







教程文档
XTuner 一个大语言模型&多模态模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
🤓 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
🍃 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡✅,colab✅
一、LLM微调
XTuner 的运行原理:
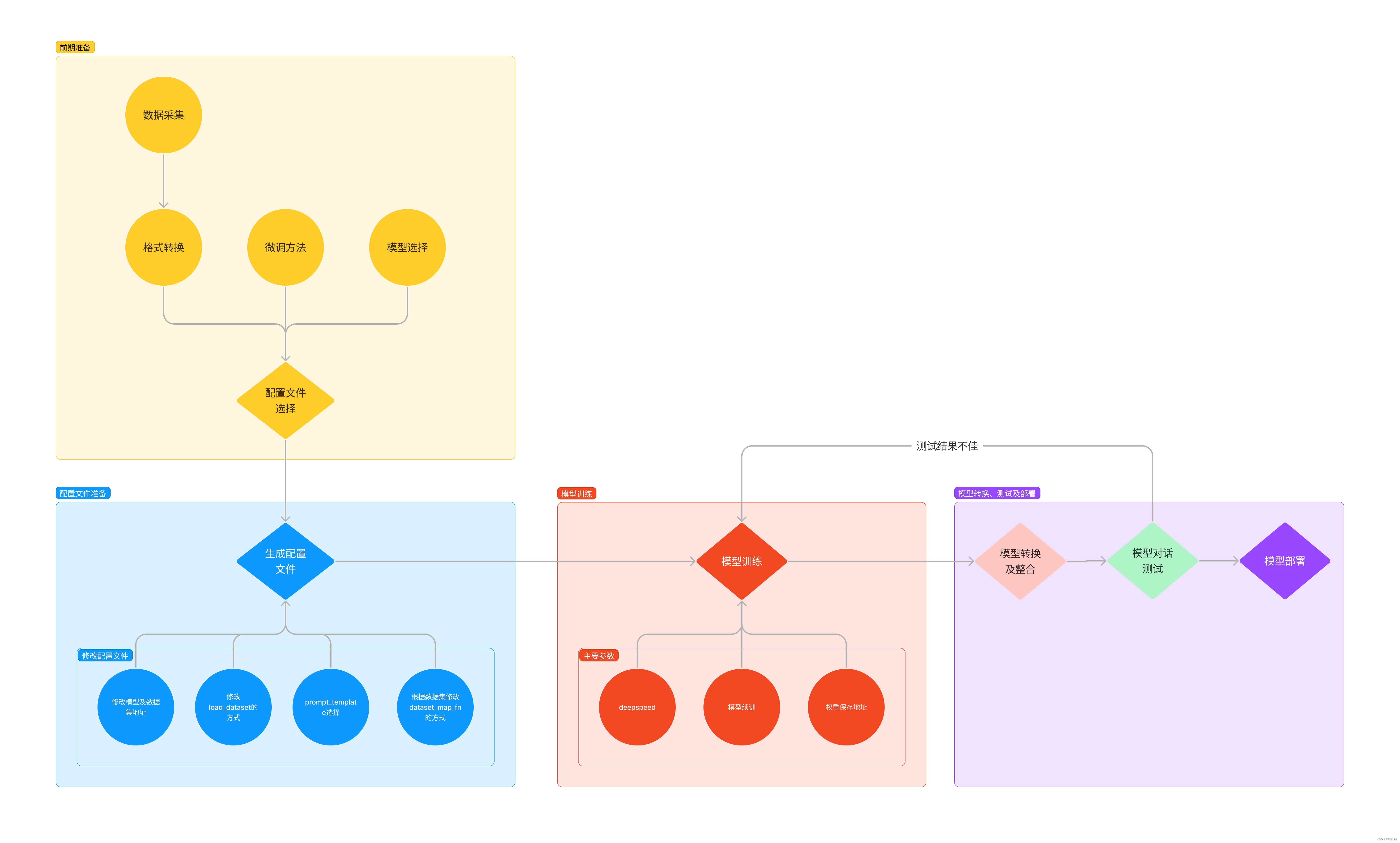
参考文档
1. 环境配置
2. 数据准备
生成简单数据,单条训练数据格式如下:

3. 模型准备
通过软链接连接模型
4. 配置文件
配置文件(config),其实是一种用于定义和控制模型训练和测试过程中各个方面的参数和设置的工具。准备好的配置文件只要运行起来就代表着模型就开始训练或者微调了。
查看全部可用配置文件xtuner list-cfg
internlm2_1_8b相关配置文件 xtuner list-cfg -p internlm2_1_8b:

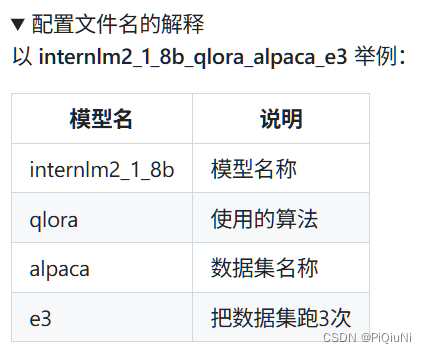
我们的微调与类似,拷贝其配置文件:
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
修改配置文件
配置文件介绍
假如我们真的打开配置文件后,我们可以看到整体的配置文件分为五部分:
- PART 1 Settings:涵盖了模型基本设置,如预训练模型的选择、数据集信息和训练过程中的一些基本参数(如批大小、学习率等)。
- PART 2 Model & Tokenizer:指定了用于训练的模型和分词器的具体类型及其配置,包括预训练模型的路径和是否启用特定功能(如可变长度注意力),这是模型训练的核心组成部分。
- PART 3 Dataset & Dataloader:描述了数据处理的细节,包括如何加载数据集、预处理步骤、批处理大小等,确保了模型能够接收到正确格式和质量的数据。
- PART 4 Scheduler & Optimizer:配置了优化过程中的关键参数,如学习率调度策略和优化器的选择,这些是影响模型训练效果和速度的重要因素。
- PART 5 Runtime:定义了训练过程中的额外设置,如日志记录、模型保存策略和自定义钩子等,以支持训练流程的监控、调试和结果的保存。
修改内容:
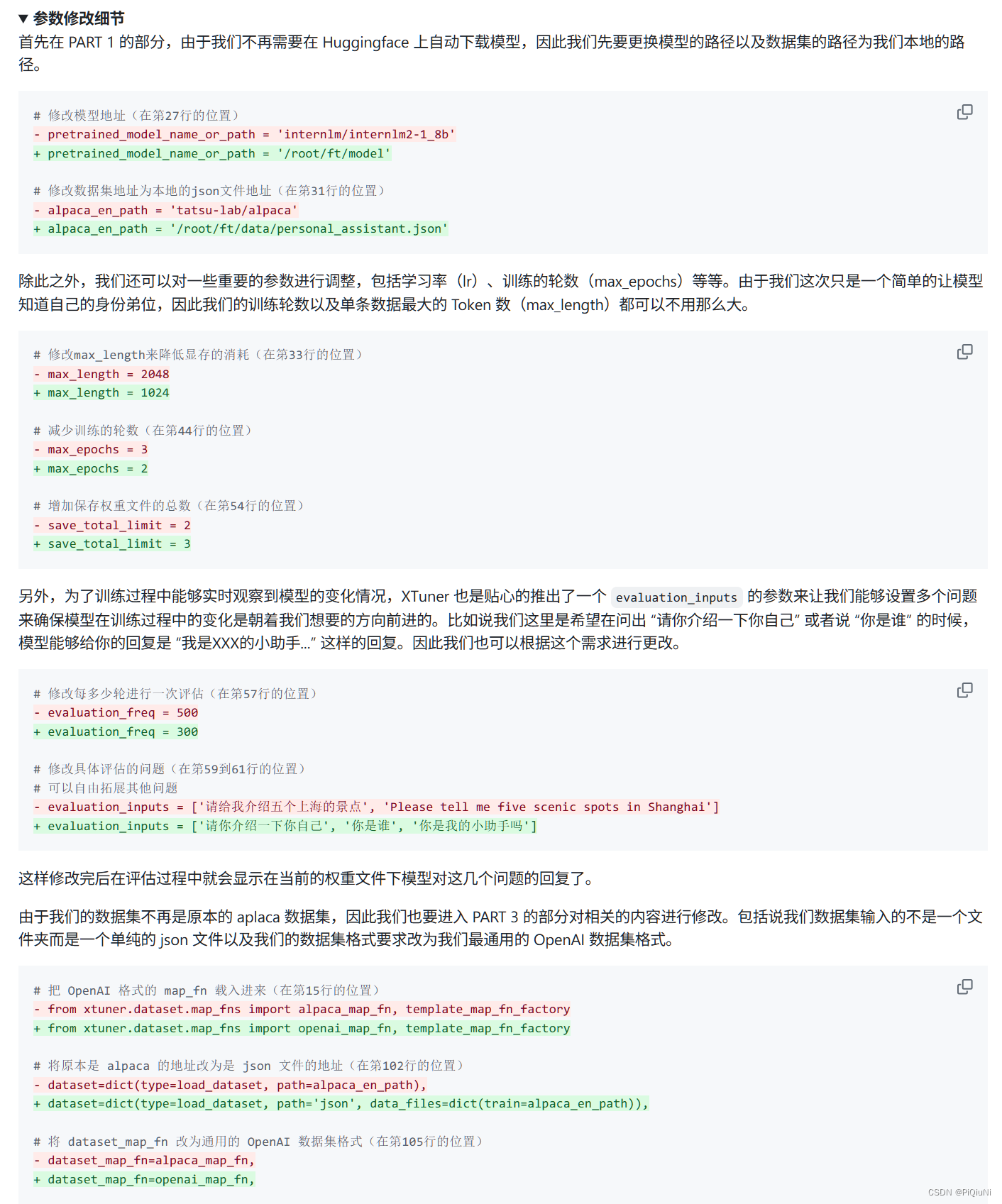
5. 直接训练
# 指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train

