







诸神缄默不语-个人CSDN博文目录
cs224w(图机器学习)2021冬季课程学习笔记集合
文章目录
YouTube 视频观看地址1 视频观看地址2 视频观看地址3 视频观看地址4
本章主要内容:
本章首先介绍了图生成模型generative models for graphs的基本概念和意义。
接下来介绍了一些真实世界网络的属性(度数分布、聚集系数、connected component、path length等,可参考1)(也是图生成模型希望可以达到的要求)。
最后介绍了一些传统的图生成模型(Erdös-Renyi graphs, small-world graphs, Kronecker graphs)。
1. (Traditional) Generative Models for Graphs
- 图生成模型问题的研究动机:
我们此前的学习过程中,都假设图是已知的;但我们也会想通过graph generative model人工生成与真实图类似的synthetic graph,这可以让我们:
①了解图的形成过程。
②预测图的演化。
③生成新的图实例。
④异常检测:检测一个图是否异常。



- 本课程对图生成模型的介绍流程:
在本章介绍真实图的属性(生成图需要符合的特性)和传统图生成模型(每种模型都源自对图形成过程的不同假设)。
在下一章介绍深度图生成模型,从原始数据直接学习到图生成过程。

2. Properties of Real-world Graphs
- 衡量真实图数据的属性有:
degree distribution
clustering coefficient
connected components
path length
对这些属性的介绍可参考1

- degree distribution
P ( k ) P(k) P(k):一个随机节点度数为 k k k 的概率
用 N k N_k Nk 表示度数为 k k k 的节点数,则 P ( k ) = N k / N P(k)=N_k/N P(k)=Nk/N
相当于节点度数的归一化直方图:
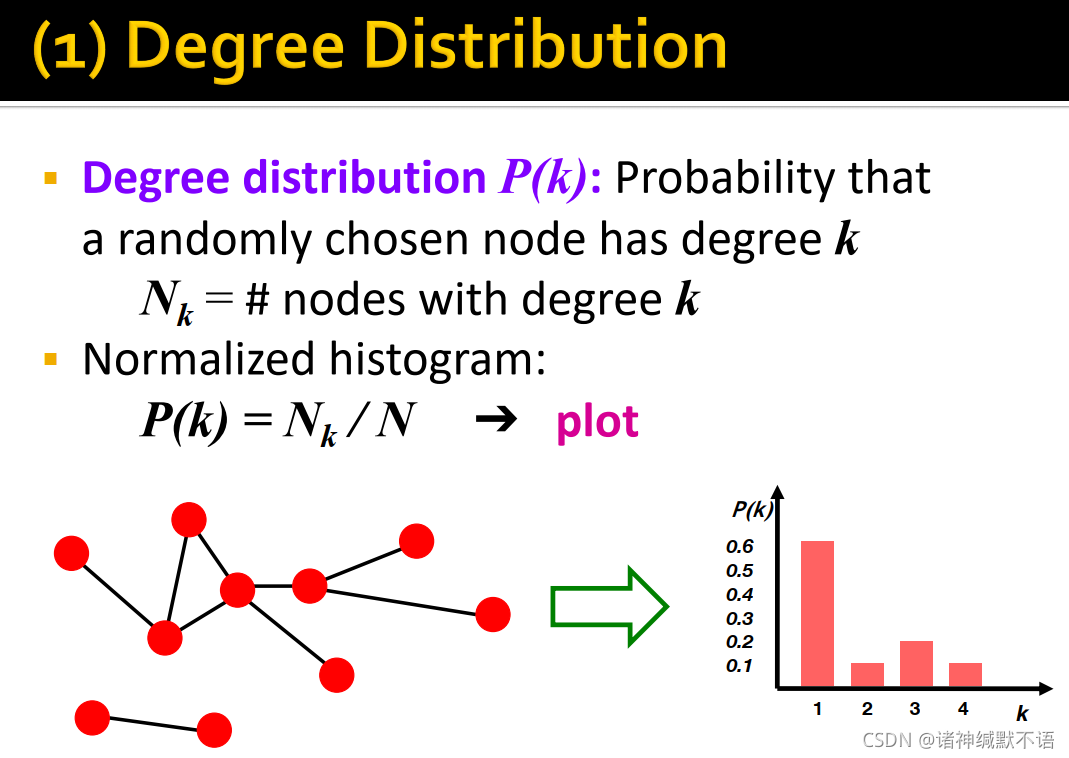
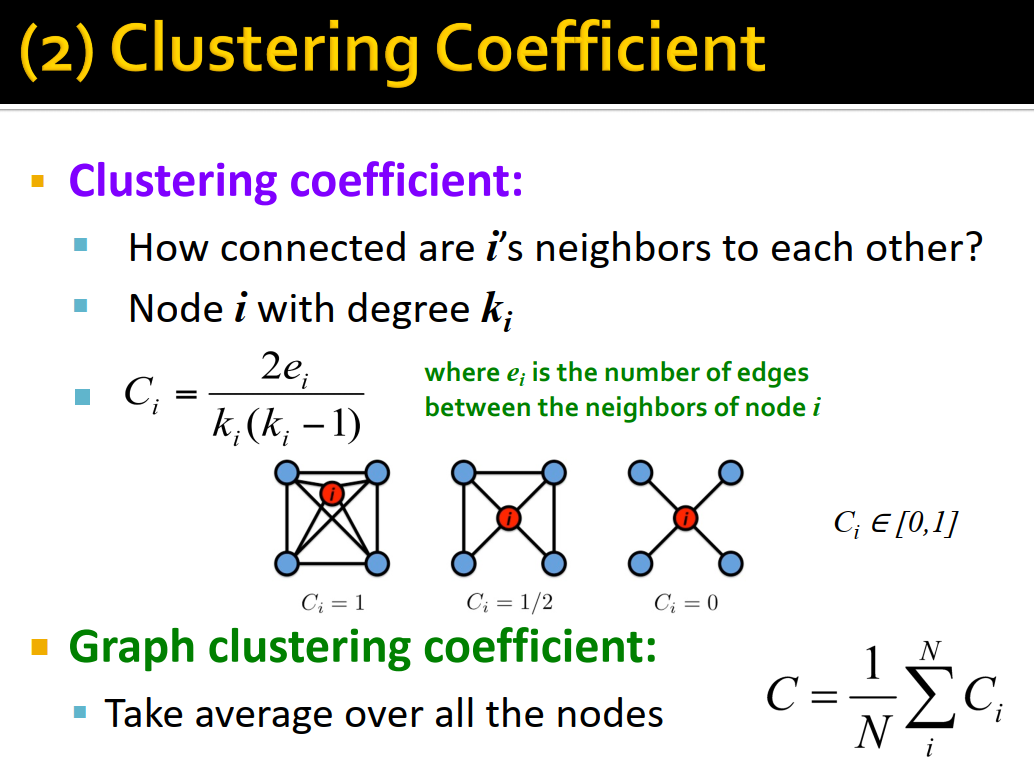
- clustering coefficient衡量节点邻居的连接紧密程度。
节点 i i i 的度数为 k i k_i ki,邻居间边数为 e i e_i ei,则其clustering coefficient为 C i = e i C k i 2 = 2 e i k i ( k i − 1 ) C_i=\dfrac{e_i}{C_{k_i}^2}=\dfrac{2e_i}{k_i(k_i-1)} Ci=Cki2ei=ki(ki−1)2ei,即实际存在的邻居上的边数占所有邻居上可能存在的边数( C k i 2 C_{k_i}^2 Cki2)的比例。大小范围为 [ 0 , 1 ] [0,1] [0,1]。
整个图上的clustering coefficient就是对每个节点的clustering coefficient取平均: C = 1 N ∑ i N C i C=\dfrac{1}{N}\sum\limits_i^NC_i C=N1i∑NCi
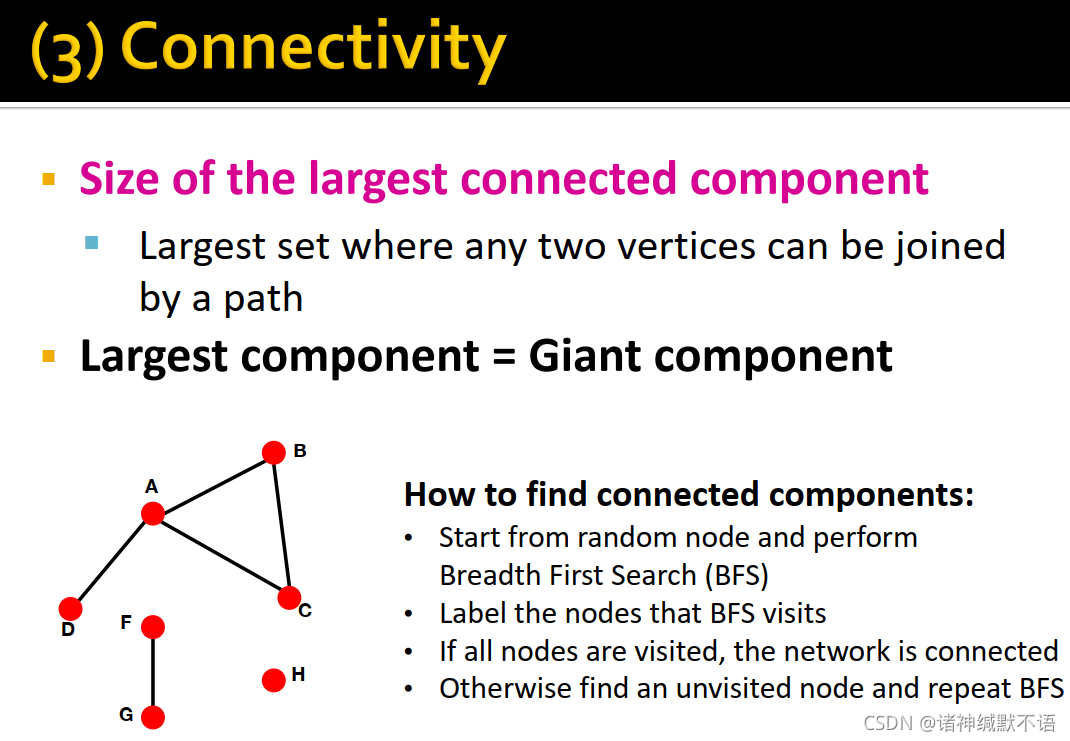
- connectivity是largest connected component(任意两个节点都有路径相连的最大子图2)的大小。
largest component=giant component
找到connected components(连通分量)的方法:随机选取节点跑BFS3,标记所有被访问到的节点;如果所有节点都能访问到,说明整个网络都是连通的;否则就选一个没有访问过的节点重复BFS过程。
- path length:一条路径的长度。
节点对之间最短路径长度称为距离。
diameter:图中最大的节点对间最短路径。
connected graph 或 strongly connected directed graph4 上的average path length: h ‾ = 1 2 E m a x ∑ i , j ≠ i h i j \overline{h}=\dfrac{1}{2E_{max}}\sum\limits_{i,j\neq i}h_{ij} h=2Emax1i,j=i∑hij
其中 h i j h_{ij} hij 是节点 i i i 到 j j j 之间的距离, E m a x E_{max} Emax 是最大边数(即节点对数) n ( n − 1 ) / 2 n(n-1)/2 n(n−1)/2
我们往往只在相连的节点对上求平均,即忽略infinite的路径长度

