







诸神缄默不语-个人CSDN博文目录
cs224w(图机器学习)2021冬季课程学习笔记集合
文章目录
YouTube 视频观看地址1 视频观看地址2 视频观看地址3
本章的视频没有PPT中有的 Graph Manipulation in GNNs 部分。这一部分在下一章中也有,计划在下一章部分再撰写对应笔记。
本章主要内容:
本章主要介绍了GNN的设计空间design space,也就是设计一个GNN模型中的各种选择条件。(下一章继续讲这个)
本章首先讲了GNN单层的设计选择。
一层GNN包含信息转换和信息聚合两个部分。
讲了三种典型实例GCN、GraphSAGE、GAT。
GCN相当于用权重矩阵和节点度数归一化实现信息转换,用邻居节点求平均的方式实现聚合。
GraphSAGE可选用多种聚合方式来聚合邻居信息,然后聚合邻居信息和节点本身信息。在GraphSAGE中可以选用L2正则化。
GAT使用注意力机制为邻居对节点的信息影响程度加权,用线性转换后的邻居信息加权求和来实现节点嵌入的计算。注意力权重用一个可训练的模型attention mechanism计算出两节点间的attention coefficient,归一化得到权重值。此外可以应用多头机制增加鲁棒性。
在GNN层中还可以添加传统神经网络模块,如Batch Normalization、Dropout、非线性函数(激活函数)等。
然后讲了GNN多层堆叠方式。
叠太多层会导致过平滑问题。感受野可以用来解释这一问题。
对于浅GNN,可以通过增加单层GNN表现力、增加非GNN层来增加整体模型的表现力。
可以应用skip connections实现深GNN。skip connections可以让隐节点嵌入只跳一层,也可以全部跳到最后一层。
1. A General Perspective on Graph Neural Networks
- 我对design space的理解大概就是在设计模型的过程中,可以选择的各种实现方式所组成的空间。比如说可以选择怎么卷积,怎么聚合,怎么将每一层网络叠起来,用什么激活函数、用什么损失函数……用这些选项组合出模型实例,构成的空间就是design space。
在后期还有一个design space的课程。对于design space的进一步理解可以看Jure的论文 You, J., Ying, R., & Leskovec, J. (2020). Design Space for Graph Neural Networks. ArXiv, abs/2011.08843. - 对deep graph encoders、GNN、聚合邻居信息等内容不再赘述。
- 通用GNN框架
(GNN的一层就是指计算图上的一层)- 对GNN的一个网络层:要经历message(信息转换)和aggregation(信息聚合)两个环节,不同的实例应用不同的设计方式(如GCN,GraphSAGE,GAT……)
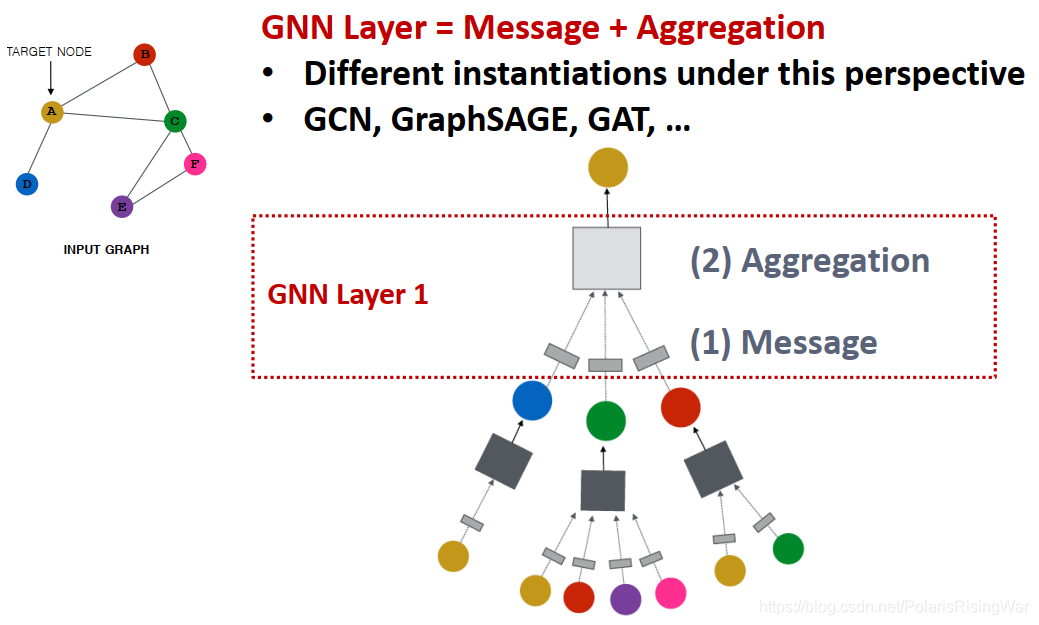 instantiation实例化(就是类似于Java编程里用类创建一个对象,将抽象的类具象化为对象……这样)
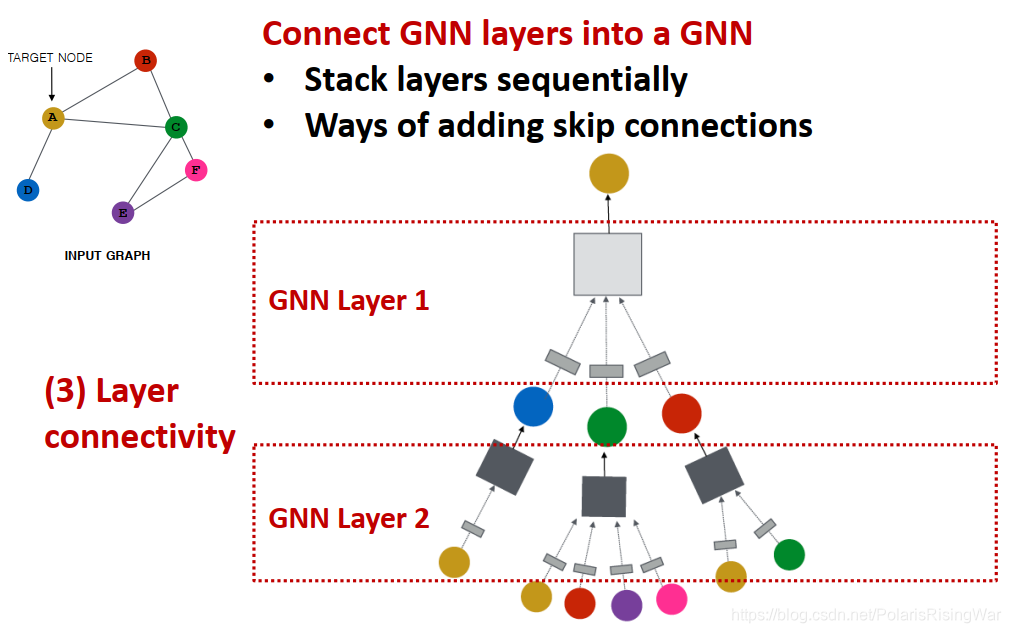
instantiation实例化(就是类似于Java编程里用类创建一个对象,将抽象的类具象化为对象……这样) - 连接GNN网络层:可以逐层有序堆叠,也可以添加skip connections
- 图增强graph sugmentation:使原始输入图和应用在GNN中的计算图不完全相同(即对原始输入进行一定处理后,再得到GNN中应用的计算图)。
图增强分为:图特征增强 / 图结构增强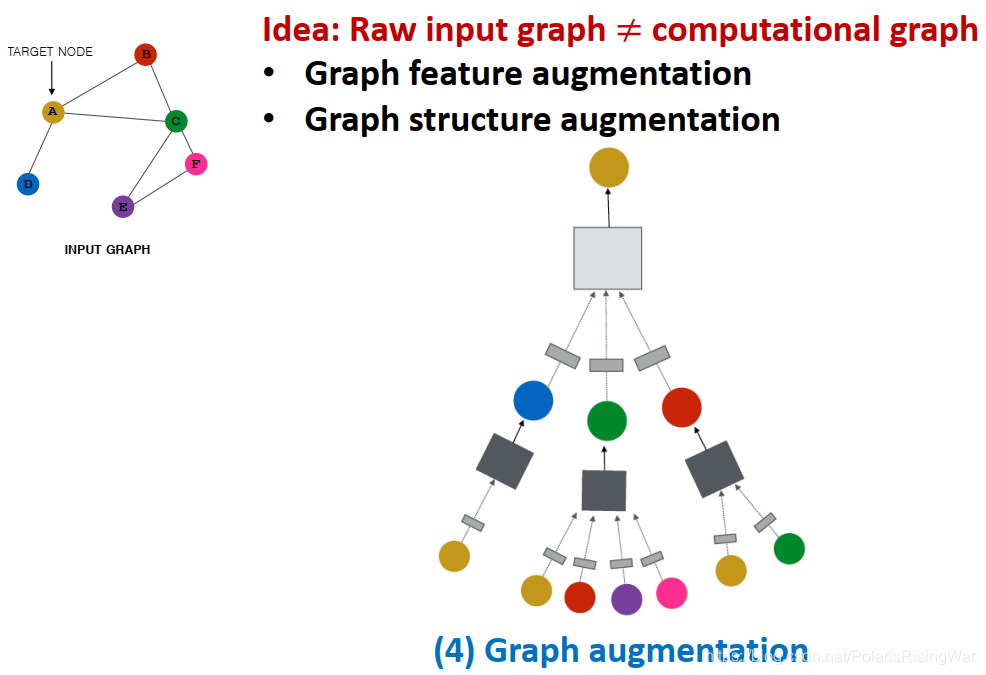
- 学习目标:有监督/无监督目标,节点/边/图级别目标
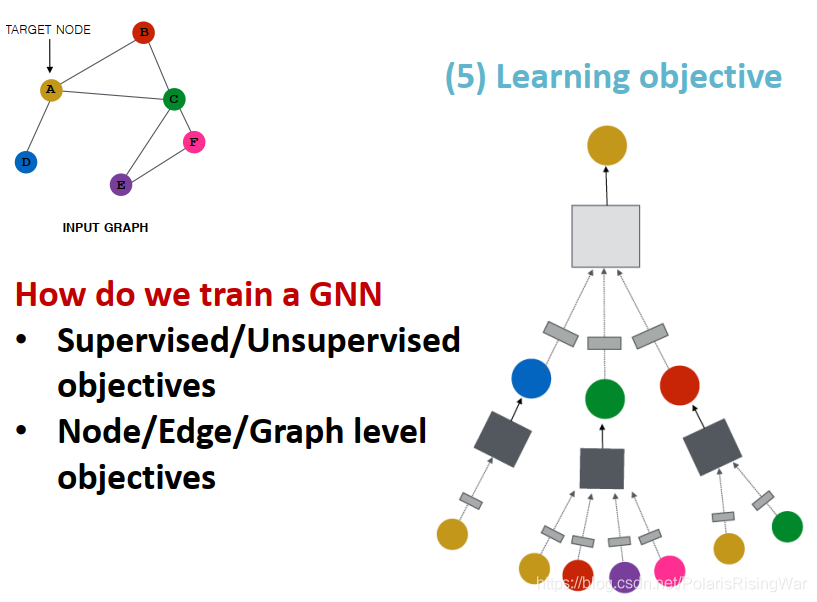
- A General GNN Framework
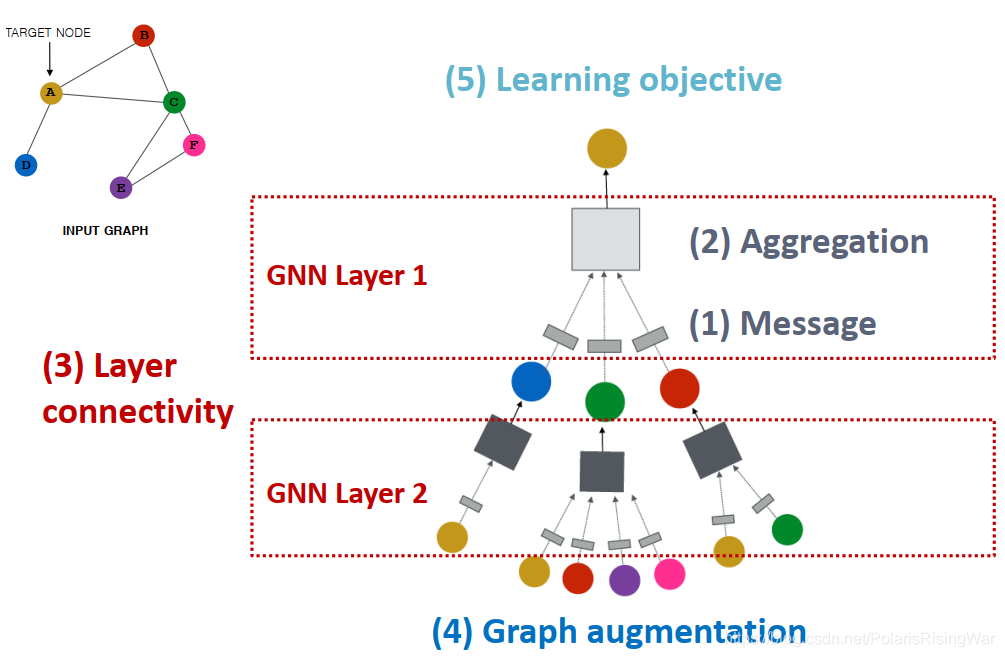