6. 使用 deepspeed 来加速训练
结合 XTuner 内置的 deepspeed 来加速整体的训练过程,共有三种不同的 deepspeed 类型可进行选择,分别是 deepspeed_zero1, deepspeed_zero2 和 deepspeed_zero3
DeepSpeed是一个深度学习优化库,由微软开发,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed特别适用于需要巨大计算资源的大型模型和数据集。
在DeepSpeed中,zero 代表“ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括:
- deepspeed_zero1:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。
- deepspeed_zero2:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。
- deepspeed_zero3:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练。
选择哪种deepspeed类型主要取决于你的具体需求,包括模型的大小、可用的硬件资源(特别是GPU内存)以及训练的效率需求。一般来说:
如果你的模型较小,或者内存资源充足,可能不需要使用最高级别的优化。
如果你正在尝试训练非常大的模型,或者你的硬件资源有限,使用deepspeed_zero2或deepspeed_zero3可能更合适,因为它们可以显著降低内存占用,允许更大模型的训练。
选择时也要考虑到实现的复杂性和运行时的开销,更高级的优化可能需要更复杂的设置,并可能增加一些计算开销。
# 使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
训练过程:

简单重复数据集训练可能导致模型过拟合:
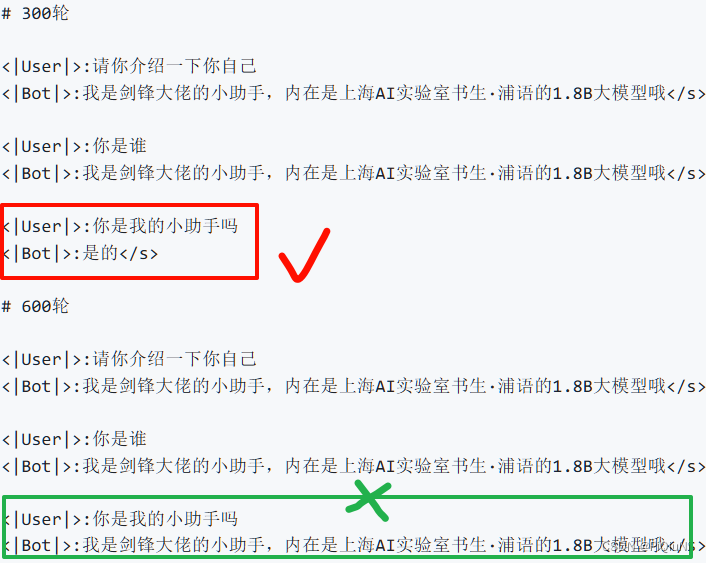
假如我们想要解决这个问题,其实可以通过以下两个方式解决:
- 少保存权重文件的间隔并增加权重文件保存的上限:这个方法实际上就是通过降低间隔结合评估问题的结果,从而找到最优的权重文。我们可以每隔100个批次来看什么时候模型已经学到了这部分知识但是还保留着基本的常识,什么时候已经过拟合严重只会说一句话了。但是由于再配置文件有设置权重文件保存数量的上限,因此同时将这个上限加大也是非常必要的。
- 增加常规的对话数据集从而稀释原本数据的占比:这个方法其实就是希望我们正常用对话数据集做指令微调的同时还加上一部分的数据集来让模型既能够学到正常对话,但是在遇到特定问题时进行特殊化处理。比如说我在一万条正常的对话数据里混入两千条和小助手相关的数据集,这样模型同样可以在不丢失对话能力的前提下学到剑锋大佬的小助手这句话。这种其实是比较常见的处理方式,大家可以自己动手尝试实践一下。
二、 模型转换、整合、测试及部署
1. 模型转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,那么我们可以通过以下指令来实现一键转换。
xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
2. 模型整合
LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
3. 对话测试
#与模型进行对话
xtuner chat /root/ft/final_model --prompt-template internlm2_chat

