






 KG-BERT通过微调预训练的Bert模型,利用实体和关系的上下文描述进行知识图谱任务,如三元组分类和链接预测。KEPLER则尝试统一语言模型和知识图谱表示,通过实体和关系描述的编码,实现更丰富的文本和知识表示。两种方法都强调了描述在捕获语义和关系中的作用,但计算成本和效率是挑战。
KG-BERT通过微调预训练的Bert模型,利用实体和关系的上下文描述进行知识图谱任务,如三元组分类和链接预测。KEPLER则尝试统一语言模型和知识图谱表示,通过实体和关系描述的编码,实现更丰富的文本和知识表示。两种方法都强调了描述在捕获语义和关系中的作用,但计算成本和效率是挑战。
Kg-bert
为了通过丰富的语言模型充分利用上下文的表征,对知识图谱完成的预训练Bert进行了微调,将实体和关系表示为它们的名称或者描述,然后再将名称/描述序列作为bert模型输入的句子,进行fine-tuning。将两个实体(实体名称/实体描述)或者三元组(h,r,t)作为bert的输入序列。
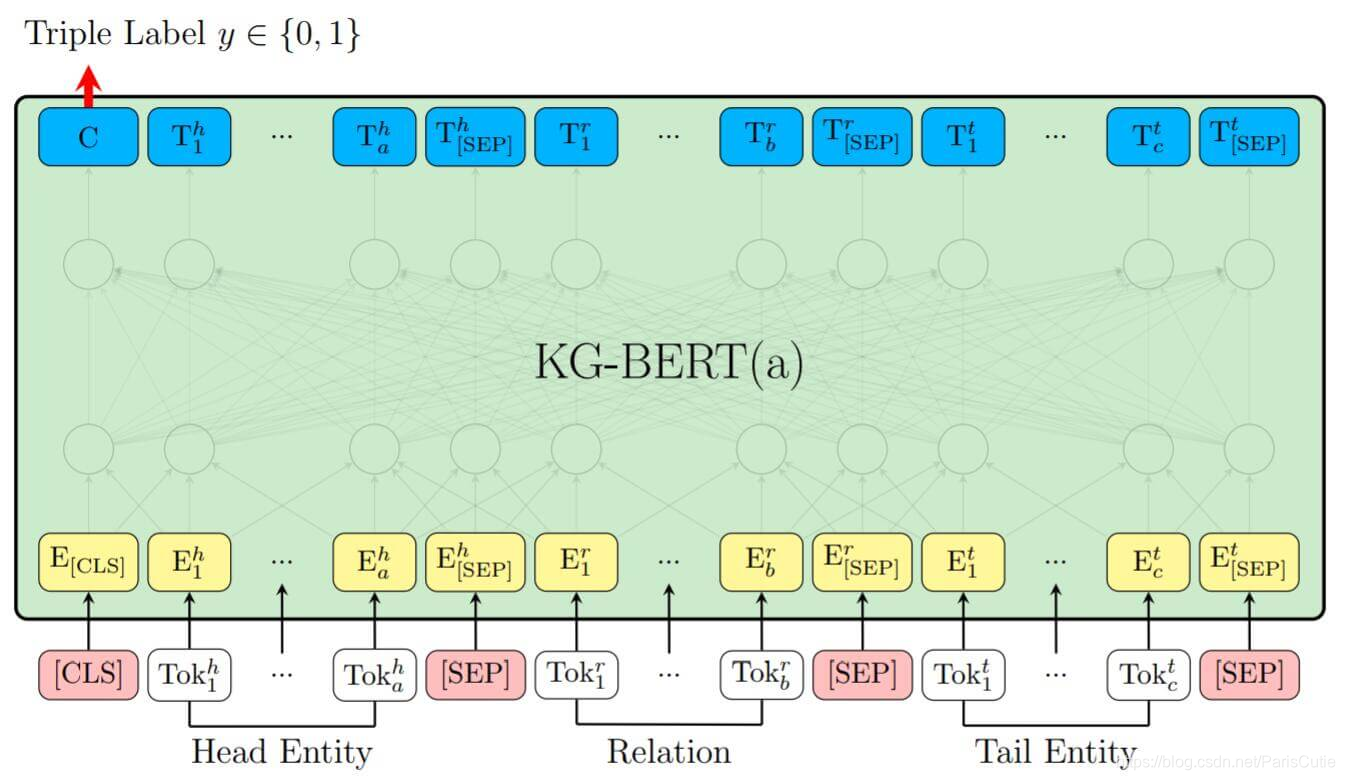
KG-Bert(a):将实体和关系的名称/描述直接放入bert,并用 [CLS] 处的输出C来预测三元组是否正确。
例如, 三元组(SteveJobs,founded,AppleInc)中的头实体SteveJobs 可以表示为它的描述Steven Paul Jobs was an American business magnate, entrepreneur and investor 或者它的名字Steve Jobs, 而尾实体 AppleInc可以表示为Apple Inc. is an American multinational technology company headquartered in Cupertino, California或者它的名称Apple Inc.
