







20-面向流水线的指令设计(上):一心多用的现代CPU
愿得一心人,白首不相离:单指令周期处理器
单指令周期处理器(Single Cycle Processor):在一个时钟周期内,处理器 正好能处理一条指令。
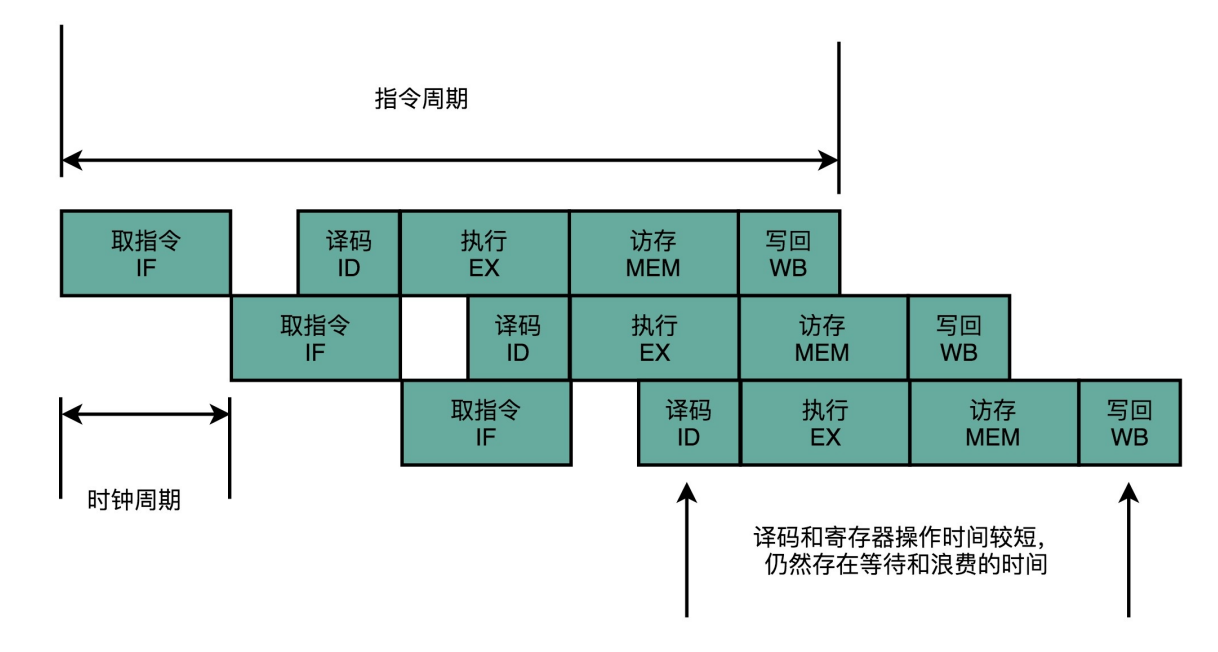
这个执行过程,至少需要花费一个时钟周期。因为在取指令 的时候,我们需要通过时钟周期的信号,来决定计数器的自增。
因为指令的电路复杂程度不同,所以实际的执行时间不同。如果时间周期是固定的则会有浪费的时间(内部时间碎片)
随着门电路层数的增加,由于门延迟 的存在,位数多、计算复杂的指令需要的执行时间会更长。
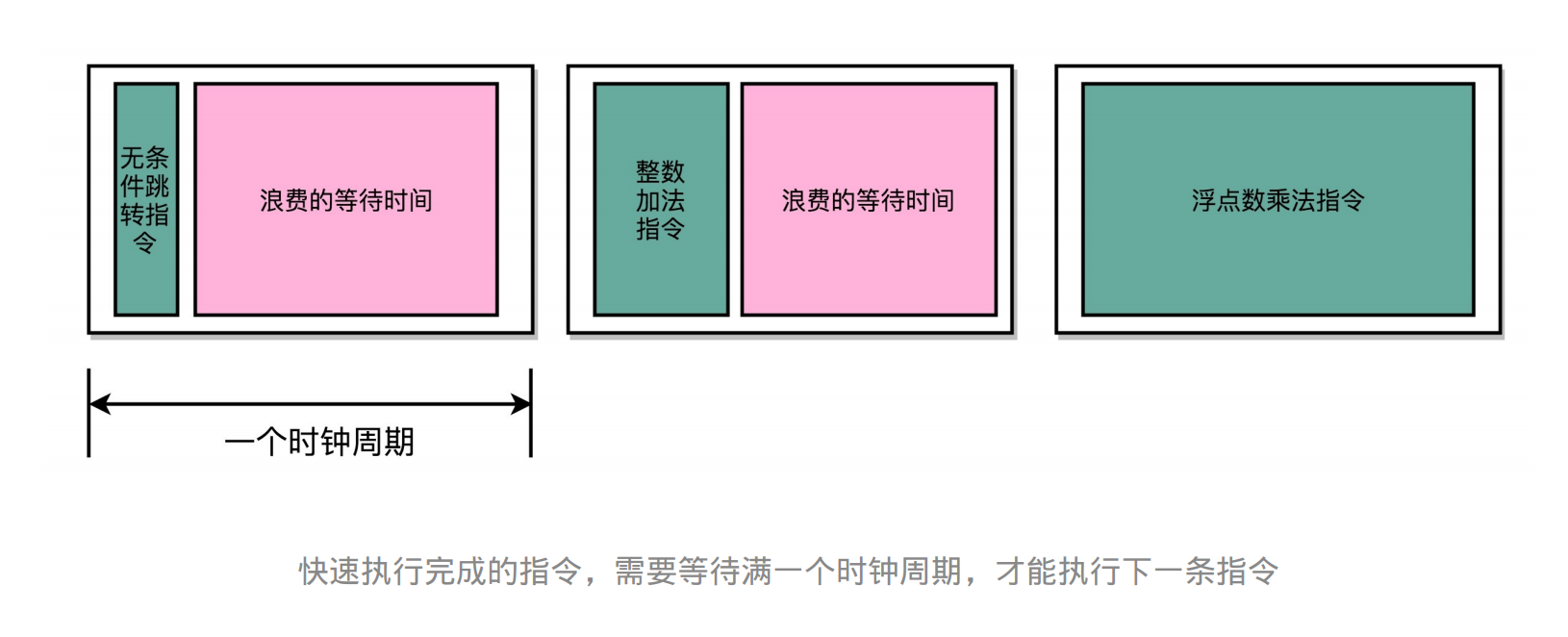
虽然CPI为1,但是时钟的频率太低。每个时钟周期会浪费大量时间
CPI (Clock cycle Per Instruction)表示每条计算机指令执行所需的时钟周期.
