




RLBoost:利用可抢占资源实现高效强化学习训练
强化学习已成为解锁大型语言模型高级推理能力的关键技术。然而,RL工作流程中的rollout和训练阶段具有根本不同的资源需求,现有框架难以有效解决这一资源紧张问题。RLBoost通过创新的混合架构,利用可抢占GPU资源,实现了1.51x-1.97x的训练吞吐量提升和28%-49%的成本效率改善,为大规模RL训练提供了新的解决方案。
论文标题: RLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
来源: arXiv:2510.19225
链接: http://arxiv.org/abs/2510.19225
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
强化学习(RL)已成为解锁大型语言模型(LLMs)高级推理能力的关键技术,广泛应用于数学、编程和工具使用等任务。RL工作流程主要由两个相互依赖的阶段组成:rollout阶段和训练阶段。rollout阶段通常占整体执行时间的73%以上,且能通过多个独立实例高效扩展;而训练阶段则需要紧密耦合的GPU和全网格通信。现有RL框架分为两类:collocated架构和disaggregated架构。前者强制两个阶段共享相同GPU,无法解决资源紧张问题;后者在不修改已建立的RL算法的情况下,遭受资源利用不足的问题。与此同时,可抢占GPU资源(如公共云上的spot实例和生产集群中的备用容量)为加速RL工作流程提供了显著的节省成本机会。

研究问题
- 资源需求不匹配:rollout阶段需要多个独立实例并具有状态无关性,而训练阶段需要紧密耦合的GPU和全网格通信,两者资源需求根本不同
- 资源利用效率低:现有collocated架构无法解决资源紧张,disaggregated架构在同步RL算法下遭受资源利用不足
