







 本文介绍了RNN的产生背景,详细阐述了RNN的模型架构和计算过程,揭示了其在处理不同长度输入时的优势。同时,文章指出RNN存在的信息衰减问题,并提及LSTM和GRU等改进模型。通过对RNN的深入探讨,为后续的注意力机制打下基础。
本文介绍了RNN的产生背景,详细阐述了RNN的模型架构和计算过程,揭示了其在处理不同长度输入时的优势。同时,文章指出RNN存在的信息衰减问题,并提及LSTM和GRU等改进模型。通过对RNN的深入探讨,为后续的注意力机制打下基础。
栏目介绍
最近在搭司法的一个模型,现在在处理数据的阶段,后面在和师兄讨论的时候说应该要用attention,毕竟司法这一块对解释性的要求还是比较高的。虽然之前有所了解,但是总感觉没有能拿到attention的本质,并且多少有点忘了,所以从头开始这个栏目,相当于在给自己做一个笔记。
RNN
出现背景
RNN(Recurrent Neural Network)循环神经网络是一类可以处理不同长度输入的一种深度学习模型,产出的压力主要在于NLP任务,比如翻译任务。就中英翻译来说,我们拿到的英文可能是任意长度的,短到一个人名,长到阅读里的长难句翻译。这种数据在当时有很多人通过截断来做,但显然这会对输入内容有所牺牲,不是理想的解决方式,于是RNN就背负着希望出现了。
模型架构
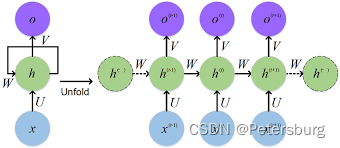
通过这张图可以很容易地说明情况,首先整个RNN的代码的参数就在h这一块(箭头左侧),x是输入,o是输出。具体而言,箭头左边绿色这一块可以仅仅只是两个矩阵W和U。我们现在来说整个数据是如何通过这个模型过了一遍。
我们不妨假设我们的输入 x = Where have you been recently? 是一个有五个单词的句子,首先我们当然会用一些方法把这些单词向量化,这里我们不详述,默认已经把这句话的五个单词分别转化成的五个定长的向量
v 1 , v 2 , v 3 , v 4 , v 5 v_1, v_2, v_3, v_4, v_5 v1,v2,v3,v4,v5
他们每一个都是对应位置英文单词的向量,比如 v 1 v_1 v1对应的是where, v 3 v_3 v3对应的是you。那么现在我们的输入从五个人容易读的英文单词,变成了5个计算机容易处理的定长向量。下面我们描述RNN怎么处理这五个向量。
模型计算
第一步
随机初始化一个隐层向量 h 1 h_1 h1,计算向量 W ∗ h 1 W * h_1 W∗h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