无可奈何花落去,似曾相识燕归来:现代处理器的流水线设计
指令流水线 :把时钟周期设拆分成完成一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,可以直接 执行下一条指令的对应阶段。
流水线的本质是增加CPU各个部分的忙碌率。类似操作系统调度进程和批处理系统
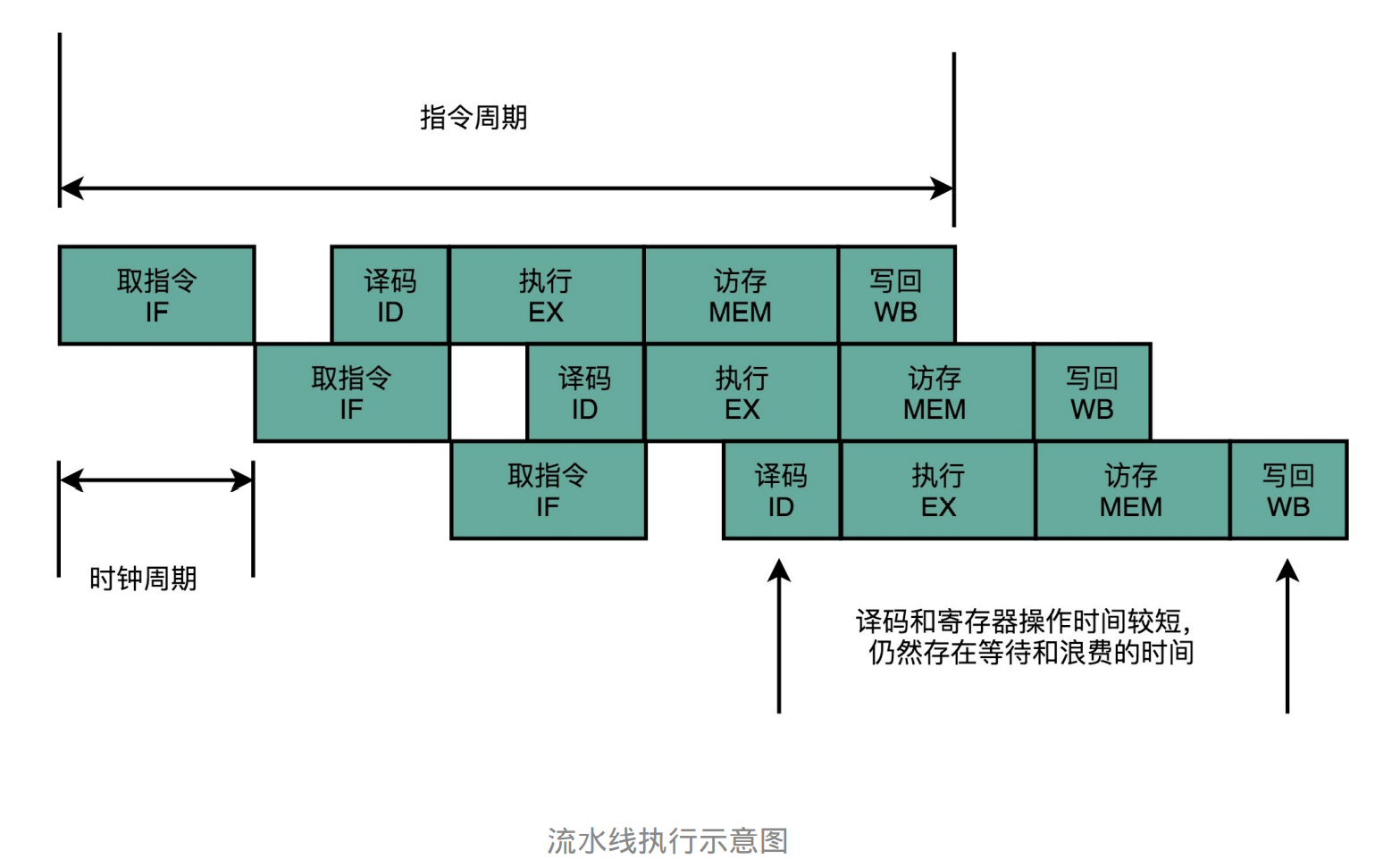
- 原理:虽然执行一 条指令的时钟周期增加,但是每个时钟周期只要完成一个阶段,减少了时间内部碎片。所以可以再提高CPU的主频。
- 如果指令过于复杂则可以切分成更多阶段。为了使每个阶段的时间差不多
- 优点:时间分成更小的区间,利于提高CPU各模块的忙碌率,减少每个阶段的时间内部碎片
- 流水线不能减少单条指令执行的“延时”,但可以提高CPU的吞吐率
- 缺点:系统中断,资源争抢等问题变得更复杂
超长流水线的性能瓶颈
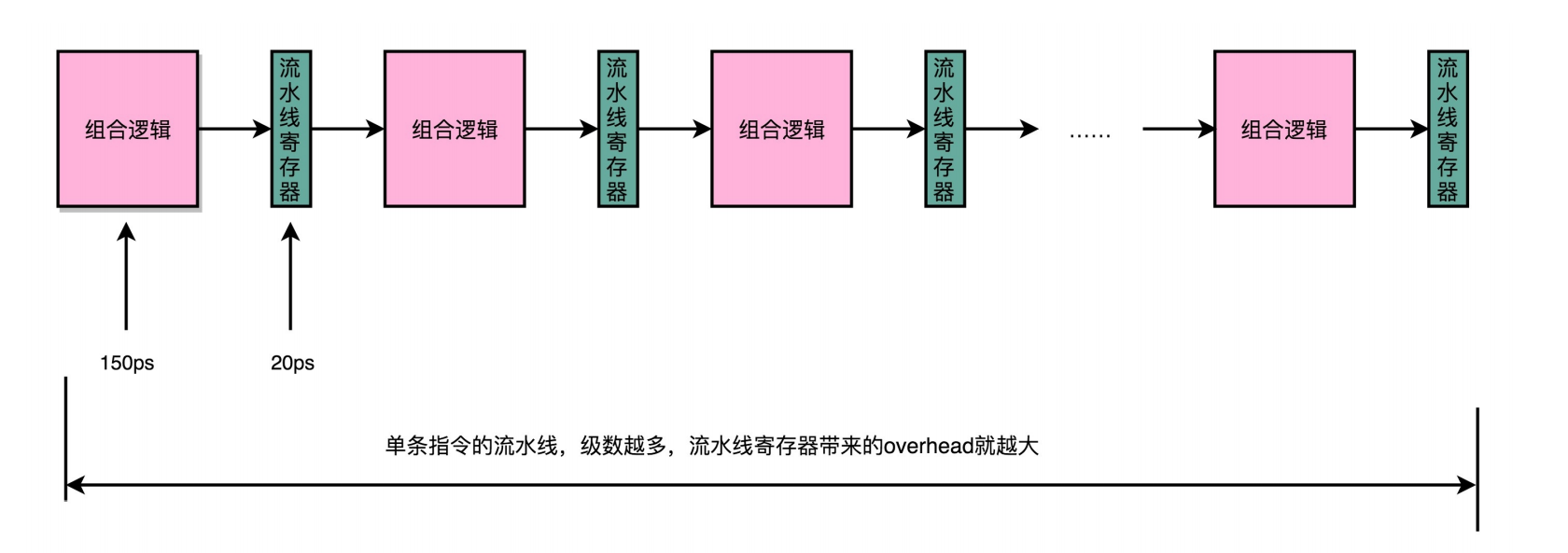
最基本的原因:增加流水线深度,有性能成本的。
每级流水线都需要把数据放到流水线寄存器(Pipeline Register)中来同步执行阶段。读写寄存器是有性能开销的。
总结延伸
把指令的执行过程,切分成一个一个流水线级,来提升 CPU的吞吐率。而我们本身的CPU的设计,又是由一个个独立的组合逻辑电路串接起来形成的,天然能够适 合这样采用流水线“专业分工”的工作方式。
因为每加一级都会带来额外的性能开销,所以一味地增加流水线深度,并不能无限地提高性能。
因为指令的执行不再 是顺序地一条条执行,而是在上一条执行到一半的时候,下一条就已经启动了,所以也给我们的程序带来了 很多挑战。
21-面向流水线的指令设计(下):奔腾4是怎么失败的?
每一个细分的流水线步骤都很简单,所 以我们的单个时钟周期的时间就可以设得更短。这也变相地让CPU的主频提升得很快。
新的挑战:冒险和分支预测
超长流水线的缺点:
-
功耗太高
- 提升流水线深度,必须要和提升CPU主频同时进行。
- 由于流水线深度的增加,需要更多的电路数量和晶体管
-
执行效果不好
- 在实际的程序执行中,流水线会遇到三种冒险并且需要预测分支
22-冒险和预测(一):hazard是“危”也是“机”
- 问题:CPU流水线设计的缺点和风险有哪些
- 答案:三大冒险,分别是结构冒险 、数据冒险,控制冒险
结构冒险 (Structural Harzard)、数据冒险(Data Harzard)以及控制冒险(Control Harzard)
结构冒险:为什么工程师都喜欢用机械键盘?