- 对GNN的一个网络层:要经历message(信息转换)和aggregation(信息聚合)两个环节,不同的实例应用不同的设计方式(如GCN,GraphSAGE,GAT……)
2. A Single Layer of GNN
- 再回顾一遍在第一节中写过的GNN单层网络的设计空间:message transformation + message aggregation
- GNN单层网络的目标是将一系列向量(上一层的自身和邻居的message)压缩到一个向量中(新的节点嵌入)
完成这个目标分成两步:信息处理,信息聚合(这里的聚合方法是需要ordering invariant的,也就是邻居节点信息聚合,聚合的顺序应当和结果无关)
- message computation:
m
u
(
l
)
=
MSG
(
l
)
(
h
u
(
l
−
1
)
)
\mathbf{m}_u^{(l)}=\text{MSG}^{(l)}(\mathbf{h}_u^{(l-1)})
mu(l)=MSG(l)(hu(l−1))
直觉:用每个节点产生一个信息,传播到其他节点上
示例:线性层 m u ( l ) = W ( l ) h u ( l − 1 ) \mathbf{m}_u^{(l)}=\mathbf{W^{(l)}}\mathbf{h}_u^{(l-1)} mu(l)=W(l)hu(l−1)(权重矩阵 W ( l ) \mathbf{W^{(l)}} W(l))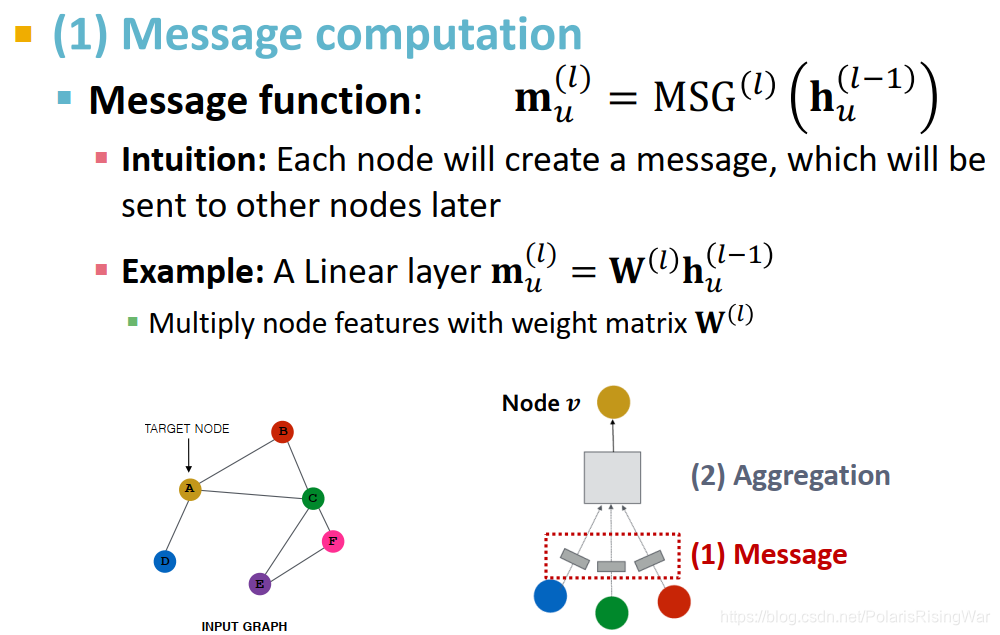
- message aggregation
直觉:对每个节点,聚合其邻居的节点信息: h v ( l ) = A G G ( l ) ( { m u ( l ) , u ∈ N ( v ) } ) \mathbf{h}_v^{(l)}=AGG^{(l)}(\{\mathbf{m}_u^{(l)},u\in N(v)\}) hv(l)=AGG(l)({mu(l),u∈N(v)})
举例:求和,求平均,求极大值
- 这种message aggregation会导致节点自身的信息丢失,因为对
h
v
(
l
)
\mathbf{h}_v^{(l)}
hv(l) 的计算不直接依赖于
h
v
(
l
−
1
)
\mathbf{h}_v^{(l-1)}
hv(l−1)。
对此问题的解决方式:在计算 h v ( l ) \mathbf{h}_v^{(l)} hv(l) 时包含 h v ( l − 1 ) \mathbf{h}_v^{(l-1)} hv(l−1):- message computation:对节点本身及其邻居应用不同的权重矩阵
m u ( l ) = W ( l ) h u ( l − 1 ) \mathbf{m}_u^{(l)}=\mathbf{W^{(l)}}\mathbf{h}_u^{(l-1)} mu(l)=W(l)hu(l−1)
m v ( l ) = B ( l ) h v ( l − 1 ) \mathbf{m}_v^{(l)}=\mathbf{B^{(l)}}\mathbf{h}_v^{(l-1)} mv(l)=B(l)hv(l−1) - message aggregation:聚合邻居信息,再将邻居信息与节点自身信息进行聚合(用concatenation或加总)
h v ( l ) = C O N C A T ( A G G ( l ) ( { m u ( l ) , u ∈ N ( v ) } ) , m v ( l ) ) \mathbf{h}_v^{(l)}=\textcolor{red}{CONCAT}(\textcolor{orange}{AGG^{(l)}(\{\mathbf{m}_u^{(l)},u\in N(v)\}}),\textcolor{red}{\mathbf{m}_v^{(l)}}) hv(l)=CONCAT(AGG(l)({mu(l),u∈N(v)}),mv(l))
- message computation:对节点本身及其邻居应用不同的权重矩阵
- GNN单层网络就是合并上述两步:对每个节点,先计算出其自身与邻居的节点信息,然后计算其邻居与本身的信息聚合。
