







Arxiv 2203 - SepViT: Separable Vision Transformer

- 论文:https://arxiv.org/abs/2203.15380
- 解读:https://mp.weixin.qq.com/s/FxkiHYX-BKZ3-iewKNmXnw
- 核心目的:优化Attention计算。
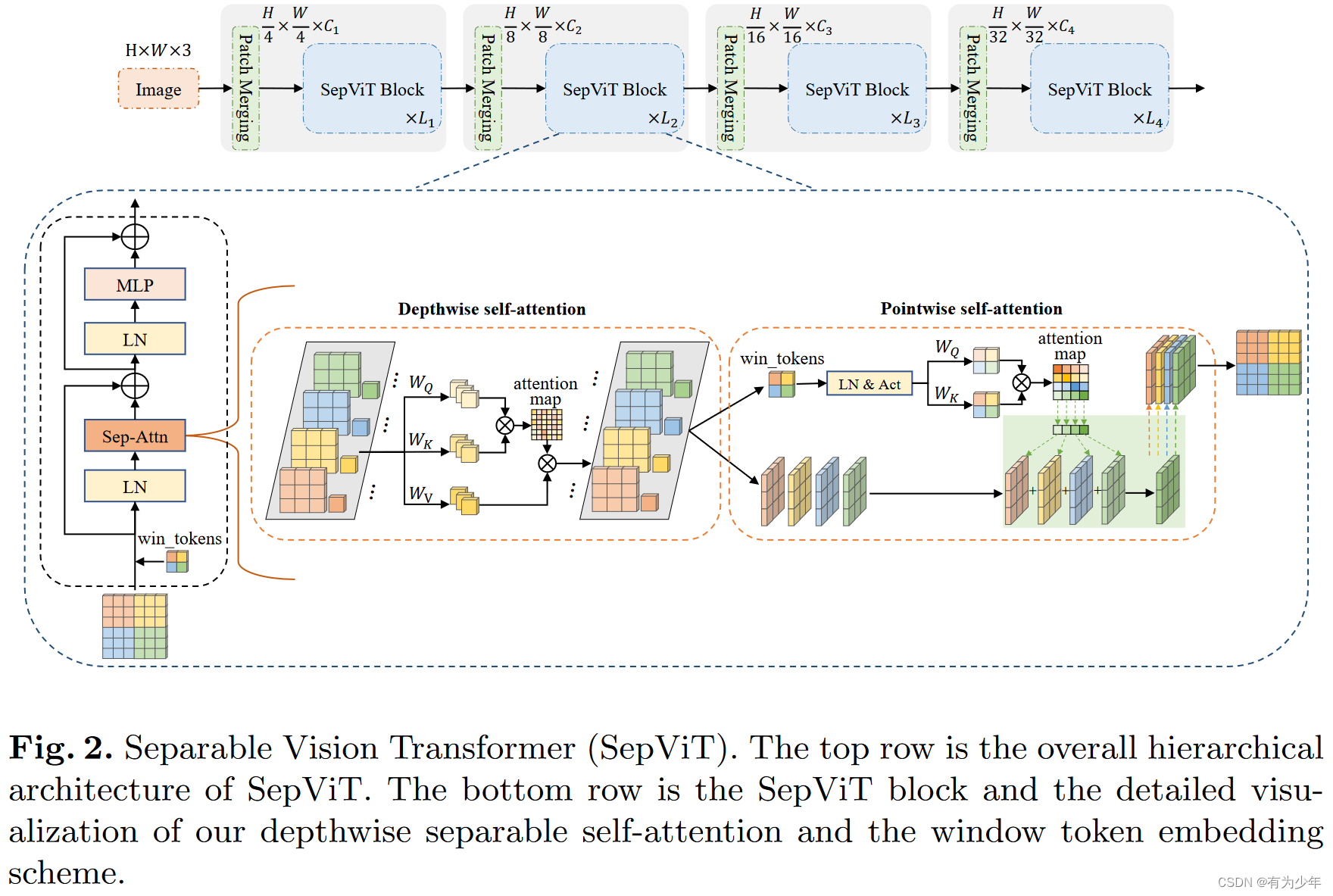
此外,SepViT还采用了条件位置编码(CPE)。对于每个阶段,都有一个重叠的Patch合并层用于特征图降采样,然后是一系列的SepViT Block。空间分辨率将以stride=4步或stride=2步逐步进行下采样,最终达到32倍下采样,通道尺寸也逐步增加一倍。