- 成本效益不佳:无法有效利用可抢占资源(如spot实例),这些资源成本可低至按需实例的10%,但具有不可预测的可用性
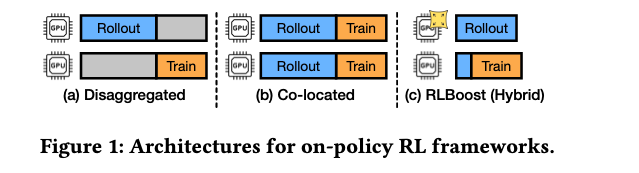
主要贡献
- 混合架构设计:提出混合架构,利用可抢占资源进行高吞吐量和成本效益的RL训练,保持训练集群的同时将rollout工作负载转移到可抢占实例
- 自适应rollout卸载机制:设计自适应rollout卸载机制,通过部分响应种子技术动态调整训练集群工作负载以适应实时资源可用性
- 基于拉取的权重传输:开发基于拉取的权重传输机制,使新分配的实例能够快速加入并参与当前步骤的rollout
- 令牌级响应收集和迁移:实现令牌级响应收集和迁移,最小化抢占开销并实现连续负载平衡
方法论精要
RLBoost采用混合架构,结合了collocated和disaggregated架构的优点,同时利用可抢占资源提高成本效率。系统核心包含保留训练集群和弹性可抢占实例池,通过rollout管理器协调两个集群的工作。
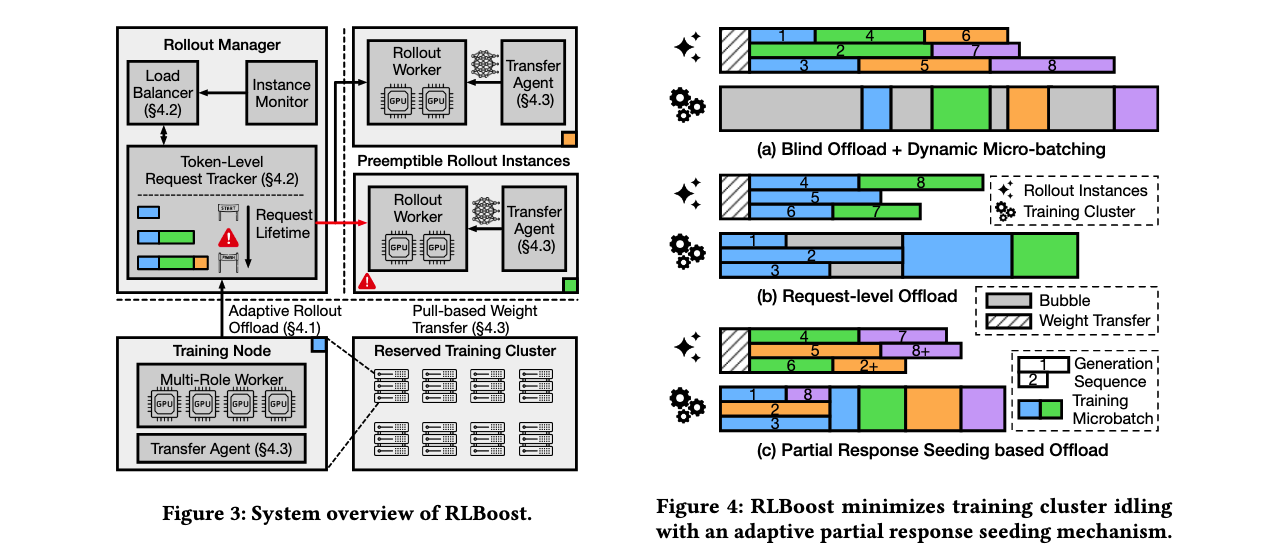
自适应rollout卸载机制
RLBoost面临的关键挑战是如何在动态资源可用性下平衡训练集群和远程rollout实例之间的执行。传统方法要么盲目卸载所有rollout计算,要么按固定数量分配样本,这些方法都存在效率问题。
部分响应种子机制是RLBoost的创新解决方案。不同于控制卸载的rollout样本数量,RLBoost将训练集群限制在每个步骤开始时仅在特定时间窗口内执行rollout,然后转换为训练模式。对于长尾响应,训练集群"种子化"部分响应供rollout实例继续处理。由于rollout实例只需对已生成的token执行单次prefill,迁移部分生成的响应引入的开销最小。