在不同的实体和关系之间用 [SEP] 分隔,每个Token的描述分别为Token本身的embedding和Position Embedding,Segment Embeding组成,头实体和尾实体都使用
e
A
e_{A}
eA作为Segement Embeding,而关系使用
e
B
e_{B}
eB
最后的输出C用来计算三元组的分类,对于三元组(h,r,t)其打分函数为:
s
τ
=
f
(
h
,
r
,
t
)
=
s
i
g
m
o
i
d
(
C
W
T
)
s_{\tau}=f(h,r,t)=sigmoid(CW^{T})
sτ=f(h,r,t)=sigmoid(CWT)
其中损失函数为:
L
=
−
∑
τ
∈
D
+
⋃
D
−
(
y
τ
l
o
g
(
s
τ
0
+
(
1
−
y
τ
)
l
o
g
(
s
τ
1
)
)
)
L=-\sum_{\tau \in D+\bigcup D-}(y_{\tau}log(s_{\tau0}+(1-y_{\tau})log(s_{\tau1})))
L=−τ∈D+⋃D−∑(yτlog(sτ0+(1−yτ)log(sτ1)))
其中
y
τ
y_{\tau}
yτ是三元组是正例还是负例的标签
∈
0
,
1
\in{0,1}
∈0,1,D-表示负例,通过仅替换
头实体和尾实体得来的。
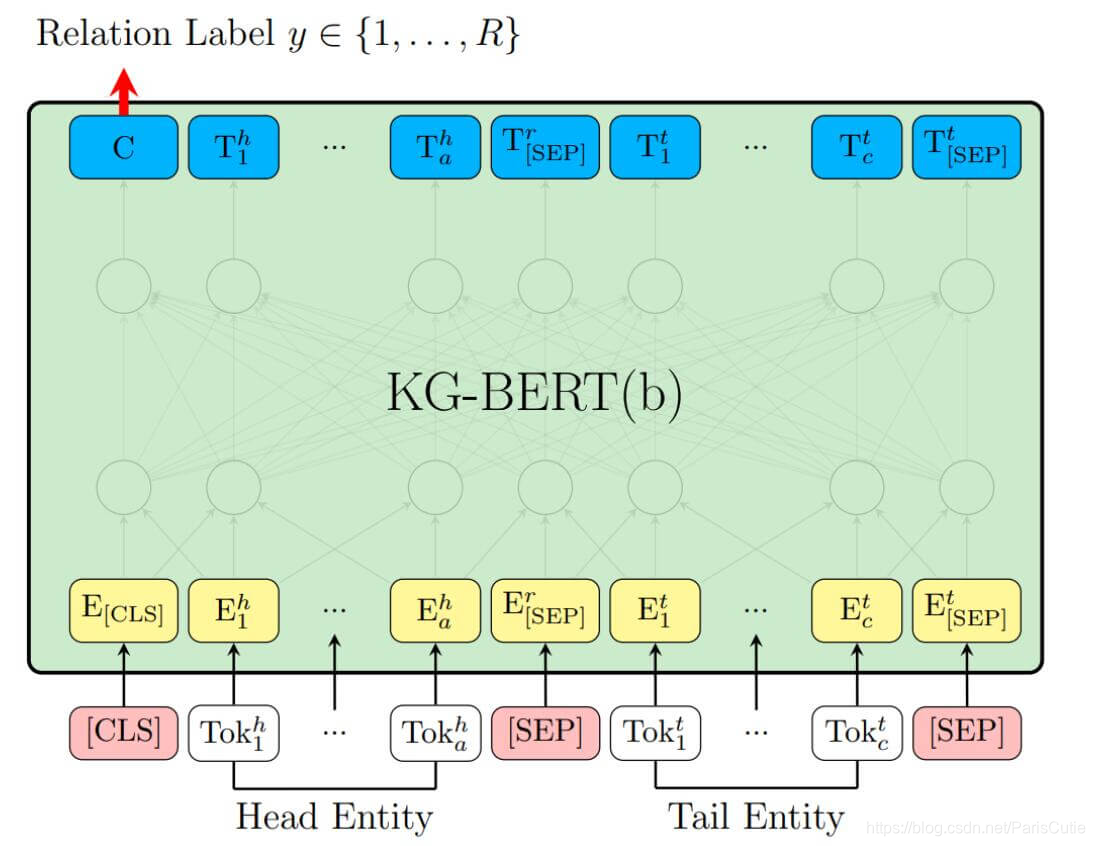
在KG-Bert(b)中,只使用两个实体h,t的描述来预测它们之间的关系r,并且这种结构在预测关系时要优于KG-Bert(a)。KG-Bert(b)采用**[CLS]**处的输出C接一个分类矩阵来预测两个实体之间的关系。
s
τ
′
=
f
(
h
,
r
,
t
)
=
s
o
f
t