主要改动
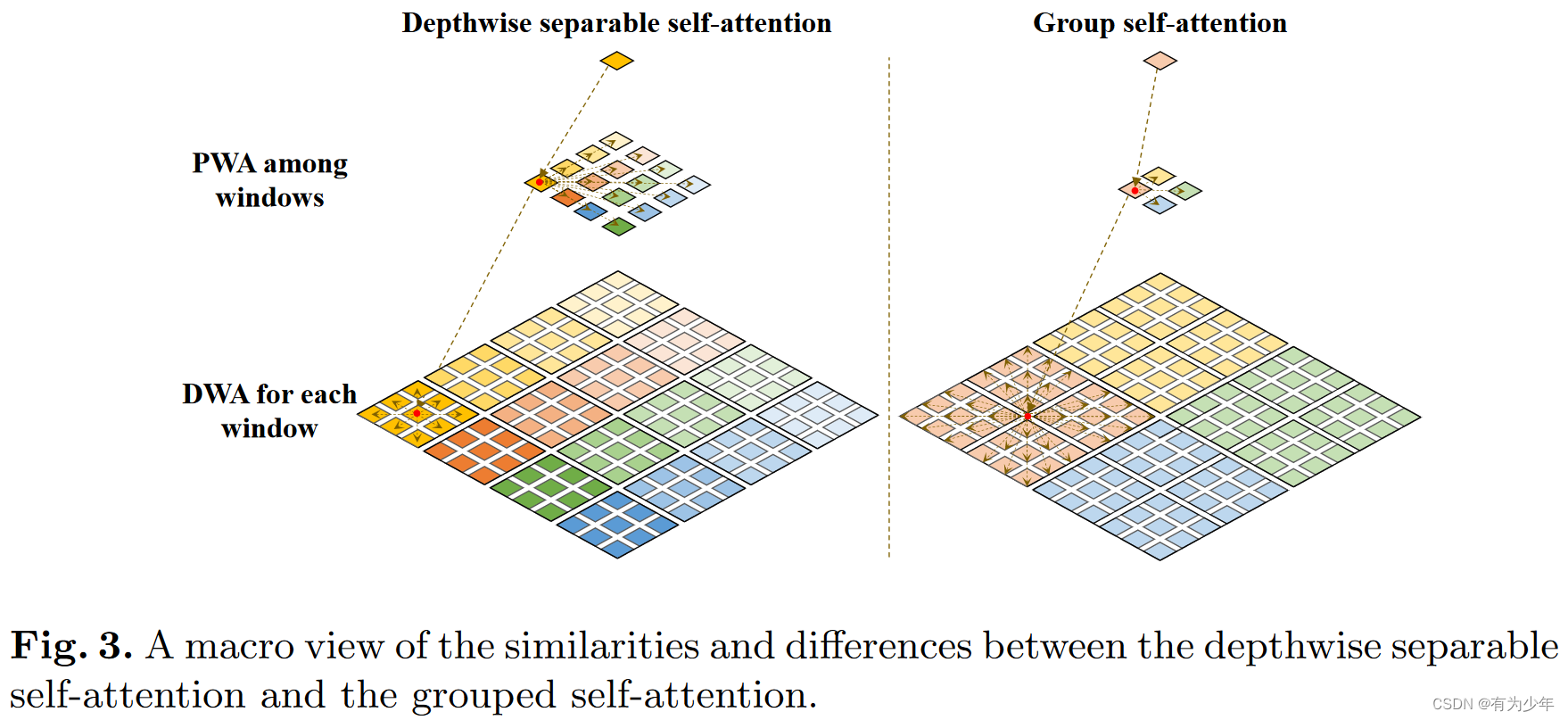
局部上下文和全局信息都可以在单个SepViT Block中捕获,而其他工作应该使用2个连续的Block来完成这种局部-全局建模。在SepViT块中,每个window内的局部信息通信是通过DepthWise Self-Attention(DWA)实现的,window间的全局信息交换是通过PointWise Self-Attention(PWA)进行。
- 受MobileNet中深度可分卷积的启发重新设计了Self-Attention模块:self-attention (SA)->depthwise separable self-attention (DSSA)。
