。由于验证集合没有参与决策树的创建,所以用REP剪枝后的决策树对于测试样例的偏差要好很多,能够解决一定程度的过拟合问题,效用不是很明显。
上面提到的ERP是最简单的剪枝方法,思路简单粗暴。但是因为需要一个验证集来协助,在数据量较少的时候这也算是一个缺点吧,下面介绍的
悲观剪枝可以克服这样的缺点。
悲观剪枝就是递归式的计算每个内部节点所覆盖样本节点的误判率。剪枝后该内部节点会变成一个叶子节点,该叶子节点的类别为原内部节点的最优叶结点所决定。具体怎样选择最优叶结点,下文会有介绍。然后比较剪枝前后该节点的错误率来决定是否进行剪枝。该方法和前面提到的第一种方法思路是一致的,不同之处在于如何估计剪枝前后分类树内部节点的错误率。
对于具有多个叶子结点的一棵树,如果我们用一个叶子结点来代替的话,那么修改后的决策树对于原来的训练集的误判率肯定是上升的。但是对于验证集或者说测试集,修改后的决策树可能会有一个好的表现。在训练集的表现可能会比新的数据集差,那么就根据子树被换后出现误判的情况,我们在计算过程中加一个经验性的惩罚参数,也有称之为惩罚因子。但是这个参数的大小没有一个规则去判定和计算,所以这个参数的选定是根据经验获得的,也可称为经验性的惩罚因子。
这个参数如何加入我们的计算比较合适???请看这个公式:(E+0.5)/N。这个公式是这样解释的,0.5就是惩罚因子,一棵树的一个叶子结点,覆盖了N个样本(有正确分类的有错误分类的),其中错误分类的是E个,这个公式计算的是这个叶子节点的错误率。那么一颗子树,它有L个叶子节点,每个叶子节点都有可能会拿来去替代这个子树,那么这个子树的误判率计算得: 。这样的话我们可以看到一颗子树虽然被某个叶子结点替换,并且造成一定的误判率,但是子树的每个叶结点都加了惩罚因子,所以子树的误判率提升,和叶结点被替换后产生的误判比较并没有占到便宜。在这里了我们可以认为近似。
。这样的话我们可以看到一颗子树虽然被某个叶子结点替换,并且造成一定的误判率,但是子树的每个叶结点都加了惩罚因子,所以子树的误判率提升,和叶结点被替换后产生的误判比较并没有占到便宜。在这里了我们可以认为近似。
我们假设剪枝前,由剪枝的节点处导致误判个数是M个,剪枝后内部节点变成了叶子节点,那么误判个数M也需要加上一个惩罚因子,变成M+0.5。这个子树是否可以被剪枝替换掉的条件就是M+0.5是否 在 的标准误差之内。对于样本的误差率e,即前面说的误判率,可以根据经验把它估计成各种各样常见的分布模型,比如是二项式分布,比如是正态分布。
的标准误差之内。对于样本的误差率e,即前面说的误判率,可以根据经验把它估计成各种各样常见的分布模型,比如是二项式分布,比如是正态分布。
假设决策树错误分类一个样本,错误的值加1,否则就加0,该树错误分类的概率(误判率)为e,e为决策树误判的属性,可以通过以下公式计算:
由刚刚我们的假设可知误判次数就是伯努利分布,我们可以估计出该树的误判次数均值和标准差:
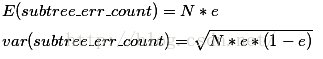
因此把子树替换成叶子节点后,该叶子的误判次数也看做是一个伯努利分布,其概率误判率e为(E+0.5)/N,因此叶子节点的误判次数均值为

在此之前我们下过结论:使用训练数据,子树总是比替换为一个叶节点后产生的误差小,但是使用校正后有误差计算方法却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝(当然这是经过惩罚因子处理之后的计算值):