- 案例研究:MSN Graph(社交网络)

(这个本来有个地图,但是它好像有点问题,在B站视频里直接码掉了,我也不敢放。总之就是一个地图,并说图数据中有180M用户节点、1.3B条边)
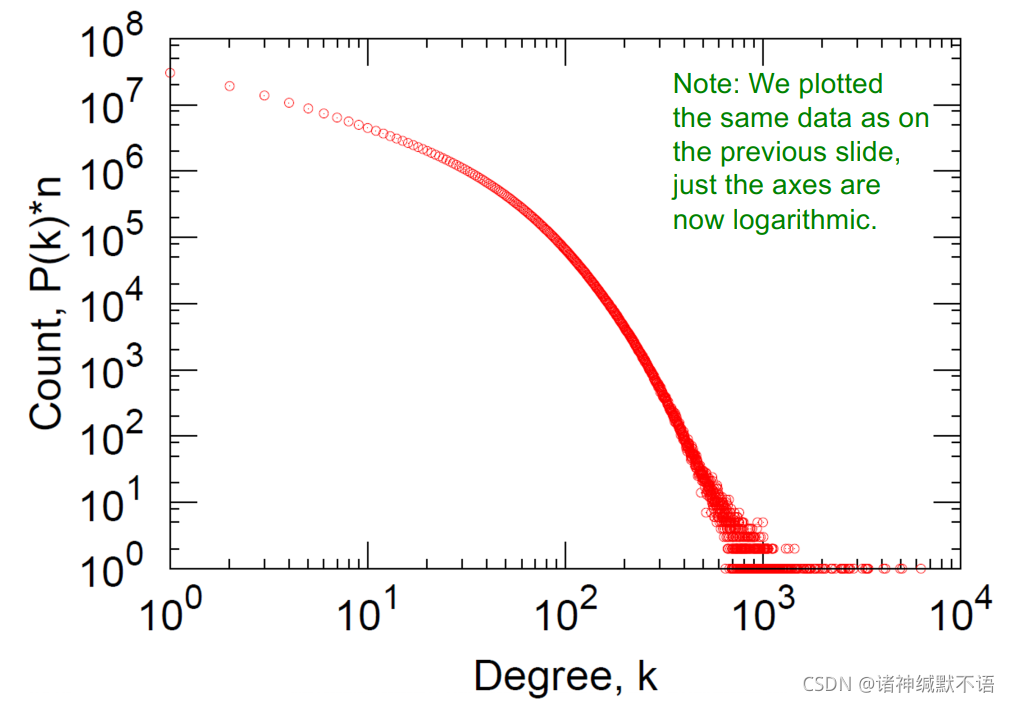
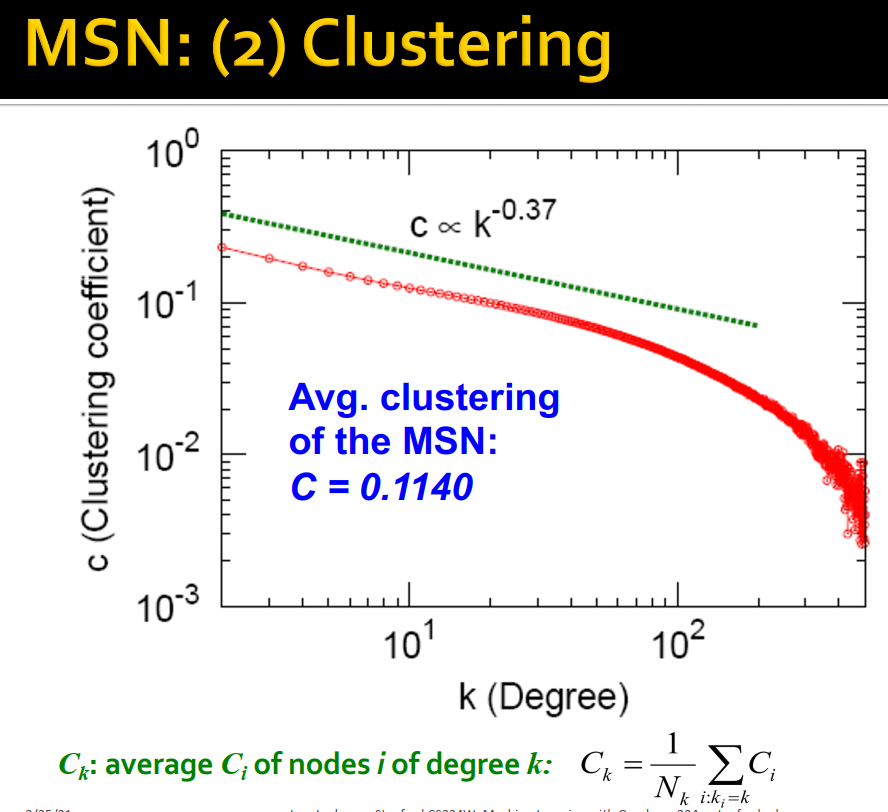
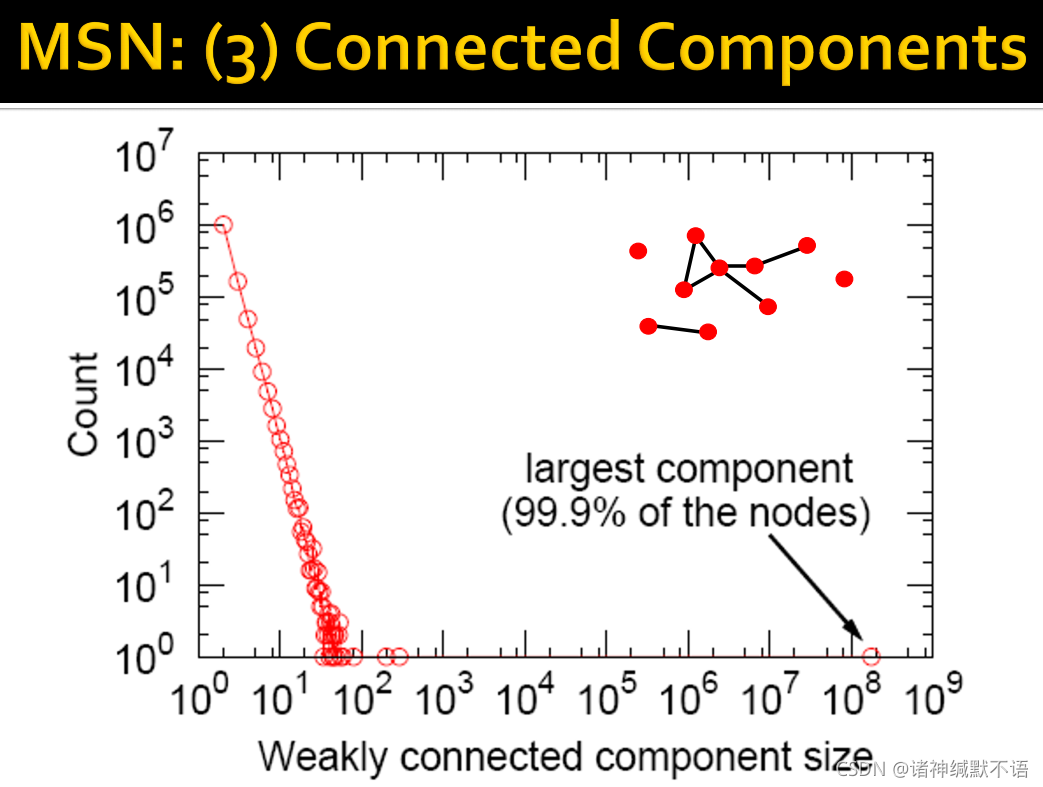
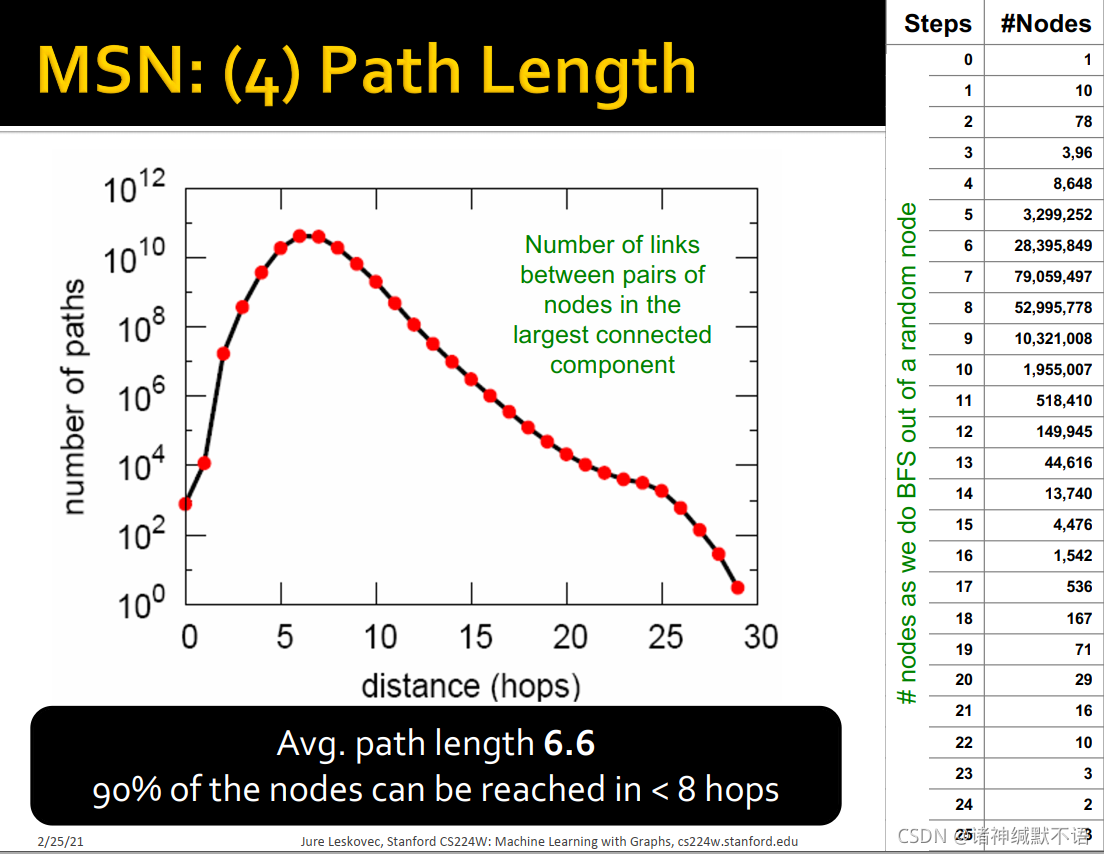 small word phenomenon:虽然图很大但是平均最短路径很小(6.6)。
small word phenomenon:虽然图很大但是平均最短路径很小(6.6)。 这些值是否超乎预料,需要通过图生成模型来检验。
这些值是否超乎预料,需要通过图生成模型来检验。3. Erdös-Renyi Random Graphs6
- Erdös-Renyi Random Graphs是最简单的图生成模型,有两种变体:
G n p G_{np} Gnp:有 n n n 个节点的无向图,每条边 ( u , v ) (u,v) (u,v) 以概率 p p p 独立同分布生成。
G n m G_{nm} Gnm:有 n n n 个节点的无向图,随机生成 m m m 条边。

