







- 论文:https://arxiv.org/abs/2403.19588
- 代码:https://github.com/naver-ai/rdnet
- 语雀文档:https://www.yuque.com/lart/papers/yrmgielt34ve6oty

本文改进了 DenseNet,并揭示了其相对于主要的 resnet 风格架构的被低估的有效性。本文认为 DenseNets 的潜力被忽视了,原因是未改变过的训练方法和传统设计元素不能充分显示其能力。本文表明,基于拼接的密集连接是强大的,表明 DenseNets 可以重新与现代架构竞争。本文系统地改进了次优组件——调整架构、重设计块和改进训练方法,以加宽 DenseNets 并提高内存效率,同时保持拼接式连接。
所提出模型采用了简单的架构元素,最终在残差学习的传承中超越了 Swin Transformer、ConvNeXt 和 DeiT-III 架构。所提出模型在 ImageNet-1K 上表现出接近最先进的性能,与最近的模型和下游任务、ADE20k 语义分割和 COCO 目标检测/实例分割相竞争。最后,我们提供实证分析揭示了拼接相对于加性连接的优点,引导人们重新关注 DenseNet 风格设计。
背景介绍
ResNet 中引入了加法连接实现的残差学习。这改变了游戏规则,通过确保输入梯度始终保持为恒等映射导数来减少梯度消失问题。这主导了近些年神经网络架构设计的发展,包括卷积神经网络和最近的 Vision Transformer。
在残差学习主导的这一时期的早期阶段,DenseNet 引入了一种新颖的方法:通过特征拼接而不是使用加法连接。这引入了特征重用的概念,允许更紧凑的模型,并通过显式监督传播到早期的层来减少过拟合。 DenseNet 在语义分割等任务中展示了效率和卓越的性能【The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation】。DenseNet 之后的架构设计的演变似乎挑战了 ResNet 的主导地位,但由于加法连接的优势,其受欢迎程度有所下降。
DenseNet 的继任者们重新审视 DenseNet 以推进其设计精神,但无法阻挡主流趋势。本文认为,由于低可访问性(accessibility)、过时的训练方法和低容量的组件,导致其潜力仍未得到充分开发,DenseNet 可以受益于现代架构的进步。此外,DenseNet 需要彻底改革,因为其有限的适用性,以及由于特征维度增加带来的内存挑战。虽然作者解决了内存问题,但是这些问题继续限制架构的扩展,特别是宽度缩放。尽管存在这些缺点,其核心设计理念仍然非常有效。