m
a
x
(
C
W
T
)
s_{\tau}^{'}=f(h,r,t)=softmax(CW^{T})
sτ′=f(h,r,t)=softmax(CWT)
损失函数采用多分类任务
L
′
=
−
∑
τ
∈
D
+
∑
i
=
1
R
y
τ
i
′
l
o
g
(
s
τ
i
′
)
L^{'}=-\sum_{\tau \in D+} \sum_{i=1}^{R} y_{\tau i}^{'}log(s_{\tau i}^{'})
L′=−τ∈D+∑i=1∑Ryτi′log(sτi′)
其中
y
τ
i
′
y_{\tau i}^{'}
yτi′是关系的独热向量
Triple Classification
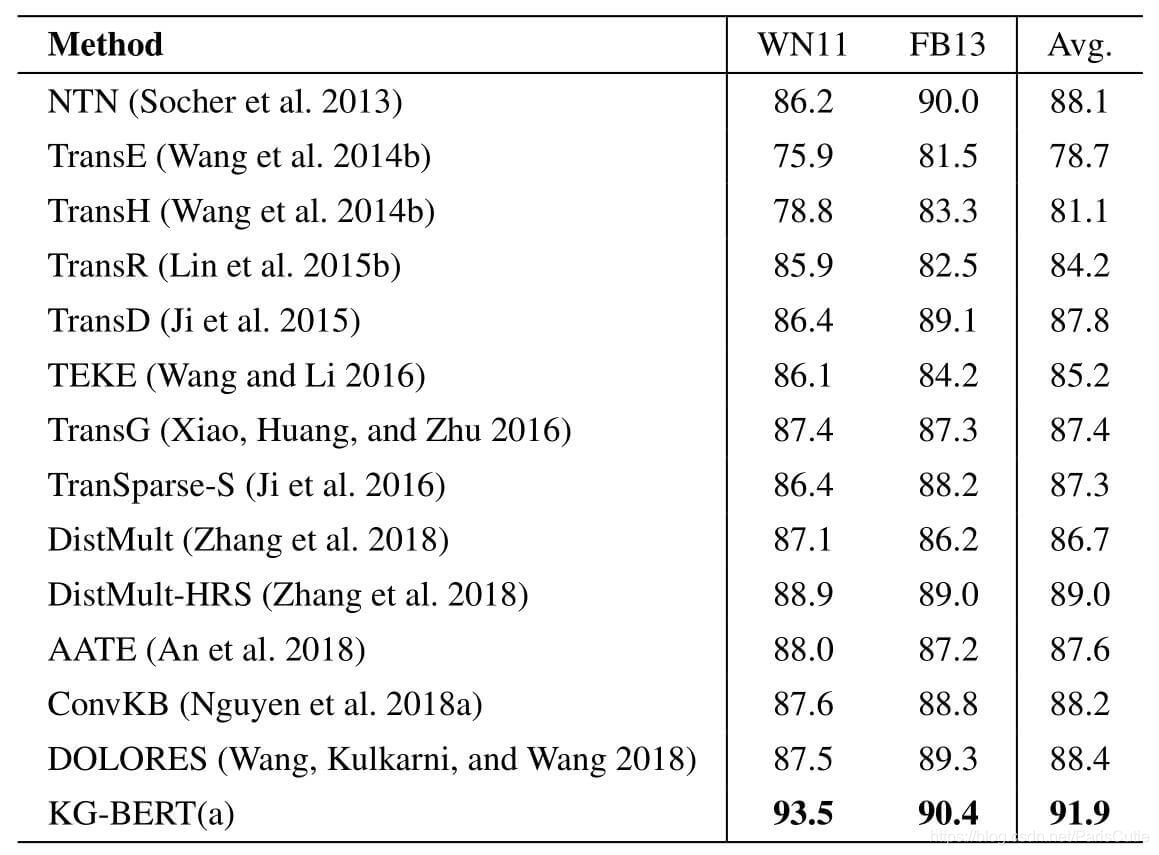
三元组分类的目的是判断一个给定的三元组(h,r,t)是否正确,KG-Bert(a)可以充分利用大型外部文本数据中丰富的语言模式来克服知识图谱的稀疏性。
而KG-Bert(a)表现良好的主要原因是:
- 输入含有实体和关系的单词序列(使用了文本描述)
- 三元组分类任务和Bert训练时的NSP任务类似,可以捕捉到文本中两个句子之间的关系
- Token Vector结合了上下文,不同三元组中描述往往不同,因此不同三元组中相同元素则可以获得不同的表示
- Self-attention可以发现三元事实中最重要的词
Link Prediction
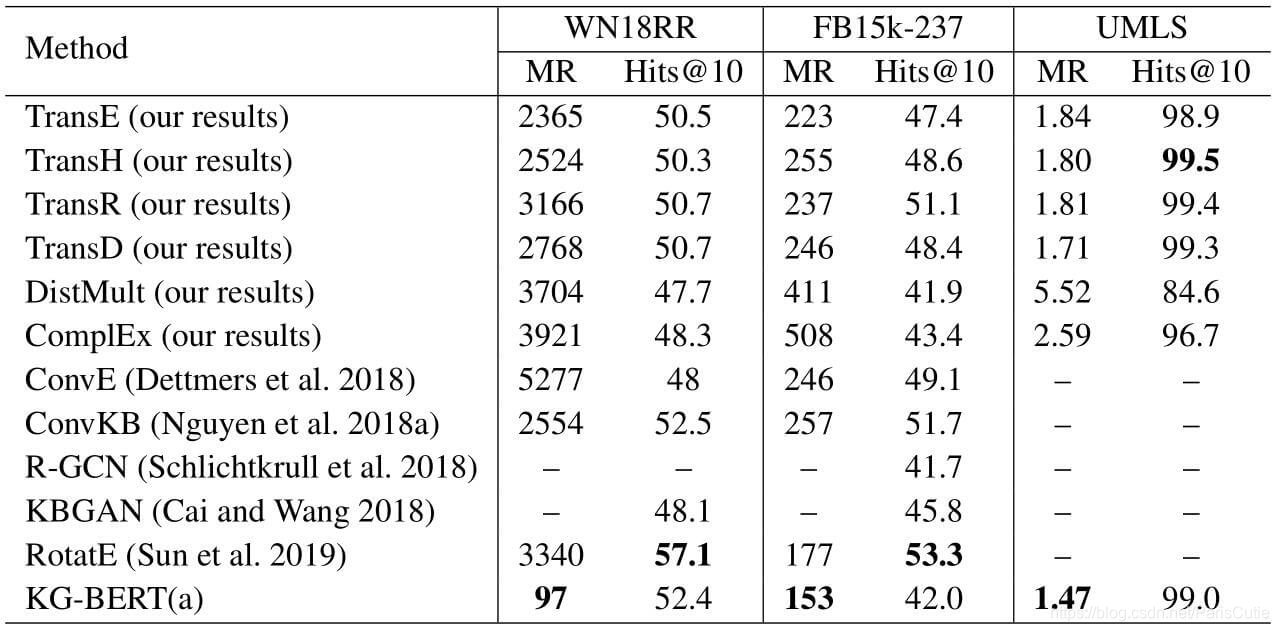
KG-Bert(a)在MR上取得了很好的效果,但是Hit@10表现就不太好,KG-Bert虽然能避免实体和实体相关性很强的相似三元组,但没对三元组本身进行明确的建模,因此不好给定准确的排名。