算法1展示了自适应调度算法,它动态调整种子窗口 T s e e d T_{seed} Tseed并强制执行最大允许的远程rollout实例数量 N p r e m N_{prem} Nprem。每个步骤中,RLBoost跟踪训练集群的空闲时间 t t r a i n w a i t t^{wait}_{train} ttrainwait和远程rollout实例的空闲时间 t r e m o t e w a i t t^{wait}_{remote} tremotewait。通过平衡这两个目标,采用反馈驱动机制逐步调整 T s e e d T_{seed} Tseed,在波动下保持稳定性并适应不断变化的工作负载模式。
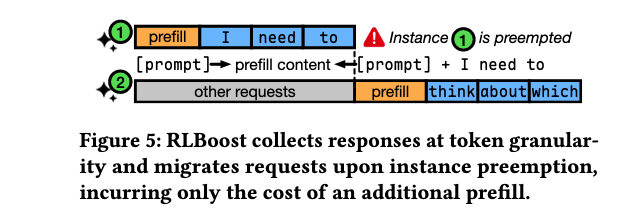
令牌级响应收集和迁移
由于rollout实例可能随时被抢占,路由到它的请求可能无法完成生成。RLBoost的rollout管理器以令牌粒度收集响应,为每个请求启动异步任务以流方式跟踪和接收响应token。
当实例被抢占时,RLBoost保留路由到该实例的请求的部分生成响应,并将请求迁移到健康实例继续生成。重定向实例只需对连接的prompt和先前生成的token执行prefill操作,与从头开始生成相比,开销可忽略不计。
连续负载均衡基于令牌级响应收集能力,包含两个主要组件:SelectInstance用于初始候选实例选择和抢占时的重新路由;ContinuousLB是后台监控任务,根据需要在实例间连续迁移和重新分配样本。
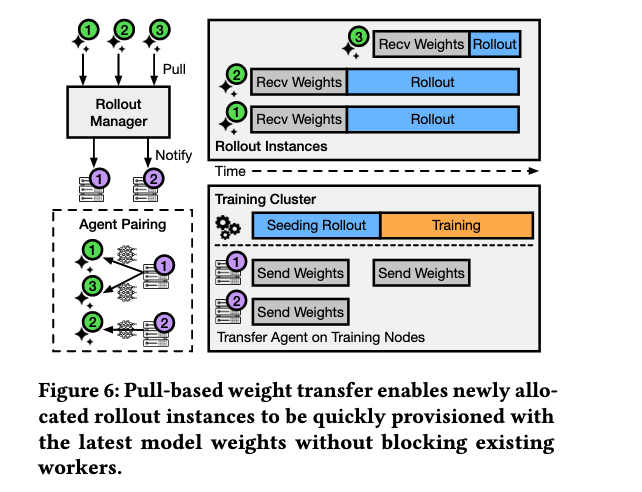
基于拉取的权重传输
传统同步权重更新方法在步骤完成后才传输权重,导致中途加入的实例无法处理请求直到下一步骤。RLBoost采用基于拉取的传输代理异步传输权重,使新分配的rollout实例能够快速获取最新模型权重并立即开始生成。