考虑到这一 点(bearing this in mind),本文通过突出拼接被低估的功效来重振 DenseNet。
- 通过对超过 10k 个不同设置的随机网络进行全面的试点研究训练验证了所提主张,即拼接可以超越加法连接。
- 之后通过更节省内存的设计对 DenseNet 进行现代化改造,拓宽它,放弃无效组件并增强架构和块设计,同时通过拼接保留密集连接的本质。同时也采用与 DenseNet 协同作用的现代策略。
所提模型在下游任务上展示了具有竞争力的性能。值得注意的是,随着输入大小的增加,所提模型 RDNet 并没有表现出速度减慢或退化的情况。
相关工作
Densely Connected Neural Networks
DenseNet 在卷积神经网络中开创了超越加法连接的密集连接,其特点是参数效率和增强的精度。在此框架的基础上的一些变体:
- PeleeNet【Pelee: A Real-Time Object Detection System on Mobile Devices】成功提出了修改方案,以在 DenseNet 上实现实时推理功能。
- VovNet【An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection】背离了 DenseNet 的密集特征重用,转而支持旨在实时目标检测的更稀疏的 one-shot 聚合。
- CSPNet【CSPNet: A New Backbone that can Enhance Learning Capability of CNN】通过省略特征并之后在跨阶段层中拼接他们,从而减少了计算需求还几乎不影响精度。
- FC-DenseNet【The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation】等人进一步强调了 DenseNet 在语义分割上的有效性。
- MDUNet【MDU-Net: Multi-scale Densely Connected U-Net for biomedical image segmentation】利用密集连接来增强生物医学图像分割。
- DCCT【Densely connected convolutional transformer for single image dehazing】将密集连接集成到 Transformer 架构中,以促进图像去雾。