link prediction预测评估需要用几乎所有的实体替换头实体或尾实体,而且所有被替换后的三元组序列都需送入模型,所以模型的评估是非常耗时的。
Relation Prediction
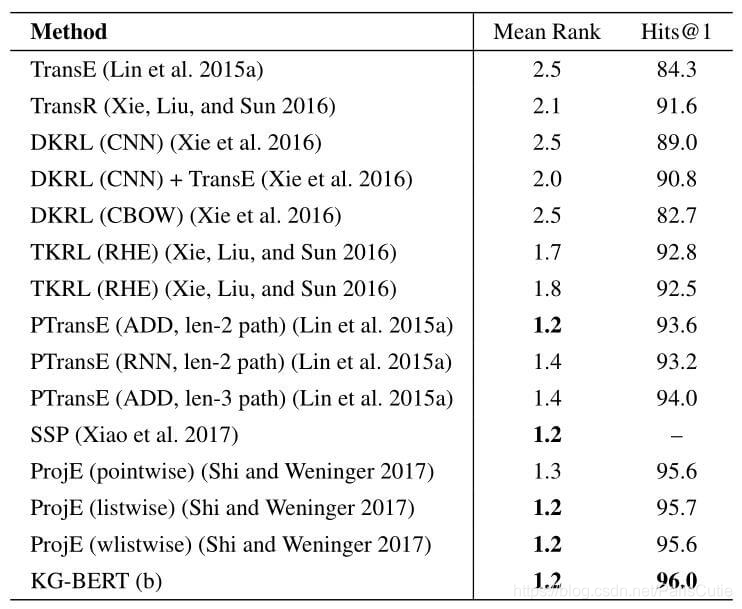
KG-类似与BERT微调中的句对分类,也可以从Bert预训练中受益。
Attention Visualization
从KG-Bert(a)取出第11层,以 (twenty dollar bill NN 1, hypernym, note NN 6) 为例子,头实体描述为 a United sates bill worth 20 dollars , 关系名 hypernym ,尾实体描述 a piece of paper money 作为序列。

p
a
p
e
r
paper
paper和
m
o
n
e
y
money
money具有很高的权重,同时模式很好学到了
[
s
e
p
]
[sep]
[sep]的作用
在KG-Bert(b)中,以三元组 *(20th century ,/time/event/includes event, World War II)*为例
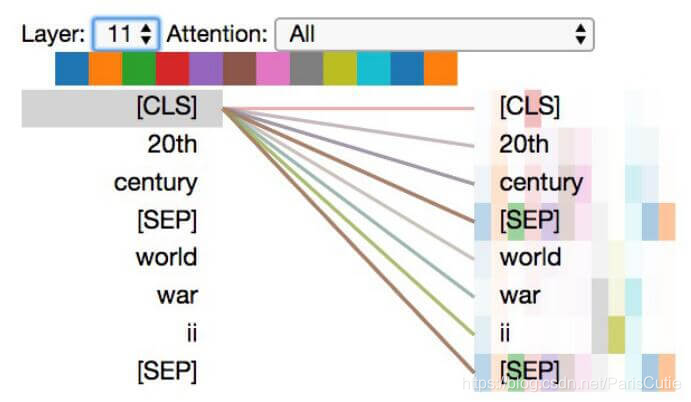
b学到了类似a的模式,不过每个头的注意力更为分散,由于b的目标是对实体进行关系预测,所以对
[
C
L
S
]
[CLS]
[CLS]分配了更高的权重
Summary
KG-Bert现在最大的问题是计算成本太高,尤其是链接预测,轮流替换实体描述花费了大量的时间,不过总的来说,输入数据的方式很简单,将知识图谱的任务转换为序列分类问题,同时可以利用文本中的丰富语义信息,并突出显示与三元组相关的最重要的词。
KEPLER
