









PyTorch之BN核心参数详解
原始文档:https://www.yuque.com/lart/ugkv9f/qoatss
affine
初始化时修改
affine 设为 True 时,BatchNorm 层才会学习参数 gamma 和 beta,否则不包含这两个变量,变量名是 weight 和 bias。
.train()
- 如果
affine==True,则对归一化后的 batch 进行仿射变换,即乘以模块内部的 weight(初值是[1., 1., 1., 1.])然后加上模块内部的 bias(初值是[0., 0., 0., 0.]),这两个变量会在反向传播时得到更新。 - 如果
affine==False,则 BatchNorm 中不含有 weight 和 bias 两个变量,什么都都不做。
.eval()
- 如果
affine==True,则对归一化后的 batch 进行放射变换,即乘以模块内部的 weight 然后加上模块内部的 bias,这两个变量都是网络训练时学习到的。 - 如果
affine==False,则 BatchNorm 中不含有 weight 和 bias 两个变量,什么都不做。
修改实例属性
无影响,仍按照初始化时的设定。
track_running_stats
由于 BN 的前向传播中涉及到了该属性,所以实例属性的修改会影响最终的计算过程。
class _NormBase(Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ['track_running_stats', 'momentum', 'eps',
'num_features', 'affine']
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True
) -> None:
super(_NormBase, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
if self.affine:
self.weight = Parameter(torch.Tensor(num_features))
self.bias = Parameter(torch.Tensor(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
self.reset_parameters()
...
class _BatchNorm(_NormBase):
...
def forward(self, input: Tensor) -> Tensor:
self._check_input_dim(input)
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
if self.num_batches_tracked is not None: # type: ignore
self.num_batches_tracked = self.num_batches_tracked + 1 # type: ignore
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
可以看到这里的bn_training控制的是,数据运算使用当前batch计算得到的统计量(True)
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
这里强调的是统计量buffer的使用条件(self.running_mean, self.running_var)
- training==True and track_running_stats==False, 这些属性被传入F.batch_norm中时,均替换为None
- training==True and track_running_stats==True, 会使用这些属性中存放的内容
- training==False and track_running_stats==True, 会使用这些属性中存放的内容
- training==False and track_running_stats==False, 会使用这些属性中存放的内容
"""
assert self.running_mean is None or isinstance(self.running_mean, torch.Tensor)
assert self.running_var is None or isinstance(self.running_var, torch.Tensor)
return F.batch_norm(
input,
# If buffers are not to be tracked, ensure that they won't be updated
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
self.weight, self.bias, bn_training, exponential_average_factor, self.eps)
.train()
注意代码中的注释:Buffers are only updated if they are to be tracked and we are in training mode. 即仅当为训练模式且track_running_stats==True时会更新这些统计量 buffer。
另外,此时self.training==True。bn_training=True。
track_running_stats==True
BatchNorm 层会统计全局均值 running_mean 和方差 running_var,而对 batch 归一化时,仅使用当前 batch 的统计量。
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
使用 momentum 更新模块内部的 running_mean。
- 如果 momentum 是 None,那么就是用累计移动平均(这里会使用属性
self.num_batches_tracked来统计已经经过的 batch 数量),否则就使用指数移动平均(使用 momentum 作为系数)。二者的更新公式基本框架是一样的: x n e w = ( 1 − f a c t o r ) × x c u r + f a c t o r × x b a t c h x_{new}=(1 - factor) \times x_{cur} + factor \times x_{batch} xnew=(1−factor)×xcur+factor×xbatch