- EifficientSCI【EfficientSCI: Densely Connected Network with Space-time Factorization for Large-scale Video Snapshot Compressive Imaging】在视频快照压缩成像利用了密集连接的优势。
- 【Small-Object Detection Based on YOLO and Dense Block via Image Super-Resolution】利用密集连接来改进小物体的检测。
这些参考文献展示了基于 DenseNet 的设计的潜力,但最近没有文献使用密集连接的原理挑战 ImageNet 基准。
现代架构
DeiT 和 AugReg【How to train your vit? data, augmentation, and regularization in vision transformers】展示了现代化的训练方法可以替代 ViT 训练中的大量数据需求。后续的分层 ViT 更接近 ConvNet,表明局部性提供了功效和计算效率。混合架构然后显式为局部性配备卷积。具有讽刺意味的是,新来者(incomer)已变得更接近 ConvNet,尽管使用 Transformer。这也是为了不放弃简单卷积经过验证的有效性。
ConvNet 最初由于强大的能力和效率而占据主导地位。有趣的是,ViT 方面的进步也为 ConvNet 的现代化做出了贡献;许多最近的架构都受到 ViT 设计的启发,但具有局部性,展示了卷积的持续的高竞争力。
- 像 RepLKNet【Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs】和 SLaK【More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity】这样的后继者采用了基于大尺寸卷积来模拟注意力的全局性,从而学习增强的全局表示。
- RevCol【Reversible Column Networks】引入了 一个新概念,通过多个列重复混合多级特征。
- InceptionNeXt【InceptionNeXt: When Inception Meets ConvNeXt】在 ConvNeXt 中采用了 inception module 以改进性能。
- HorNet【Hornet: Efficient highorder spatial interactions with recursive gated convolutions】和 MogaNet【Moganet: Multi-order gated aggregation network】都通过分别采用多门控卷积和多级特征表现出了卓越的性能,同时也利用了多尺度特征来实现全局性。