在这两步上都可以用非线性函数(激活函数)来增加其表现力:激活函数常写作 σ ( ⋅ ) \sigma(\cdot) σ(⋅):如 ReLU ( ⋅ ) \text{ReLU}(\cdot) ReLU(⋅), Sigmoid ( ⋅ ) \text{Sigmoid}(\cdot) Sigmoid(⋅)……
- 经典GNN层(公式中橘色部分为信息聚合,红色部分为信息转换)
- 图卷积网络GCN
h v ( l ) = σ ( ∑ u ∈ N ( v ) W ( l ) h u ( l − 1 ) ∣ N ( v ) ∣ ) \mathbf{h}_v^{(l)}=\textcolor{orange}{\sigma(\sum\limits_{u\in N(v)}}\textcolor{red}{\mathbf{W}^{(l)}\frac{\mathbf{h}_u^{(l-1)}}{|N(v)|}}\textcolor{orange}{)} hv(l)=σ(u∈N(v)∑W(l)∣N(v)∣hu(l−1))
信息转换:对上一层的节点嵌入用本层的权重矩阵进行转换,用节点度数进行归一化(在不同GCN论文中会应用不同的归一化方式)
信息聚合:加总邻居信息,应用激活函数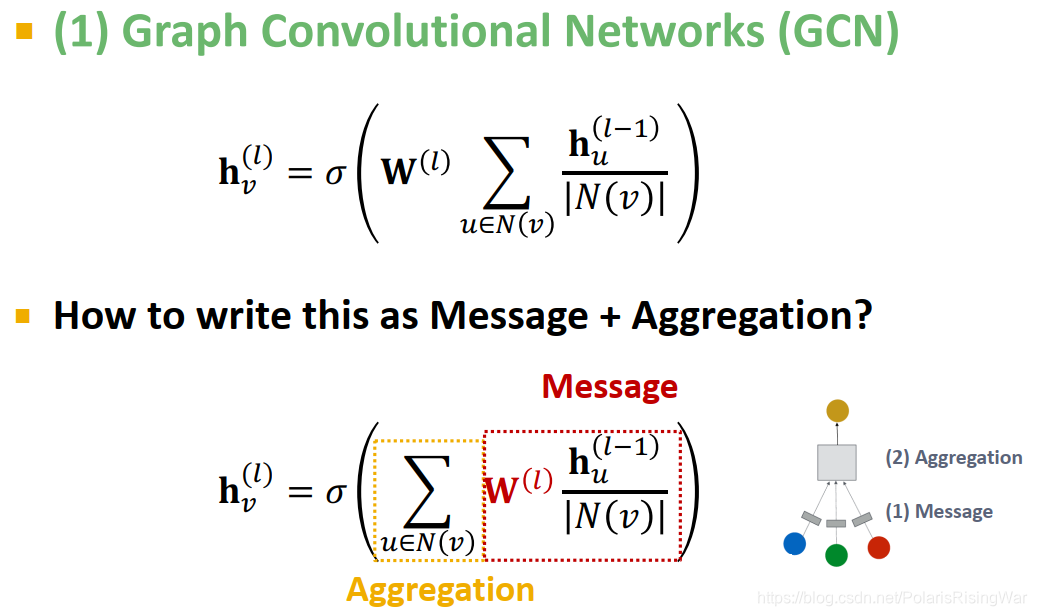
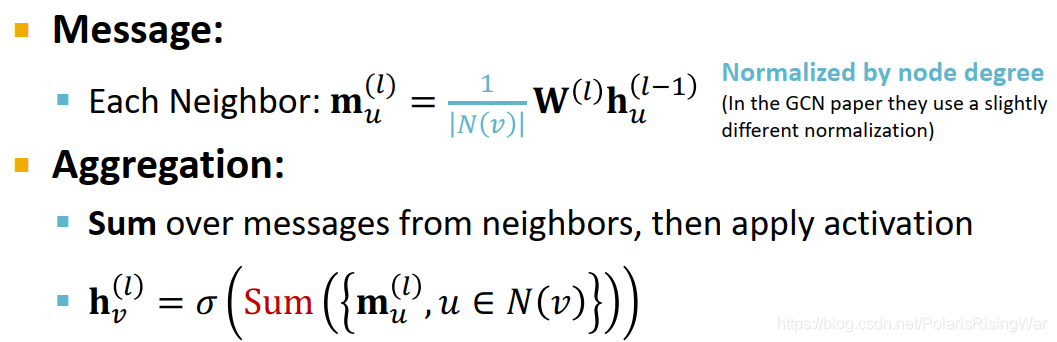
- GraphSAGE
h v ( l ) = σ ( W ( l ) ⋅ CONCAT ( h v ( l − 1 ) , AGG ( { h u ( l − 1 ) , ∀ u ∈ N ( v ) } ) ) ) h_v^{(l)}=\textcolor{orange}{\sigma(\mathbf{W}^{(l)}\cdot\text{CONCAT}(}h_v^{(l-1)},\textcolor{orange}{\text{AGG}(\{\mathbf{h}_u^{(l-1)},\forall u\in N(v)\})))} hv(l)=σ(W(l)⋅CONCAT(hv(l−1),AGG({hu(l−1),∀u∈N(v)})))
信息转换在 A G G AGG AGG 过程中顺带着实现
信息聚合分为两步:
第一步:聚合邻居节点信息: h N ( v ) ( l ) ← AGG ( { h u ( l − 1 ) , ∀ u ∈ N ( v ) } ) h_{N(v)}^{(l)}\leftarrow\text{AGG}\left(\{\mathbf{h}_u^{(l-1)},\forall u\in N(v)\}\right) hN(v)(l)←AGG({hu(l−1),∀u∈N(v)})
第二步:将上一步信息与节点本身信息进行聚合: h v ( l ) = σ ( W ( l ) ⋅ CONCAT ( h v ( l − 1 ) , h N ( v ) ( l ) ) h_v^{(l)}=\sigma\left(\mathbf{W}^{(l)}\cdot\text{CONCAT}(h_v^{(l-1)},h_{N(v)}^{(l)}\right) hv(l)=σ(W(l)⋅CONCAT(hv(l−1),hN(v)(l))
- GraphSAGE聚合邻居的方式:(后续课程中将详细介绍不同实现方式的理论基础和结果)
- Mean:邻居的加权平均值
AGG = ∑ u ∈ N ( v ) h u ( l − 1 ) ∣ N ( v ) ∣ \text{AGG}=\textcolor{orange}{\sum\limits_{u\in N(v)}}\dfrac{h_u^{(l-1)}}{\textcolor{red}{|N(v)|}} AGG=u∈N(v)∑∣N(v)∣hu(l−1) - Pool:对邻居向量做转换,再应用对称向量函数,如求和
Mean
(
⋅
)
\text{Mean}(\cdot)
Mean(⋅) 或求最大值
Max
(
⋅
)
\text{Max}(\cdot)
Max(⋅)