- 问题: CPU并行执行多个指令时,可能会用到同样的硬件
- 本质:硬件层面的资源竞争问题。可以通过增加资源来解决(或者把资源进行拆分隔开)
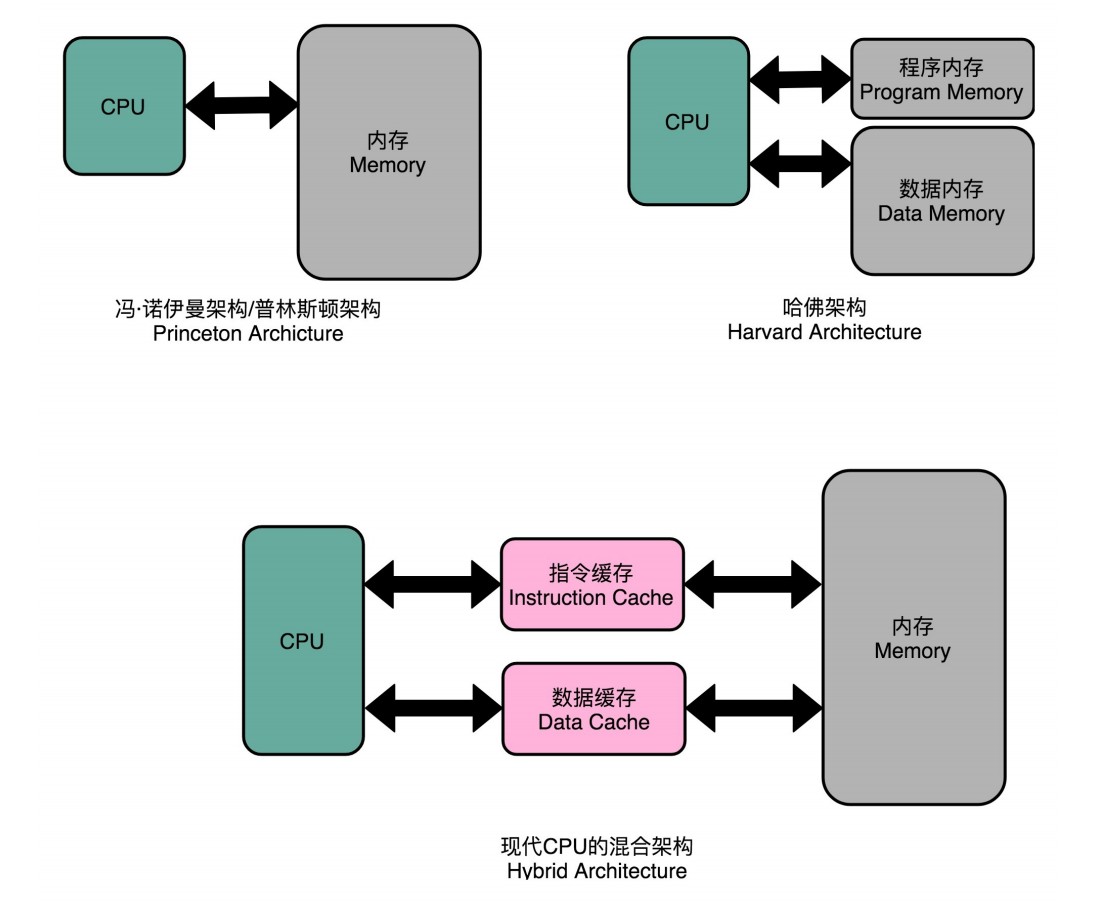
- 解决:把内存分成分存放指令的程序内存和存放数据的数据内存。 有各自的地址译码器。
- 问题:对程序指令和数据需要的内存空间,我们就没有办法根据实际的应用去动态分配了。失去灵活性
- 解决:只对高速缓存部分进行区分,分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部分。
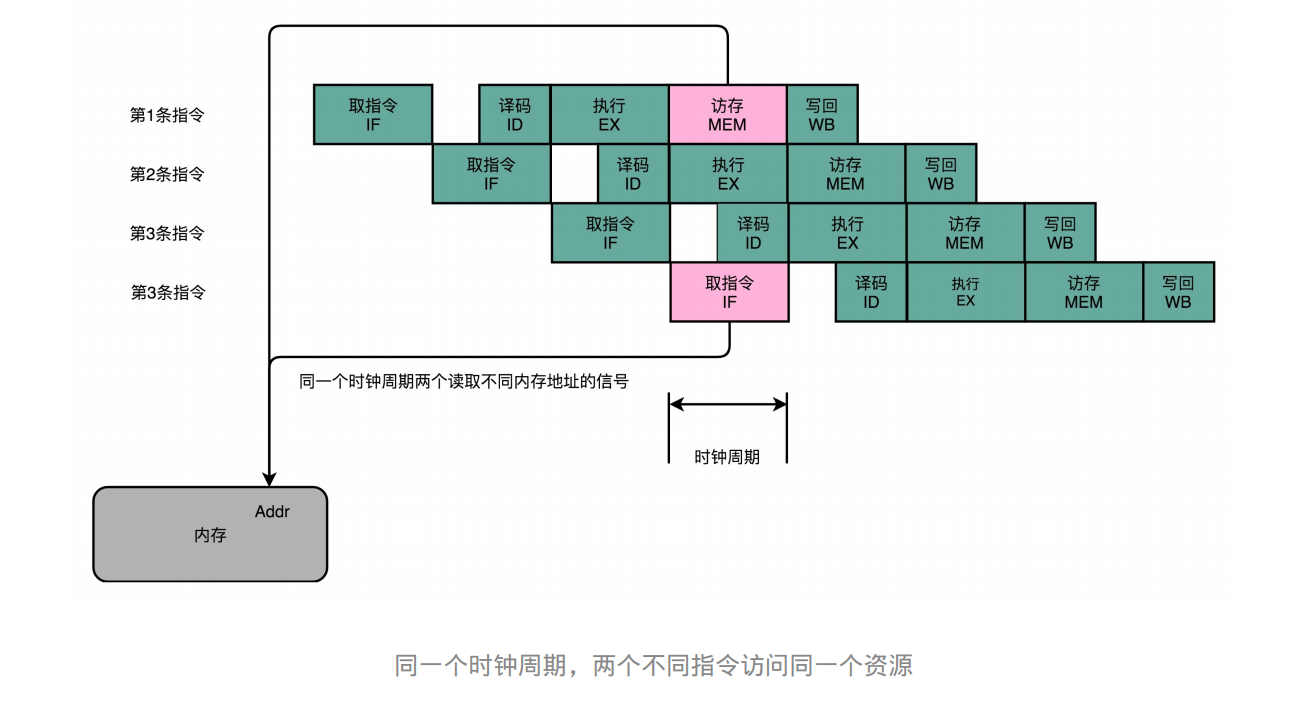
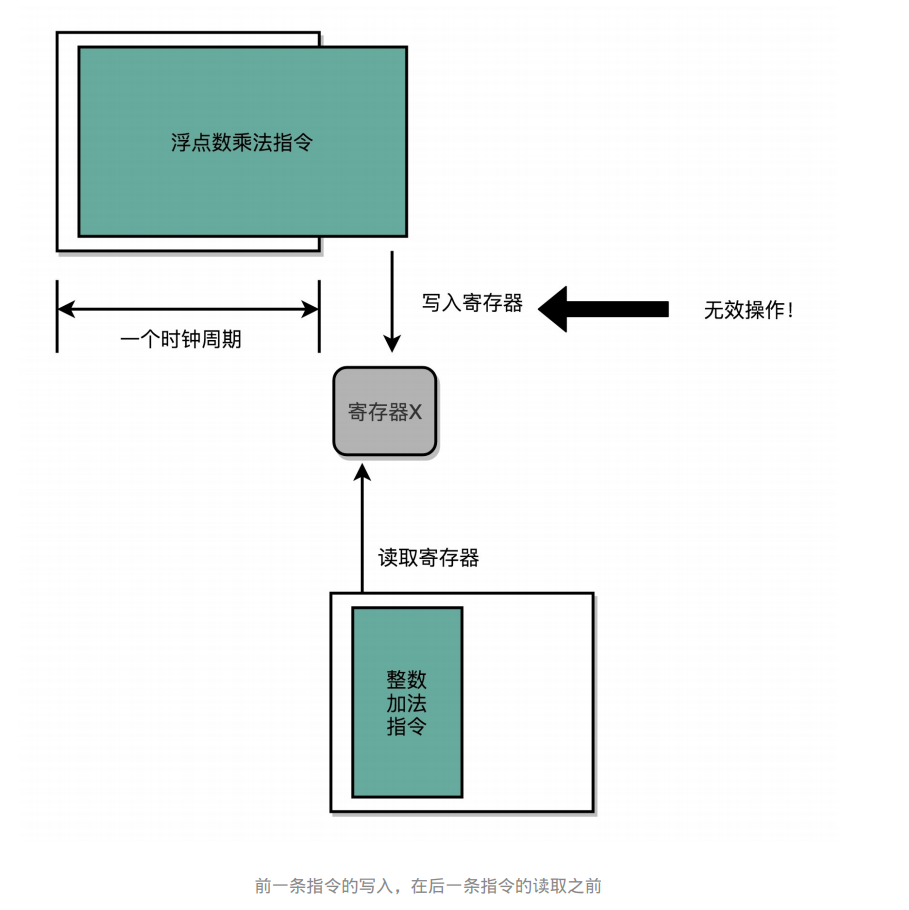
数据冒险:三种不同的依赖关系
数据冒险:在多个并发的指令间,有数据依赖的情况(RAW,WAR,WAW )
这个先写后读的依赖关系,我们一般被称之为数据依赖,也就是Data Dependency。
这个先读后写的依赖,一般被叫作反依赖,也就是Anti-Dependency。