这些架构在分类和密集预测任务上也超越了 ViT。但使用加法连接和架构复杂性等相似之处继续限制架构多样性和创新。此外,更现代的架构策略已经成功地重新审视了现有的体系结构,但没有处理加法链接基线的情况。这项工作遵循一个总体方向,但确保从一个独特的基线开始,承认关于现有路线图有效性的不确定性。
具体方法
本节从猜想开始,即 DenseNet 可能不会落后于现代架构,并通过修改后的 DenseNet 架构来证明这一点。根据猜想和试点实验,本文提出了新的方法,其中包含一些现代化的材料来复兴 DenseNet。
本节从我们的猜想开始,即 DenseNet 可能不会落后于现代架构,并通过证实修改后 的 DenseNet 架构来证明这一点。根据我们的猜想和试点实验,我们提出了我们的方 法论,其中包含一些现代化的材料来复兴 DenseNet。
动机
ResNet 因基于加法的残差连接的简单形式而闻名,这一组件促进了模块化架构设计。而 DenseNet 基于特征拼接的基础组件形式,基于通过具有显式参数效率的拼接的密集连接。然而,由于内存问题,这一形式应该限制特征维度,这使得宽度扩展具有挑战性。
DenseNet 最初优于 ResNet,但未能实现完整的范式转变,由于适用性而失去了最初的动力。特别是,尽管有在存储方面做出的努力,但宽度缩放对于 DenseNet 来说仍然是个问题,像 DenseNet-161/233 这样的宽模型会消 耗更多的内存。尽管如此,受到先前工作【Revisiting ResNets: Improved Training and Scaling Strategies,A convnet for the 2020s,ResNet strikes back: An improved training procedure in timm】的启发,并受到语义分割等密集预测任务的成功的推动,相信 DenseNet 将优于流行的架构,并值得进一步探索其潜力,即特征拼接能力强大;DenseNet 的上述问题可以通过策略设计来缓解。
猜想