预训练语言模型不能从文本中获得常识,而KGE能获得知识图谱中实体和关系的有效表示,却不能捕捉上下文。KEPLER是一个KGE和PLM表示统一的模型,它包含了PLM和KE的联合优化目标。
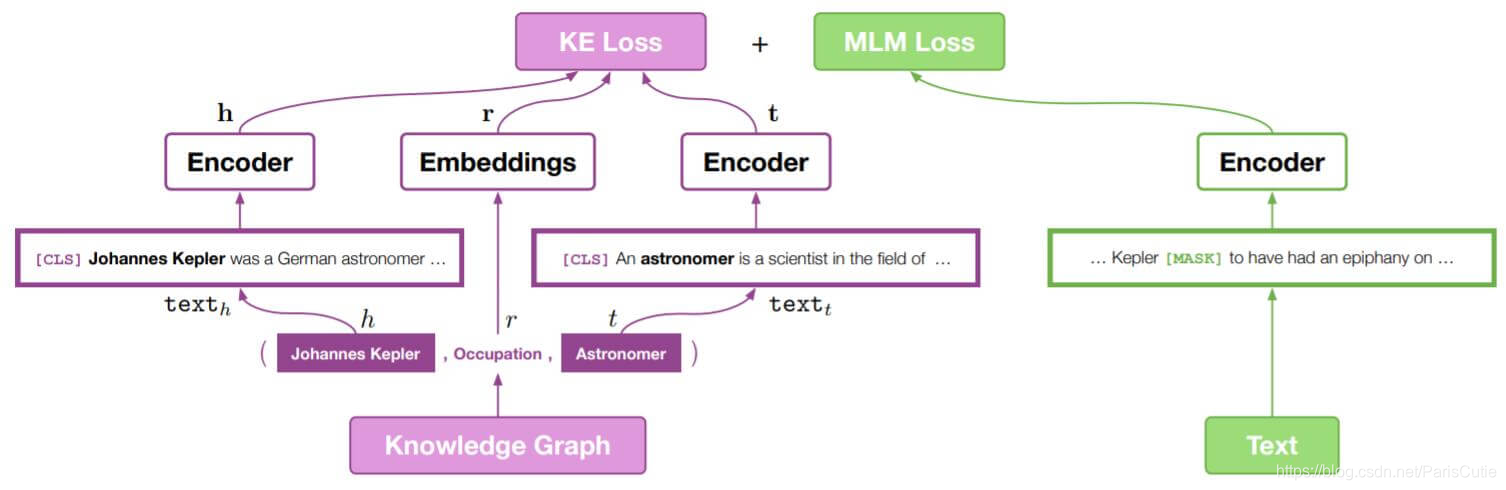
Encoder
采用Transformer Encoder将
N
N
N个序列作为输入,经过
L
L
L层Transformer Encoder堆叠,得到
d
d
d维的上下文表示
H
i
H_i
Hi,
1
≤
i
≤
L
1≤i≤L
1≤i≤L,每层编码器
E
i
E_i
Ei由多头自注意力和前馈神经网络组成,每层Encoder表示:
H
i
=
E
i
(
H
i
−
1
)
H_{i}=E_i(H_{i-1})
Hi=Ei(Hi−1)
对于任意文本,将经过编码后的 [CLS] 处
[
E
C
L
S
]
[E_{CLS}]
[ECLS] 作为文本的表示
Knowledge Embedding
KEPLER将实体和关系映射到
d
d
d 维的空间中,并使用打分函数训练。
它不在存储Embedding,而是将实体结合它们本身的描述编码作为Embedding,本文设计了三种有效的方式
- 实体描述作为嵌入
- 实体和关系描述作为嵌入
- 关系为条件的实体嵌入
Entity Descriptions Embeddings
对于三元组(h,r,t)只使用三元组就是对头实体
h
h
h的描述
t
e
x
t
h
text_h
texth和尾实体
t
t
t的描述
t
e
x
t
t
text_t
textt分别进行编码,然后再将关系
r
r
r单独嵌入:
h
=
E
[
C
L
S
]
(
t
e
x
t
h
)
h=E_{[CLS]}(text_h)