,只是具体的 f a c t o r factor factor 有所不同。- x n e w x_{new} xnew 代表更新后的 running_mean 和 running_var;
- x c u r x_{cur} xcur 表示更新前的running_mean和running_var;
- $x_{batch}$ 表示当前 batch 的均值和无偏样本方差。
- 累计移动平均的更新中 f a c t o r = 1 / n u m _ b a t c h e s _ t r a c k e d factor=1/num\_batches\_tracked factor=1/num_batches_tracked。
- 指数移动平均的更新公式是 f a c t o r = m o m e n t u m factor=momentum factor=momentum。
修改实例属性
如果设置.track_running_stats==False,此时self.num_batches_tracked不会更新,而且exponential_average_factor也不会被重新调整。
而由于:
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
且此时self.training==True,并且self.track_running_stats==False,所以送入F.batch_norm的self.running_mean&self.running_var两个参数都是 None。
也就是说,此时和直接在初始化中设置**track_running_stats==False**是一样的效果。
但是要小心这里的~~exponential_average_factor~~的变化。不过由于通常我们初始化 BN 时,仅仅会送入~~num_features~~,所以默认会使用~~exponential_average_factor = self.momentum~~来构造指数移动平均更新运行时统计量。(此时exponential_average_factor不会发挥作用)
track_running_stats==False
则 BatchNorm 中不含有 running_mean 和 running_var 两个变量,也就是仅仅使用当前 batch 的统计量来归一化 batch。
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
修改实例属性
如果设置.track_running_stats==True,此时self.num_batches_tracked仍然不会更新,因为其初始值是 None。
整体来看,这样的修改并没有实际影响。
.eval()
此时self.training==False。
self.running_mean if not self.training or self.track_running_stats else None,
self.running_var if not self.training or self.track_running_stats else None,
此时送入F.batch_norm的两个统计量 buffer 和初始化时的结果是一致的。
track_running_stats==True
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
此时bn_training = (self.running_mean is None) and (self.running_var is None) == False。所以使用全局的统计量。
对 batch 进行归一化,公式为
y
=
x
−
E
^
[
x
]
V
a
r
^
[
x
]
+
ϵ
y=\frac{x-\hat{E}[x]}{\sqrt{\hat{Var}[x]+\epsilon}}
y=Var^[x]+ϵx−E^[x],注意这里的均值和方差是running_mean 和 running_var,在网络训练时统计出来的全局均值和无偏样本方差。
修改实例属性
如果设置.track_running_stats==False,此时bn_training不变,仍未 False,所以仍然使用全局的统计量。也就是self.running_mean, self.running_var中存放的内容。
整体而言,此时修改属性没有影响。
track_running_stats==False
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
此时bn_training = (self.running_mean is None) and (self.running_var is None) == True。所以使用当前 batch 的统计量。
对 batch 进行归一化,公式为
y
=
x
−
E
[
x
]
V
a
r
[
x
]
+
ϵ
y=\frac{x-{E}[x]}{\sqrt{{Var}[x]+\epsilon }}
y=Var[x]+ϵx−E[x],注意这里的均值和方差是batch 自己的 mean 和 var,此时 BatchNorm 里不含有 running_mean 和 running_var。
注意此时使用的是无偏样本方差(和训练时不同),因此如果 batch_size=1,会使分母为 0,就报错了。
修改实例属性
如果设置.track_running_stats==True,此时bn_training不变,仍为 True,所以仍然使用当前 batch 的统计量。也就是忽略self.running_mean, self.running_var中存放的内容。
此时的行为和未修改时一致。
汇总
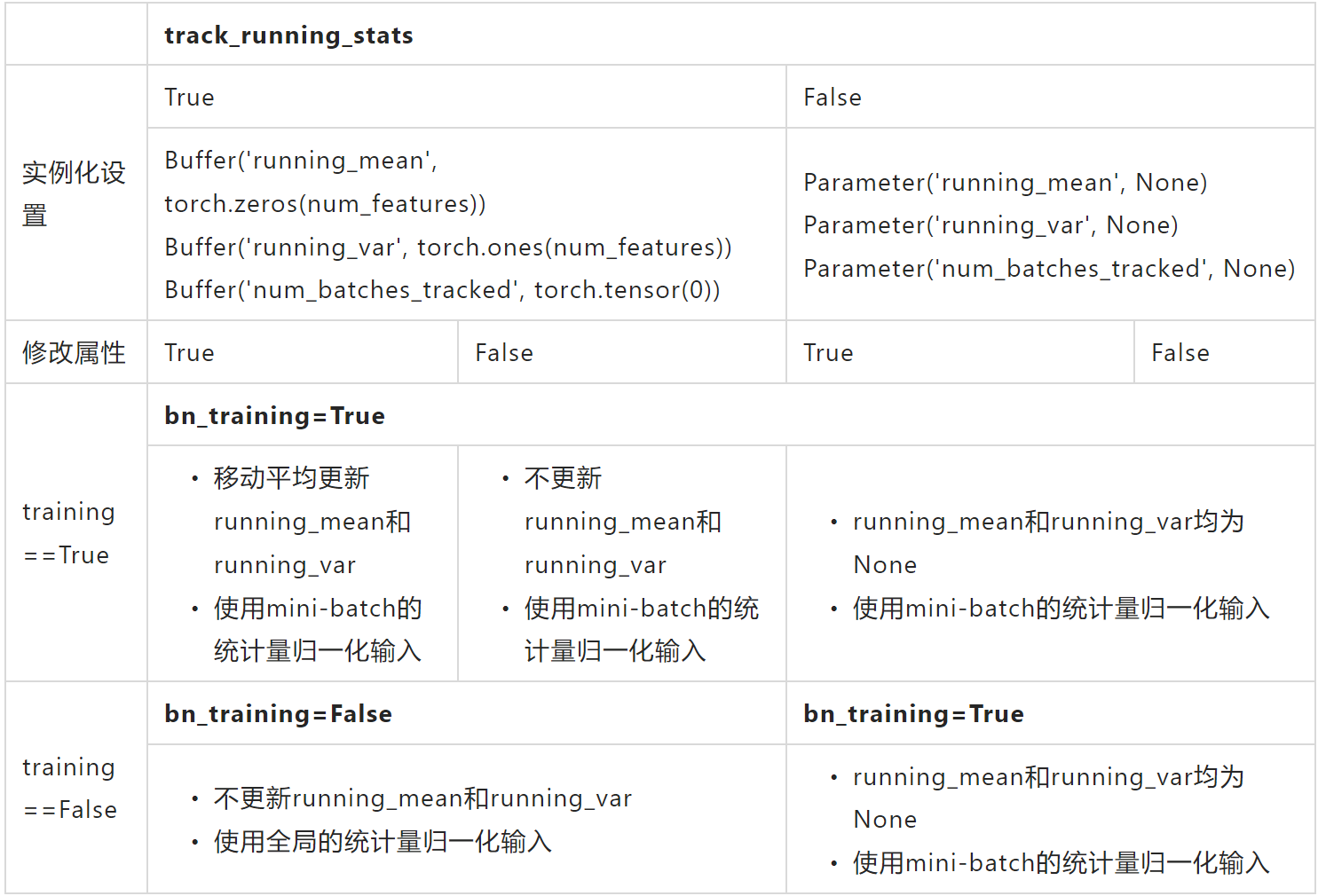
图片截图自原始文档。
参考
另外的话
欢迎关注我的公众号,文章更新提醒更及时哦:


















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