特征拼接是增加秩的有效方法。考虑层输出 f ( X W ) f(XW) f(XW) 权重为 W ∈ R d i n × d o u t W \in \mathbb{R}^{d_{in} × d_{out}} W∈Rdin×dout 和输入 X ∈ R N × d i n X \in \mathbb{R}^{N × d_{in}} X∈RN×din,以及一个非线性操作 f f f ,假设中的实例数 N ≫ d i n N \gg d_{in} N≫din。当关注 f f f 的矩阵秩 rank ( f ( X W ) ) \text{rank}(f(XW)) rank(f(XW)) 时,当 d i n d_{in} din 不太小时存在非线性,秩通常会更接近 d o u t d_{out} dout【Rethinking Channel Dimensions for Efficient Model Design】。文献【Dual Path Networks,Deep Pyramidal Residual Networks,Rethinking Channel Dimensions for Efficient Model Design】表明, d o u t > d i n d_{out}>d_{in} dout>din 的权重层提供了增强的表示能力。有趣的是,DenseNet 具有相似的方面,因为可以分解 W = [ W P , I ] W=[W_P,I] W=[WP,I],分解得到的二者分别表示构建块和拼接的权重。所以进一步认为,经常像这样提高秩会更有益。 W P W_P WP 的输出维度称为增长率(growth rate,GR)。
策略设计可以减轻内存问题。考虑堆叠层 X W 1 f ( W 2 ) XW_1f(W_2) XW1f(W2) 的输出,其中权重 W 1 ∈ R d i n × d r W_1 \in \mathbb{R}^{d_{in} \times d_r} W1∈Rdin×dr, W 2 ∈ R d r × d o u r W_2 \in \mathbb{R}^{d_{r} \times d_{our}} W2∈Rdr×dour, d r < d i n , d o u t d_r < d_{in},d_{out} dr<din,dout,以及 W 2 W_2 W2 之后的非线性操作 f f f 。同样,由于 d r d_r dr 不是那么小,因此秩可能会保留。这表明使用像 W 1 W_1 W1(即过渡层)这样的中间维度缩减器可能不会显着影响排名。所以频繁应用这一设计可以有效解决内存问题。
试点研究
通过在 Tiny-ImageNet 上对 15k 个网络进行采样来验证猜想,其中它们的连接方式要么像 ResNet 一样是加法,要么是 DenseNet 中的拼接。仔细控制有关计算成本的实验,并涉及不同的训练设置,以确保平衡和全面的比较。有趣的是,拼接方式平均 Tiny-ImageNet 准确率均优于加法快捷方式 54.3±3.7(拼接)与 52.7±4.2(加法),从而经验上支持了本文主张。