h=E[CLS](texth)
t
=
E
[
C
L
S
]
(
t
e
x
t
t
)
t=E_{[CLS]}(text_t)
t=E[CLS](textt)
r
=
T
r
r=T_r
r=Tr
其中
T
r
T_r
Tr代表关系
r
r
r的Embedding权重。
Entity and Relation Descriptions
r
^
=
E
<
s
>
(
t
e
x
t
r
)
\hat{r}=E_{<s>}(text_r)
r^=E<s>(textr)
将关系的描述进行编码,用
r
^
\hat{r}
r^替换
r
r
r。
Entity Embedding Conditioned On Relations
直觉上,一个实体的语义可能有多个方面,不同的关系关注于不同的方面,以这种方式,使用
r
r
r为条件的实体嵌入
h
r
=
E
<
s
>
(
t
e
x
t
h
,
r
)
h_r=E_{<s>}(text_{h,r})
hr=E<s>(texth,r)
t e x t h , r text_{h,r} texth,r是拼接了 h h h和 r r r,同样在开头加上 < s > <s> <s>,末尾加上 < / s > </s> </s>,用 h r h_r hr替代 h h h.
Knowledge Embedding Loss and Score Function
KE损失函数如下:
L
K
E
=
−
l
o
g
σ
(
γ
−
d
r
(
h
,
t
)
)
−
∑
i
=
1
n
1
n
l
o
g
σ
(
d
r
(
h
i
′
,
t
i
′
)
−
r
)
L_{KE}=-log \sigma(\gamma -d_r(h,t))-\sum^n_{i=1} \frac{1}{n}log \sigma(d_r(h^{'}_i,t_i^{'})-r)
