




目录
本文是对DnLUT技术的代码解读,原文解读请看DnLUT。
原文概要
DnLUT通过PCM模块和L型卷积,有效提升以往基于LUT方法降低色噪声的能力,用最小的存储量得到了同样的感受野范围,主要是2个创新点:
- 提出了一个PCM模块(Pairwise Channel Mixer),使得其转换后LUT既不会维度太大,又可以满足通道和空间的交互性。
- 提出了L型卷积(Rotation Non-overlapping Kernel),减小了旋转中卷积核的overlapping,从而在相同的感受野条件下,降低了LUT尺寸。
其网络结构图如下:
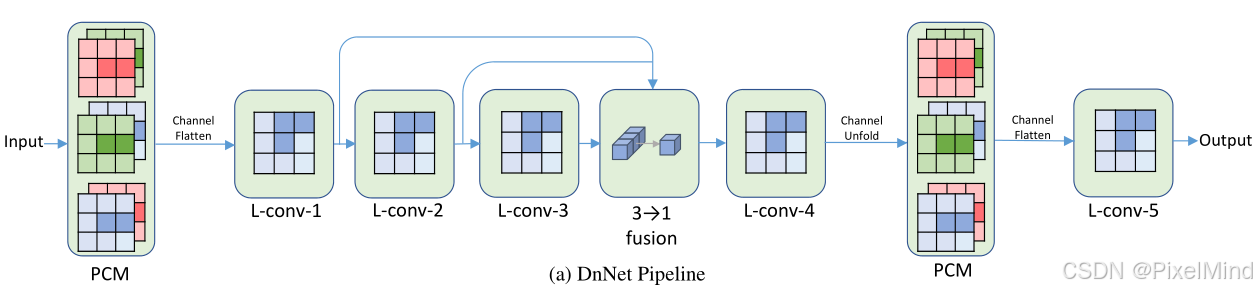
Pairwise Channel Mixer,如下图(c)所示,是空间和通道的交互,有3个4DLUT:
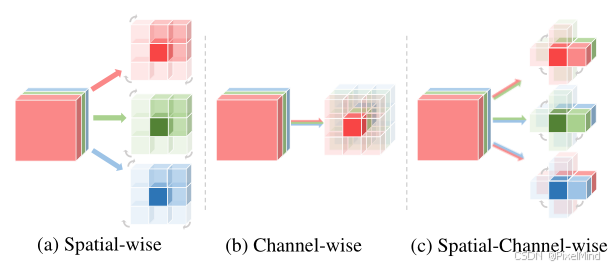
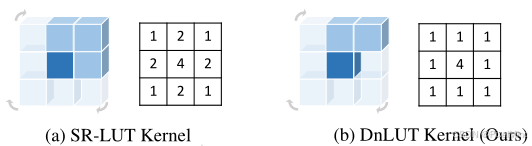
L型卷积(Rotation Non-overlapping Kernel),如下图(b)所示,L型卷积在旋转后达到跟S型卷积一样的感受野,但减小了除中心位置的overlap,减小了LUT的存储压力:
首先我们通过专栏前面文章的讲解,可以预判流程实现需要分为:训练、转表、微调以及推理,这里DnLUT作者只开源了训练的部分,但其他的部分其实跟MuLUT等论文大差不差。代码整体结构如下:
跟模型实现重点的部分在dn文件夹中,关于某个层的实现在common文件夹的network.py中。
1. 训练
首先我们观察common/option_dnlut_sidd.py,可以看到DnLUT调用的模型是SRNets。
class BaseOptions():
def __init__(self, debug=False):
self.initialized = False
self.debug = debug
def initialize(self, parser):
# experiment specifics
parser.add_argument('--model', type=str, default='SRNets')
parser.add_argument('--task', '-t', type=str, default='sr')
parser.add_argument('--scale', '-r', type=int, default=1, help="up scale factor")
parser.add_argument('--sigma', '-s', type=int, default=50, help="noise level")
parser.add_argument('--qf', '-q', type=int, default=20, help="deblocking quality factor")
parser.add_argument('--nf', type=int, default=64, help="number of filters of convolutional layers")
parser.add_argument('--stages', type=int, default=1, help="stages of MuLUT")
parser.add_argument('--modes', type=str, default='sdy', help="sampling modes to use in every stage")
parser.add_argument('--interval', type=int, default=4, help='N bit uniform sampling')
parser.add_argument('--modelRoot', type=str, default='../models')
parser.add_argument('--expDir', '-e', type=str, default='/home/styan/DNLUT/exp/mulut_gaussian_50', help="experiment folder")
parser.add_argument('--load_from_opt_file', action='store_true', default=False)
parser.add_argument('--debug', default=False, action='store_true')
self.initialized = True
return parserSRNets模型代码实现位于dn/model_dnlut.py中:
class SRNets(nn.Module):
""" A LUT-convertable SR network with configurable stages and patterns. """
def __init__(self, nf=64, scale=4, modes=['s', 'd', 'y'], stages=4, channel_mix=True):
super(SRNets, self).__init__()
if channel_mix:
self.add_module("s1_m", SRNet("Mx1", nf=nf, upscale=None))
self.add_module("s2_m", SRNet("Mx1", nf=nf, upscale=None))
self.add_module("s1_q", SRNet("Qx1", nf=nf, upscale=None))
self.add_module("s2_q", SRNet("Qx1", nf=nf, upscale=None))
self.add_module("s3_q", SRNet("Qx1", nf=nf, upscale=None))
for s in range(stages): # 2-stage
for mode in modes:
self.add_module("s{}_{}".format(str(s + 1), mode),
SRNet("{}x1".format(mode.upper()), nf=nf))
print_network(self)
def forward(self, x, stage, mode):
key = "s{}_{}".format(str(stage), mode)