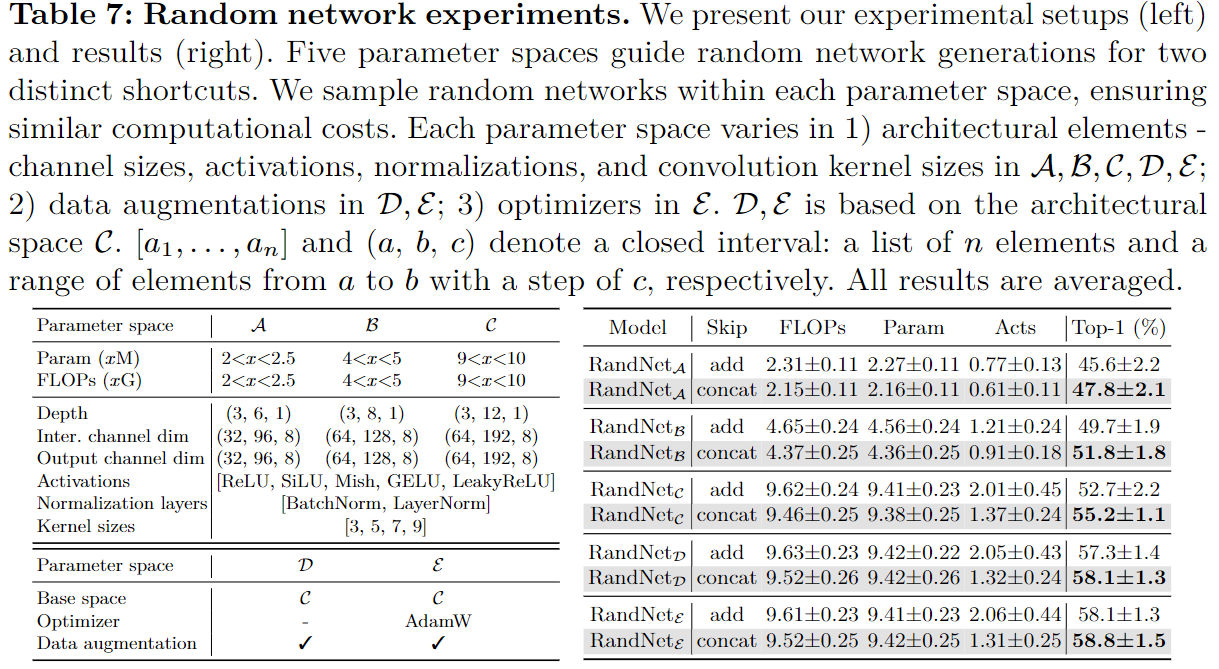

模型架构扩展
表 1 详细介绍了有助于性能改进的要素。
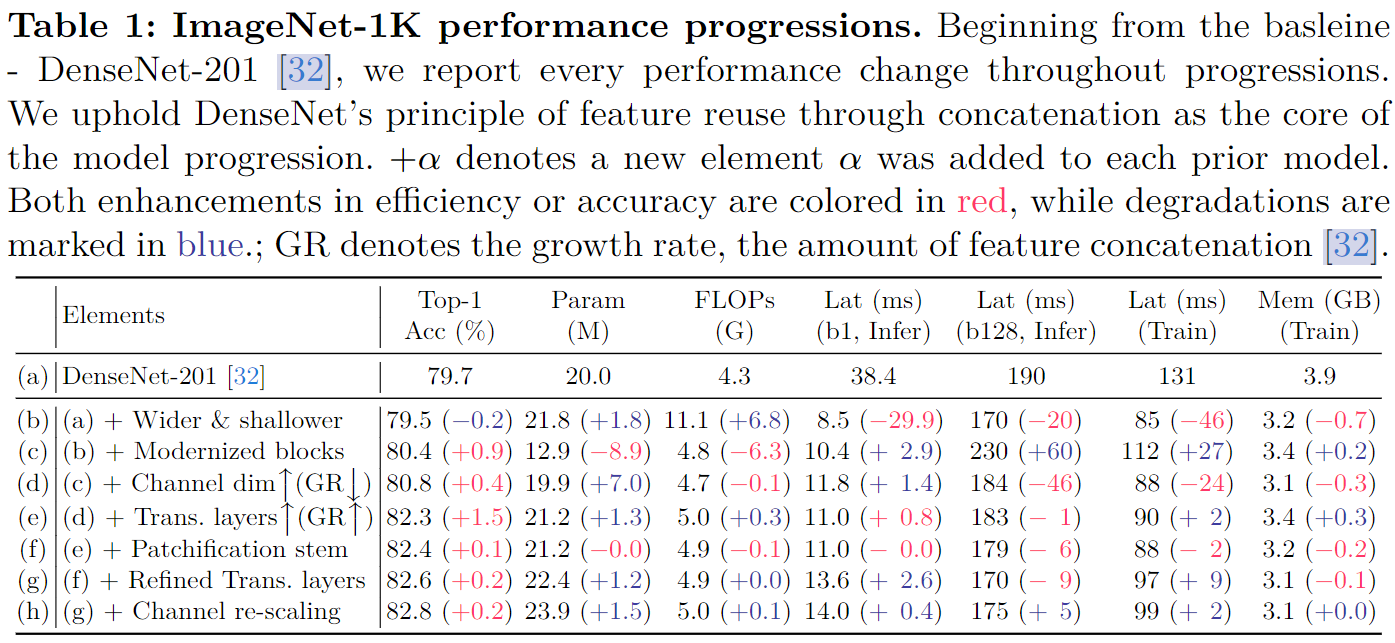
- 基线。 正如一系列重新审视 ResNet 的工作所表明的那样,精炼的训练方案带来了显着的改进。同样使用现代训练设置来训练 DenseNet-201 作为基线。遵循充分探索的设置:
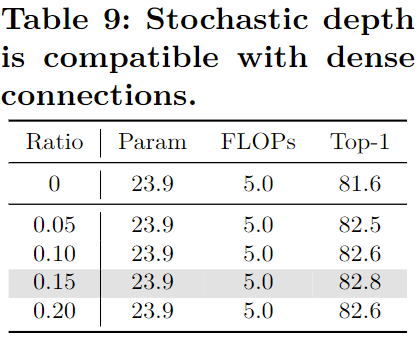
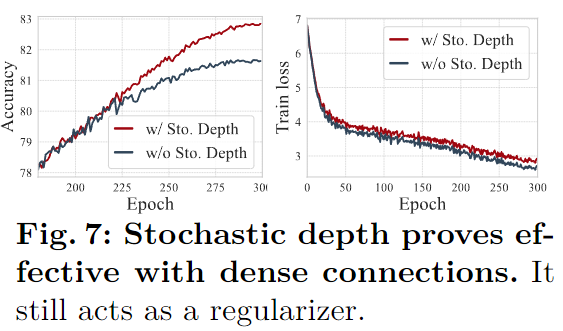
- 包括标签平滑、RandAugment、随机擦除、Mixup、Cutmix,和随机深度;
- 使用 AdamW 与余弦学习率衰减和线性预热以及流行的大周期训练设置 (300)。
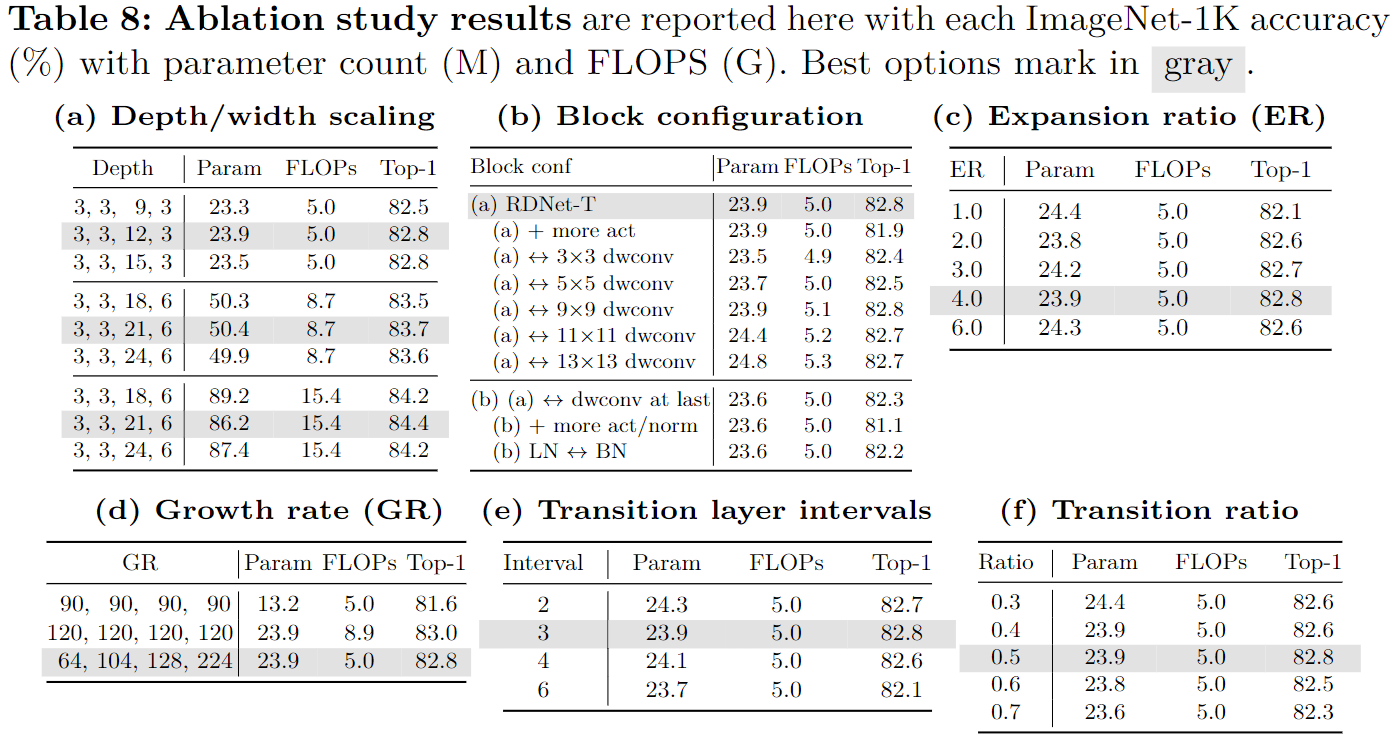
- 更宽、更浅。 DenseNet 最初提出了超深的架构,如 DenseNet-256。它有效地展示了可扩展性。在资源限制下,通过高增长率(GR)和增加深度来增强特征维度很难同时实现。先前的工作设计了更浅的网络以实现效率,特别是延迟。受此启发将 DenseNet 修改为有利的基线;通过增强 GR 并减少其深度来拓宽网络。具体来说:大幅增加 GR——从 32 增加到 120,以及调整每个阶段的块数,从 (6, 12, 48, 32) 减少到更小的 (3, 3, 12, 3) 用于深度调整。同时不会将深度缩小太多以保持最小的非线性。表 1 中的 (b) 显示这种策略修改导致显着的延迟和内存效率,其中训练速度和内存分别降低约 35% 和 18%。GFLOPs 显着增加至 11.1,这将通过后续操作进行调整。进一步的研究支持了这样的决定,即优先考虑宽度,同时平衡深度。
- 改进的特征混合器。 将 ConvNeXt 中的基本块用于特征混合器块,该块已经被广泛研究以揭示其有效性。在使用它之前,应重新评估这里案例的研究,因为 DenseNets 没有使用加法连接,并且构建块最初设计为连续缩减维度的形式。本文发现使用以下设置仍然有效:使用层归一化(LN)而不是批量归一化 (BN);后激活(post-activation)策略;深度卷积;更少的归一化和激活;核大小为 7。我们块的一个独特之处是输出通道(GR)小于输入通道(C);混合特征最终是更压缩的特征。从表 1© 中可以看出,这样的设计大幅提高了精度 (+0.9%),同时略微增加了计算成本。
