







【README】
本文记录了flink读取不同数据源的编码方式,数据源包括;
- 集合(元素列表);
- 文件
- kafka;
- 自定义数据源;
本文使用的flink为 1.14.4 版本;maven依赖如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>【1】从集合读取数据
【1.1】代码
/**
* @Description flink从集合读取数据
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月15日
*/
public class SourceTest1_Collection {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从集合读取数据
DataStream<SensorReading> sensorStream = env.fromCollection(Arrays.asList(
new SensorReading("sensor_1", 12341561L, 36.1)
, new SensorReading("sensor_2", 12341562L, 33.5)
, new SensorReading("sensor_3", 12341563L, 39.9)
, new SensorReading("sensor_4", 12341564L, 31.2)
));
// 打印输出
sensorStream.print("sensor");
// 从元素列表读取数据
DataStream<Integer> intStream = env.fromElements(1, 2, 3, 7, 8, 2, 100, 34, 3);
intStream.print("intStream");
// 执行
env.execute("sensorJob");
}
}/**
* @Description 传感器温度读数
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月15日
*/
public class SensorReading {
private String id;
private Long timestamp;
private double temperature;
public SensorReading() {
}
public SensorReading(String id, Long timestamp, double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
打印结果:
intStream:6> 8
intStream:5> 7
intStream:7> 2
sensor:8> SensorReading{id='sensor_2', timestamp=12341562, temperature=33.5}
intStream:1> 34
sensor:1> SensorReading{id='sensor_3', timestamp=12341563, temperature=39.9}
intStream:3> 2
intStream:4> 3
intStream:2> 1
intStream:2> 3
sensor:7> SensorReading{id='sensor_1', timestamp=12341561, temperature=36.1}
intStream:8> 100
sensor:2> SensorReading{id='sensor_4', timestamp=12341564, temperature=31.2}
【2】 从文件读取数据
【2.1】代码
/**
* @Description flink从文件读取数据
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月15日
*/
public class SourceTest2_File {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); // 设置全局并行度为1
// 从文件读取数据
DataStream<String> fileStream = env.readTextFile("D:\\workbench_idea\\diydata\\flinkdemo2\\src\\main\\resources\\sensor.txt");
// 打印输出
fileStream.print("sensor");
// 执行
env.execute("sensorJob");
}
}sensor.txt 如下:
sensor_1,12341561,36.1
sensor_2,12341562,33.5
sensor_3,12341563,39.9
sensor_4,12341564,31.2打印结果:
sensor> sensor_1,12341561,36.1
sensor> sensor_2,12341562,33.5
sensor> sensor_3,12341563,39.9
sensor> sensor_4,12341564,31.2
【3】从kafka读取数据
1)引入maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.4</version>
</dependency>2)flink作为消费者连接到kafka
/**
* @Description flink从kafka读取数据
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月15日
*/
public class SourceTest3_kafka {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); // 设置全局并行度为1
// 创建flink连接kafka
KafkaSource kafkaSource = KafkaSource.<String>builder().setValueOnlyDeserializer(new SimpleStringSchema())
.setProperties(KafkaConsumerProps._INS.getProps()).setTopics("hello0415").setGroupId("flink").build();
DataStream<String> kafkaStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
// 打印输出
kafkaStream.print("kafkaStream");
// 执行
env.execute("kafkaStreamJob");
}
}public enum KafkaConsumerProps {
_INS;
/* 1.创建kafka生产者的配置信息 */
Properties props = new Properties();
private KafkaConsumerProps() {
/*2.指定连接的kafka集群, broker-list */
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.163.201:9092,192.168.163.202:9092,192.168.163.203:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "G1");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
}
public Properties getProps() {
return props;
}
}3)打开 kafka生产者命令行:
kafka-console-producer.sh --broker-list centos201:9092,centos202:9092,centos203:9092 --topic hello0415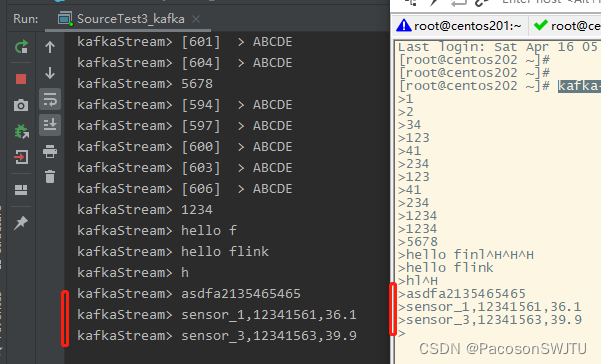
补充: 关于kafka集群,可以参见我的文章 :
kafka集群搭建_PacosonSWJTU的博客-CSDN博客
【4】自定义数据源
自定义数据源,可以用于自测 flinkjob 的场景中;
public class SourceTest4_UDF {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4); // 设置全局并行度为1
// 创建自定义数据源
DataStream<SensorReading> udfStream = env.addSource(new SourceFunction<SensorReading>() {
int i = 1;
int mod = 1000;
Random random = new Random();
boolean runnable = true;
@Override
public void run(SourceContext<SensorReading> sourceContext) throws Exception {
while (runnable) {
sourceContext.collect(new SensorReading(String.valueOf(i++ % mod + 1), System.currentTimeMillis(), 30 + random.nextGaussian()));
if (i % 5 == 0) TimeUnit.SECONDS.sleep(1);
}
}
@Override
public void cancel() {
runnable = false;
}
});
// 打印输出
udfStream.print("udfStream");
// 执行
env.execute("udfStreamJob");
}
}打印结果:
udfStream:4> SensorReading{id='5', timestamp=1650030559865, temperature=31.015354380481117}
udfStream:1> SensorReading{id='2', timestamp=1650030559853, temperature=29.23797321841027}
udfStream:3> SensorReading{id='4', timestamp=1650030559865, temperature=31.148402161461384}
udfStream:2> SensorReading{id='3', timestamp=1650030559865, temperature=30.082462570224305}














 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