AGG = Mean ( { MLP ( h u ( l − 1 ) ) , ∀ u ∈ N ( v ) } ) \text{AGG}=\textcolor{orange}{\text{Mean}}\left(\left\{\textcolor{red}{\text{MLP}}\left(h_u^{(l-1)}\right),\forall u\in N(v)\right\}\right) AGG=Mean({MLP(hu(l−1)),∀u∈N(v)}) - LSTM:在reshuffle的邻居上应用LSTM
A G G = LSTM ( [ h u ( l − 1 ) , ∀ u ∈ π ( N ( v ) ) ] ) AGG=\textcolor{orange}{\text{LSTM}}\left(\left[h_u^{(l-1)},\forall u\in\pi\left(N\left(v\right)\right)\right]\right) AGG=LSTM([hu(l−1),∀u∈π(N(v))])
- Mean:邻居的加权平均值
- 在GraphSAGE每一层上都可以做 L2 归一化:
h
v
(
l
)
←
h
v
(
l
)
∣
∣
h
v
(
l
)
∣
∣
2
h^{(l)}_v\leftarrow\dfrac{h^{(l)}_v}{||h^{(l)}_v||_2}
hv(l)←∣∣hv(l)∣∣2hv(l)
经过归一化后,所有向量都具有了相同的L2范式
有时可以提升模型的节点嵌入效果
- GAT1
h v ( l ) = σ ( ∑ u ∈ N ( v ) α v u W ( l ) h u ( l − 1 ) ) \mathbf{h}_v^{(l)}=\sigma\left(\sum_{u\in N(v)}\textcolor{green}{\alpha_{vu}}\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)}\right) hv(l)=σ(∑u∈N(v)αvuW(l)hu(l−1))
α v u \alpha_{vu} αvu 是注意力2权重attention weights,衡量 u u u 的信息对 v v v 的重要性(越重要,权重越高,对 v v v 的信息计算结果影响越大)。
在GCN和GraphSAGE中, α v u = 1 ∣ N ( v ) ∣ \alpha_{vu}=\dfrac{1}{|N(v)|} αvu=∣N(v)∣1,直接基于图结构信息(节点度数)显式定义注意力权重,相当于认为节点的所有邻居都同样重要(注意力权重一样大)。 - 在GAT中注意力权重的计算方法是:通过attention mechanism
a
a
a(一个可训练的模型)用两个节点上一层的节点嵌入计算其attention coefficient
e
v
u
e_{vu}
evu,用
e
v
u
e_{vu}
evu 计算
α
v
u
\alpha_{vu}
αvu。
attention mechanism: e v u = a ( W ( l ) h u ( l − 1 ) , W ( l ) h v ( l − 1 ) ) \textcolor{blue}{e_{vu}}=a\left(\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)},\mathbf{W}^{(l)}\mathbf{h}_v^{(l-1)}\right) evu=a(W(l)hu(l−1),W(l)hv(l−1))
这个 a a a 随便选(可以是不对称的),比如用单层神经网络,则 a a a 有可训练参数(线性层中的权重): e v u = Linear ( Concat ( W ( l ) h u ( l − 1 ) , W ( l ) h v ( l − 1 ) ) ) \textcolor{blue}{e_{vu}}=\text{Linear}\left(\text{Concat}\left(\mathbf{W}^{\left(l\right)}\mathbf{h}_u^{\left(l-1\right)},\mathbf{W}^{\left(l\right)}\mathbf{h}_v^{\left(l-1\right)}\right)\right) evu=Linear(Concat(W(l)hu(l−1),W(l)hv(l−1)))