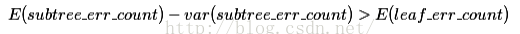
下面我们举一个实例:
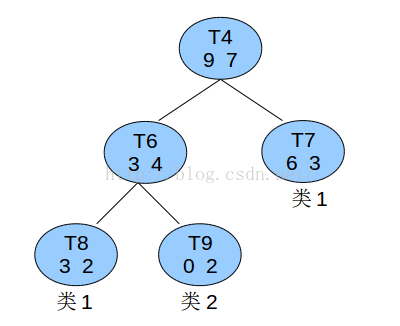
上图是一颗子树,目标类别是2个:类1和类2.三个叶结点,左边是
计算子树的误差率:
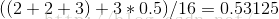
计算着颗子树的误差率的标准误差:

子树替换为一个叶节点后,其误差率为: ,可以看到M+0.5就是7+0.5
,可以看到M+0.5就是7+0.5
因为8.5-1.996<7.5,所以不能决定将子树T4替换这一个叶子节点。
总觉得我的理解和网上其他的理解结论不同,希望大牛指点。
对于具有多个叶子结点的一棵树,如果我们用一个叶子结点来代替的话,那么修改后的决策树对于原来的训练集的误判率肯定是上升的。但是对于验证集或者说测试集,修改后的决策树可能会有一个好的表现。在训练集的表现可能会比新的数据集差,那么就根据子树被换后出现误判的情况,我们在计算过程中加一个经验性的惩罚参数,也有称之为惩罚因子。但是这个参数的大小没有一个规则去判定和计算,所以这个参数的选定是根据经验获得的,也可称为经验性的惩罚因子。
这个参数如何加入我们的计算比较合适???请看这个公式:(E+0.5)/N。这个公式是这样解释的,0.5就是惩罚因子,一棵树的一个叶子结点,覆盖了N个样本(有正确分类的有错误分类的),其中错误分类的是E个,这个公式计算的是这个叶子节点的错误率。那么一颗子树,它有L个叶子节点,每个叶子节点都有可能会拿来去替代这个子树,那么这个子树的误判率计算得:
。这样的话我们可以看到一颗子树虽然被某个叶子结点替换,并且造成一定的误判率,但是子树的每个叶结点都加了惩罚因子,所以子树的误判率提升,和叶结点被替换后产生的误判比较并没有占到便宜。在这里了我们可以认为近似。我们假设剪枝前,由剪枝的节点处导致误判个数是M个,剪枝后内部节点变成了叶子节点,那么误判个数M也需要加上一个惩罚因子,变成M+0.5。这个子树是否可以被剪枝替换掉的条件就是M+0.5是否 在
的标准误差之内。对于样本的误差率e,即前面说的误判率,可以根据经验把它估计成各种各样常见的分布模型,比如是二项式分布,比如是正态分布。假设决策树错误分类一个样本,错误的值加1,否则就加0,该树错误分类的概率(误判率)为e,e为决策树误判的属性,可以通过以下公式计算:
由刚刚我们的假设可知误判次数就是伯努利分布,我们可以估计出该树的误判次数均值和标准差:
因此把子树替换成叶子节点后,该叶子的误判次数也看做是一个伯努利分布,其概率误判率e为(E+0.5)/N,因此叶子节点的误判次数均值为
在此之前我们下过结论:使用训练数据,子树总是比替换为一个叶节点后产生的误差小,但是使用校正后有误差计算方法却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝(当然这是经过惩罚因子处理之后的计算值):
以上公式就是剪枝的标准。
下面我们举一个实例:
上图是一颗子树,目标类别是2个:类1和类2.三个叶结点,左边是
计算子树的误差率:
计算着颗子树的误差率的标准误差:
子树替换为一个叶节点后,其误差率为:
,可以看到M+0.5就是7+0.5因为8.5-1.996<7.5,所以不能决定将子树T4替换这一个叶子节点。
总觉得我的理解和网上其他的理解结论不同,希望大牛指点。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









