







----------------------------------🗣️ 语音合成 VITS相关系列直达 🗣️ -------------------------------------
🫧VITS :TTS | 保姆级端到端的语音合成VITS论文详解及项目实现(超详细图文代码)
🫧MB-iSTFT-VITS:TTS | 轻量级语音合成论文详解及项目实现
🫧MB-iSTFT-VITS2:TTS | 轻量级VITS2的项目实现以及API设置-CSDN博客
🫧PolyLangVITS:MTTS | 多语言多人的VITS语音合成项目实现-CSDN博客
本文主要讲解了端到端的语音合成模型VITS论文及项目实现~
论文题目:2021_VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
1.论文总结
提出一种TTS模型框架VITS,用到normalizing flow和对抗训练方法,提高合成语音自然度,其中论文结果上显示已经和GT相当。是结合了VAE和FLOW的新架构。
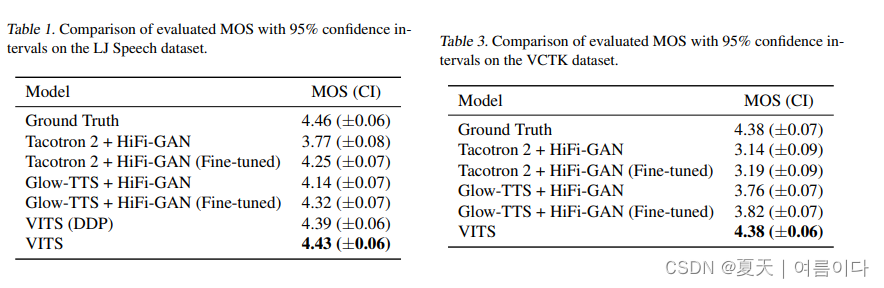
在俩各数据集中的实验结果
论文的主要贡献:
- 首个自然度超过2-stage架构SOTA的完全E2E模型。MOS4.43, 仅低于GT录音0.03。
- 得益于图像领域中把Flow引入VAE提升生成效果的研究,成功把Flow-VAE应用到了完全E2E的TTS任务中。
- 训练非常简便,完全E2E。不需要像Fastspeech系列模型需要额外提pitch, energy等特征,也不像多数2-stage架构需要根据声学模型的输出来finetune声码器以达到最佳效果。
- 摆脱了预设的声学谱作为链接声学模型和声码器的特征,成功的应用来VAE去E2E的学习隐性表示来链接两个模块。
- 多人模型自然度不下降,不像其他模型趋于持平GT录音MOS分。
本文只详细翻译论文的第二部分,讲解模型的实现细节(编号与论文相同)。
2. 方法论Method
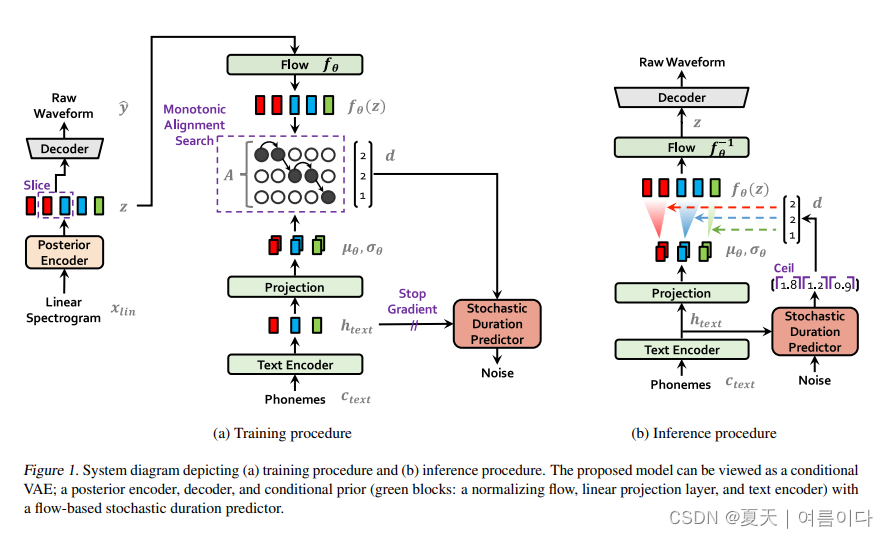
在这节中,论文解释了论文提出的方法以及构架,建议的方法主要在前三个小节:条件 VAE 表述(conditional VAE formulation);由变异推理得出的配准估计(alignment estimaion derived from variational inference);提高合成质量的对抗训练(adversarial estimation for improving synthesis quality)。整体架构将在本节末尾介绍。图 1a 和 1b 分别显示了我们方法的训练和推理过程。将方法称为带有对抗性学习的端到端文本到语音(VITS)。
2.1.可变推理
VITS 可以表示为条件 VAE,其目标是最大化可变下界,也称为证据下界 (ELBO)。其目标是最大化难以处理的数据的边际对数似然 log pθ(x|c):
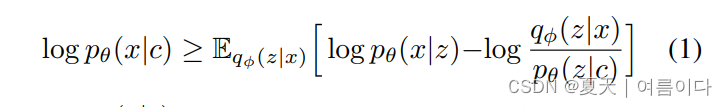
其中,pθ(z|c) 表示给定条件 c 的潜变量 z 的先验分布,pθ(x|z) 是数据点 x 的似然函数,qφ(z|x) 是近似后验分布。那么训练损失就是负ELBO,可以看作是重建损失 log pθ(x|z) 和 KL 发散 log qφ(z|x) 的总和,其中 z ∼ qφ(z|x)。
2.1.2.损失
作为一个目标数据点,使用梅尔惠普图去替代音波文件,定义为Xmel.上采样潜变量z去求得y',通过一个解码器和转置y',
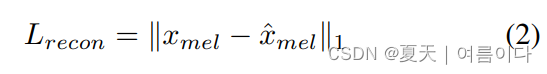
2.1.3.KL散度(KL-divergence)
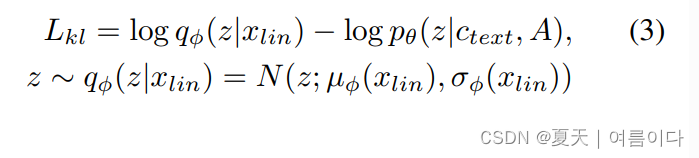
2.2.Alignment Estimation
2.2.1.Monotonic Alignment Search(MAS)
为了估计输入文本和目标语音之间的对齐度 A,采用单调对齐搜索(Monotonic Alignment Search,MAS)(Kim 等人,2020 年)。数据参数最大化的对齐方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











