






特征工程预处理
1. 特征预处理定义
通过⼀些转换函数将特征数据转换成更加适合算法模型的特征数据过程
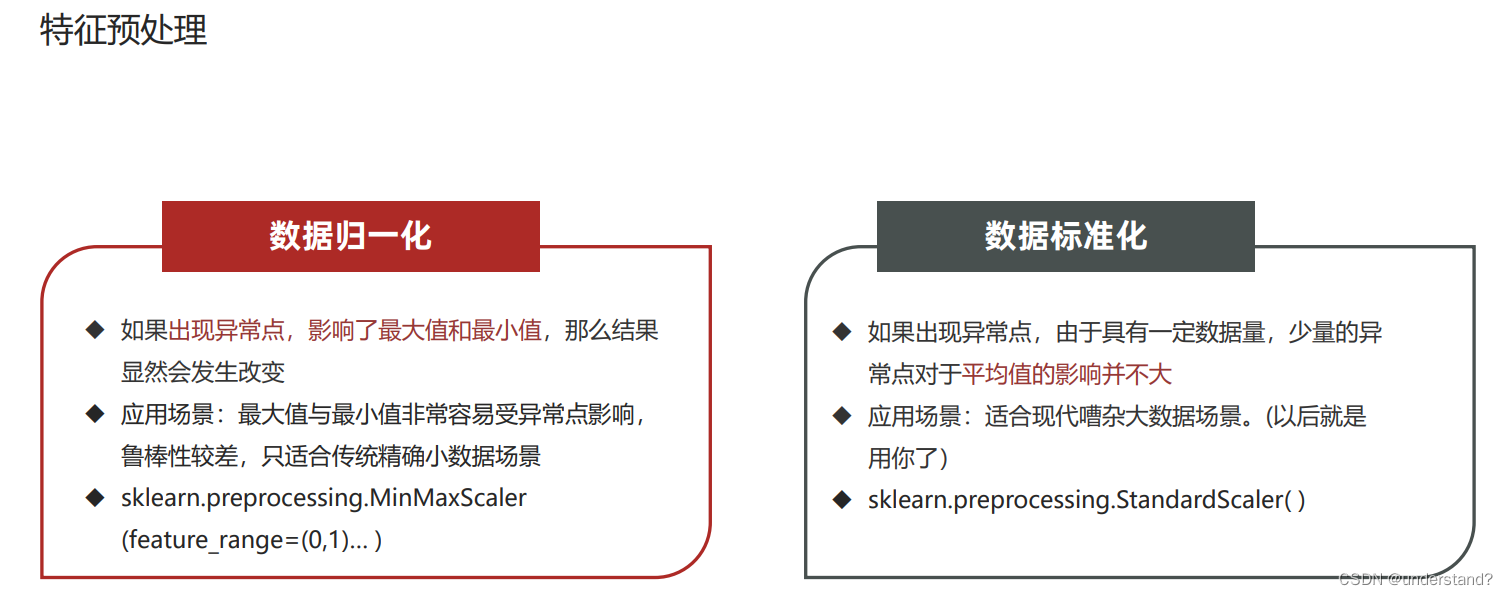
归一化标准化目的:特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响 (支配)目标结果,使得一些模型(算法)无法学习到其它的特征。
2.归一化
归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
数据归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之 间
公式总结如下:
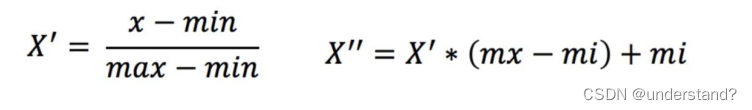
首先需要下载sklearn包
数据归一化API代码实现如下:
from sklearn.preprocessing import StandardScaler,MinMaxScaler
#准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
def dm01_StandardScaler(data): #标准化
transformer = StandardScaler() #初始标准化对象
data = transformer.fit_transform(data) #特征转换
print(data)
dm01_StandardScaler(data)结果如下:

3.标准化
数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
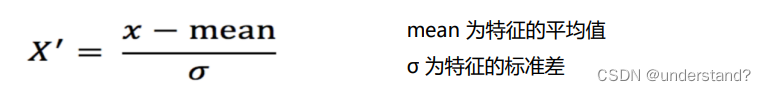
数据标准化API:
from sklearn.preprocessing import StandardScaler,MinMaxScaler
#准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
def dm02_MinMaxScaler(data): #归一化
transformer = MinMaxScaler()
data = transformer.fit_transform(data)
print(data)
dm02_MinMaxScaler(data)结果如下:

4.总结
归一法:注意最⼤值最⼩值是变化的,另外,最⼤值与最⼩值⾮常容易受异常点影响,所以这种⽅法鲁棒性较差,只适合传统精 确⼩数据场景。
标准化:在已有样本⾜够多的情况下⽐较稳定,适合现代嘈杂⼤数据场景。
鸢尾花识别案例
1.利用KNN算法对鸢尾花分类 -加载鸢尾花数据集
代码如下:
from sklearn.datasets import load_iris
iris_data =load_iris()
#加载数据
def dmo1_irisdata_jiazai(data):
print(f'data-->\n{data}')
dmo1_irisdata_jiazai(iris_data)结果:

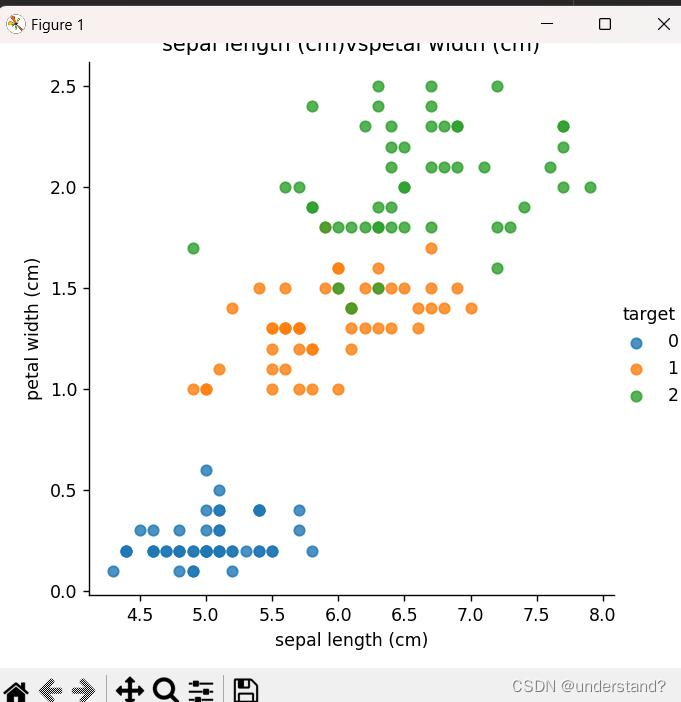
2.利用KNN算法对鸢尾花分类 -加载鸢尾花数据集
代码如下:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
iris_data =load_iris()
#数据展示
def dmo2_irisdata_show(data):
iris_df=pd.DataFrame(iris_data['data'],columns=iris_data.feature_names)
#print(iris_df)
iris_df['target']=iris_data.target
#print(iris_df)
feature_names=list(iris_data.feature_names)
#print(feature_names)
for i in range(len(feature_names)):
for j in range(i+1,len(feature_names)):
c1=feature_names[i]
c2=feature_names[j]
sns.lmplot(x=c1,y=c2,hue='target',data=iris_df,fit_reg=False)
plt.xlabel(c1)
plt.ylabel(c2)
plt.title(f'{c1}vs{c2}')
plt.show()
dmo2_irisdata_show(iris_data)结果:
3.利用KNN算法对鸢尾花分类 - 数据集划分
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris_data =load_iris()
#分类训练测试集
def dom3_traintest_split(data):
mydataset=load_iris()
x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.3,random_state=22)
print(f'数据总数量, {len(mydataset.data)}')
print(f'训练集中的x-特征值, {len(x_train)}')
print(f'测试集中的x-特征值, {len(x_test)}')
print(y_train)
dom3_traintest_split(iris_data)结果:
4.利用KNN算法对鸢尾花分类 – 模型训练– 模型评估
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris_data =load_iris()
#模型训练和预测
def dmo4_trainpredict(data):
mydataset = load_iris()
#赋值处理
x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.2,random_state=22)
#数据标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
#测试集标准化
x_test=transfer.transform(x_test)
#模型训练
estimator=KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
#模型评估
score=estimator.score(x_test,y_test)
print(f'分数-->{score}')
print(f'模型分类类别--,{estimator.classes_}')
mydata=[[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata=transfer.transform(mydata)
mypred=estimator.predict(mydata)
print(f'预测值,{mypred}')
dmo4_trainpredict(iris_data)5.完整代码及总结
这就是一个用KNN-算法实现分类,训练,评估和预测的完整的鸢尾花案例的代码
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris_data =load_iris()
#加载数据
def dmo1_irisdata_jiazai(data):
print(f'data-->\n{data}')
#数据展示
def dmo2_irisdata_show(data):
iris_df=pd.DataFrame(iris_data['data'],columns=iris_data.feature_names)
#print(iris_df)
iris_df['target']=iris_data.target
#print(iris_df)
feature_names=list(iris_data.feature_names)
#print(feature_names)
for i in range(len(feature_names)):
for j in range(i+1,len(feature_names)):
c1=feature_names[i]
c2=feature_names[j]
sns.lmplot(x=c1,y=c2,hue='target',data=iris_df,fit_reg=False)
plt.xlabel(c1)
plt.ylabel(c2)
plt.title(f'{c1}vs{c2}')
plt.show()
#分类训练测试集
def dom3_traintest_split(data):
mydataset=load_iris()
x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.3,random_state=22)
print(f'数据总数量, {len(mydataset.data)}')
print(f'训练集中的x-特征值, {len(x_train)}')
print(f'测试集中的x-特征值, {len(x_test)}')
print(y_train)
#模型训练和预测
def dmo4_trainpredict(data):
mydataset = load_iris()
#赋值处理
x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.2,random_state=22)
#数据标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
#测试集标准化
x_test=transfer.transform(x_test)
#模型训练
estimator=KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
#模型评估
score=estimator.score(x_test,y_test)
print(f'分数-->{score}')
print(f'模型分类类别--,{estimator.classes_}')
mydata=[[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata=transfer.transform(mydata)
mypred=estimator.predict(mydata)
print(f'预测值,{mypred}')
if __name__ == '__main__':
dmo2_irisdata_show(iris_data)这里还有大致步骤
 谢谢你的阅读!
谢谢你的阅读!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