# print(key)
module = getattr(self, key)
return module(x)这样可以看到,每个层使用的是SRNet结构,其实现在common/network.py中。
############### Image Super-Resolution ###############
class SRNet(nn.Module):
""" Wrapper of a generalized (spatial-wise) MuLUT block.
By specifying the unfolding patch size and pixel indices,
arbitrary sampling pattern can be implemented.
"""
def __init__(self, mode, nf=64, upscale=None, dense=True):
super(SRNet, self).__init__()
self.mode = mode
print(mode)
if 'x1' in mode:
assert upscale is None
if mode == 'Sx1':
self.model = MuLUTUnit('2x2', nf, upscale=1, dense=dense)
self.K = 2
self.S = 1
elif mode == 'SxN':
self.model = MuLUTUnit('2x2', nf, upscale=1, dense=dense)
self.K = 2
self.S = upscale
elif mode == 'Cx1':
self.model = MuLUTcUnit('1x1', nf)
self.K = 2
self.S = 1
elif mode == 'Px1':
self.model = PoolNear()
self.K = 2
self.S = 1
elif mode == 'Qx1':
self.model = MuLUTcUnit('1x1q', nf)
self.K = 2
self.S = 1
elif mode == 'Mx1':
self.model_rg = MuLUTmixUnit('2x2', nf)
self.model_gb = MuLUTmixUnit('2x2', nf)
self.model_rb = MuLUTmixUnit('2x2', nf)
self.K = 2
self.S = 1
elif mode == 'MxN':
self.model_rg = MuLUTmixUnit('2x2', nf)
self.model_gb = MuLUTmixUnit('2x2', nf)
self.model_rb = MuLUTmixUnit('2x2', nf)
self.K = 2
self.S = 1
elif mode == 'Vx1':
self.model = MuLUTUnit('1x3', nf, upscale=1, dense=dense)
self.K = 2
self.S = 1
elif mode == 'VxN':
self.model = MuLUTUnit('1x3', nf, upscale=1, dense=dense)
self.K = 2
self.S = 1
elif mode == 'TMx1':
self.model = MuLUTcUnit('1x1', nf)
self.K = 1
self.S = 1
elif mode == 'Dx1':
self.model = MuLUTUnit('2x2d', nf, upscale=1, dense=dense)
self.K = 3
self.S = 1
elif mode == 'DxN':
self.model = MuLUTUnit('2x2d', nf, upscale=upscale, dense=dense)
self.K = 3
self.S = upscale
elif mode == 'Yx1':
self.model = MuLUTUnit('1x4', nf, upscale=1, dense=dense)
self.K = 3
self.S = 1
elif mode == 'YxN':
self.model = MuLUTUnit('1x4', nf, upscale=upscale, dense=dense)
self.K = 3
self.S = upscale
elif mode == 'Ex1':
self.model = MuLUTUnit('2x2d3', nf, upscale=1, dense=dense)
self.K = 4
self.S = 1
elif mode == 'ExN':
self.model = MuLUTUnit('2x2d3', nf, upscale=upscale, dense=dense)
self.K = 4
self.S = upscale
elif mode in ['Ox1', 'Hx1']:
self.model = MuLUTUnit('1x4', nf, upscale=1, dense=dense)
self.K = 4
self.S = 1
elif mode == ['OxN', 'HxN']:
self.model = MuLUTUnit('1x4', nf, upscale=upscale, dense=dense)
self.K = 4
self.S = upscale
else:
raise AttributeError
self.P = self.K - 1
def forward(self, x):
if 'TM' in self.mode:
B, C, H, W = x.shape
x = self.model(x)
# print('down')
return x
elif 'C' in self.mode:
B, C, H, W = x.shape
x = self.model(x)
# print('down')
return x
elif 'Q' in self.mode:
B, C, H, W = x.shape
x = self.model(x)
# print('down')
return x
elif 'P' in self.mode:
B, C, H, W = x.shape
x = self.model(x)
# print('down')
return x
elif 'M' in self.mode:
B, C, H, W = x.shape
x_rg = x[:, :2, :, :]
x_gb = x[:, 1:, :, :]
# x_rb = torch.stack((x[:, 0:1, :, :], x[:, 2:, :, :]),dim=1).squeeze(2)
x_rb = torch.stack((x[:, 2:, :, :], x[:, 0:1, :, :]),dim=1).squeeze(2)
processed_tensors = []
for x, im in zip([x_rg, x_gb, x_rb], ['rg', 'gb', 'rb']):
if 'rg' in im:
x = self.model_rg(x) # B*C*L,K,K
x_rg_ = x
elif 'gb' in im:
x = self.model_gb(x) # B*C*L,K,K
x_gb_ = x
else:
x = self.model_rb(x) # B*C*L,K,K
x_rb_ = x
processed_tensors.append(x)
if x.is_cuda:
device = x.device
else:
device = torch.device('cpu')
combined_x = torch.cat(processed_tensors, dim=1).to(device)
# print('down')
return combined_x#, x_rg_, x_gb_, x_rb_
else:
B, C, H, W = x.shape
x = F.unfold(x, self.K) # B,C*K*K,L
x = x.view(B, C, self.K * self.K, (H - self.P) * (W - self.P)) # B,C,K*K,L
x = x.permute((0, 1, 3, 2)) # B,C,L,K*K
x = x.reshape(B * C * (H - self.P) * (W - self.P),
self.K, self.K) # B*C*L,K,K
x = x.unsqueeze(1) # B*C*L,l,K,K
if 'Y' in self.mode:
x = torch.cat([x[:, :, 0, 0], x[:, :, 1, 1],
x[:, :, 1, 2], x[:, :, 2, 1]], dim=1)
x = x.unsqueeze(1).unsqueeze(1)
elif 'V' in self.mode:
# print(x.shape)
x = torch.cat([x[:, :, 0, 0], x[:, :, 0, 1],
x[:, :, 1, 1]], dim=1)
# print(x.shape)
x = x.unsqueeze(1).unsqueeze(1)
elif 'H' in self.mode:
x = torch.cat([x[:, :, 0, 0], x[:, :, 2, 2],
x[:, :, 2, 3], x[:, :, 3, 2]], dim=1)
x = x.unsqueeze(1).unsqueeze(1)
elif 'O' in self.mode:
x = torch.cat([x[:, :, 0, 0], x[:, :, 2, 2],
x[:, :, 1, 3], x[:, :, 3, 1]], dim=1)
x = x.unsqueeze(1).unsqueeze(1)
x = self.model(x) # B*C*L,K,K
x = x.squeeze(1)
x = x.reshape(B, C, (H - self.P) * (W - self.P), -1) # B,C,K*K,L
x = x.permute((0, 1, 3, 2)) # B,C,K*K,L
x = x.reshape(B, -1, (H - self.P) * (W - self.P)) # B,C*K*K,L
x = F.fold(x, ((H - self.P) * self.S, (W - self.P) * self.S),
self.S, stride=self.S)
return x需要注意的有2个实现,一个是跟PCM相关的,一个是跟L型卷积相关的,分别对应的mode是Mx1以及Vx1,我们在上面关于SRNet的各种类型中定位到这具体的实现就是如下的:
elif mode == 'Mx1':
self.model_rg = MuLUTmixUnit('2x2', nf)
self.model_gb = MuLUTmixUnit('2x2', nf)
self.model_rb = MuLUTmixUnit('2x2', nf)
self.K = 2
self.S = 1
elif mode == 'MxN':
self.model_rg = MuLUTmixUnit('2x2', nf)
self.model_gb = MuLUTmixUnit('2x2', nf)
self.model_rb = MuLUTmixUnit('2x2', nf)
self.K = 2
self.S = 1
elif mode == 'Vx1':
self.model = MuLUTUnit('1x3', nf, upscale=1, dense=dense)
self.K = 2
self.S = 1然后我们再观察MuLUTmixUnit和MuLUTUnit的实现,就可以基本清楚DnLUT的各个组件了,两者实现均在common/network.py中。
class MuLUTmixUnit(nn.Module):
""" Channel-wise MuLUT block [RGB(3D) to RGB(3D)]. """
def __init__(self, mode, nf):
super(MuLUTmixUnit, self).__init__()
self.act = nn.ReLU()
if mode == '2x2':
self.conv1 = Conv(2, nf, [1,2])
else:
raise AttributeError
self.conv2 = DenseConv(nf, nf)
self.conv3 = DenseConv(nf + nf * 1, nf)
self.conv4 = DenseConv(nf + nf * 2, nf)
self.conv5 = DenseConv(nf + nf * 3, nf)