- 更大的中间通道维度。 深度卷积的大的输入维度至关重要【Mobilenetv2: Inverted residuals and linear bottlenecks】。在之前的工作中,通过巧妙地调节逆瓶颈层的扩展比(ER),扩大块内的中间张量大小超出输入维度(例如,ER 被调整为 6),成功地实现显着的性能。DenseNet 类似地采用了 ER 概念;然而,他们独特地将其应用于增长率(GR)(例如,ER=4xGR)而不是输入维度,以减少输入和输出维度。这会通过非线性层损害编码特征的能力【Rethinking Channel Dimensions for Efficient Model Design】。因此通过使 ER 与输入维度成比例来设计该方法(即,将 ER 与 GR 解耦)。这种变化会导致更大的中间维度,从而造成计算需求增加;因此,将 GR 减半(例如,从 120 减至 60)可以在不影响准确性的情况下满足这些需求。即在应用非线性之前丰富特征并进一步压缩通道来控制计算成本。此后实现了快了 21% 的训练速度和高了 0.4% 的准确率,如表 1 所示。
- 更多过渡层。 阶段之间的过渡层旨在减少通道数量。由于每个块中的密集连接,特征的强化积累不允许高增长率(GR)。当多个块堆叠在单个阶段中时,情况会变得更糟,例如在第三阶段,其中累积了许多具有低 GR 的块。这里引入了一个新颖的设计,引入更多的过渡层。具体来说,建议在阶段中使用过渡层,不仅在每个阶段之后,而且在每三个步幅为 1 的块之后。这些过渡层不涉及下采样,仅涉及降维。
- 这种修改显然大大降低了计算成本,因此成功地增加了总的 GR(注意这里增加 GR 的目的是在架构层面解决基线中整体 GR 较低的问题,而前面减少 GR 的设定是为了在块层面提高 ER)。表 8e 中的实验结果表明经常使用过渡层通常可以提高准确性。
- 与 FLOP 相比,模型的参数计数较低。通过在不同阶段引入可变 GR 而不是统一的 GR 来解决这个问题。表 8d 中的进一步研究表明,均匀的增长率 (GR) 会损害准确性和效率。
- Patchification Stem。 最近的工作展示了使用图像补丁作为 Stem 输入的有效性。这里使用相同的大小 4 和步长 4 的设置来作为补丁(跟着 LN)。使用补丁可以显着加快计算速度,而不会损失精度,如表 1(f))。