写后再写的依赖,一般被叫作输出依赖,也就是Output Dependency。
先写后读(Read After Write,RAW)
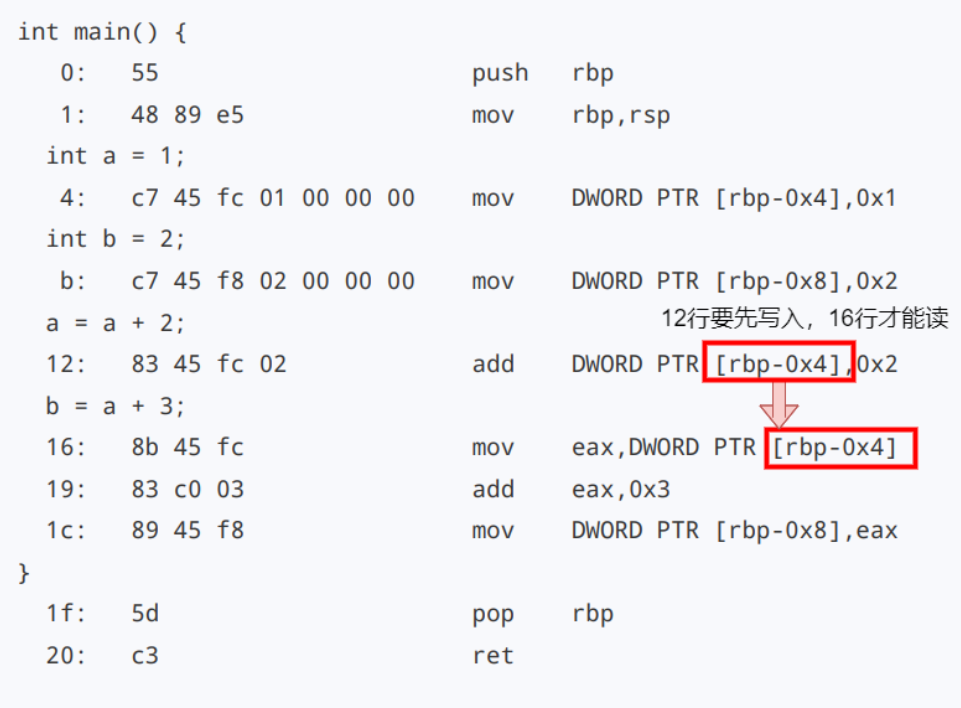
定义两个变量 a 和 b,然后计算 a = a + 2。再计算 b = a + 3。
int main() {
int a = 1;
int b = 2;
a = a + 2;
b = a + 3;
}
先读后写(Write After Read)
先计算 a = b + a,然后再计算 b = a + b。
int main() {
int a = 1;
int b = 2;
a = b + a;
b = a + b;
}

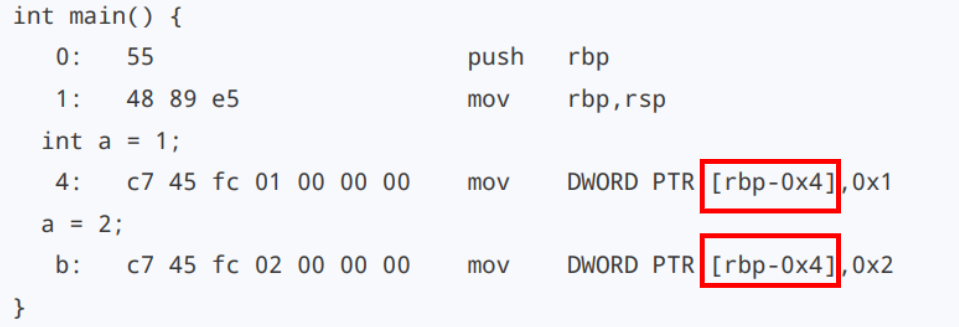
写后再写(Write After Write)
这次,我们先设置变量 a = 1,然后再设置变量 a = 2。
int main() {
int a = 1;
a = 2;
}
再等等:通过流水线停顿解决数据冒险
- 问题:怎么解决数据冒险?