-
G
n
p
G_{np}
Gnp:图由随机过程生成,因此同样的
n
n
n 和
p
p
p 可以不同的图实例:
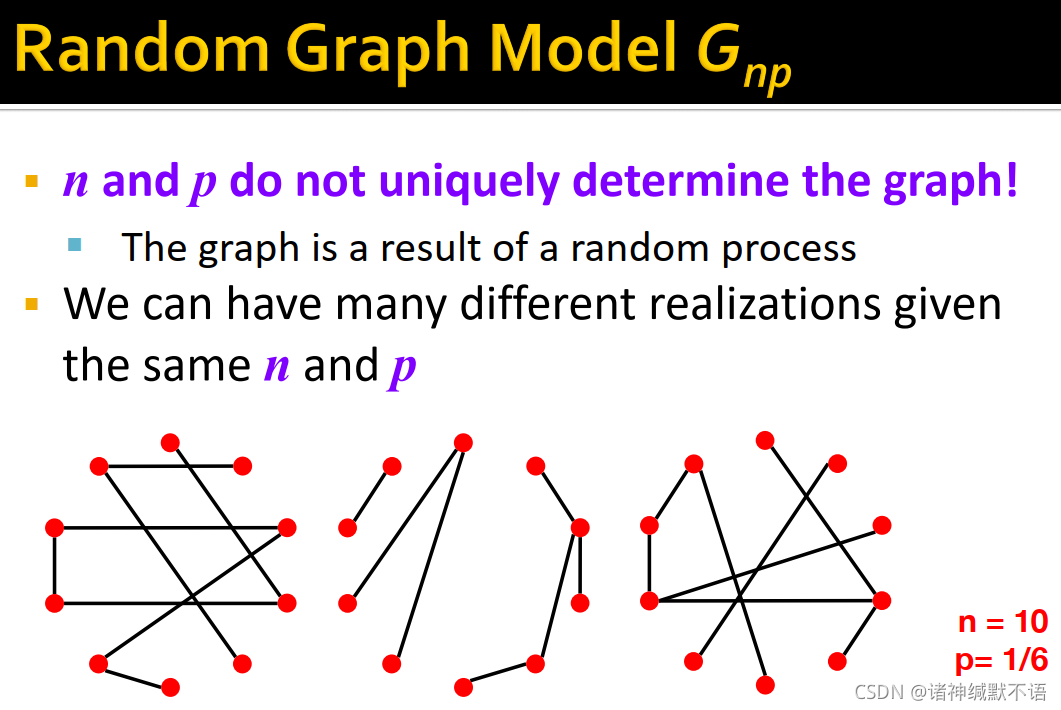
-
G
n
p
G_{np}
Gnp 的图属性值:

- degree distribution
一个节点的度数为 k k k 的概率,即图中度数为 k k k 的节点所占比例的期望值服从二项分布7: P ( k ) = C n − 1 k p k ( 1 − p ) n − 1 − k P(k)=C_{n-1}^kp^k(1-p)^{n-1-k} P(k)=Cn−1kpk(1−p)n−1−k(在除这个节点之外的 n − 1 n-1 n−1 个节点中有 k k k 个节点与该节点以 p p p 的概率相连,这一事件发生的概率)
k ‾ = p ( n − 1 ) σ 2 = p ( 1 − p ) ( n − 1 ) \begin{aligned} \overline{k} & =p(n-1) \\ \sigma^2 & =p(1-p)(n-1) \end{aligned} kσ2=p(n−1)=p(1−p)(n−1)
ER随机图的度数分布类似于一个高斯分布的离散模拟。
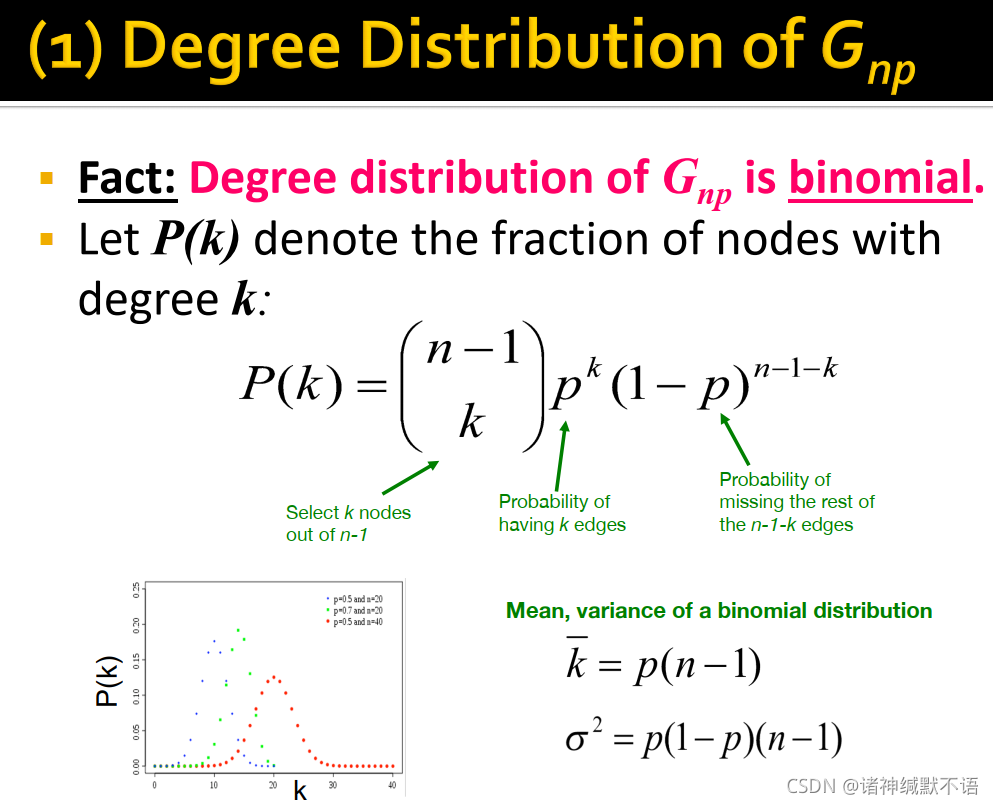
- clustering coefficient
每个节点邻居中边数的期望值为 E [ e i ] = p ⋅ C k i 2 = p ⋅ k i ( k i − 1 ) 2 E[e_i]=p\cdot C_{k_i}^2=p\cdot\dfrac{k_i(k_i-1)}{2} E[ei]=p⋅Cki2=p⋅2ki(ki−1)
E [ C i ] = 2 E [ e i ] k i ( k i − 1 ) = p ⋅ k i ( k i − 1 ) k i ( k i − 1 ) = p = k ‾ n − 1 ≈ k ‾ n E[C_i]=\dfrac{2E[e_i]}{k_i(k_i-1)}=\dfrac{p\cdot k_i(k_i-1)}{k_i(k_i-1)}=p=\dfrac{\overline{k}}{n-1}\approx\dfrac{\overline{k}}{n} E[Ci]=ki(ki−1)2E[ei]=ki(ki−1)p⋅ki(ki−1)=p=n−1k≈nk
random graph的clustering coefficient很小,如果我们保持平均度数 k k k 不变、增大图尺寸(指固定 p = k ⋅ 1 / n p=k\cdot 1/n p=k⋅1/n), C C C 会随图尺寸 n n n 减小。

- connected components
随着 p p p 从0到1变化,CC会出现如图中数轴所示的变化8 情况。
k ‾ = 2 E / n \overline{k}=2E/n k=2E/n
p = k ‾ / ( n − 1 ) p=\overline{k}/(n-1) p=k/(n−1)
k ‾ = 1 − ϵ \overline{k}=1-\epsilon k=1−ϵ 时所有CC的尺寸都是 Ω ( log n ) \Omega(\log{n}) Ω(logn)
k ‾ = 1 + ϵ \overline{k}=1+\epsilon k=1+ϵ 时出现一个 Ω ( n ) \Omega(n) Ω(n) 的CC,其他CC的尺寸还是 Ω ( log n ) \Omega(\log{n}) Ω(logn),每一个节点都至少期望有一条边

这种平均度数在1上下会突然出现largest connected component的转变被称为phase transition9 behavior,如图所示,平均度数达到3的时候已经几乎所有节点都属于largest connected component了:
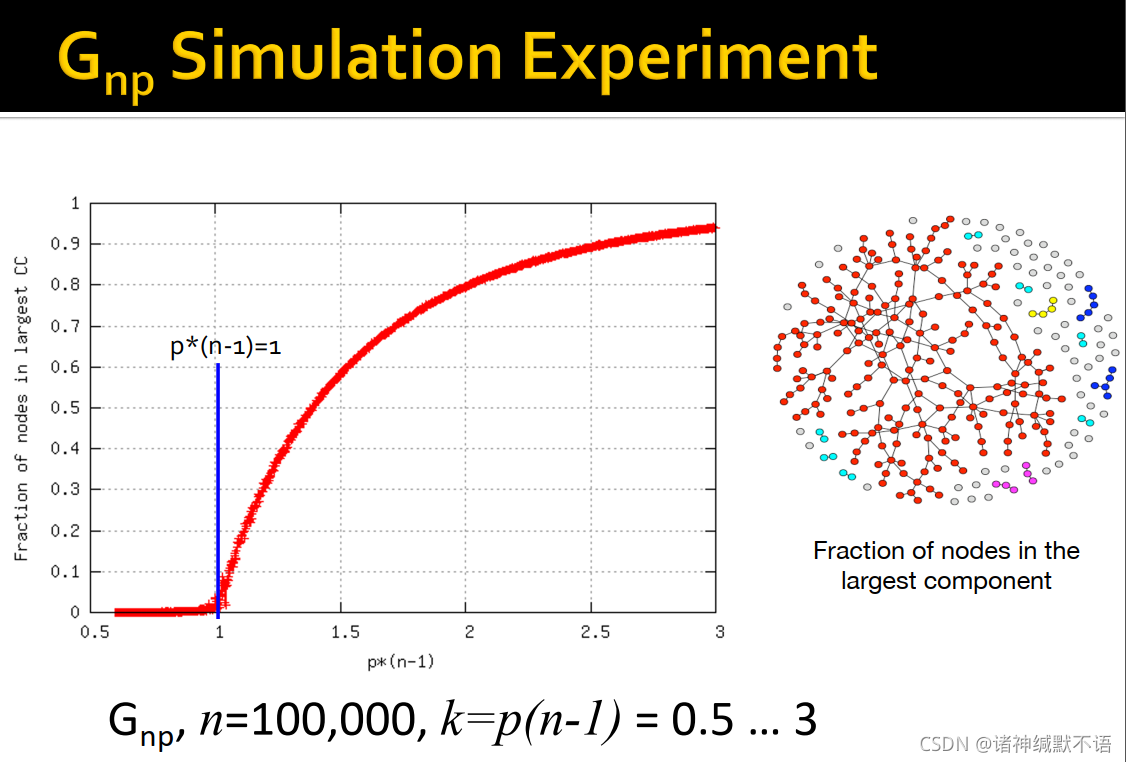
-
G
n
p
G_{np}
Gnp 的degree distribution,clustering coefficient和connectivity:

- 定义图
G
(
V
,
E
)
G(V,E)
G(V,E) 上的概念expansion10
α
\alpha
α:对任意节点子集
S
S
S,伸出
S
S
S 的边数(如图所示,指
S
S
S 和
V
\
S
V\backslash S
V\S 之间的边)大于等于
α
⋅
min
(
∣
S
∣
,
∣
V
\
S
∣
)
\alpha\cdot\min(|S|,|V\backslash S|)
α⋅min(∣S∣,∣V\S∣)(这个
min
\min
min 只是考虑到
∣
S
∣
|S|
∣S∣ 超过
1
2
∣
V
∣
\frac{1}{2}|V|
21∣V∣ 的可能性,如果
∣
S
∣
|S|
∣S∣ 是小部分的话,可以直接大于等于
α
∣
S
∣
\alpha|S|
α∣S∣)
英文原文:if ∀ S ⊆ V \forall S\subseteq V ∀S⊆V: # of edges leaving S ≥ α ⋅ min ( ∣ S ∣ , ∣ V \ S ∣ ) S\geq\alpha\cdot\min(|S|,|V\backslash S|) S≥α⋅min(∣S∣,∣V\S∣)
或等价于: α = min S ⊆ V # edges leaving S min ( ∣ S ∣ , ∣ V \ S ∣ ) \alpha=\min\limits_{S\subseteq V}\dfrac{\#\ \text{edges leaving S}}{\min(|S|,|V\backslash S|)} α=S⊆Vminmin(∣S∣,∣V\S∣)# edges leaving S

- expansion是用来衡量鲁棒性的:为了disconnect
l
l
l 个节点(让一个CC中
l
l
l 个节点不再属于这个CC),需要割断至少
α
⋅
l
\alpha\cdot l
α⋅l 条边。
(为什么是 l l l 而不是 min ( l , n − l ) \min(l,n-l) min(l,n−l)呢,因为 n − l n-l n−l 要是比 l l l 还小这就不太对劲了,就不是这 l l l 个节点被disconnect了而是对面被disconnect了对吧……在上文也说了一般这部分是小部分,所以可以直接用 l l l 的)
如图所示,expansion越低的图越容易被disconnect。而社交网络就是在社区11内部expansion高,在社区之间expansion低:
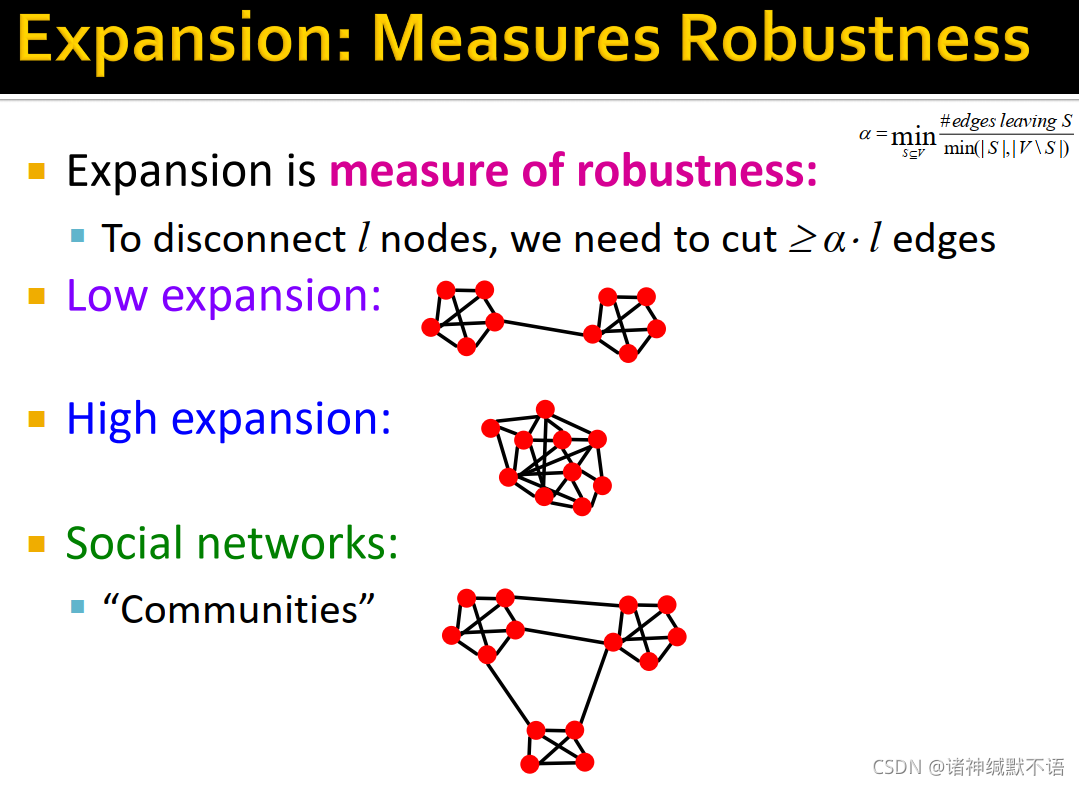
- random graphs的expansion:
事实:对于一个有 n n n 个节点,expansion为 α \alpha α 的图,节点对间存在长度为 O ( ( log n ) / α ) O((\log{n})/\alpha) O((logn)/α) 的路径。
对随机图 G n p G_{np} Gnp:对 log n > n p > c , d i a m ( G n p ) = O ( log n / log ( n p ) ) \log{n}>np>c,\ diam(G_{np})=O\big(\log{n}/\log{(np)}\big) logn>np>c, diam(Gnp)=O(logn/log(np))12
如图所示,随机图有很好的expansion,所以BFS需要经对数级步数访问所有节点:
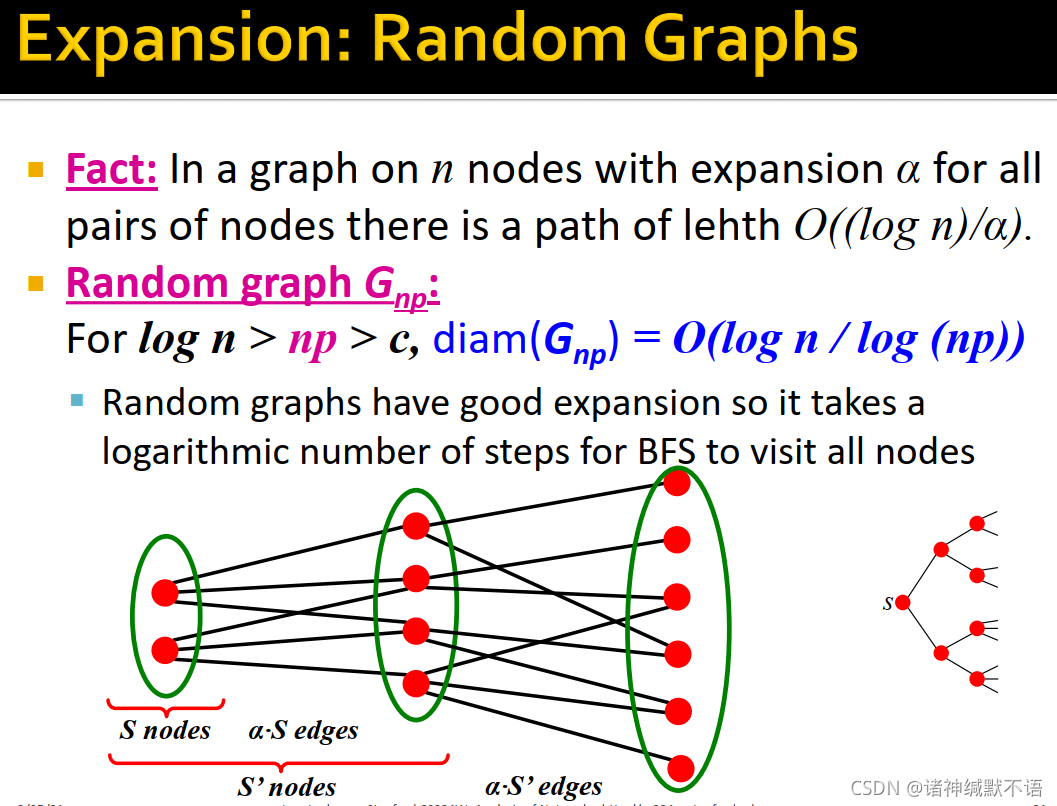
- 如果我们固定
k
‾
=
n
p
\overline{k}=np
k=np,我们就可以得到图节点间最长的最短路径
d
i
a
m
(
G
n
p
)
=
O
(
log
n
)
diam(G_{np})=O\big(\log{n}\big)
diam(Gnp)=O(logn),Erdös-Renyi Random Graphs可以让节点在迅速增加时,shortest path length仍然增长很慢,如图所示:
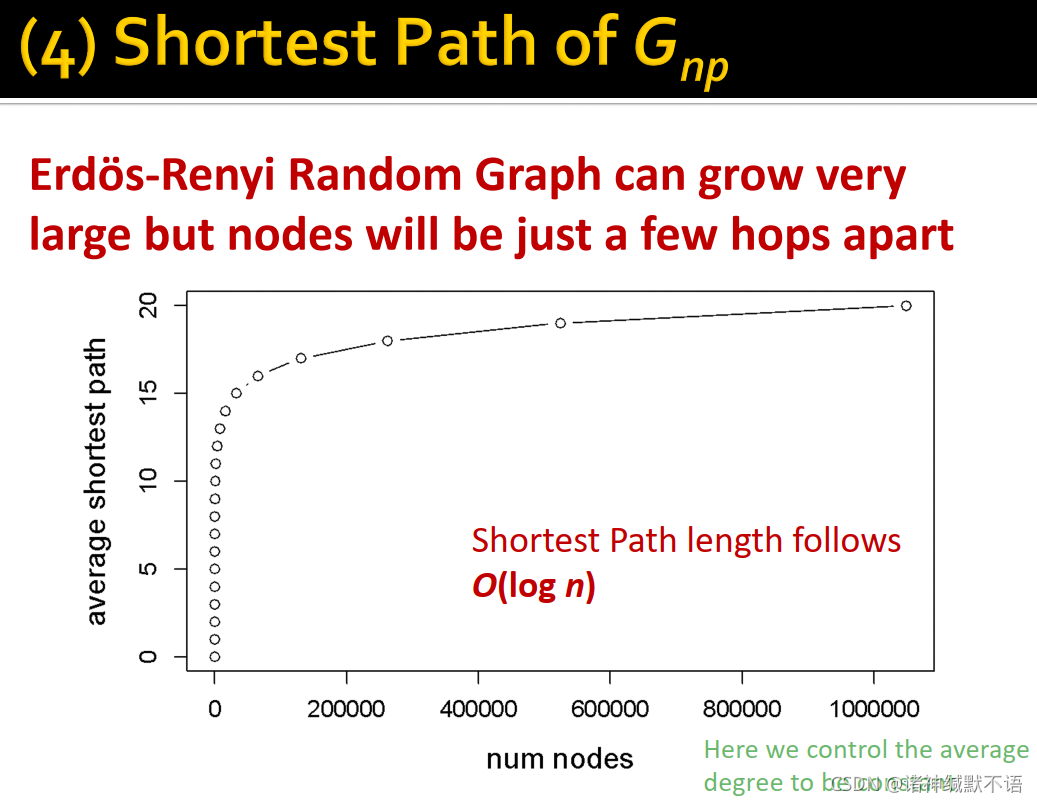
- degree distribution
- 得到
G
n
p
G_{np}
Gnp 上的所有属性后,与MSN的属性对比,发现:
MSN的degree distribution很偏,但 G n p G_{np} Gnp 是高斯分布。不相似。
两种图的avg. path length都很短。相似。
G n p G_{np} Gnp 的聚集系数远小于MSN,失去了局部结构。不相似。
MSN绝大多数节点都属于GCC, G n p G_{np} Gnp 在 k ‾ > 1 \overline{k}>1 k>1(示例中约等于14)时也存在GCC。在存在GCC方面相似,但真实图中的giant component并不通过phase transition9出现。
可见真实世界的图不是随机图。
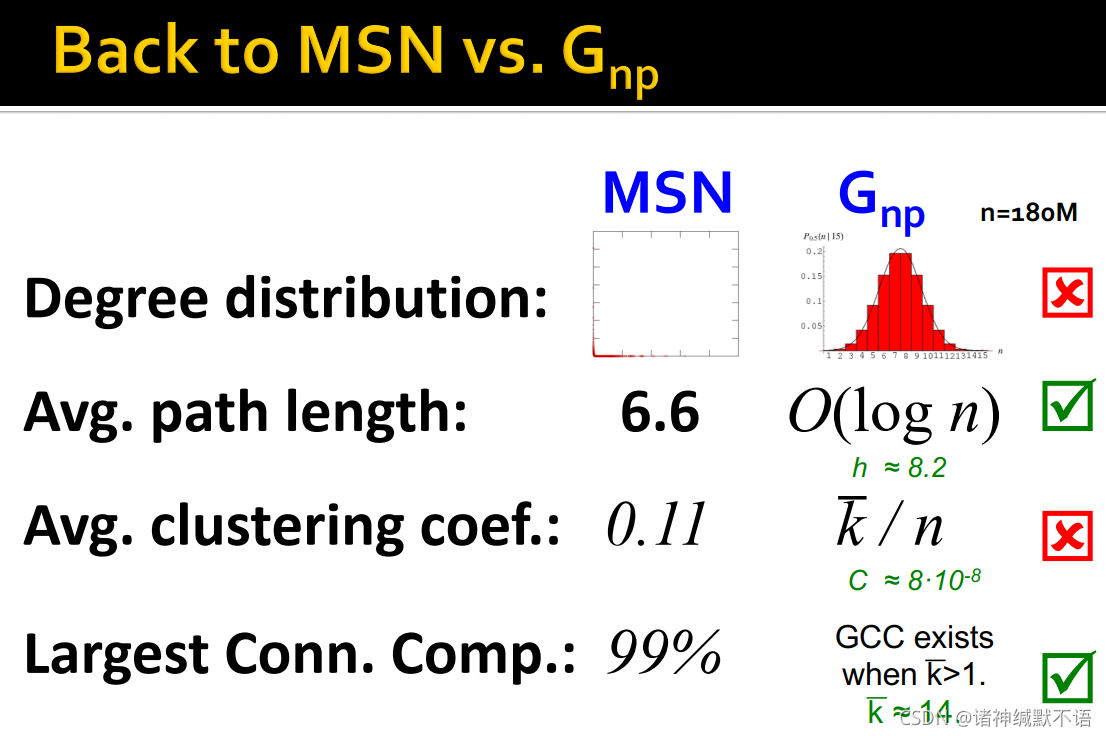

