






ChatGPT背后的技术:强化学习与RLHF
摘要
最近,以ChatGPT为主的超大语言模型相继出现,在人类语言理解及对话方面都表现出了卓越的效果。ChatGPT通过In-Context Learning和Chain-of-thought(COT)等一系列包含指令的任务获得逻辑能力,能够更准确、更可靠地理解和执行各种形式多变的任务。ChatGPT的背后拥有较为完备的技术方案体系,包括instruction tuning、loss中的RLHF等,本文对这些关键技术和理论进行总结。
强化学习
我们都知道近几年人工智能在应用领域中表现很好,例如AlphaGo 在围棋比赛中击败顶尖人类棋手,自动驾驶技术可靠性越来越高、逐渐走向成熟,这些成果都是基于一项经典而又复杂的技术—强化学习,因此本节介绍强化学习的基本概念,并举例说明on-policy和off-policy的差别。
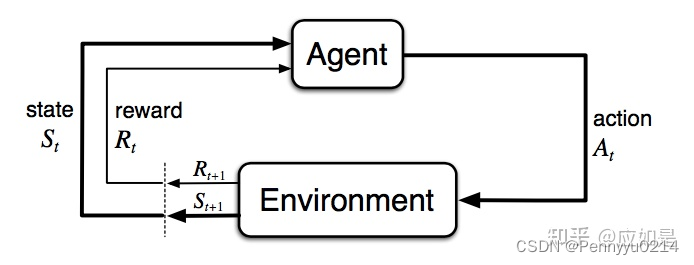
首先解释强化学习的概念,假设未知环境(unknown environment)中有一个智能体(agent),该智能体与环境互动所产生的不同决策可获得不同奖励(reward)。智能体以最大化累计奖励(maximize cumulative rewards)为目标采取行动/动作(action)。
其中智能体通常情况下也是一个模型的形态,智能体有一个状态集合S,包含了很多不同的状态s;同时也有一组动作库A包含不同的动作a,智能体通过动作改变状态。智能体的下一步动作由转移概率P决定,同时每一个特定环境下的动作都会生成一个奖励,由奖励函数R触发,从而干预智能体的决策。智能体策略π(s)指导智能体采取更优行动以最大化收益,因而每个状态都对应一个价值函数V,代表智能体采取当前决策时能够在未来获得的收益期望值。换句话说,当前状态和策略的价值函数能够从预期的视角衡量其优劣。
RL的常见方法:①动态规划,应用于模型已知的情况;②蒙特卡洛方法,从经验中学习,即观察完整样本回报来推测期望值,并改进策略;③TD-Learning方法,也是基于经验学习,但无需使用完整回报状态。
本文介绍过程中,将时刻t的状态记为
S
t
S_t
St,行为记为
A
t
A_t
At,奖励记为
R
t
R_t
Rt.
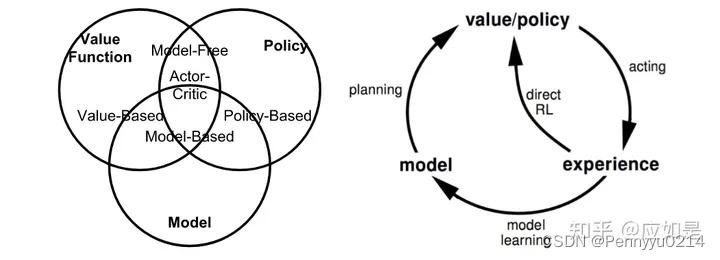
分类:强化学习按不同标准分为很多种,按模型的工作方式可分为模型已知和模型未知两种,模型已知即基于模型的学习,是指在获知全部信息时,可以通过动态规划等方法寻找最佳策略;模型未知即无模型的强化学习,是基于部分信息做规划;按策略类型包括目标策略(On-policy)和行为策略(Off-policy),二者介绍如下:
- On-policy:
特点:生成样本的policy(target)跟网络更新参数时使用的policy(value)相同。例如Sarsa;
问题:生成和更新时用的policy相同,可能无法收敛到最优解,解决方法:epsilon-greedy. - Off-policy:
特点:生成样本的policy(value function)跟网络更新参数时使用的policy(value function)不同。例如Q-Learning;
问题:更新缓慢,但确保了行为覆盖完全。
现有方法
Q-Learning
首先介绍马尔科夫决策过程:
马尔可夫决策过程(MDP)是解决几乎所有强化学习问题的通用范式。MDP中所有的状态都具有“马尔可夫”性,即未来仅依赖于当前状态,而与历史状态无关,形式如下:
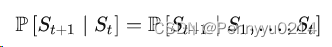
图说明如下:
一个MDP包含五元组的数据结构:
- 状态集合S;
- 动作集合A;
- 状态转移概率:P是给定状态和动作组合下一时刻状态的条件概率: P ( s t + 1 = s ’ ∣ s t = s , a t = a ) P(s_{t+1}=s’|s_t=s, a_t=a) P(st+1=s’∣st=s,at=a);
- 奖励函数:R是状态和动作组合的奖励期望: R ( s t = s , a t = a ) = E [ r t ∣ s t = s , a t = a ] R(s_t=s, a_t=a)=E[r_t|s_t=s, a_t=a] R(st=s,at=a)=E[rt∣st=s,at=a];
- 衰减因子γ.
其次介绍贝尔曼方程:
贝尔曼方程是强化学习的一种价值函数算法,其计算时使用未来放缩后的奖励累加作为当前的价值函数,公式如下:
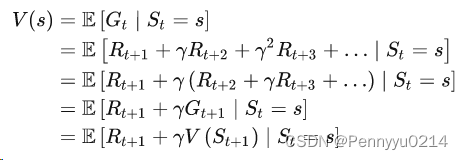
贝尔曼方程的最优方程:即产生最大价值的方程,其形式为:
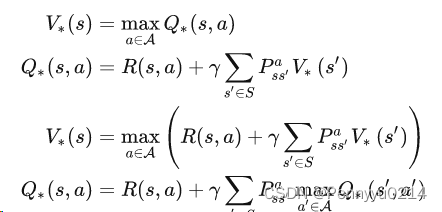
搜索策略:一个执行之后能得到最大回报的策略。
Q-Learning是强化学习的一种算法,基于值(values-based)做出决策,通过反馈一个表格的形式。表格的行代表状态,列代表可能产生的动作,表格中的值代表行对应的状态下执行列的动作时,所能获取的最大期望奖励。

总结Q-Learning的执行流程如下:
- 初始化Q-table;
- 选择当前状态的最优动作(或按概率随机);
- 执行所选动作,获得新估计值Q;
- 更新Q-table.
Sarsa
Sarsa则使用next_obs时会采取的动作收益更新当前收益,方法是随机采样next动作表(Q-Learning中是选取下一步的最大收益),期间设置epsilon决定随机采样或最大化。Sarsa更新策略如下:
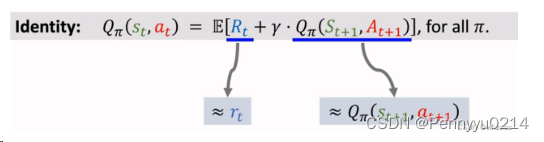
用伪代码来直观反映Q-Learning和Sarsa的区别:

由上图能够看出,Q-Learning采用最优策略更新当前价值,即对应着公式里的max函数,而Sarsa则依赖(实际执行时可以随机选或循序选)。
















 63
63











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