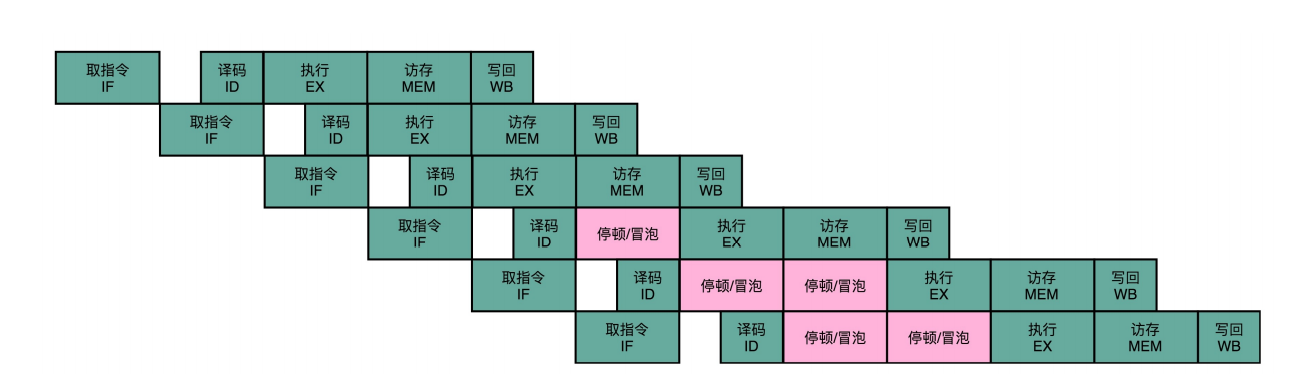
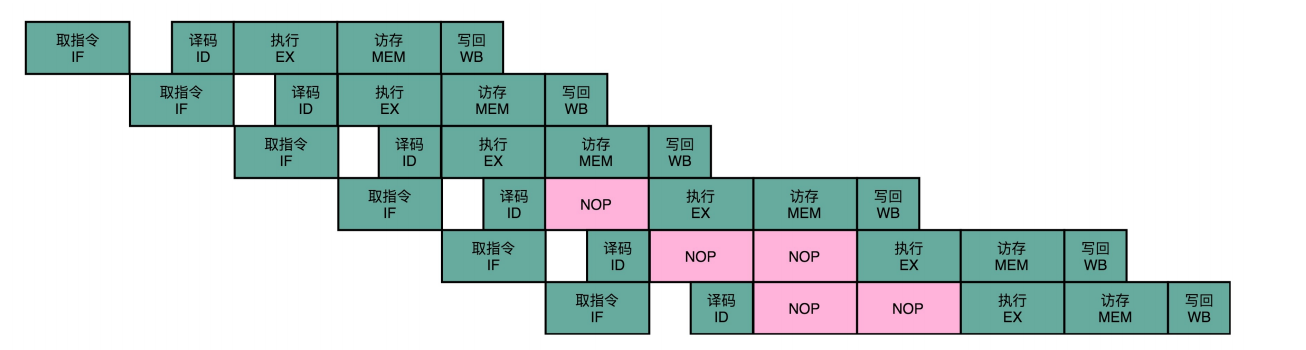
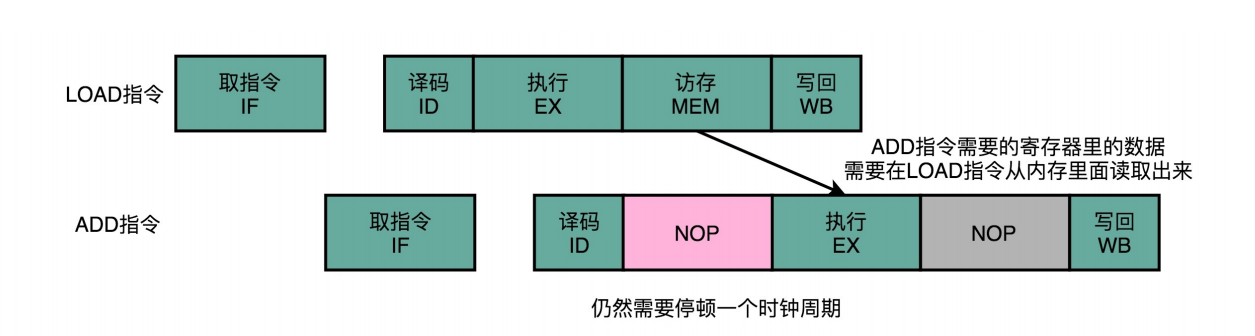
- 解决:流水线停顿:后面指令插入等待的阶段,等前面的指令释放资源
- 缺点:浪费CPU资源
- 解决:操作数前推
- 优点:减少CPU资源浪费(NOP),减少两次寄存器操作
- 缺点:前面指令没执行完特点阶段,下一条相关指令还是会被“阻塞”
- 解决:乱序执行
- 优点:可以利用保留站来避开并行指令间的资源竞争和慢速操作
- 缺点:CPU结构变复杂,系统中断时保存上下文更复杂.
- 一旦发生指令跳转,指令缓存池中指令都浪费,因为不是按顺序执行所以恢复到跳转位置的状态复杂
流水线停顿(Pipeline Stall),或者叫流水线冒泡(Pipeline Bubbling)。
23-冒险和预测(二):流水线里的接力赛
结构冒险和数据冒险,以及应对这两种冒险的两个解决方案。一种方案是增加资源, 通过添加指令缓存和数据缓存,让我们对于指令和数据的访问可以同时进行。这个办法帮助CPU解决了取指 令和访问数据之间的资源冲突。另一种方案是直接进行等待。通过插入NOP这样的无效指令,等待之前的指 令完成。这样我们就能解决不同指令之间的数据依赖问题。
- 问题:怎么才能减少浪费CPU资源来解决数据冒险?
- 解决:操作数前推。
NOP操作和指令对齐
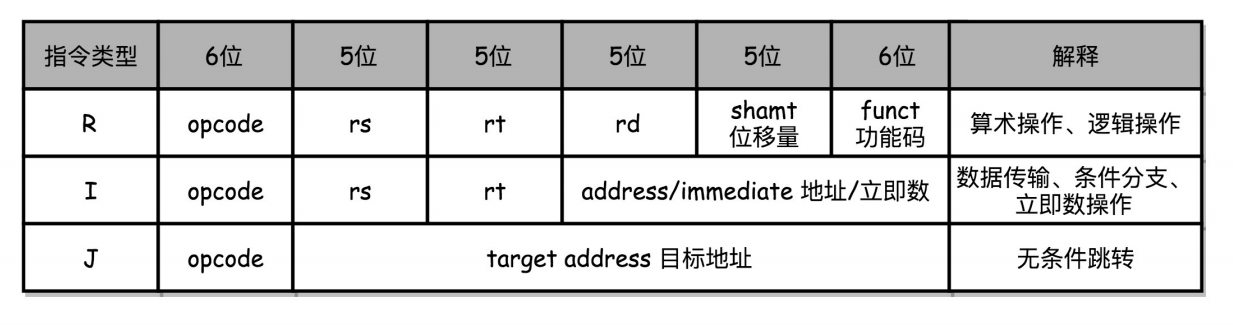