4. The Small-World Model
- 发明小世界模型的动机:我们有高聚集系数、高diameter的regular lattice graph,也有低聚集系数、低diameter的
G
n
p
G_{np}
Gnp 随机图,但真实图是低diameter、高聚集系数的,我们希望找到一个能生成这种图的模型。

- 在同节点数、同平均度数的随机图的对比下,各种真实图都展示出了类似的特质:

- 在随机图和regular lattice graph中,这两个属性间却存在着矛盾:
由于expansion的缘故,在固定平均度数时,随机图中的short paths为 O ( log n ) O(\log{n}) O(logn) 长但聚集系数也很低。
而有局部结构的网络regular lattice graph有很多社交网络中常有的triadic closure(我朋友的朋友还是我的朋友),即高聚集系数,但diameter也很高。
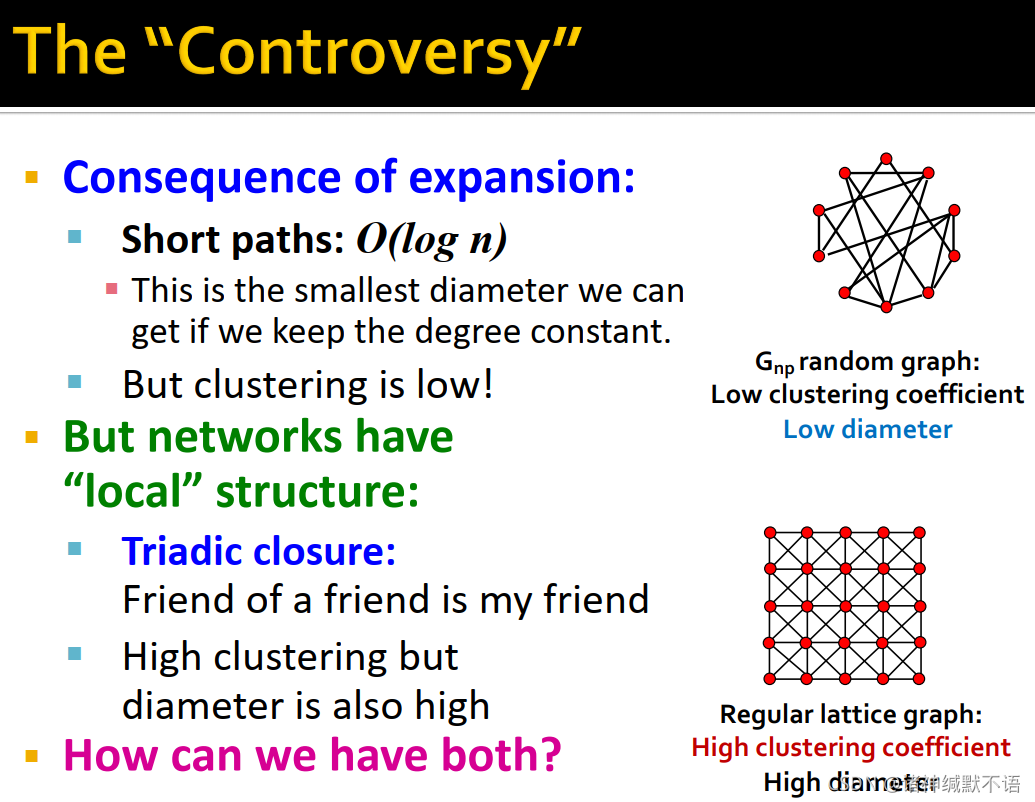
- 我们希望在两种图间进行插值,得到结合二者特性,高聚集系数、低diameter的small-world graph:
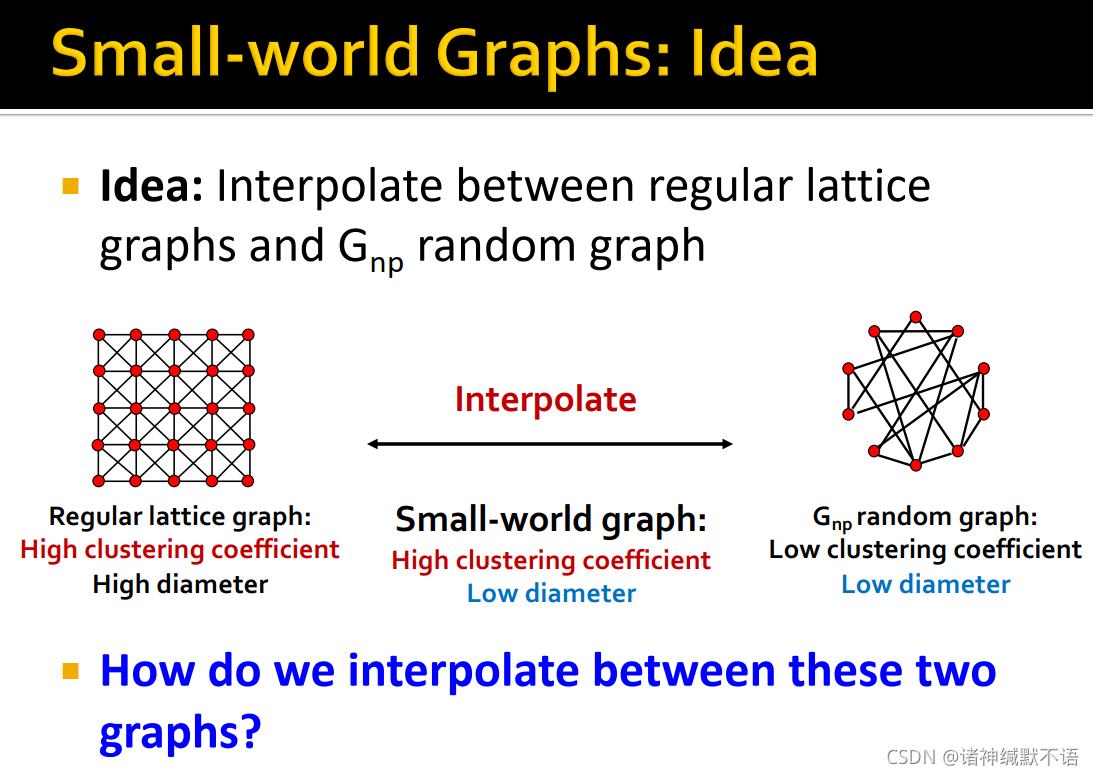
- small-world model13 的方法:
- 从一个低维regular lattice(这里表示成ring)开始,这个图有很高的聚集系数和diameter。
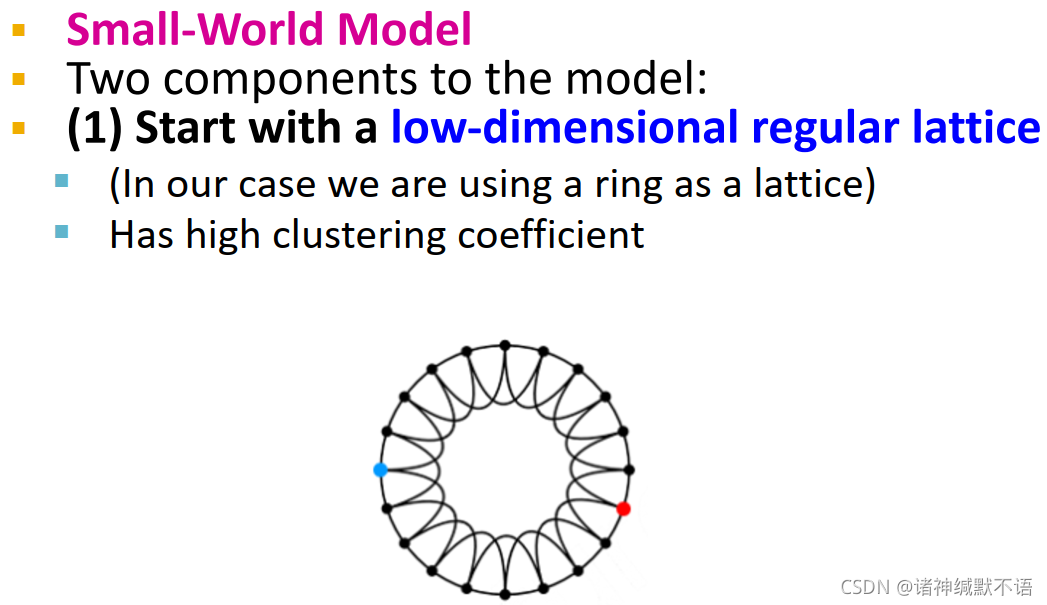
- rewire:新增随机捷径,将本来较远的部分连接起来
对每个边,以 p p p 的概率将一端移到一个随机节点上
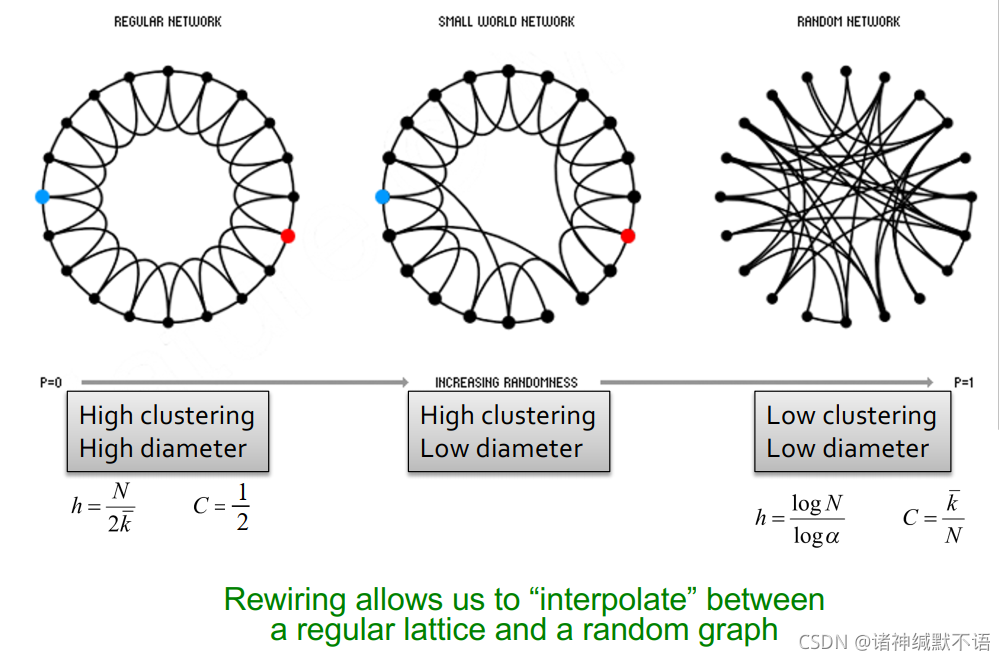 (但这些公式是怎么得到的,我并不知道)
(但这些公式是怎么得到的,我并不知道)
- 从一个低维regular lattice(这里表示成ring)开始,这个图有很高的聚集系数和diameter。
- 在下图中绿色箭头指向的区域,就是小世界模型适宜的参数区域:(能够得到这个合适区域的直觉理解:需要很多随机性才能破坏聚集系数,但仅需一点随机性就能产生捷径,所以就能得到高聚集系数、低diameter的中间的图)
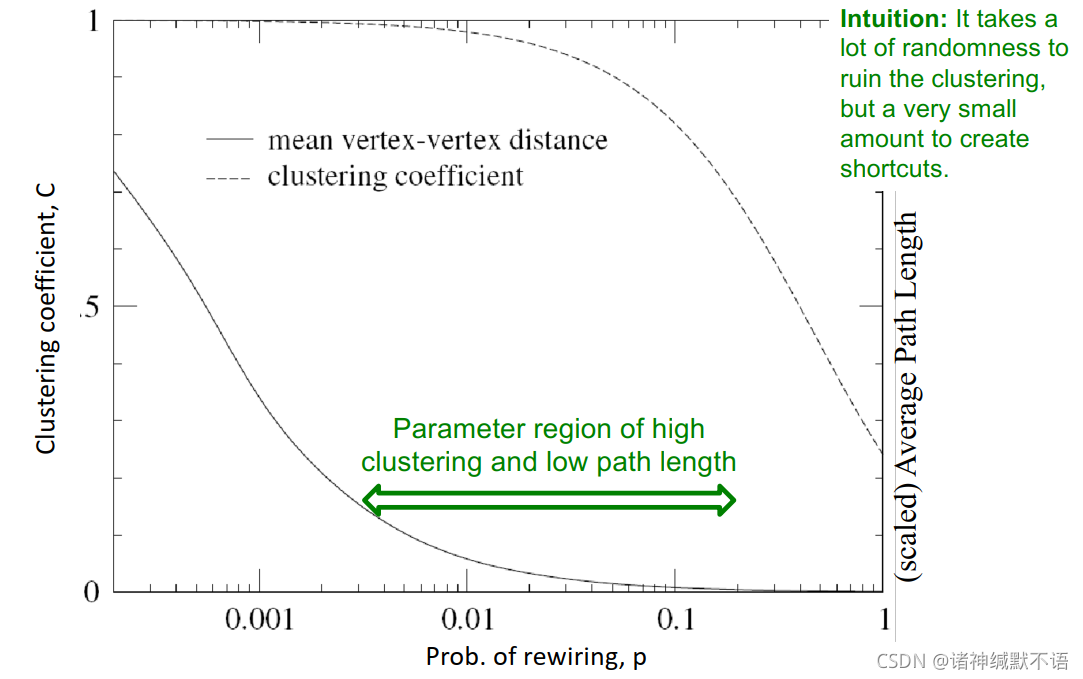
- 总结14:
小世界模型提供了一个在clustering和small-world(指diameter小)之间交互的视角,捕获到了真实图的结构,解释了真实图中的高聚集系数,但其度数分布仍然并不符合真实图的情况。

