







朴素贝叶斯
案例
按照以往,我们首先通过一个例子来感受一下,来看看它到底有多朴素。大学上概率论的时候老师大都举过这样一个例子:
抽奖盒里有三张券,只有一张中大奖 ,你抽了一张还没刮,小明抽了一张,刮开没中。这时候剩下最后一张中奖的概率是多少?他要跟你换你换吗?
从直觉上来讲,你中奖的概率是1/3,你最先抽了一张,不管咋操作,中奖的概率应该都是1/3。这时候小明排除掉了一张没中奖的,剩下两张必有一张中奖,所以概率是1/2。是这样吗?
这时候需要引申出贝叶斯了,P(A|B) 表示在B发生的情况下A发生的概率。
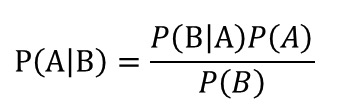
我们假设A表示你手里目前这张是中奖的,B表示小明刮出来的那张是没中奖的,
P(B|A)表示在A发生的情况下B发生的概率,代入题目中也就是如果你手里这张是中奖的,那小明刮出来那张没中奖的概率,很显然这是必然事件,因为只有一张是中奖的,你都中奖了还要别人怎么中?所以P(B|A)=1
P(A)表示你手里目前这张是中奖的概率,在计算P(A)时因为没有给出前提条件,所以P(A)=1/3,也就是三张券,你手里中奖的概率是1/3。
P(B)表示小明刮出来那张是没中奖的概率,题目中已经给出前提条件小明刮出来的是没中奖的,所以概率P(B)=1.
那么将数代入式子:P(A|B) = [P(B|A)×P(A)] / P(B) = (1 × 1/3)/ 1 = 1/3,也就是说在小明刮出来一张没中奖的前提下,你手里这张中奖的概率是1/3,小明手里剩余那张是2/3。 What?? 是不是有点懵?
(这个理解起来有点费劲,其实本质是你先抽中奖的概率是1/3. 它并不会因为小明扔掉一张没中奖的,你中奖的概率就会变成1/2。因为并不是小明先抽一张排除掉那张不中奖的,他是根据你的选择,去剩下的当中再把那张不中奖的扔掉。也就说小明的排除是一种无意义的行为,因为你抽在先,他排除在后,而且你也知道剩下的两张中必然有至少一张是不中奖的)
算法原理
啰里吧嗦半天,大致能够体会到贝叶斯有多朴素了吧。
机器学习算法中我们通常在这种情况下使用朴素贝叶斯分类器。它就是一个对所有可能性求概率的模型,最后输出结果中哪种可能性高就输出哪种。
举个栗子:一个非常炎热的夏天晚上,走在校园里面,伸手不见五指,这个时候迎面走来一个人,太远看不清楚ta的性别,但我们知道ta的特征是“短裤+短发”,而且事先有一些学生的调查样本,需要你根据某些特性大致判断Ta的性别,请问你应该怎么分类?
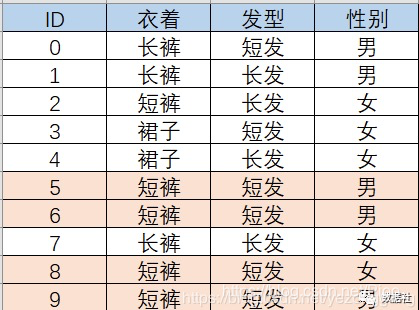
这样分析,我们首先计算求得P(boy|短裤短发)和P(girl|短裤短发)然后比较两者大小,作为依据判定性别,也就是我们根据以往数据中穿着短裤短发的人中boy和girl的条件概率作为依据,来判断当我们看见“短裤短发”人的性别,在这个例子中我们很明显把ta判定是个boy,核心思想就是这么简单:

如何处理连续值
例子中使用的都是离散值,那么对于连续值该怎么处理呢?我们可以假设这个特征服从正态分布,通过样本集计算出特征对应每一个分类的均值和方差,再根据比如密度函数,计算出新数据与均值的距离,从而获得一个概率值。
算法的优缺点
优点
-
逻辑清晰简单、易于实现,适合大规模数据。 根据算法的原理,只要我们把样本中所有属性相关的概率值都计算出来,然后分门别类地存储好,就获得了我们的朴素贝叶斯模型。
-
运算开销小。 根据上一条我们可以得知,所有预测需要用到的概率都已经准备好,当新数据来了之后,只需要获取对应的概率值,并进行简单的运算就能获得结果。
-
对于噪声点和无关属性比较健壮。 噪声点和无关属性对算法影响较小,在很多邮件服务中仍然一直沿用这个方法进行垃圾邮件过滤。
-
预测过程快。 由于所有需要用到的属性相关概率都已经计算出来了,在新数据到来需要预测的时候,只需要把对应的一些概率值取出来进行计算就可以获得结果,所用到的时间和空间都很小。
缺点
由于做了“各个属性之间是独立的”这个假设,同样该算法也暴露了缺点。因为在实际应用中,属性之间完全独立的情况是很少出现的,如果属性相关度较大,那么分类的效果就会变差。所以在具体应用的时候要好好考虑特征之间的相互独立性,再决定是否要使用该算法,比如,维度太多的数据可能就不太适合,因为在维度很多的情况下,不同的维度之间越有可能存在联合的情况,而不是相互独立的,那么模型的效果就会变差。
Python
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB #高斯分布型的朴素贝叶斯
import numpy as np
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices=np.random.permutation(len(iris_x))
iris_x_train=iris_x[indices[:-10]]
iris_y_train=iris_y[indices[:-10]]
iris_x_test=iris_x[indices[-10:]]
iris_y_test=iris_y[indices[-10:]]
clf = GaussianNB() #构造朴素贝叶斯分类器
clf.fit(iris_x_train,iris_y_train) #拟合
#result=clf.predict()
iris_y_predict=clf.predict(iris_x_test)
#调用该对象的打分方法,计算出准确率
score=clf.score(iris_x_test,iris_y_test,sample_weight=None)
print('iris_y_predict = ')
print(iris_y_predict)
print('iris_y_test = ')
print(iris_y_test)
print('Accuracy:',score)
"""
iris_y_predict =
[1 2 1 0 0 0 2 1 2 0]
iris_y_test =
[1 1 1 0 0 0 2 1 2 0]
Accuracy: 0.9
"""
参考:
https://cloud.tencent.com/developer/article/1631931














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