- 细化过渡层。 过渡层的另一个作用是下采样,采用了额外的平均池化来下采样。这里改进过渡层,删除了平均池化,并调整跨步卷积的核大小和步长(LN 也替换了 BN)。因此过渡层会起到两个额外作用:降维和下采样。在每个阶段之后放置过渡层可实现 +0.2% 的增益,而几乎不会损害效率。对于降维比,这里重新实验了之前在 DenseNet 中探讨过的影响;表 8f 再次确认 0.5 是最佳的;较高的转换比会降低精度。
- 通道重缩放。 考虑到拼接的特征具有不同方差,这里探究是否需要通道重缩放。这里提出了一种重放缩方法,其合并了【Training data-efficient image transformers & distillation through attention】中的通道层尺度和【CenterMask : Real-Time Anchor-Free Instance Segmentation】中的有效的 squeeze-excitation 组件。表 1 中展示了带来的性能提升,但是也造成了一点效率上的损失。
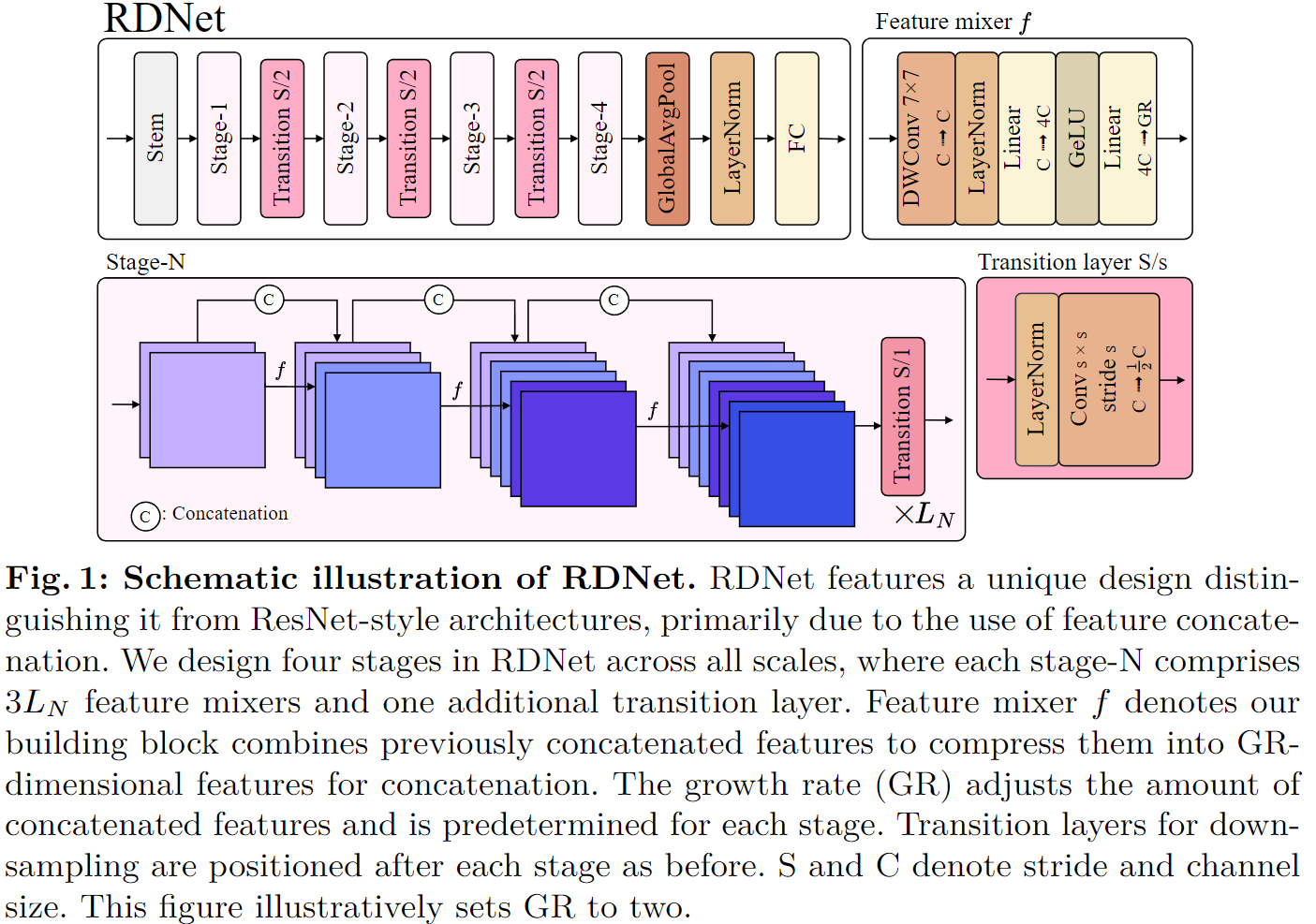
最后引入了本文提出的 Revitalized DenseNet,即 RDNet,如图 1 所示。 最终模型实现了更高的精度和效率,特别是速度显着加快(参见表 1(h) 与表 1(a))。构建 RDNet 模型系列时与广泛采用的尺度保持一致。模型独特地包括增长率 GR=(GR1,GR2,GR3,GR4),以及每个阶段中混合块的数量 B=(B1,B2,B3,B4),其中每个阶段分配三个块 Bn=3Ln。因此总共包括四个版本的模型:
- RDNet-T: GR = (64, 104, 128, 224), B = (3, 3, 12, 3)
- RDNet-S: GR = (64, 128, 128, 240), B = (3, 3, 21, 6)
- RDNet-B: GR = (96, 128, 168, 336), B = (3, 3, 21, 6)
- RDNet-L: GR = (128, 192, 256, 360), B = (3, 3, 24, 6)
实验结果
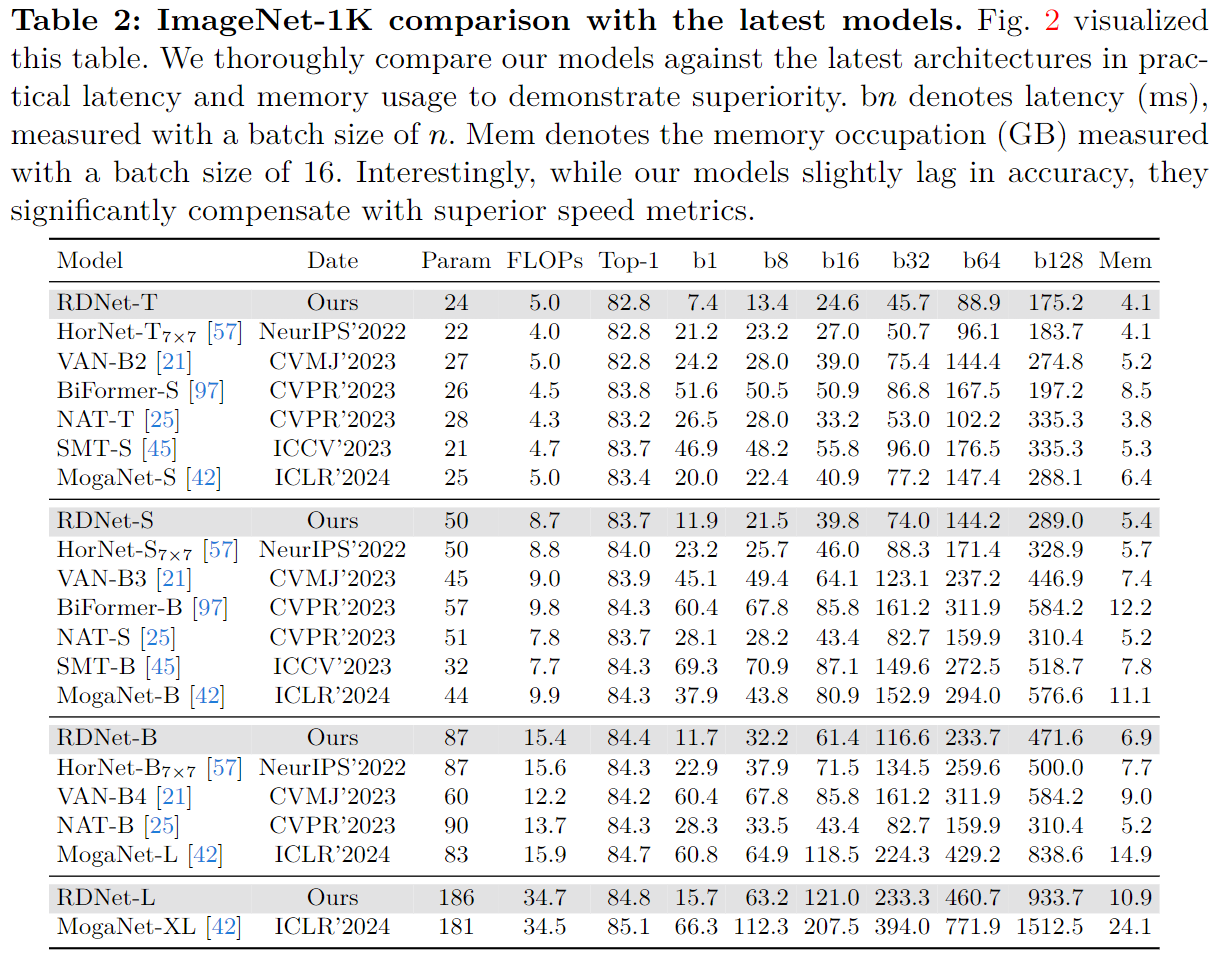
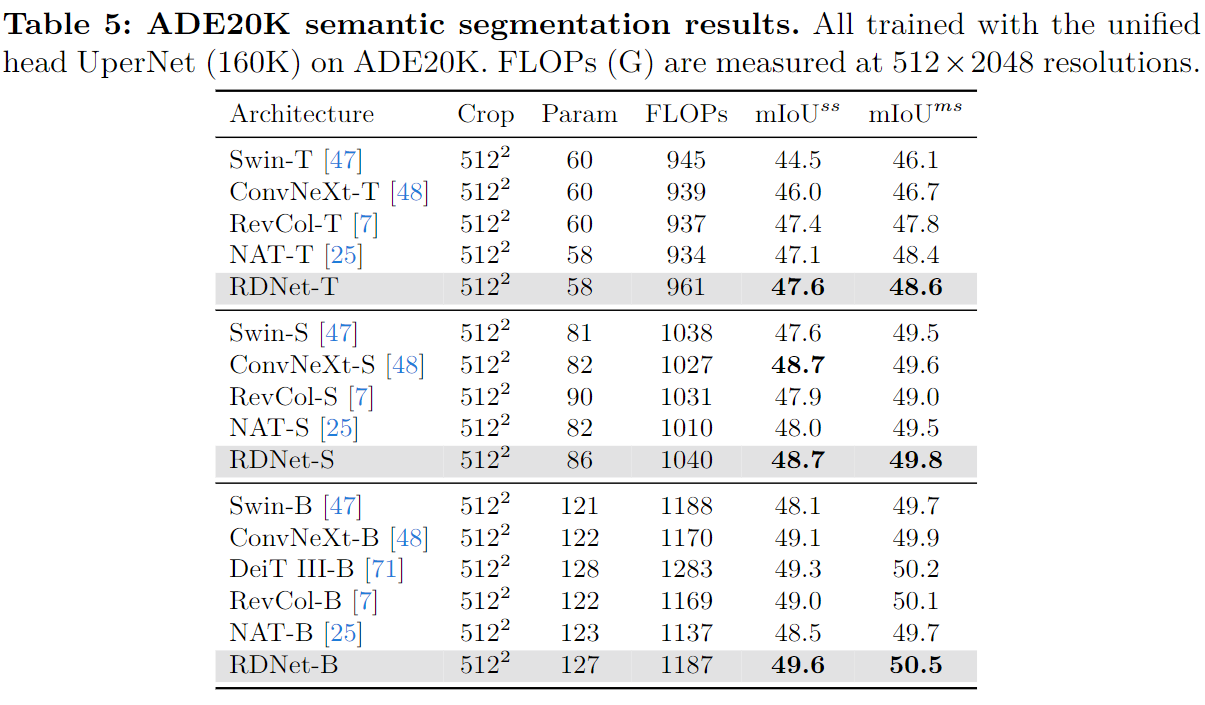
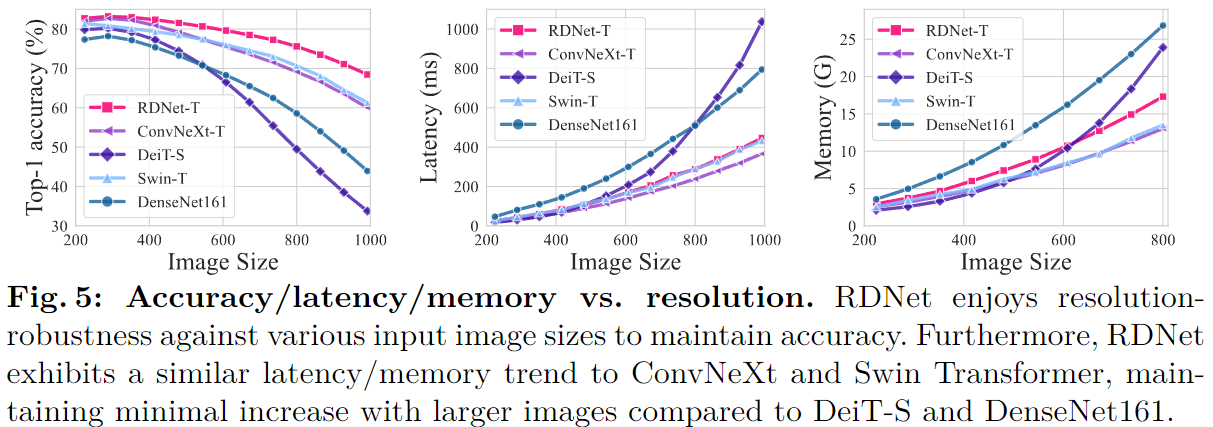
输入尺寸对不同指标的影响。
















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