- Depthwise Self-Attention(DWA):
- 这里仍然基于window-based self-attention。但是特别的是,会对不同的窗口引入一个独立的window token,作为窗口内中的整体表征,以便于简化之后的窗口之间的交互计算,该方法可以在极小的计算代价下模拟window间的注意力关系。这个Token可以初始化为0的固定向量或者可学习向量(实验展示可学习的效果更好,而且优于基于平均池化和深度分离卷积构造表征的策略)。 经过DWA,实现了window token和window内的pixel token的交互。因此可以作为该窗口的全局表征。
- 对window内所有像素token与对应window token的序列集合执行Attention操作。 这一操作处理单独窗口内的信息,可以将他们看做是输入特征图的一个通道,这些窗口包含着不同的信息。所以这里windowwise操作确实与depthwise convolution layer类似,旨在融合每个通道内的空间信息。
- Pointwise Self-Attention(PWA):通过模拟用于关联通道的pointwise convolution的动机,PWA构建了跨窗口的交互,从而得到最终的特征图。
- 先从DWA中提取特征图和window tokens。
- 在将window tokens用于建模窗口之间的注意力关系,并在LN和GELU之后通过两个独立的线性映射,获得Q和K。之后生成一个窗口之间的attention map。
- 同时直接将前面的特征图作为PWA的V(也就是没有额外的处理),对window维度进行全局加权,从而计算最终的输出。
- Depthwise Self-Attention(DWA):
- 还将AlexNet的分组卷积思想扩展到深度可分离Self-Attention,并提出了**grouped self-attention (GSA)**以进一步提高性能。
- 将相邻的子window拼接,形成更大的window,类似于将window分成组。
- 在一组window内使用DWA。通过这种方式,GSA可以捕获多个window的长期视觉依赖关系。