attention coefficient e v u e_{vu} evu 表示了 u u u 的信息对 v v v 的重要性
将 attention coefficient e v u e_{vu} evu 归一化,得到最终的 attention weight α v u \textcolor{pink}{\alpha_{vu}} αvu: α v u = exp e v u ∑ k ∈ N ( v ) exp e v k \textcolor{pink}{\alpha_{vu}}=\dfrac{\exp{e_{vu}}}{\sum_{k\in N(v)}\exp{e_{vk}}} αvu=∑k∈N(v)expevkexpevu
用softmax函数使 ∑ u ∈ N ( v ) α v u = 1 \sum_{u\in N(v)}\alpha_{vu}=1 ∑u∈N(v)αvu=1,也就是邻居对该节点的注意力权重和为1
GAT节点信息的计算方式就是基于 attention weight α v u \textcolor{pink}{\alpha_{vu}} αvu 加权求和:
h v ( l ) = σ ( ∑ u ∈ N ( v ) α v u W ( l ) h u ( l − 1 ) ) \mathbf{h}_v^{(l)}=\sigma\left(\sum_{u\in N(v)}\textcolor{pink}{\alpha_{vu}}\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)}\right) hv(l)=σ(∑u∈N(v)αvuW(l)hu(l−1))


 这里的attend指的是给予其邻居不同的重要性importance
这里的attend指的是给予其邻居不同的重要性importance


- GAT的多头注意力机制multi-head attention:增加模型鲁棒性,使模型不卡死在奇怪的优化空间,在实践上平均表现更好。
用不同参数建立多个 attention 模型:
h v ( l ) [ 1 ] = σ ( ∑ u ∈ N ( v ) α v u 1 W ( l ) h u ( l − 1 ) ) \mathbf{h}_v^{(l)}[1]=\sigma\left(\sum_{u\in N(v)}\textcolor{red}{\alpha_{vu}^1}\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)}\right) hv(l)[1]=σ(∑u∈N(v)αvu1W(l)hu(l−1))
h v ( l ) [ 2 ] = σ ( ∑ u ∈ N ( v ) α v u 2 W ( l ) h u ( l − 1 ) ) \mathbf{h}_v^{(l)}[2]=\sigma\left(\sum_{u\in N(v)}\textcolor{green}{\alpha_{vu}^2}\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)}\right) hv(l)[2]=σ(∑u∈N(v)αvu2W(l)hu(l−1))
h v ( l ) [ 3 ] = σ ( ∑ u ∈ N ( v ) α v u 3 W ( l ) h u ( l − 1 ) ) \mathbf{h}_v^{(l)}[3]=\sigma\left(\sum_{u\in N(v)}\textcolor{blue}{\alpha_{vu}^3}\mathbf{W}^{(l)}\mathbf{h}_u^{(l-1)}\right) hv(l)[3]=σ(∑u∈N(v)αvu3W(l)hu(l−1))
将输出进行聚合(通过concatenation或加总): h v ( l ) = AGG ( h v ( l ) [ 1 ] , h v ( l ) [ 2 ] , h v ( l ) [ 3 ] ) \mathbf{h}_v^{(l)}=\text{AGG}\left(\mathbf{h}_v^{(l)}[1],\mathbf{h}_v^{(l)}[2],\mathbf{h}_v^{(l)}[3]\right) hv(l)=AGG(hv(l)[1],hv(l)[2],hv(l)[3])