传输代理是驻留在每个训练节点和rollout实例上的独立进程。在集群内all-gather期间,每个训练节点将完整模型权重从GPU复制到传输代理管理的预分配CPU缓冲区。然后训练集群立即开始种子rollout,而不等待权重传递到所有rollout实例。每个rollout实例以循环方式与权重传输代理配对并建立点对点连接,在初始注册或模型更新时独立拉取最新权重。
实验洞察
实验在公共云上的H100 GPU实例进行评估,使用8B到32B模型,比较了性能和成本效率。训练集群使用配备8个H100 GPU的按需实例,可抢占rollout实例使用配备2个H100 GPU的spot实例。
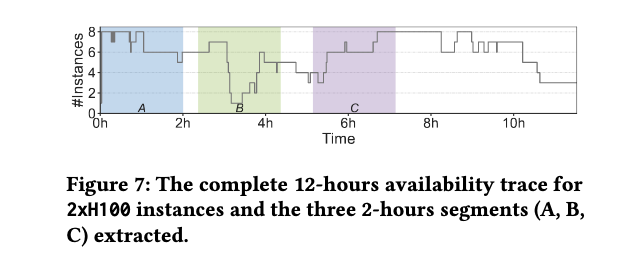
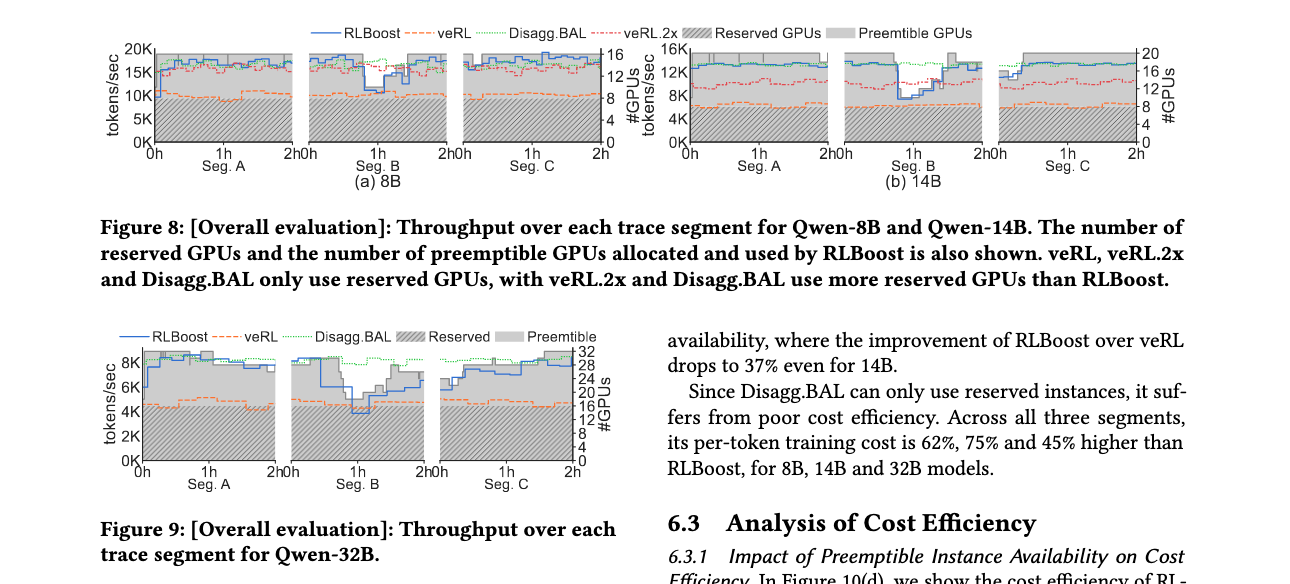
整体性能评估
与veRL(collocated架构)相比,RLBoost在三个测试段中分别实现了8B、14B和32B模型1.66x、1.97x和1.51x的平均吞吐量提升。甚至比使用两个8xH100实例的veRL.2x高出24%的吞吐量,因为veRL.2x中的FSDP训练跨越两个节点并遭受额外开销。
在成本效率方面,RLBoost相比veRL分别提高了8B、14B和32B模型34%、49%和28%的训练成本效率。在实例可用性较高的A段,RLBoost相比veRL的成本效率提升分别为36%、53%和45%。Disagg.BAL只能使用保留实例,成本效率较差,在所有三个段中,每token训练成本比RLBoost分别高出62%、75%和45%。
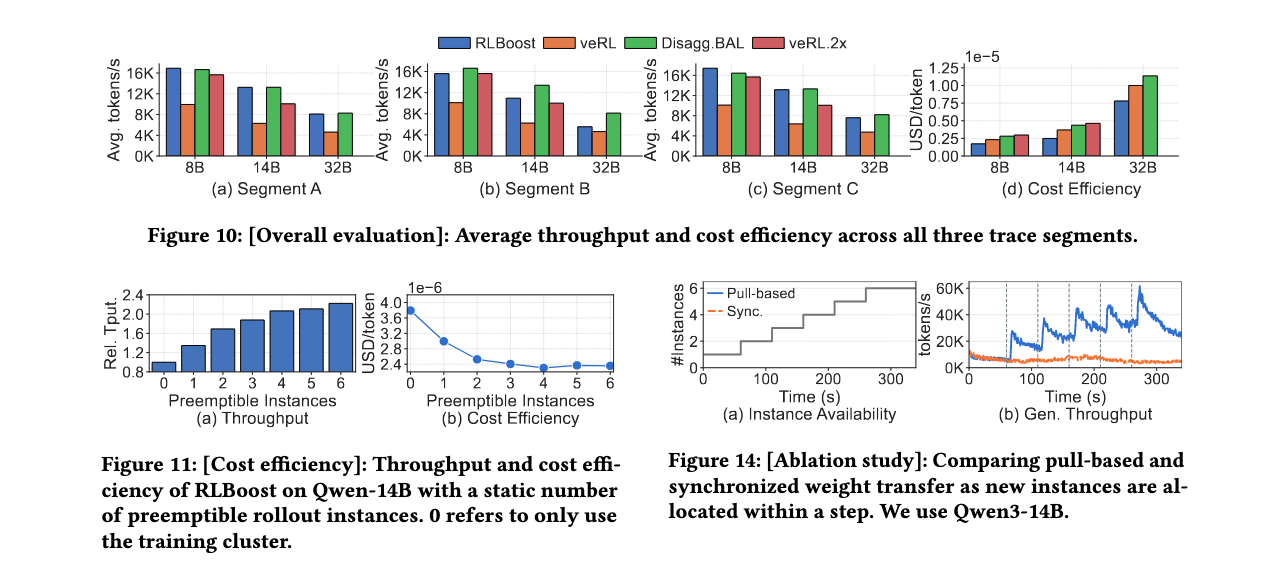
成本效率分析