5. Kronecker Graph Model
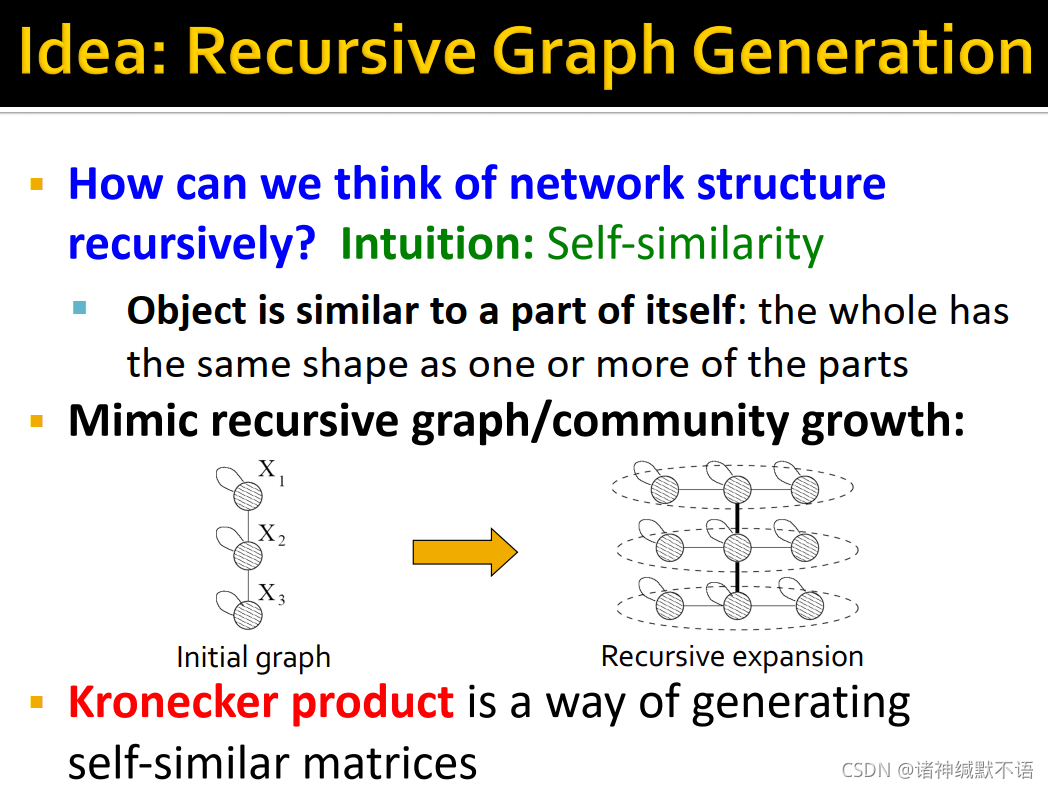
- Kronecker Graph Model的idea:迭代式的图生成
self-similarity:物体自身总是与其部分相似。我们模仿图/社区的迭代式增长,如图所示不断重复同样的图的生成过程。
Kronecker product克罗内积就是一种生成self-similar矩阵的方式。
- Kronecker graph15:从小矩阵(
K
K
K)开始,通过克罗内积
⊗
\otimes
⊗ 生成大的邻接矩阵
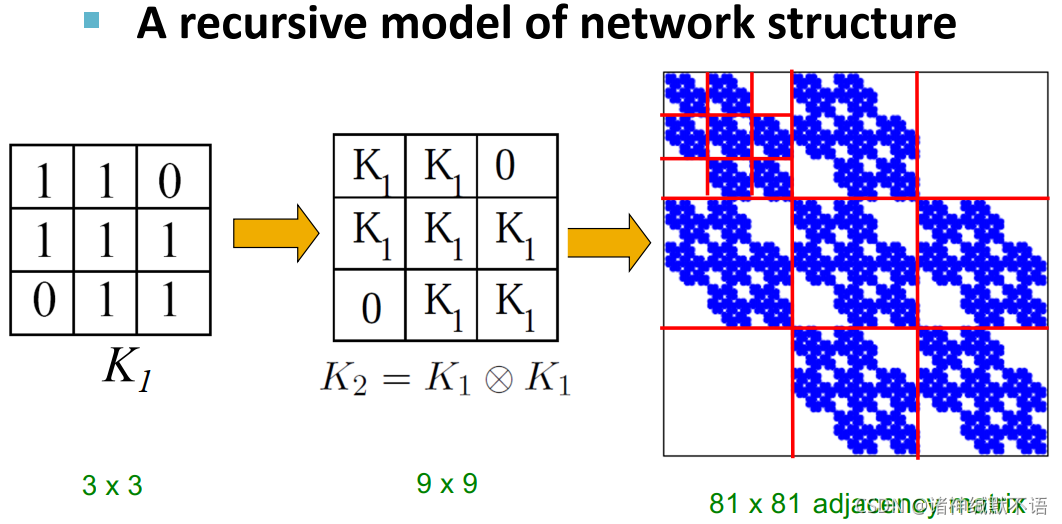 (这个东西看起来有点分形的感觉噢……但是这个self-similar的是邻接矩阵,其实也不是图本身)
(这个东西看起来有点分形的感觉噢……但是这个self-similar的是邻接矩阵,其实也不是图本身) - 克罗内积定义:
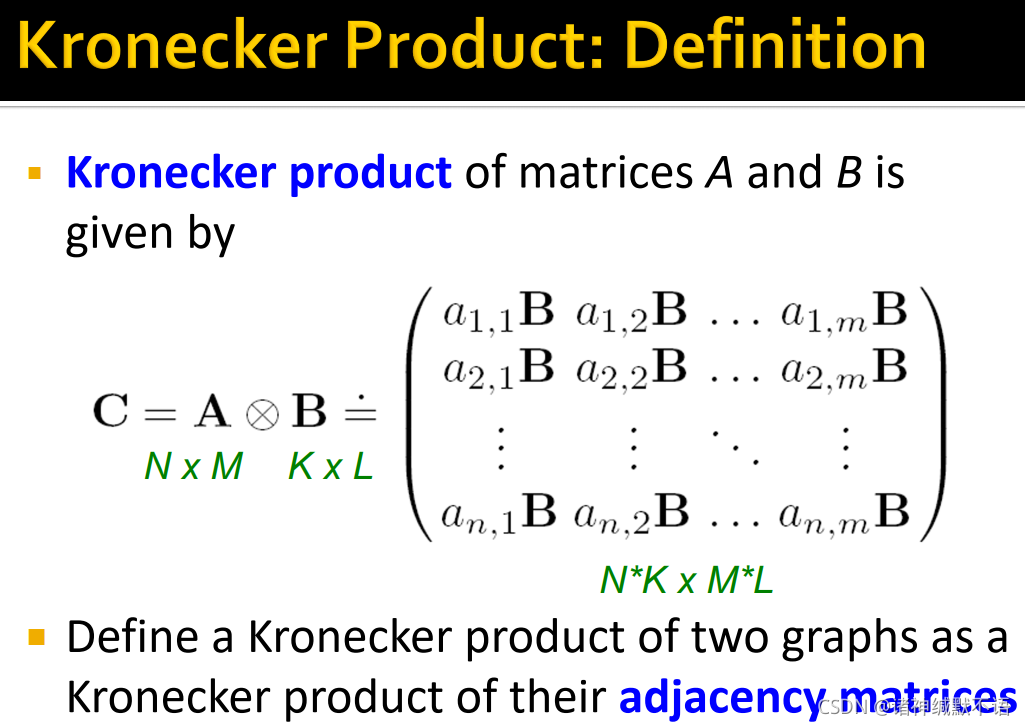
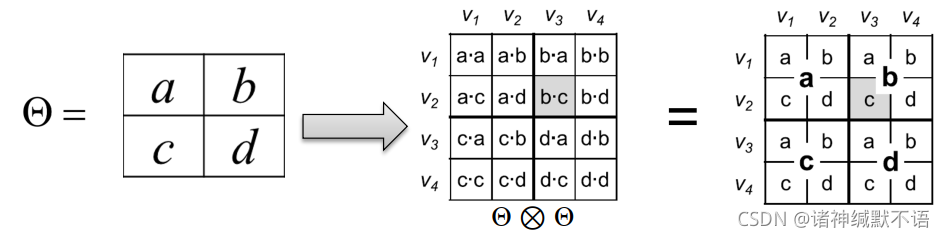
矩阵 A A A 和 B B B 的克罗内积
C = A ⊗ B = ( a 1 , 1 B a 1 , 2 B … a 1 , m B a 2 , 1 B a 2 , 2 B … a 2 , m B ⋮ ⋮ ⋱ ⋮ a n , 1 B a n , 2 B … a n , m B ) C=A\otimes B=\begin{pmatrix} a_{1,1}B & a_{1,2}B & \ldots & a_{1,m}B \\ a_{2,1}B & a_{2,2}B & \ldots & a_{2,m}B \\ \vdots & \vdots & \ddots & \vdots \\ a_{n,1}B & a_{n,2}B & \ldots & a_{n,m}B \end{pmatrix} C=A⊗B=⎝⎜⎜⎜⎛a1,1Ba2,1B⋮an,1Ba1,2Ba2,2B⋮an,2B……⋱…a1,mBa2,mB⋮an,mB⎠⎟⎟⎟⎞
(其中 A A A 的尺寸为 [ N , M ] [N,M] [N,M], B B B 的尺寸为 [ K , L ] [K,L] [K,L], C C C 的尺寸为 [ N ∗ K , M ∗ L ] [N*K,M*L] [N∗K,M∗L])
图的克罗内积是对两个图的邻接矩阵求克罗内积,以其值作为新图的邻接矩阵。
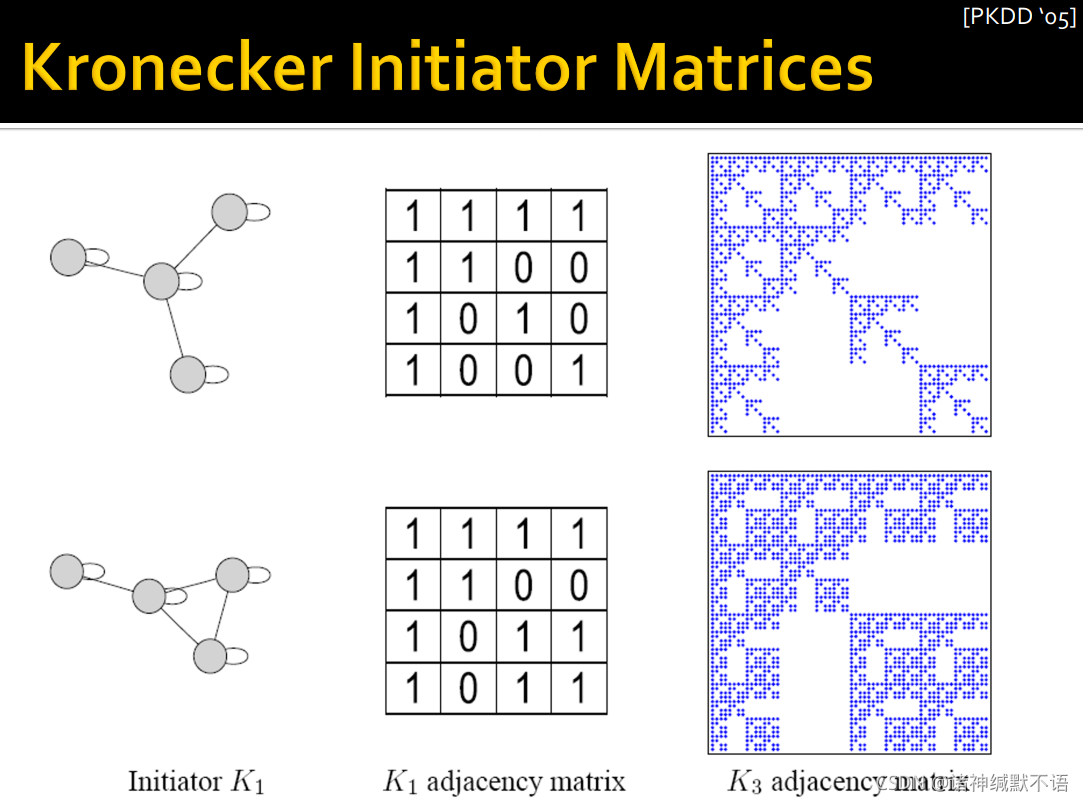
- Kronecker graph就通过对initiator matrix
K
1
K_1
K1 连续迭代做克罗内积,逐渐增长式得到最终结果(也可以用多个尺寸、元素都可以不同的initiator matrics):