MIPS体系结构下的R、I、J三类指令。
五级流水线“取指令(IF)-指令译码(ID)-指令执行(EX)-内存访问(MEM)-数据写回 (WB) ”。
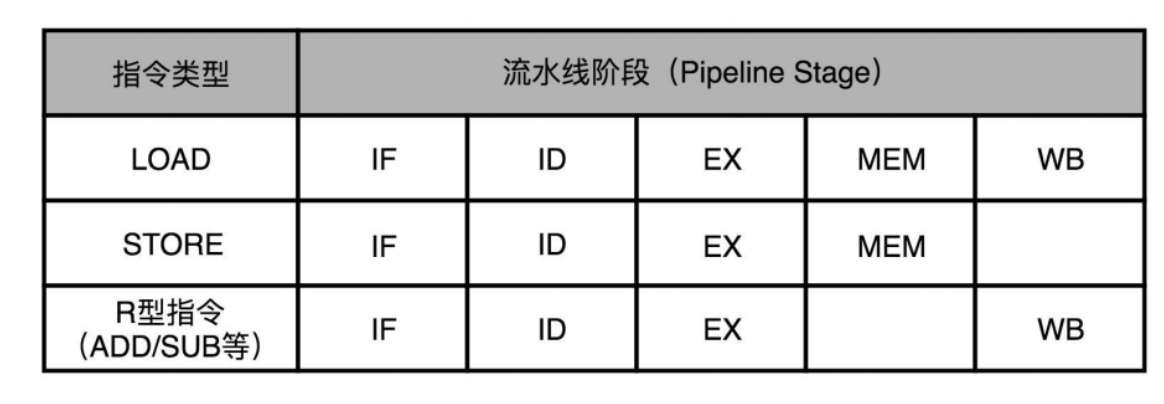
指令可以NOP一个空流水线阶段但不可以跳过。如果跳过则会改变并发指令间的流水线阶段差,相当于多个指令共用某个模块。产生结构冒险,导致资源竞争 。
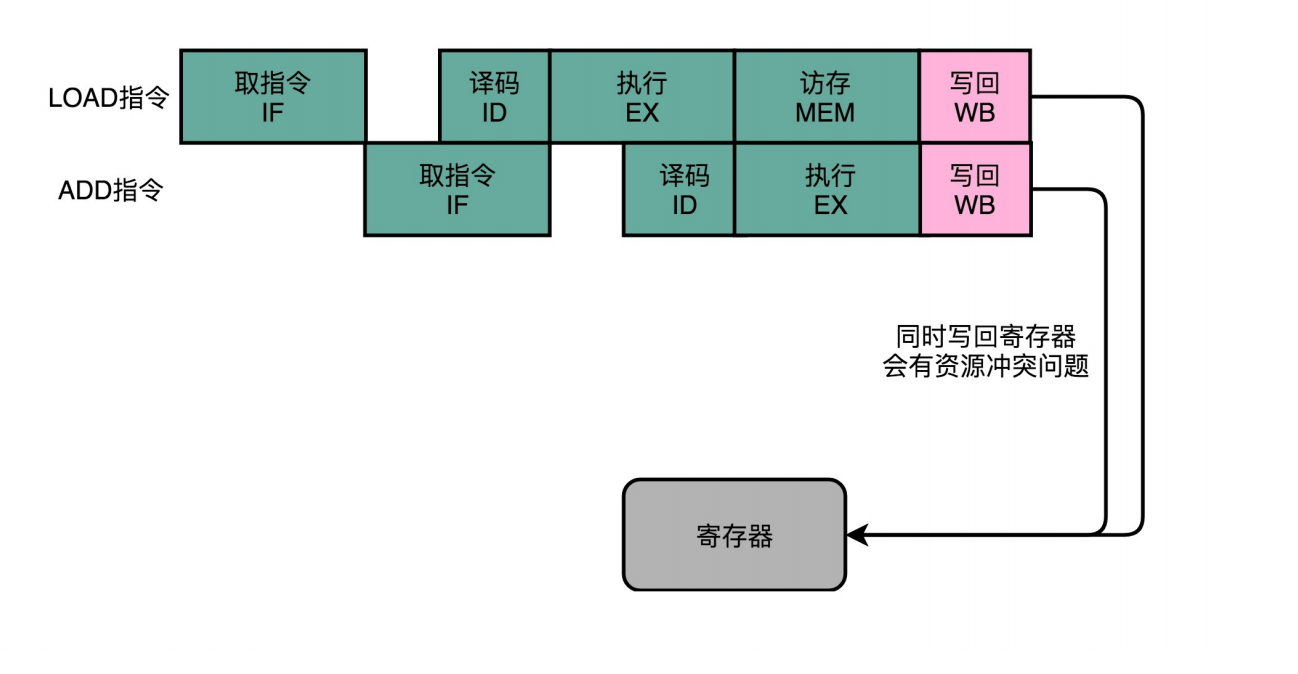
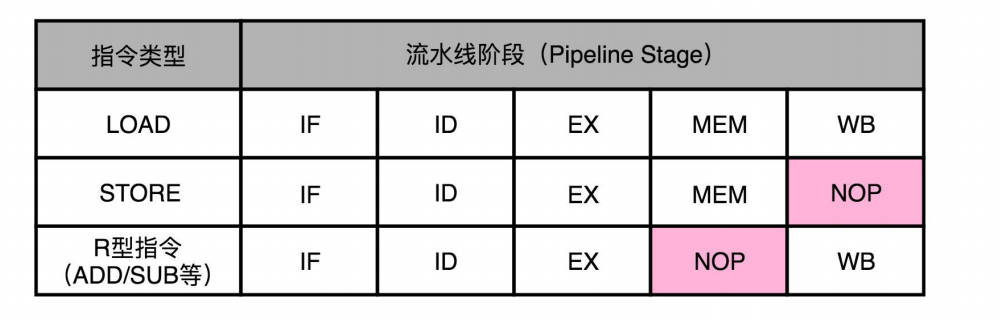
流水线里的接力赛:操作数前推
add $t0, $s2,$s1
add $s2, $s1,$t0
- 正常执行:指令2要等指令1中s1寄存器的值
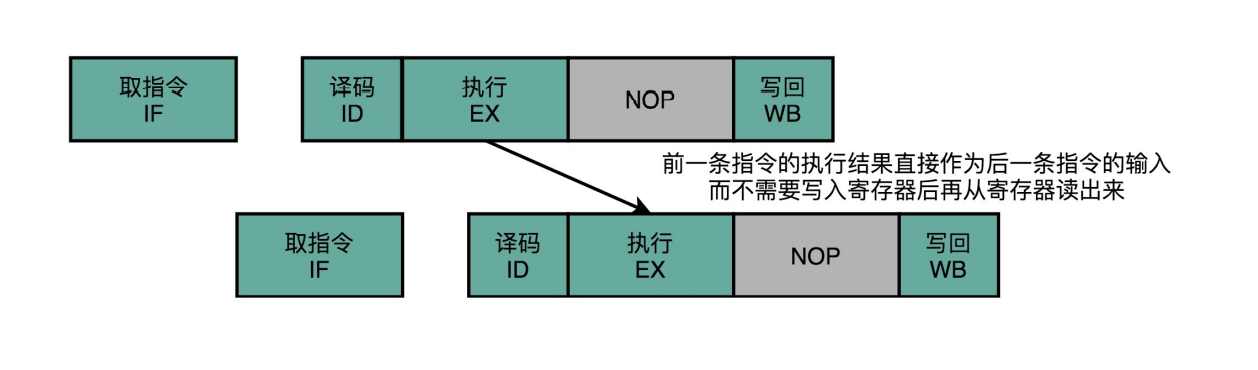
- 操作数前推 :在第一条指令的执行阶段完成之后,直接将结果数据传输给到下一条指令的ALU。
- 硬件实现:在CPU中再单独连接ALU的输入输出端。使ALU的输出能直接传给输入端它越过(Bypass)了读写寄存器
- 优点:减少CPU空闲时间(NOP),减少两个寄存器的操作
操作数前推(Operand Forwarding),或者操作数旁路(Operand Bypassing)
操作数前推的解决方案可以和流水线冒泡一起使用。
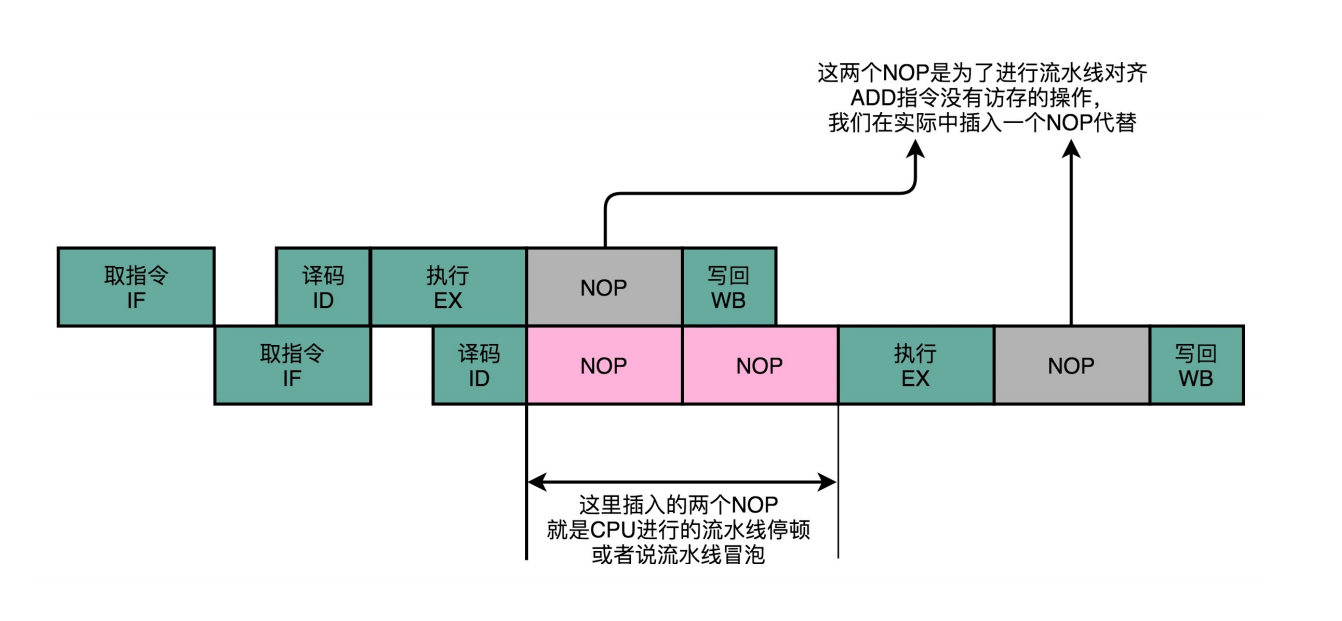
24-冒险和预测(三):CPU里的“线程池”
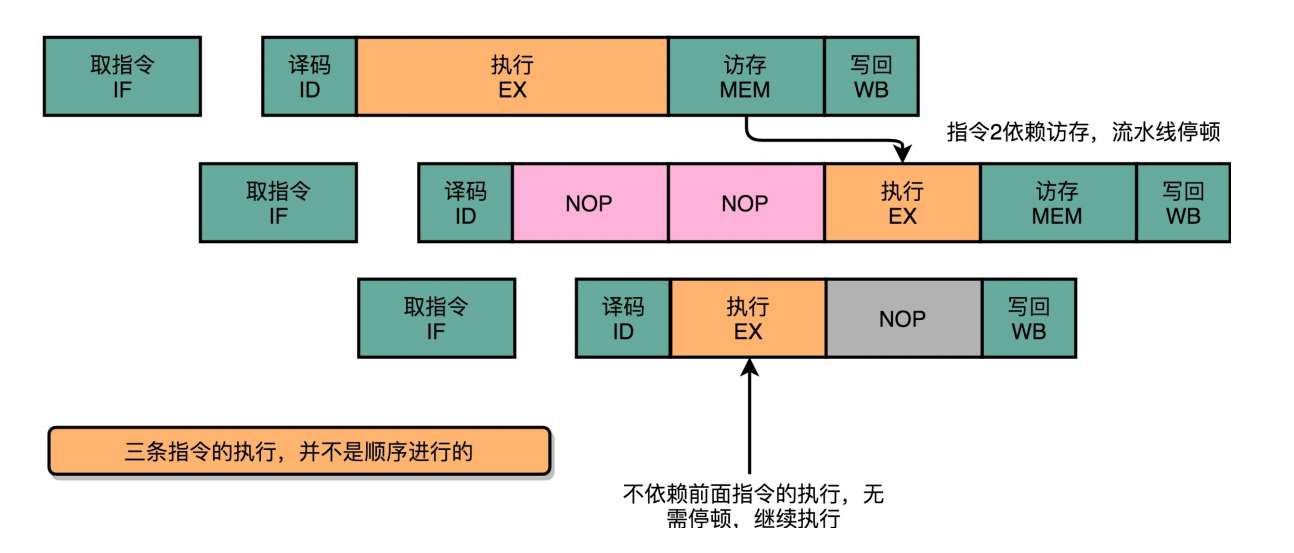