- 注意力机制的优点:
核心优点:隐式定义节点信息对邻居的importance value α v u \alpha_{vu} αvu- computationally efficient:对attentional coefficients的计算可以在图中所有边上同步运算,聚合过程可以在所有节点上同步运算
- storage efficient:稀疏矩阵运算需要存储的元素数不超过 O ( V + E ) O(V+E) O(V+E),参数数目固定( a a a 的可训练参数尺寸与图尺寸无关)
- localized:仅对本地网络邻居赋予权重
- inductive capability:边间共享机制,与全局图结构无关(我的理解就是算出 attention mechanism 的参数之后就完全可以正常对新节点运算,不需要再重新计算什么参数了)

- GAT示例:Cora Citation Net
attention机制可应用于多种GNN模型中。在很多案例中表现出了结果的提升。
如图显示,将节点嵌入降维到二维平面,节点不同颜色表示不同类,边的宽度表示归一化后的attention coefficient(8个attention head计算后求和)
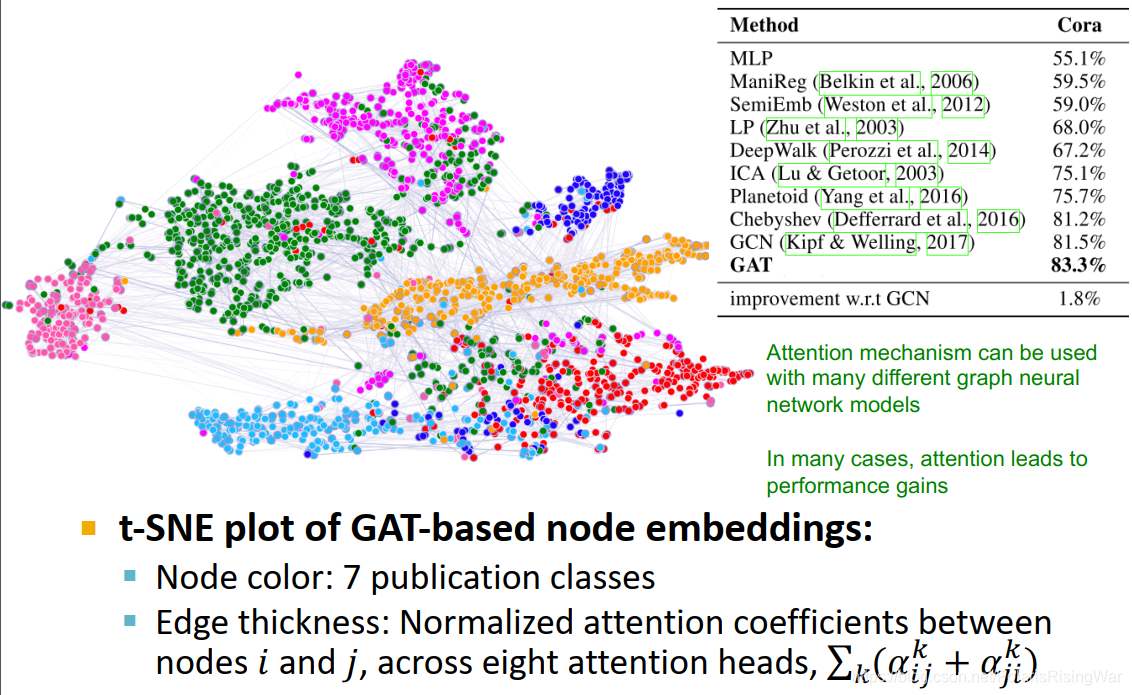 t-SNE是一种降维技术
t-SNE是一种降维技术
- 图卷积网络GCN
- 实践应用中的GNN网络层:往往会应用传统神经网络模块,如在信息转换阶段应用Batch Normalization(使神经网络训练稳定)、Dropout(预防过拟合)、Attention / Gating3(控制信息重要性)等。
 concretely具体地; 具体; 具体的; 有形地;
concretely具体地; 具体; 具体的; 有形地;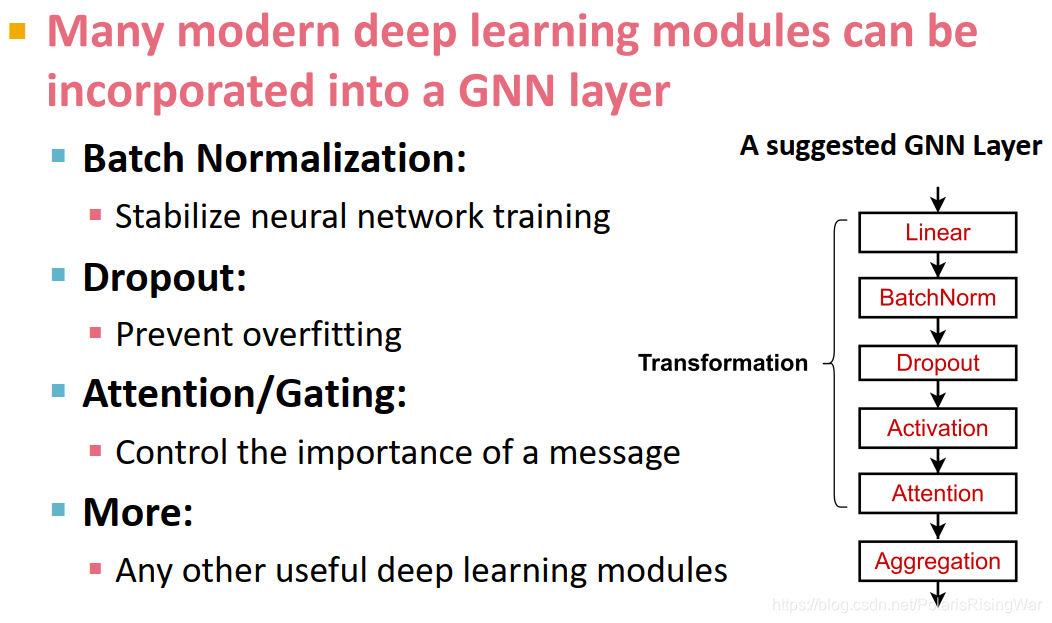
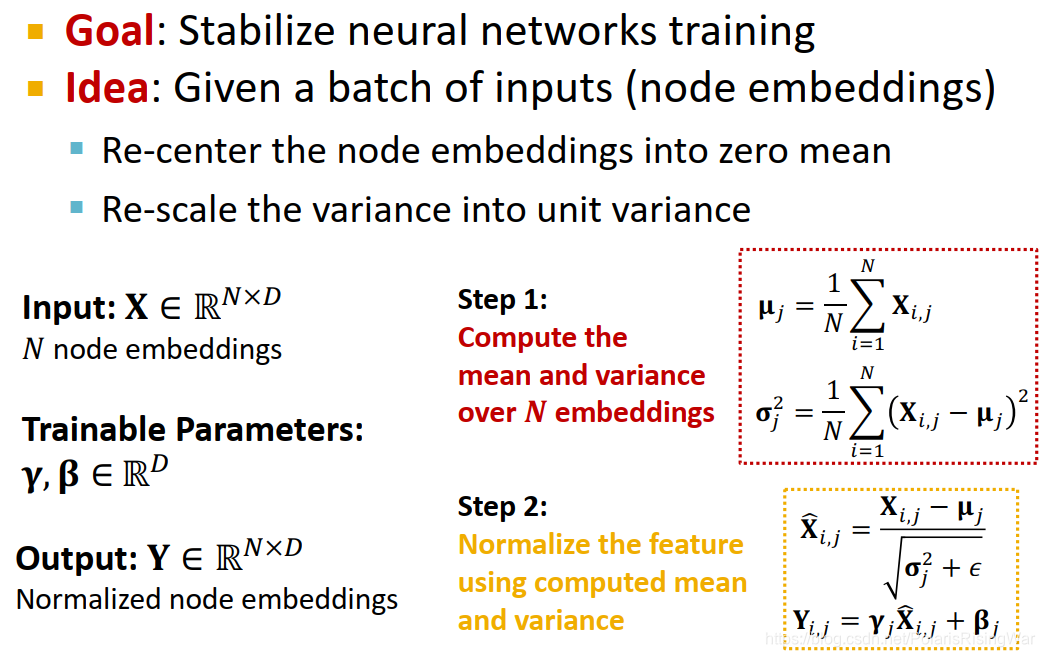
- Batch Normalization4:对一个batch的输入数据(节点嵌入)进行归一化,使其平均值为0,方差为1
- Dropout5:在训练阶段,以概率p随机将神经元置为0;在测试阶段,用所有的神经元来进行计算
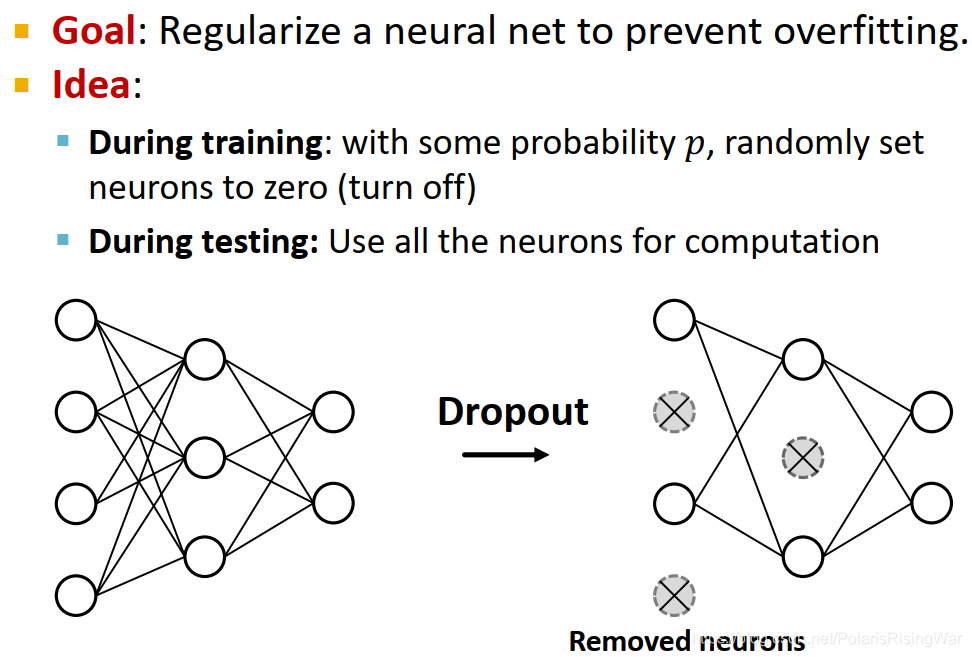
- GNN中的Dropout:应用在信息转换过程中的线性网络层上
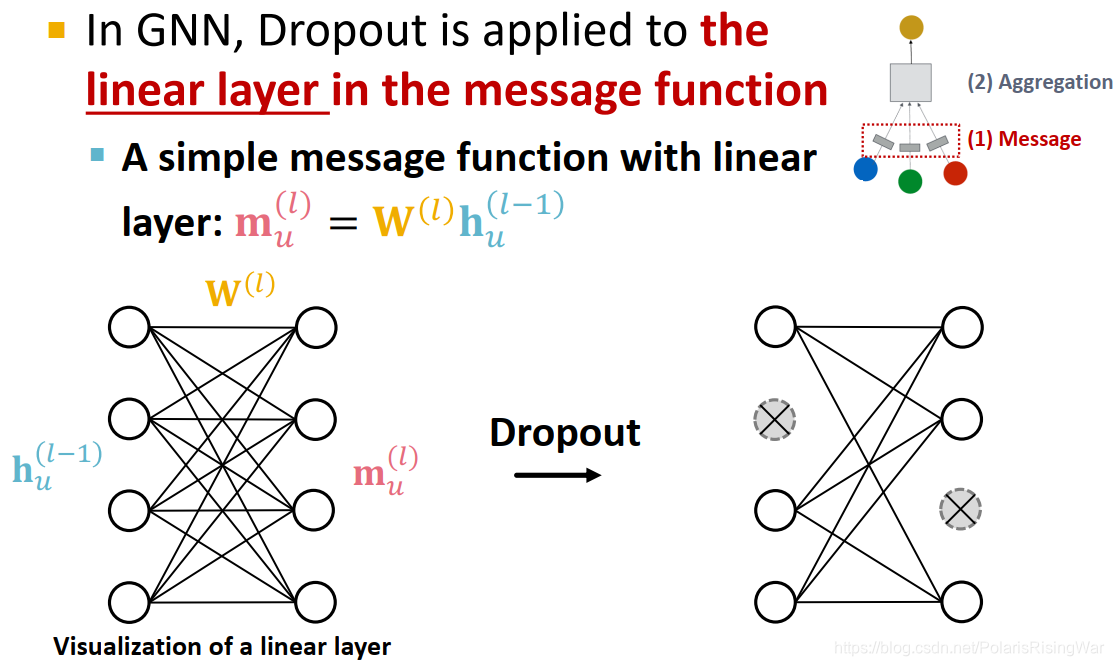
- 非线性函数 / 激活函数:用于激活嵌入向量
x
x
x 的第
i
i
i 维:
最常用的ReLU: ReLU = max ( x i , 0 ) \text{ReLU}=\max{(\mathbf{x}_i,0)} ReLU=max(xi,0)
Sigmoid: σ ( x i ) = 1 1 + e − x i \sigma(\mathbf{x}_i)=\dfrac{1}{1+e^{-\mathbf{x}_i}} σ(xi)=1+e−xi1 (用于希望限制嵌入范围)
Parametric ReLU: PReLU ( x i ) = max ( X i , 0 ) + a i min ( x i , 0 ) \text{PReLU}(\mathbf{x}_i)=\max{(\mathbf{X}_i,0)}+\textcolor{red}{a_i}\min{(\mathbf{x}_i,0)} PReLU(xi)=max(Xi,0)+aimin(xi,0) ( a i \textcolor{red}{a_i} ai 是可学习的参数)(实证表现优于ReLU)
- 可以通过 GraphGym 来测试不同的GNN设计实例(我还没用过这个包)。
3. Stacking Layers of a GNN
- 再回顾一下第一节写的连接GNN网络层部分:
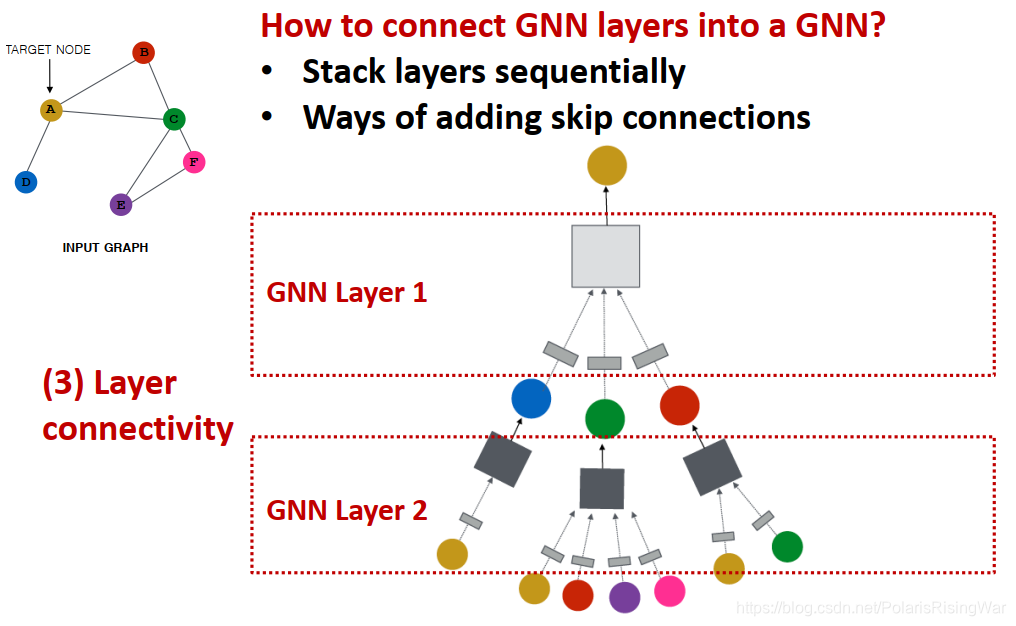
- 连接GNN网络层的标准方式:按序堆叠