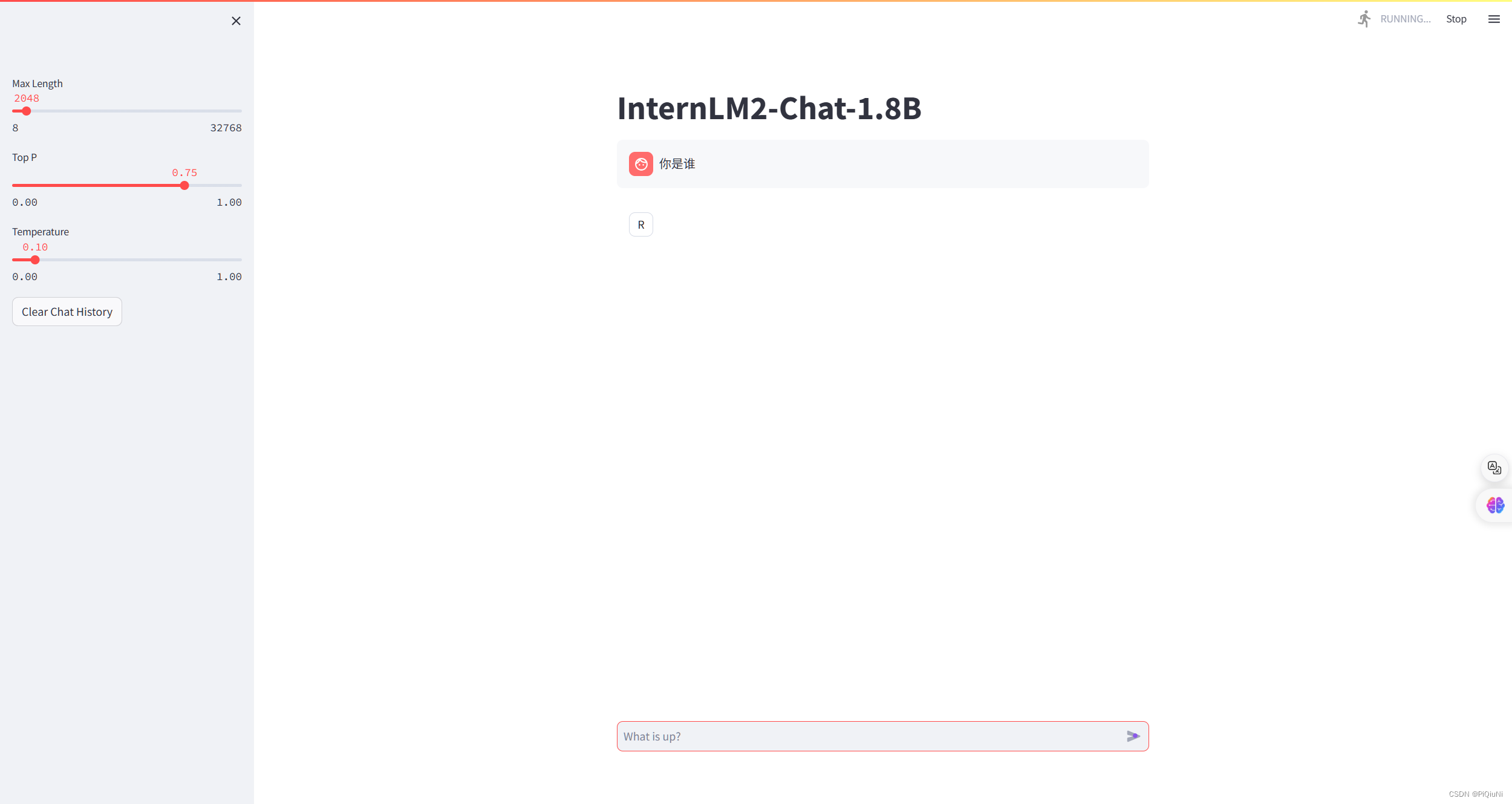
4. Web Domo















 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