self.conv6 = Conv(nf * 5, 1, 1)
def forward(self, x):
x = self.act(self.conv1(x))
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = torch.tanh(self.conv6(x))
return x
############### MuLUT Blocks ###############
class MuLUTUnit(nn.Module):
""" Generalized (spatial-wise) MuLUT block. """
def __init__(self, mode, nf, upscale=1, out_c=1, dense=True):
super(MuLUTUnit, self).__init__()
self.act = nn.ReLU()
self.upscale = upscale
if mode == '2x2':
self.conv1 = Conv(1, nf, 2)
elif mode == '2x2d':
self.conv1 = Conv(1, nf, 2, dilation=2)
elif mode == '2x2d3':
self.conv1 = Conv(1, nf, 2, dilation=3)
elif mode == '1x4':
self.conv1 = Conv(1, nf, (1, 4))
elif mode == '1x3':
self.conv1 = Conv(1, nf, (1, 3))
elif mode == '1x1':
self.conv1 = Conv(3, nf, (1, 1))
else:
raise AttributeError
if dense:
self.conv2 = DenseConv(nf, nf)
self.conv3 = DenseConv(nf + nf * 1, nf)
self.conv4 = DenseConv(nf + nf * 2, nf)
self.conv5 = DenseConv(nf + nf * 3, nf)
if mode == '1x1':
self.conv6 = Conv(nf * 5, 3, 1)
else:
self.conv6 = Conv(nf * 5, 1 * upscale * upscale, 1)
else:
self.conv2 = ActConv(nf, nf, 1)
self.conv3 = ActConv(nf, nf, 1)
self.conv4 = ActConv(nf, nf, 1)
self.conv5 = ActConv(nf, nf, 1)
if mode == '1x1':
self.conv6 = Conv(nf, 3 * upscale * upscale, 3)
else:
self.conv6 = Conv(nf, upscale * upscale, 1)
if self.upscale > 1:
self.pixel_shuffle = nn.PixelShuffle(upscale)
def forward(self, x):
x = self.act(self.conv1(x))
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = torch.tanh(self.conv6(x))
if self.upscale > 1:
x = self.pixel_shuffle(x)
return x可以看到,其实PCM就是3个1x2,输入通道有2个的卷积,而L型卷积是kernel_size变成了一个1x3,以前是一个2x2,当然需要配合合适的input形状。
最后就是一个整体的forward过程,实现在dn/1_train_model_dnlut.py中。
mode_pad_dict = {"s": 1, "d": 2, "y": 2, "e": 3, "h": 3, "o": 3, 'm': 1, 'v': 1}
def mulut_predict(model_G, x, phase="train", opt=None):
modes, stages = opt.modes, opt.stages
pred = 0
## Pair-wise Mixer stage 1
for r in [0, 1, 2, 3]:
tmp = round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, 1, 0, 0), mode='replicate'), stage=1, mode='m'), (4 - r) % 4, [2, 3]) * 127)
pred += tmp
avg_factor, bias, norm = 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
# L-conv Stage 1
pred = 0
for mode in modes:
pad = mode_pad_dict[mode]
for r in [0, 1, 2, 3]:
pred += round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, pad, 0, pad), mode='replicate'), stage=1, mode=mode), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = len(modes) * 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
x1 = x
# L-conv Stage 2
pred = 0
for mode in modes:
pad = mode_pad_dict[mode]
for r in [0, 1, 2, 3]:
pred += round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, pad, 0, pad), mode='replicate'), stage=2, mode=mode), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = len(modes) * 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
x2 = x