输入原始节点特征,输出L层后计算得到的节点嵌入向量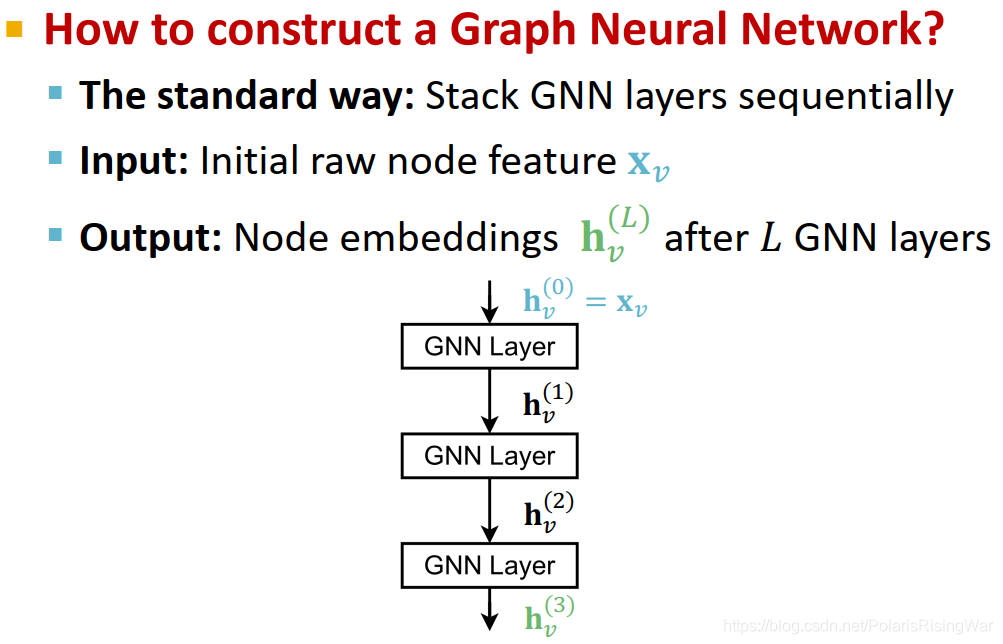
- 过平滑问题the over-smoothing problem6:如果GNN层数太多,不同节点的嵌入向量会收敛到同一个值(如果我们想用节点嵌入做节点分类任务,这就凉了)
 GNN的层跟别的神经网络的层不一样,GNN的层数说明的是它聚集多少跳邻居的信息
GNN的层跟别的神经网络的层不一样,GNN的层数说明的是它聚集多少跳邻居的信息 - GNN的感受野receptive field:决定该节点嵌入的节点组成的集合。
对K层GNN,每个节点都有一个K跳邻居的感受野。如图可见K越大,感受野越大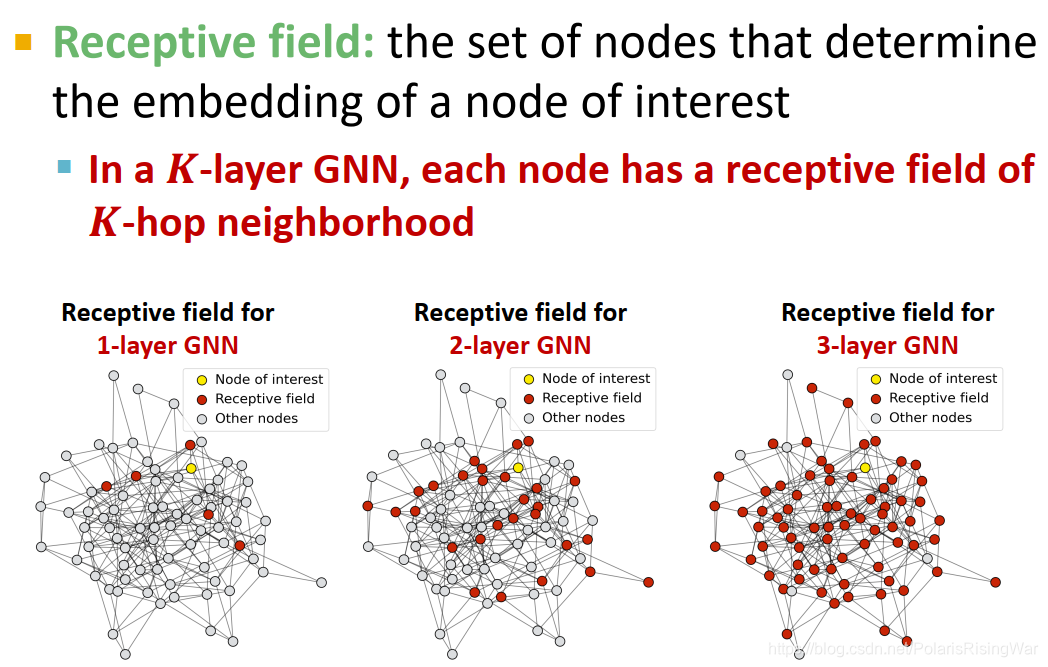
- 对两个节点来说,K变大,感受野重合部分会迅速变大
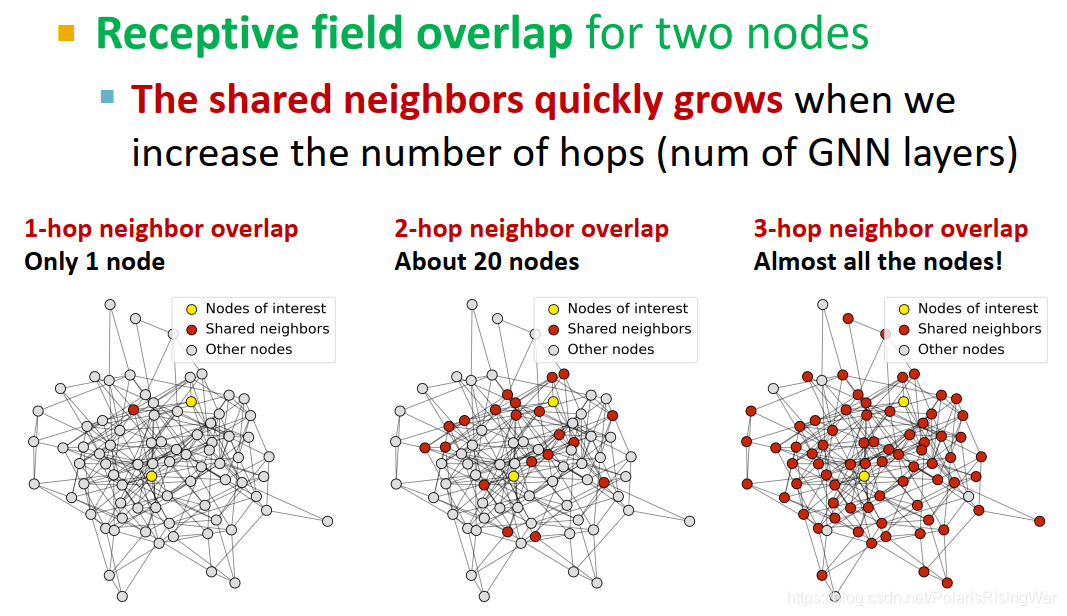
- 感受野 & 过平滑
节点嵌入受其感受野决定,两个节点间的感受野越重合,其嵌入就越相似。
堆叠很多GNN网络层→节点具有高度重合的感受野→节点嵌入高度相似→过平滑问题
- 由于过平滑问题,我们需要谨慎考虑增加GNN层。
第一步:分析解决问题所需的必要感受野(如测量图的直径7)
第二步:设置GNN层数 L 略大于我们想要的感受野
- 既然GNN层数不能太多,那么我们如何使一个浅的GNN网络更具有表现力呢?
- 方法1:增加单层GNN的表现力,如将信息转换/信息聚合过程从一个简单的线性网络变成深度神经网络(如3层MLP)

- 方法2:添加不是用来传递信息的网络层,也就是非GNN层,如对每个节点应用MLP(在GNN层之前或之后均可,分别叫 pre-process layers 和 post-process layers)
pre-processing layers:如果节点特征必须经过编码就很重要(如节点表示图像/文字时)
post-processing layers:如果在节点嵌入的基础上需要进行推理和转换就很重要(如图分类、知识图谱等任务中)colab28中的图分类任务就都有,用AtomEncoder作为pre-processing layer,池化层作为post-processing layer
- 方法1:增加单层GNN的表现力,如将信息转换/信息聚合过程从一个简单的线性网络变成深度神经网络(如3层MLP)
- 如果实际任务还是需要很多层GNN网络,那么可以在GNN模型中增加skip connections9
通过对过平滑问题进行观察,我们可以发现,靠前的GNN层可能能更好地区分节点。(就很明显嘛这事)
因此我们可以在最终节点嵌入中增加靠前GNN层的影响力,实现方法是在GNN中直接添加捷径,保存上一层节点的嵌入向量(看后文应该是指在激活函数前,在聚合后的结果的基础上再加上前一层的嵌入向量)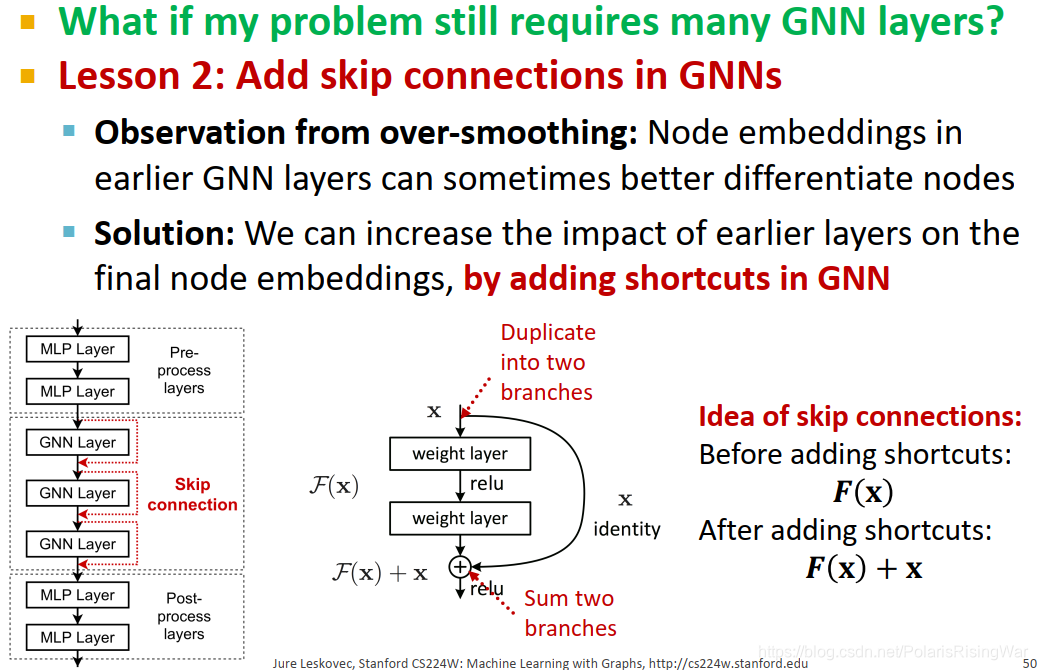
- skip connections原理10:
相当于制造了多个模型(如图所示),N个skip connections就相当于创造了 2 N 2^N 2N条路径,每一条路径最多有N个模块。
这些路径都会对最终的节点嵌入产生影响,相当于自动获得了一个浅GNN和深GNN的融合模型。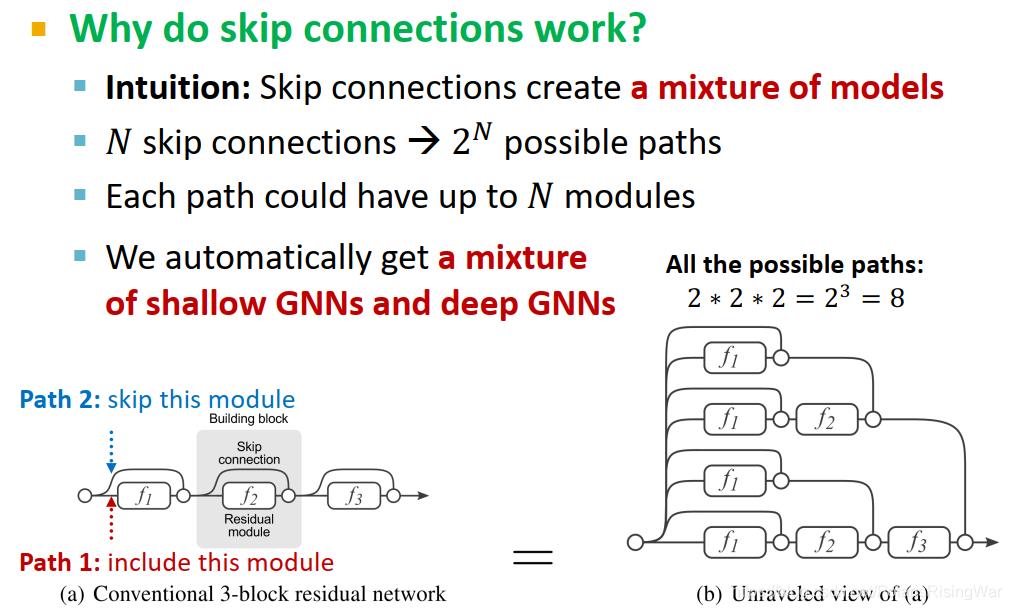
- skip connections示例:在GCN中的应用
标准GCN层: h v ( l ) = σ ( ∑ u ∈ N ( v ) W ( l ) h u ( l − 1 ) ∣ N ( v ) ∣ ) \mathbf{h}_v^{(l)}=\sigma\left(\textcolor{orange}{\sum\limits_{u\in N(v)}\mathbf{W}^{(l)}\frac{\mathbf{h}_u^{(l-1)}}{|N(v)|}}\right) hv(l)=σ(u∈N(v)∑W(l)∣N(v)∣hu(l−1))(橘色部分是 F ( x ) \mathbf{F}(x) F(x))
