






资料
实例
import pandas as pd
df = pd.read_csv('Data/Region_Data.csv', encoding='gbk', skiprows=3, skipfooter=2, engine='python')
df.head()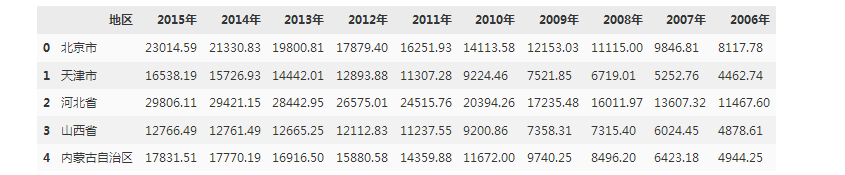
# df = pd.melt(df, id_vars='地区', value_vars='2015年', col_level=0)
df = pd.melt(df, id_vars='地区', col_level=0)
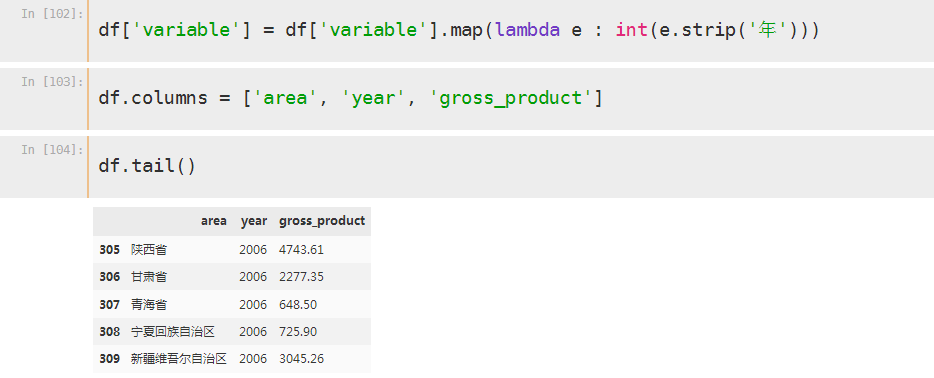
import sqlite3 as db
with db.connect('country_stat.sqlite') as con:
df.to_sql('region_gross_product', con=con, if_exists='replace', index=None)
with db.connect('country_stat.sqlite') as con:
sql = 'select * from region_gross_product \
where year=2015 \
order by gross_product \
desc \
limit 10'
df2 = pd.read_sql(sql, con=con)

with db.connect('country_stat.sqlite') as con:
sql = 'select area, avg(gross_product) as avg_gross_product from region_gross_product \
group by area \
having avg_gross_product >= 10000' #在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
df3 = pd.read_sql(sql, con=con)
















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