# L-conv Stage 3
pred = 0
for mode in modes:
pad = mode_pad_dict[mode]
for r in [0, 1, 2, 3]:
pred += round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, pad, 0, pad), mode='replicate'), stage=3, mode=mode), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = len(modes) * 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
x3 = x
# concat
x_r = torch.cat([x1[:, 0:1], x2[:, 0:1], x3[:, 0:1]], dim=1).to('cuda')
x_g = torch.cat([x1[:, 1:2], x2[:, 1:2], x3[:, 1:2]], dim=1).to('cuda')
x_b = torch.cat([x1[:, 2:], x2[:, 2:], x3[:, 2:]], dim=1).to('cuda')
# R: 3 -> 1
r = 0
pred = round_func(torch.rot90(model_G(F.pad(torch.rot90(x_r, r, [
2, 3]), (0, 0, 0, 0), mode='replicate'), stage=1, mode='q'), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = 1, 127, 255.0
x_r = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
# G: 3 -> 1
r = 0
pred = round_func(torch.rot90(model_G(F.pad(torch.rot90(x_g, r, [
2, 3]), (0, 0, 0, 0), mode='replicate'), stage=1, mode='q'), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = 1, 127, 255.0
x_g = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
# B: 3 -> 1
r = 0
pred = round_func(torch.rot90(model_G(F.pad(torch.rot90(x_b, r, [
2, 3]), (0, 0, 0, 0), mode='replicate'), stage=1, mode='q'), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = 1, 127, 255.0
x_b = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
x = torch.cat([x_r, x_g, x_b], dim=1).to('cuda')
# L-conv Stage 4
pred = 0
for mode in modes:
pad = mode_pad_dict[mode]
for r in [0, 1, 2, 3]:
pred += round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, pad, 0, pad), mode='replicate'), stage=4, mode=mode), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = len(modes) * 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
# Pair-wise Mixer stage 2
pred = 0
for r in [0, 1, 2, 3]:
tmp = round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, 1, 0, 0), mode='replicate'), stage=2, mode='m'), (4 - r) % 4, [2, 3]) * 127)
# print(tmp.shape, r)
pred += tmp
avg_factor, bias, norm = 4, 127, 255.0
x = round_func(torch.clamp((pred / avg_factor) + bias, 0, 255)) / norm
# L-conv Stage 5
pred = 0
for mode in modes:
pad = mode_pad_dict[mode]
for r in [0, 1, 2, 3]:
pred += round_func(torch.rot90(model_G(F.pad(torch.rot90(x, r, [
2, 3]), (0, pad, 0, pad), mode='replicate'), stage=5, mode=mode), (4 - r) % 4, [2, 3]) * 127)
avg_factor, bias, norm = len(modes), 0, 1
x = round_func((pred / avg_factor) + bias)
if phase == "train":
x = x / 255.0
return x这里的计算过程跟我们前面讲解的论文过程是一致的,每个计算的过程是通过调用我们前面讲到的SRNets的forward实现的,通过输入不同的stage和不同的mode(比如说mode='m'调用的是PCM即MuLUTmixUnit层,L型卷积通过查看options发现其调用就是V型卷积实现,即MuLUTUnit搭配mode=1x3)得到不同层的输出,中间当然需要搭配旋转和量化clip,最后完成输出。
以上针对于DnLUT的训练代码实现的部分讲解完毕,如果有不清楚的问题欢迎大家提出,关于转表和微调测试的部分大家可以自己尝试实现,原理逻辑是跟前面的文章一致的。

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