带skip connections的GCN层: h v ( l ) = σ ( ∑ u ∈ N ( v ) W ( l ) h u ( l − 1 ) ∣ N ( v ) ∣ + h v ( l − 1 ) ) \mathbf{h}_v^{(l)}=\sigma\left(\textcolor{orange}{\sum\limits_{u\in N(v)}\mathbf{W}^{(l)}\frac{\mathbf{h}_u^{(l-1)}}{|N(v)|}}+\textcolor{blue}{\mathbf{h}_v^{(l-1)}}\right) hv(l)=σ(u∈N(v)∑W(l)∣N(v)∣hu(l−1)+hv(l−1))(橘色部分是 F ( x ) \mathbf{F}(x) F(x),蓝字部分是 x x x)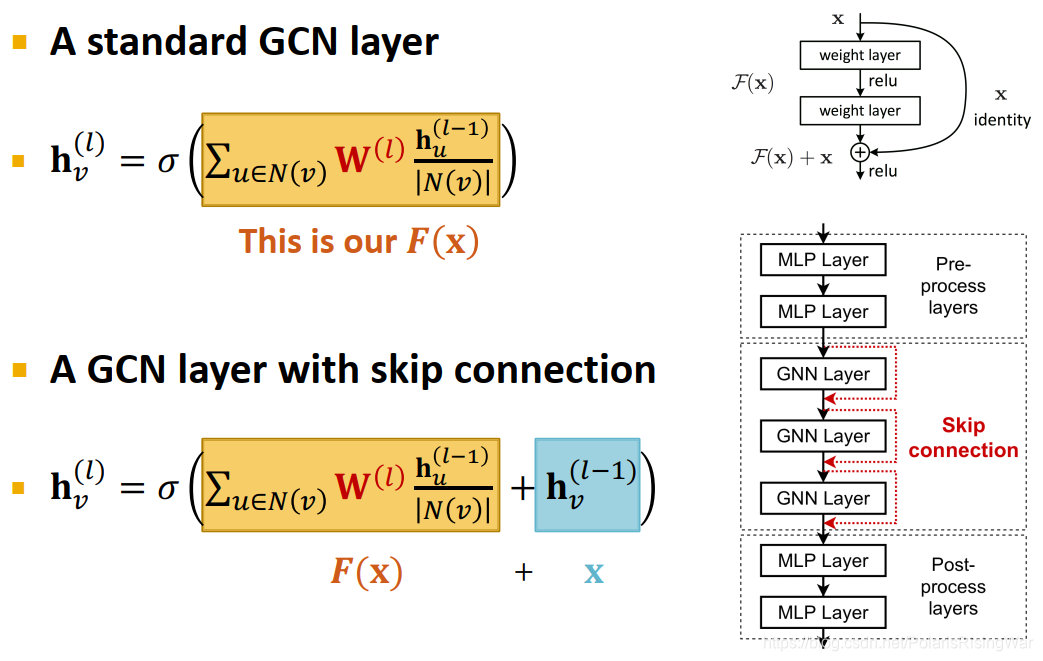
- skip connections也可以跨多层,直接跨到最后一层,在最后一层聚合之前各层的嵌入(通过concat / pooling / LSTM)11

Veličković P, Cucurull G, Casanova A, et al. Graph attention networks[J]. arXiv preprint arXiv:1710.10903, 2017. ↩︎
我了解了一下,attention是一个NLP领域的概念,反正还挺复杂的,我没咋看懂。我不懂NLP,以后如果需要的话再仔细了解。
理解GAT这里的注意力权重感觉不需要有NLP那边的领域知识,感觉可以直接将其视为一个不同节点对之间的权重(具体值需要学习)。 ↩︎gating function门函数,门机制
我简单查了一下,gating直观看起来也是设置权重的(比如关门,开门什么的),GRU、LSTM等就是应用了门机制。别的还没仔细看,因为没讲嘛…… ↩︎S. Loffe, C.Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, ICML 2015 ↩︎
Srivastava et al. Dropout: A Simple Way to Prevent Neural Networks from Overfitting, JMLR 2014 ↩︎
这个问题我自己百度了一下,看到知乎上有一个相应的问题( 如何解决图神经网络(GNN)训练中过度平滑的问题? - 知乎 ),感觉回答很专业,但是感觉是从谱域角度出发、用各种矩阵分解之类的逻辑来解释的原因……
没看懂啊,我一直在学这门课,这门课谱域GNN是一个字都没讲啊……
我看懂的部分只有对过平滑问题的定义:
即在图神经网络的训练过程中,随着网络层数的增加和迭代次数的增加,同一连通分量内的节点的表征会趋向于收敛到同一个值(即空间上的同一个位置)。
不是所有图神经网络都有 over-smooth 的问题,例如,基于 RandomWalk + RNN、基于 Attention 的模型大多不会有这个问题,是可以放心叠深度的~只有部分图卷积神经网络会有该问题。
所以我就仅对课程中讲述的内容做笔记了。以后如果有需要的话再去研究这些高深的知识吧。 ↩︎图论中,图的直径是指任意两个顶点间距离的最大值(来源:什么是图的直径?再说一遍,是图的直径,不是圆的直径._作业帮 ) ↩︎
He et al. Deep Residual Learning for Image Recognition, CVPR 2015
其实在我看来,skip connections和RNN的逻辑比较像,就都是把之前的神经元输出和上一层神经元输出结合起来作为这一层神经元的输入。 ↩︎Veit et al. Residual Networks Behave Like Ensembles of Relatively Shallow Networks, ArXiv 2016 ↩︎
Xu et al. Representation learning on graphs with jumping knowledge networks, ICML 2018 ↩︎















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