- 在计算成本和性能增益方面,GSA比DSSA具有一定的额外成本,但也具有更好的性能。
- 将具有GSA的块应用于SepViT,并在网络后期与DSSA交替运行。
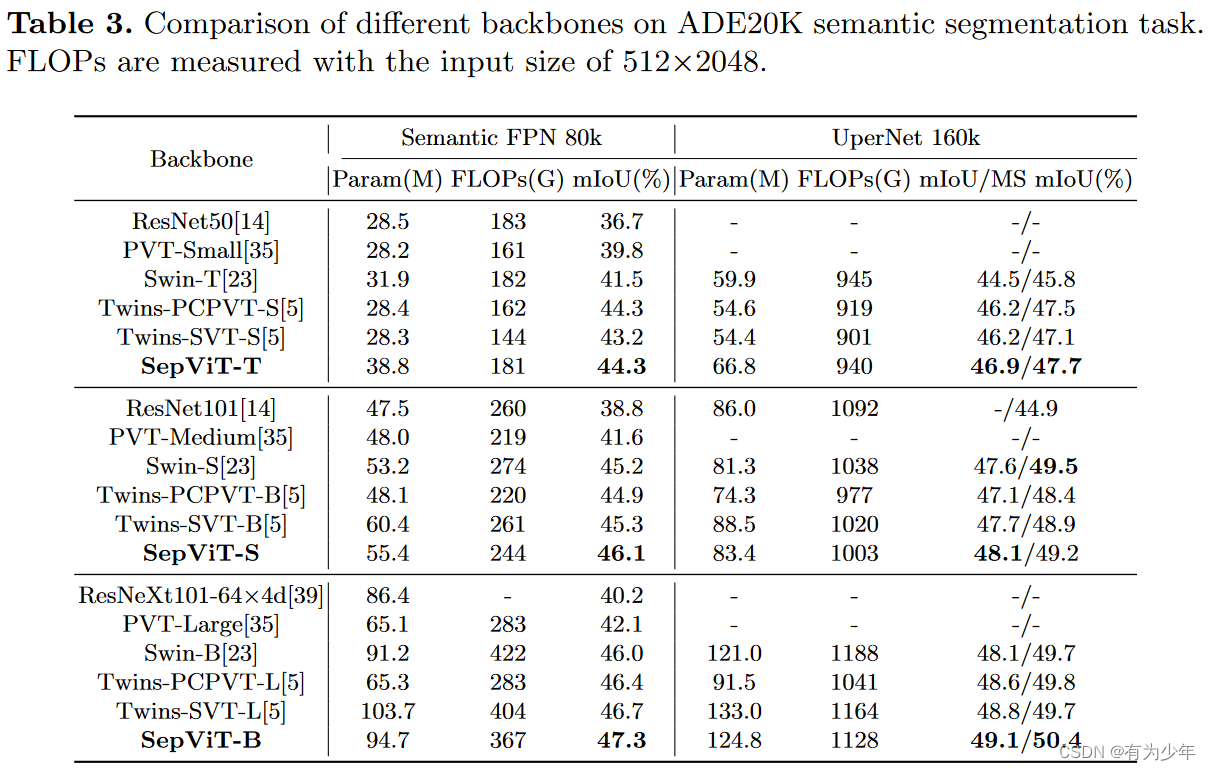
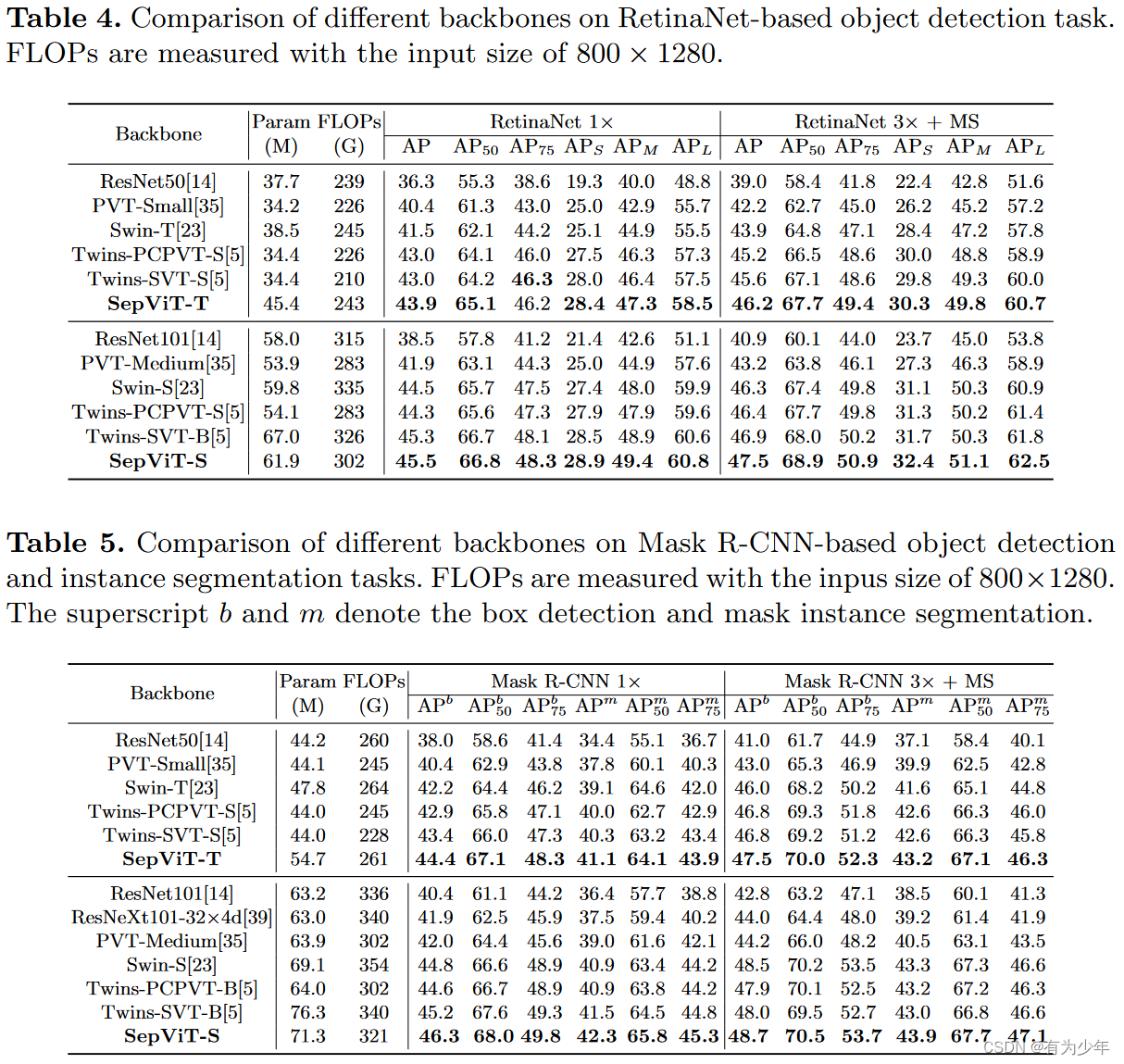
实验效果
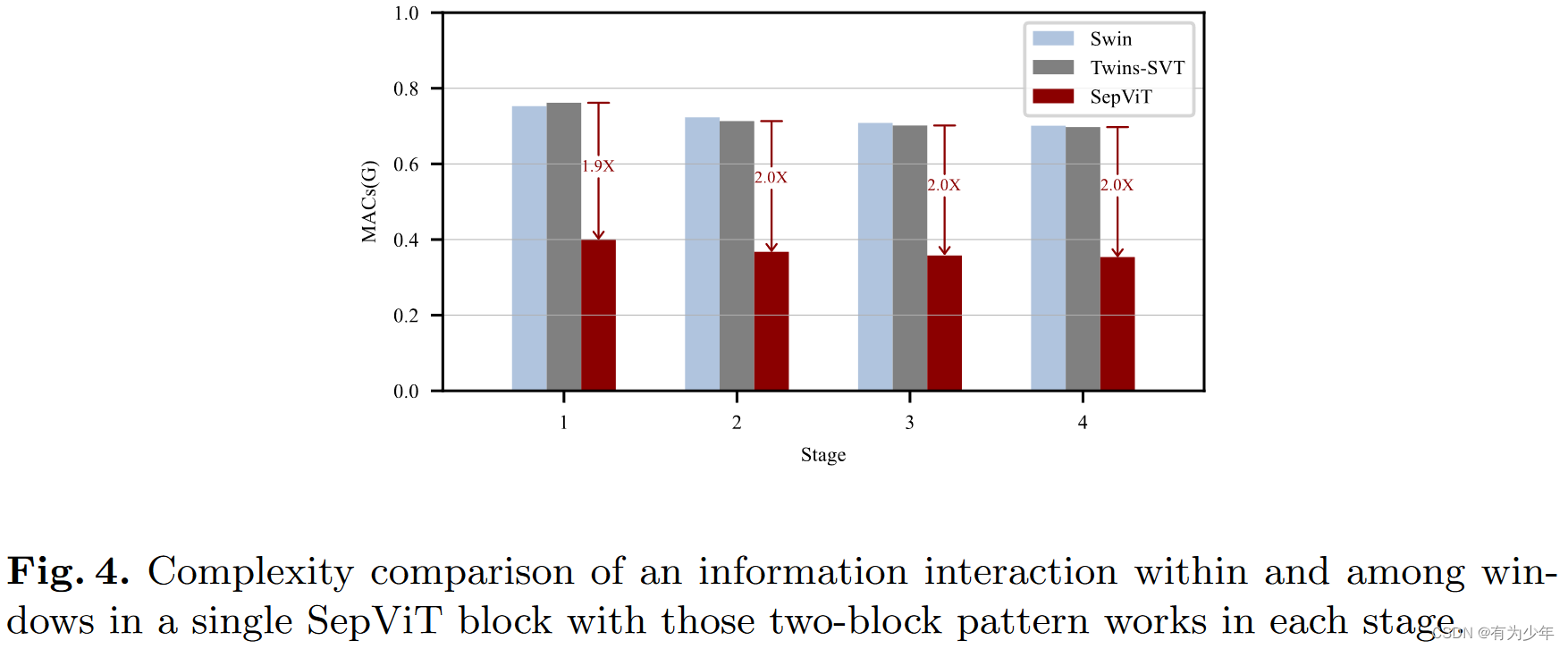
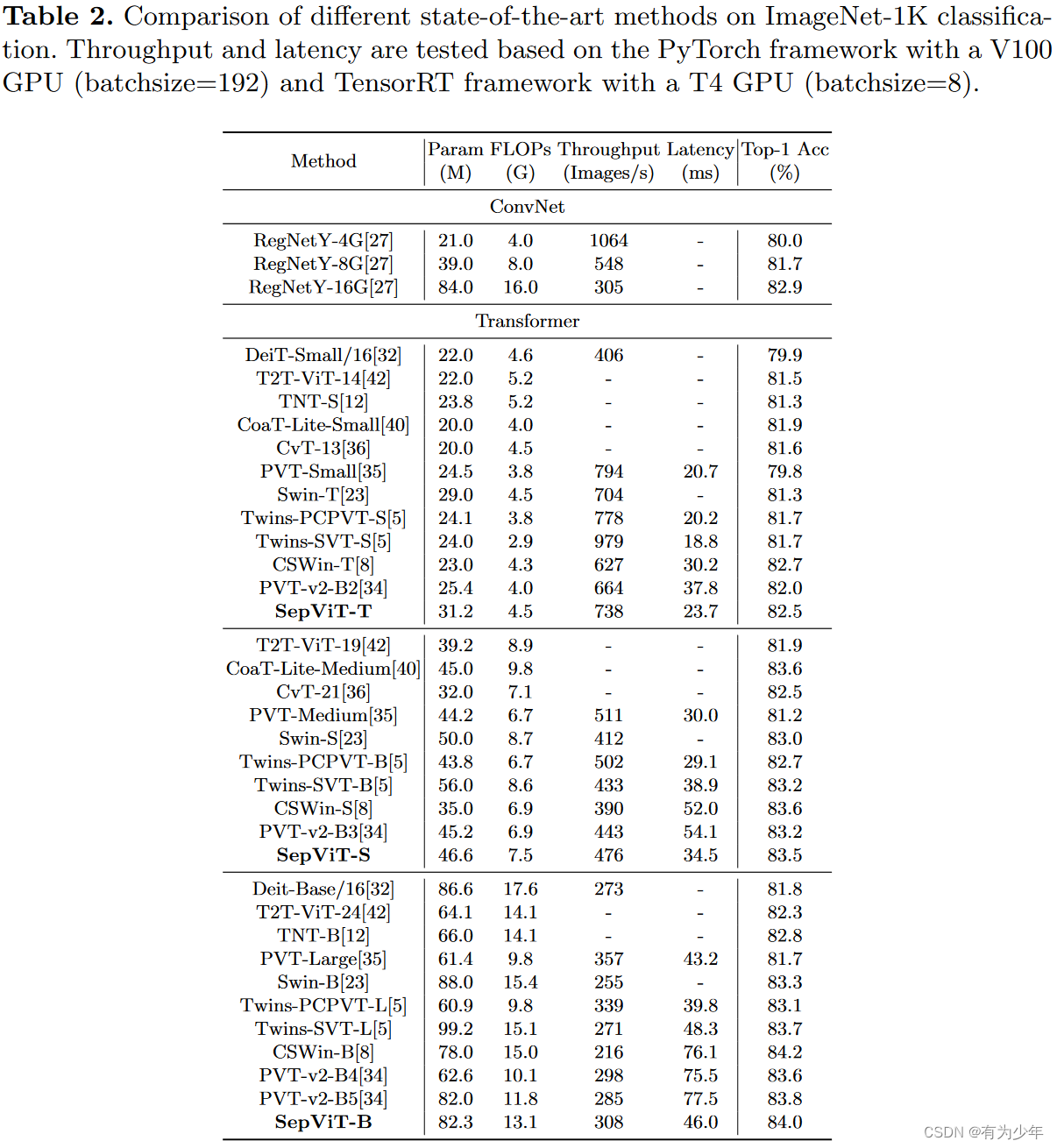















 2455
2455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