- 问题:那我们能不能让后面没有数据依赖的指令,在前面指令停顿的时候先执行呢?
- 解决:用保留站来避并行指令间的开资源竞争和慢速操作
填上空闲的NOP:上菜的顺序不必是点菜的顺序
在流水线里,后面的指令不依赖前面的指令,那就不用等待前面的指令执行,它完全可以先执行。
a = b + c
d = a * e
x = y * z
CPU里的“线程池”:理解乱序执行
从今天软件开发的维度来思考,乱序执行好像是在指令的执行 阶段,引入了一个“线程池”。
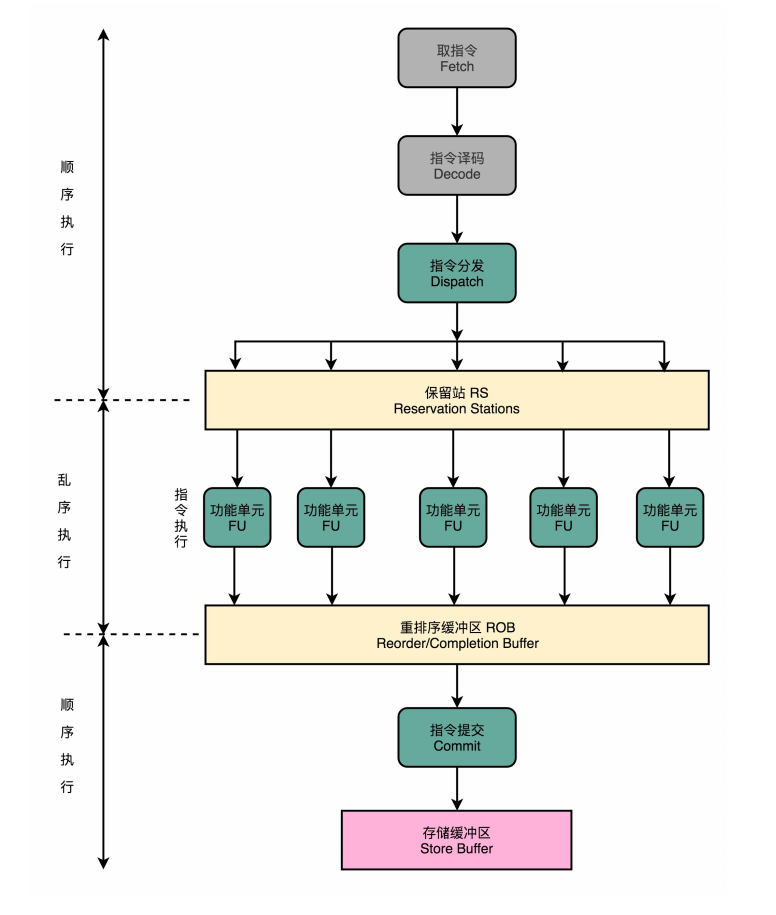
CPU里的流水线就加上保留站和重排序缓存区
乱序执行:
-
过程:
- 在译码阶段进行分析指令之间的数据依赖关系
- 指令译码完成之后会先把指令缓存到保留站。
- 这些指令等到它们所依赖的数据传递给它们之后才会被交到后面的功能单元。
- 指令执行结束后先缓存到重排序缓冲区,按原指令列表的顺序重排完整后提交指令到存储缓冲区(Store Buffer)
-
优点:
-
极大地提高了CPU的运行效率。弥补了CPU和内存之间的性能差异,也充分利用了较深的流水行带来的并发性
-
保留站(Reservation Stations)功能单元(Function Unit,FU)≈ALU,重排序缓冲区(Re-Order Buffer,ROB)
-
本质:
- 则是在指令执行的阶段通过一个类似线程池的保留站,让系统自己去动态调度指令的执行顺序。动态调度解决了流水线阻塞的问题。并且最终提交前再排序让整个动态调度对上层透明
25-冒险和预测(四):今天下雨了,明天还会下雨么?