可抢占实例可用性影响:即使只有一个实例,吞吐量也增加37%,每token训练成本降低22%。使用6个实例,相比单个实例吞吐量进一步增加64%,成本进一步降低21%。
最大响应长度影响:随着响应长度从5K增加到14K,最优可抢占实例数量($ N_{prem} $)从3增加到6。RLBoost将相对吞吐量提升1.47x-2.22x,相对成本效率提升1.24x-1.61x。
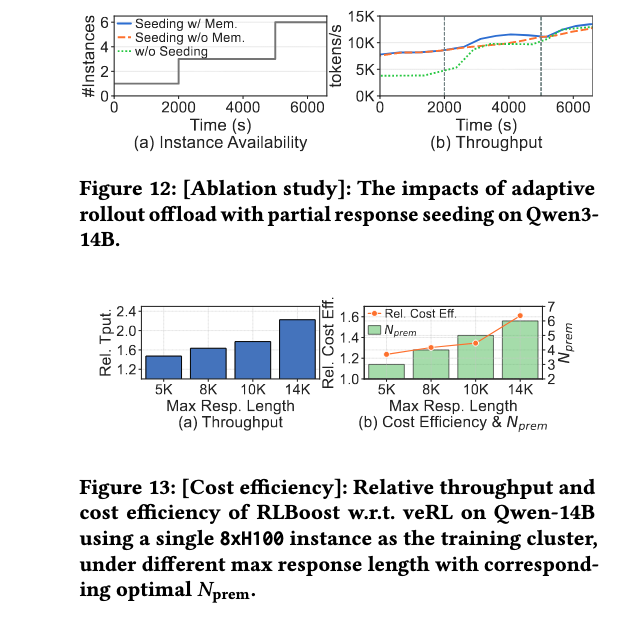
消融研究
自适应rollout卸载影响:没有种子机制时,RLBoost在初始阶段(抢占后只剩单个实例)训练吞吐量显著较低。在整个测试期间,无种子相比完整解决方案平均吞吐量降低19%。有调度器内存相比无内存进一步提高了6%的平均吞吐量。
权重传输范式影响:基于拉取的权重传输使RLBoost能够立即使用新实例进行rollout,而传统同步权重传输只能在下一步使用新实例,造成大量资源浪费。
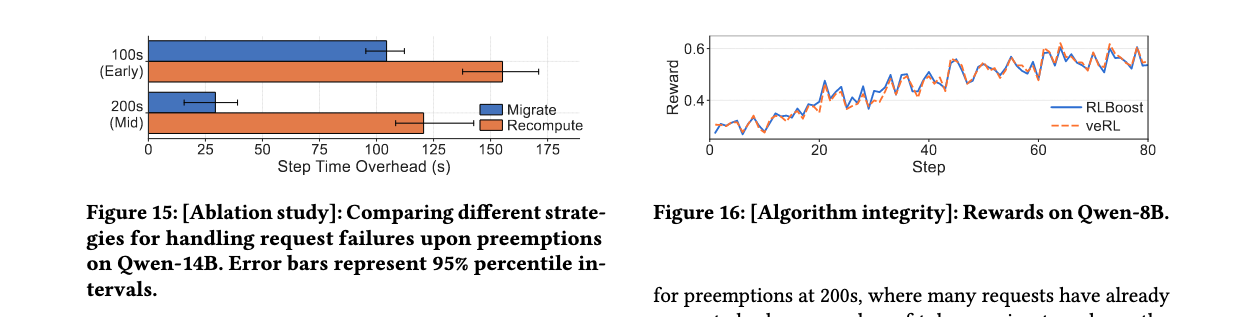
故障处理影响:对于早期抢占(步骤开始后100秒),迁移策略仅减少33%的开销。对于中期抢占(200秒),迁移策略减少76%的开销,证明令牌级响应收集的有效性。
算法完整性
与许多disaggregated框架不同,RLBoost保持已建立的同步RL算法。RLBoost的训练奖励曲线与veRL密切匹配,证明RLBoost对同步GRPO算法没有修改,使用相同的训练设置,保持了算法完整性。
RLBoost通过创新的混合架构设计,成功解决了RL训练中的资源紧张问题,利用可抢占资源实现了显著的性能提升和成本节约,为大规模RL训练提供了高效实用的解决方案。


















 2335
2335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









