







爬取故事文学网小,中,高所有故事、文言文




查看源代码,一开始以为很顺利,结果却报错了,对比其他页面才发现id="contson后面的值是跟随url变的
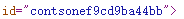

本以为接下来会一切顺利,接下来还报错了,仔细一看才发现原来古诗和文言文的url格式并不一样


一个是.cn另一个是.org,现在才发现,不注意细节的我毁了多少女子的温柔
再次忠告:注意细节!!!!!
好了,话不多说代码赠上
import requests
import re
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTMLl like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
def kind(url):#获取小学,初中,高中的诗词的url,name,作者,朝代
html=requests.get(url=url,headers=headers)
html.encoding='utf-8'
html=html.text
shi_info=re.findall('<div class="main3">(.*?)<div id="btmwx"',html,re.S)
shi_info=str(shi_info)
shi_list=re.findall('<span><a href="(.*?)" target="_blank">(.*?)</a>(.*?)</span>',str(shi_info))
for url2,name,zz in shi_list:
main(url2,name,zz,url)
def main(url,name,zz,s):#获取内容
try:
html=requests.get(url=url,headers=headers)
html.encoding='utf-8'
html=html.text
key=re.findall('https://so.gushiwen.cn/shiwenv_(.*?).aspx',url)[0]
shi=re.findall('<div class="contson" id="contson{}">(.*?)</div>'.format(key),html,re.S)[0].replace('\n','').replace('<br />','').replace('<p>','').replace('</p>','').replace(' ','')
All=name+'@'+name+','+zz+','+shi+'\n'
#w(All)
print('='*80)
print(name+'获取并输出完毕'+'内容节选:------'+shi[10:16]+s[30:39])
print('='*80)
except:
html=requests.get(url=url,headers=headers)
html.encoding='utf-8'
html=html.text
key=re.findall('https://so.gushiwen.org/shiwenv_(.*?).aspx',url,re.S)[0]
shi=re.findall('<div class="contson" id="contson{}">(.*?)</div>'.format(key),html,re.S)[0].replace('\n','').replace('<br />','').replace('<p>','').replace('</p>','').replace(' ','')
All=name+'@'+name+','+zz+','+shi+'\n'
w(All)
print('='*80)
print(name+'获取并输出完毕'+'内容节选:------'+shi[10:16]+s[30:39])
print('='*80)
def w(info):#写入txt数据库
f=open('main.txt','a',encoding='utf-8')
f.write(info)
f.close()
time.sleep(2)
urls=['https://so.gushiwen.cn/wenyan/xiaowen.aspx','https://so.gushiwen.cn/wenyan/chuwen.aspx','https://so.gushiwen.cn/wenyan/gaowen.aspx','https://so.gushiwen.cn/gushi/xiaoxue.aspx','https://so.gushiwen.cn/gushi/chuzhong.aspx','https://so.gushiwen.cn/gushi/gaozhong.aspx']#古诗url已下载
#urls_wen=['https://so.gushiwen.cn/wenyan/xiaowen.aspx','https://so.gushiwen.cn/wenyan/chuwen.aspx','https://so.gushiwen.cn/wenyan/gaowen.aspx']#文言文url
for url in urls:
print(url)
kind(url)
time.sleep(30)


至于为什么要以这种格式保存,emmmmm----我说为了好看你信吗?🙄















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