-
问题:代码中出现jump时会破坏指令的执行顺序,影响流水线执行效果
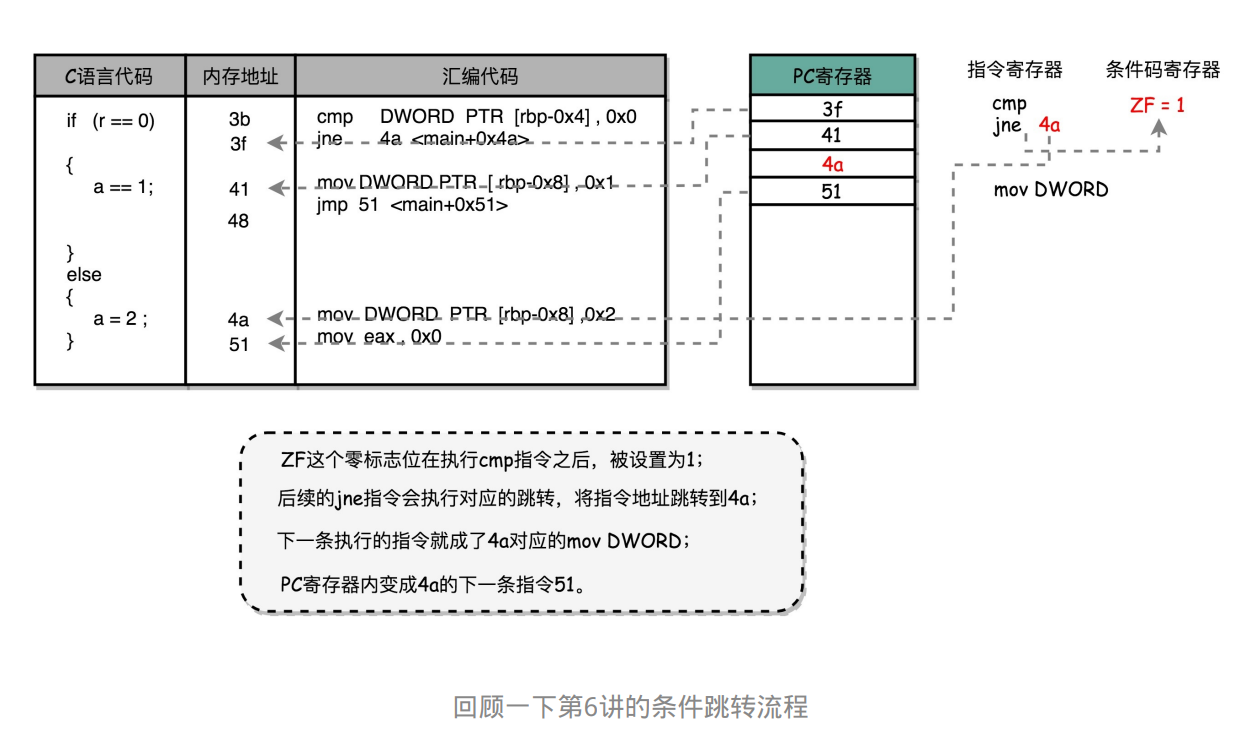
-
解决:缩短分支延迟。在指令周期结束前就把信息传给后面
- 用于比较的电路实现简单。所以将条件判断、地址跳转提前到指令译码阶段进行。在CPU里面设计对应的旁路更快向后反馈信息。(本质=操作数前移)
-
解决:分支预测。通过信息预测下条分支把分支当作顺序执行
-
静态分支预测
- 默认不发生跳转。
-
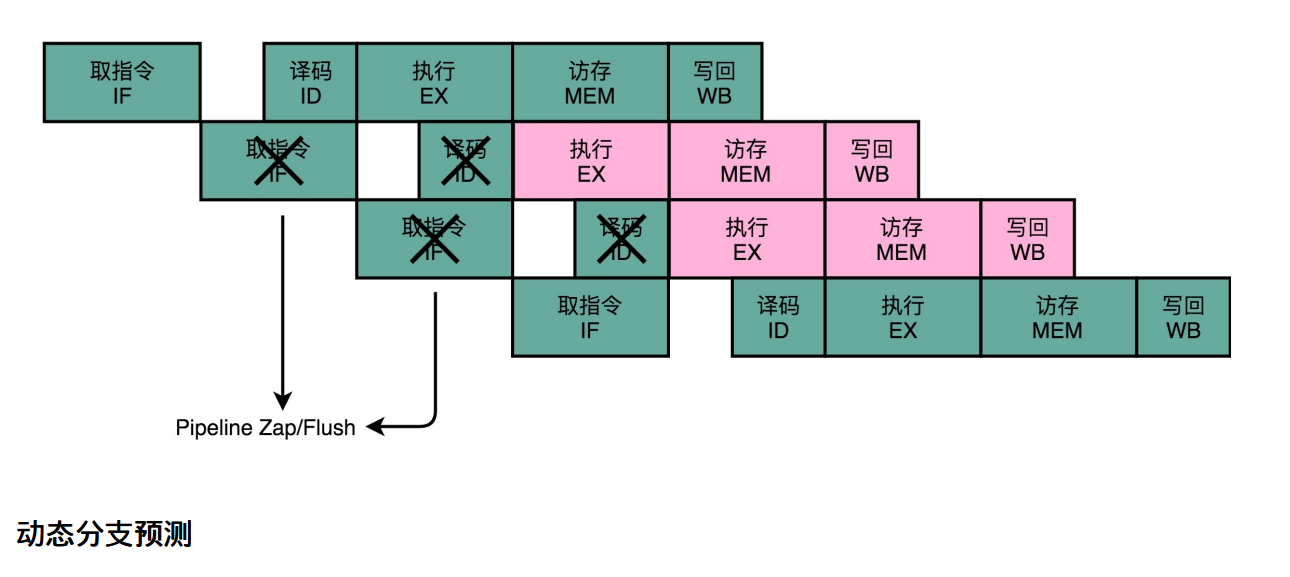
动态分支预测
-
一级分支预测:下次复用上次的选择
-
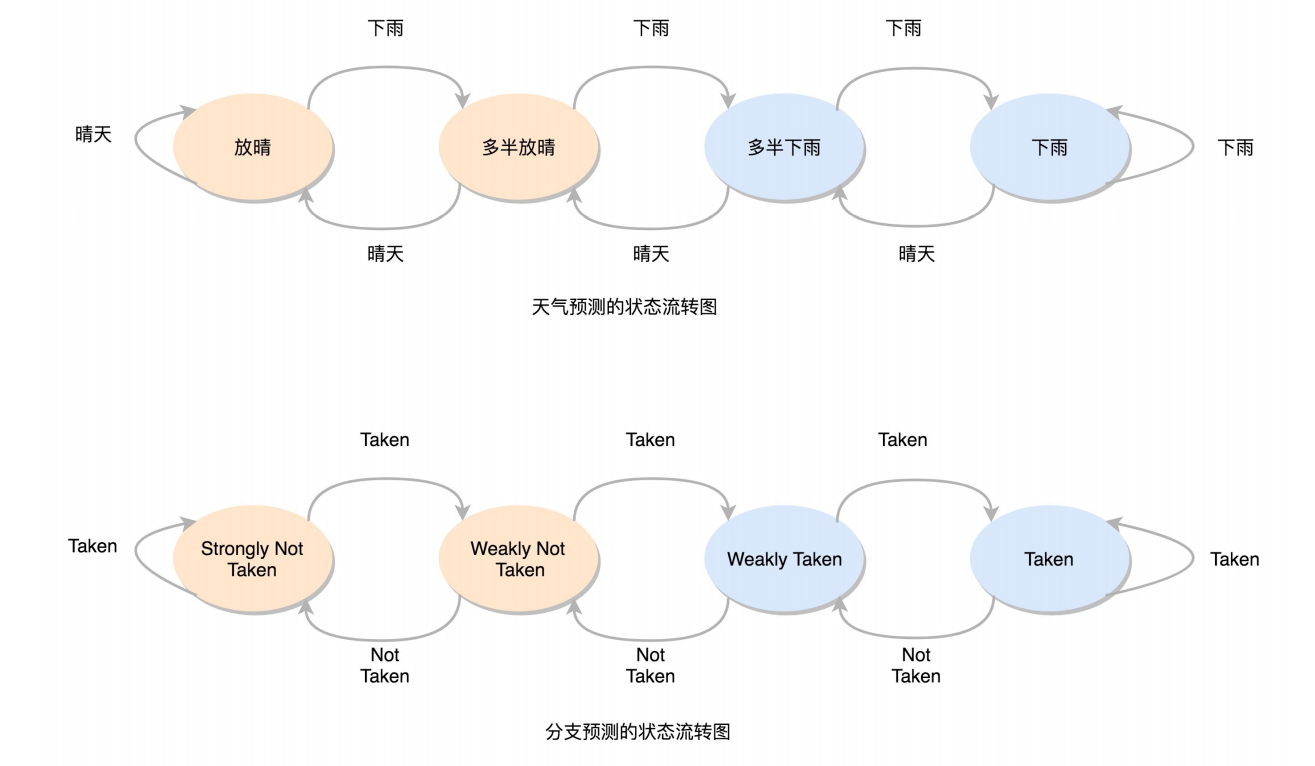
双模态预测器:引入状态机,有输入信号时根据之前的阶段判断是累加阶段还是转换状态
-
一级分支预测(One Level Branch Prediction),或者叫1比特饱和计数(1-bit saturating counter)。2比特饱和计数,双模态预测器(Bimodal Predictor)。
双模态预测器(Bimodal Predictor)。















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