LKE=−logσ(γ−dr(h,t))−∑i=1nn1logσ(dr(hi′,ti′)−r)
其中
(
h
i
′
,
r
,
t
i
′
)
(h^{'}_i,r,t_i^{'})
(hi′,r,ti′)是负采样得到的样本
σ
\sigma
σ是sigmoid激活函数,
γ
\gamma
γ是间隔,
d
r
d_r
dr是打分函数,沿用TransE的打分函数:
d
r
(
h
,
t
)
=
∣
∣
h
+
r
−
t
∣
∣
p
d_r(h,t)=||h+r-t||_p
dr(h,t)=∣∣h+r−t∣∣p
Masked Language Modeling
在Msked Language Modeling上,沿用了Bert的MLM训练损失,结构和mask方式都没有发生变化,在分类时仍是在Encoder的最后一层输出
H
L
,
j
H_{L,j}
HL,j后接上和字典等同大小的
W
W
W路分类器。
Training Objectives
训练目标就是KGE和MLM部分之和
L
=
L
K
E
+
L
M
L
M
L=L_{KE}+L_{MLM}
L=LKE+LMLM
两部分目标是共享Encoder的,训练时可以采样不同类型的文本作为训练数据
Summary
作者分别从PLM和KGE两个方面总结了KEPLER的优点:
- 作为PLM,将常识集成进语言表示,并且具有强大的语言理解能力,增强了抽取知识的能力,能够直接适应很多NLP任务。
- 作为KEM,能够丰富文本信息,能在文本描述的引导下预测从未出现的实体。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