- Kronecker initiator matrices示例:
- stochastic Kronecker graphs
步骤如图所示:- 创建尺寸为 [ N 1 , N 1 ] [N_1,N_1] [N1,N1] 的probability matrix Θ 1 \Theta_1 Θ116
- 计算得到 k k k 阶克罗内积 Θ k \Theta_k Θk
- 生成实例矩阵
K
k
K_k
Kk:对
Θ
k
\Theta_k
Θk 中的每个元素
p
u
v
p_{uv}
puv,按概率选择是否生成
K
k
K_k
Kk 对应的元素1(也就是按概率
p
u
v
p_{uv}
puv 生成对应的边
(
u
,
v
)
(u,v)
(u,v))
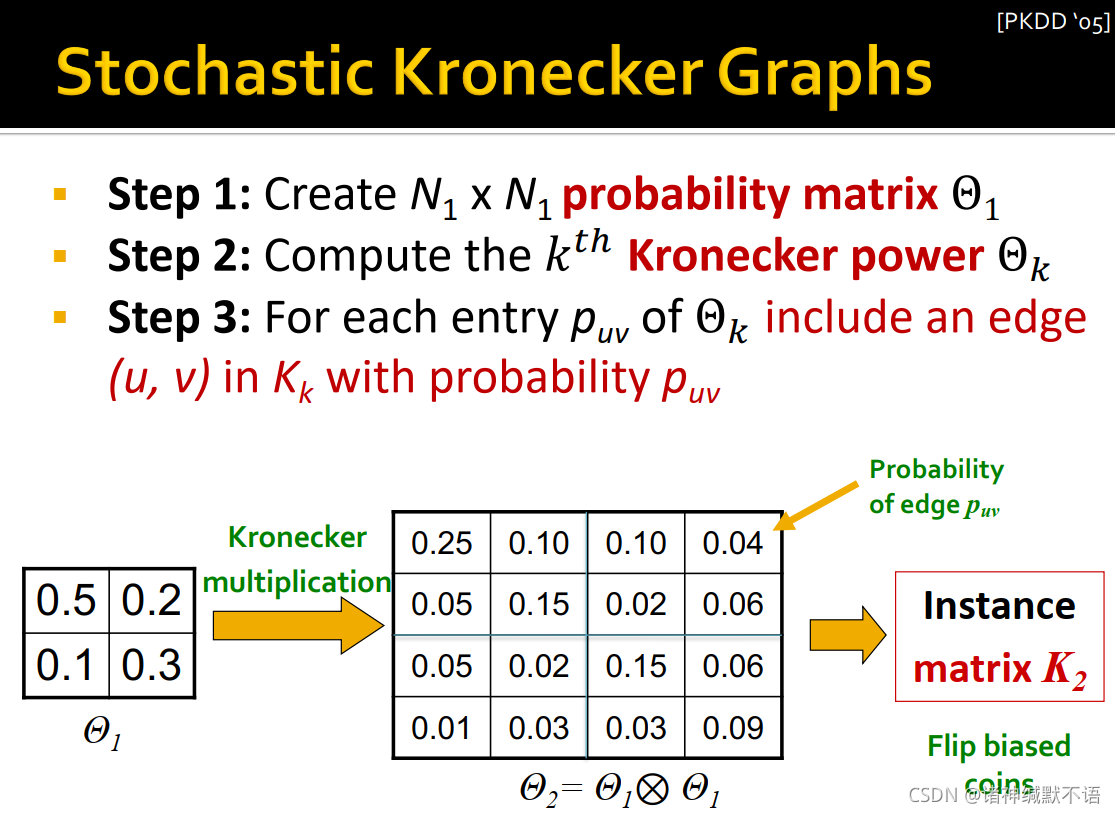
- Generation of Kronecker Graphs
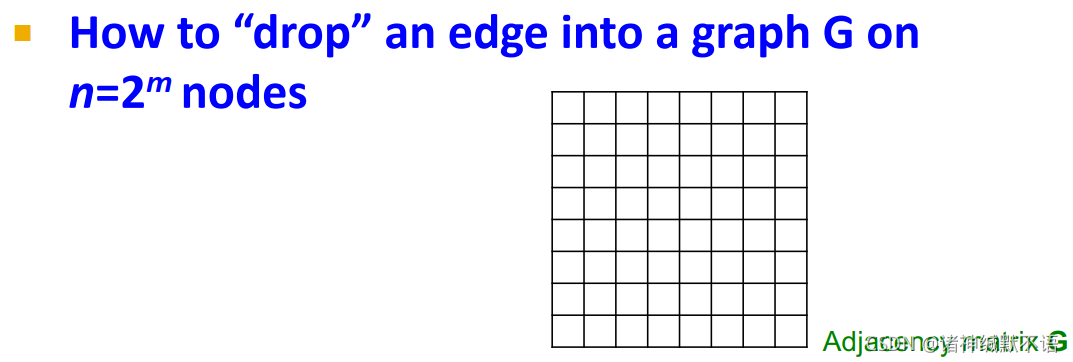
根据上面提到的方法,如果想要生成一个有向的stochastic Kronecker graph,需要计算 n 2 n^2 n2 次概率,太慢。
利用Kronecker graphs的递归特性,我们还有一种更快的方法ball dropping / edge dropping:

- 对Kronecker图的概率的理解,如图所示,既可以按照中间那种算出每一个元素的概率然后计算每一条边是否存在,也可以理解为右边那种形式,就很多层,每一层都是原
Θ
\Theta
Θ,最底层就是每个元素就是最终Kronecker graph的元素:
- 快速Kronecker generator algorithm:从一个尺寸为
[
2
,
2
]
[2,2]
[2,2] 的矩阵开始,迭代
m
m
m 次,就能得到一个节点数为
n
=
2
m
n=2^m
n=2m 的图
G
G
G。
如图所示,一种比较快的方式是按层(从大象限到小象限)依次按概率选择一个象限,a→d→a/b/c/d,像这样选到最底层的一个格子,即邻接矩阵的一个元素、图的一条边,就相当于按照原来的边生成概率来建立新的边。
这样的问题就是可能会出现边冲突,也就是多次选择到了同一个格子。发生这种情况就直接忽略并再选一次。


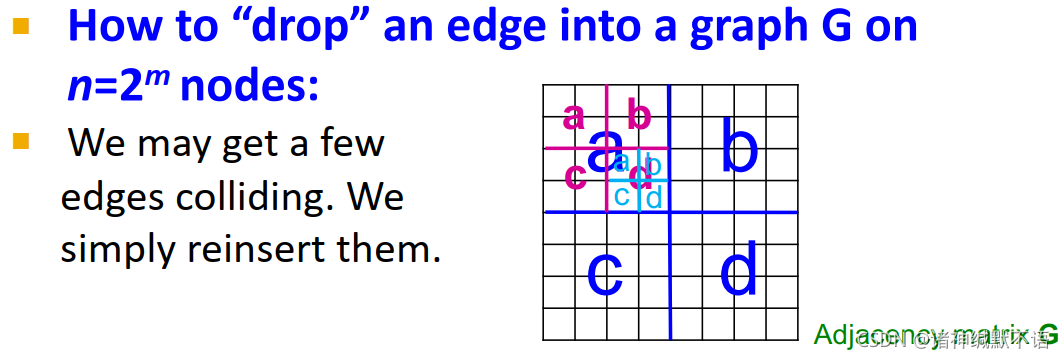
- Fast Kronecker generator algorithm中插入一条有向边的算法:
- 对矩阵进行归一化(就让它的元素总和为1,也就是变成概率矩阵)。
- 逐层根据概率选择象限并挪动对应的坐标。在选到最后一层时就把这条边添上。

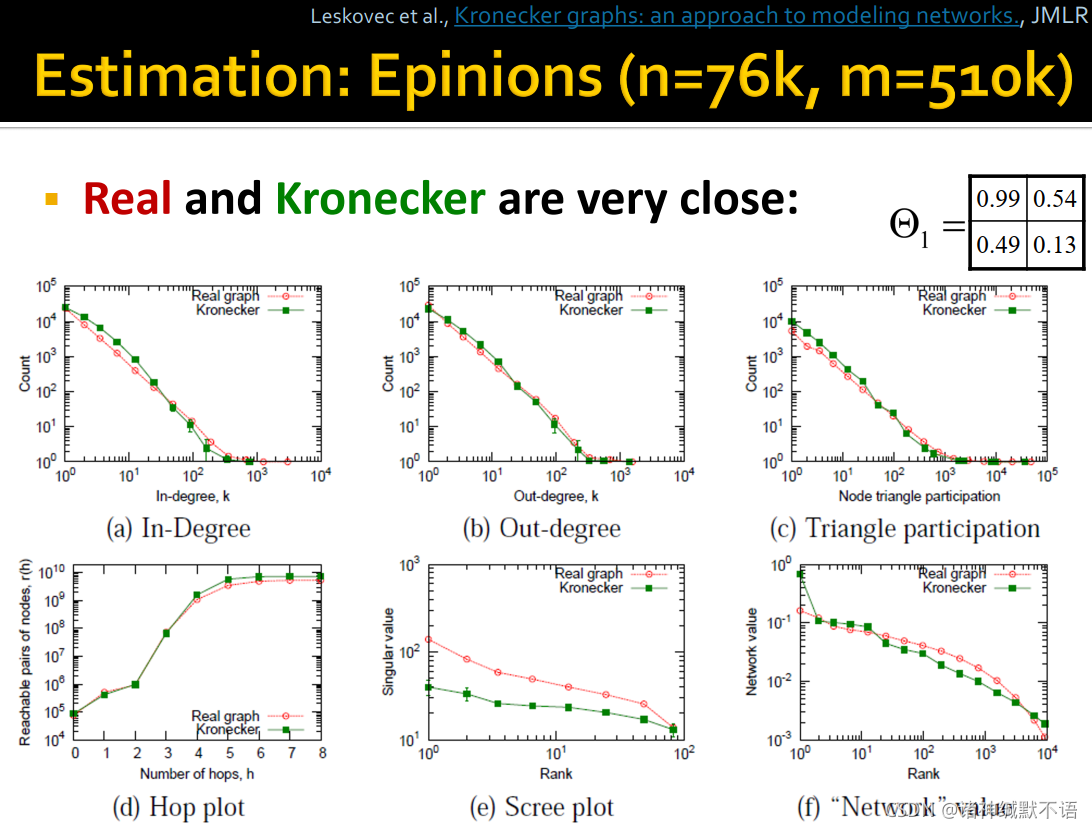
- 在Epinions17图上的估计结果18
如图所示,用 Θ 1 \Theta_1 Θ1 作为initiator matrix生成的Kronecker graph在各项属性19上都与真实图的类似:
6. 本章总结
介绍了传统的图生成模型,每种模型都对图生成过程提出了不同的先验假设。
下一章将介绍直接从原始数据学习图生成过程的深度图生成模型。

7. 其他正文及脚注未列出的参考资料
- CS244W: Machine Learning with Graphs (2) ——图的性质和随机图模型_lssx0817的博客-CSDN博客
- cs224w 图神经网络 学习笔记(二)Properties of Networks and Random Graph Models_喵木木的博客-CSDN博客
- 关于ER图:
在图论的数学理论部分中,ER模型(Erdős–Rényi model)可指代两个密切相关的随机图生成模型中的任意一个。这两个模型的名称来自于数学家Paul Erdős(保尔•厄多斯)和Alfréd Rényi(阿尔弗烈德•瑞利),他们在1959年首次提出了其中一个模型,而另一个模型则是Edgar Gilbert(埃德加•吉尔伯特)同时并且独立于Erdős和Rényi提出的。在Erdős和Rényi的模型中,节点集一定、连边数也一定的所有图是等可能的;在Gilbert的模型中,每个连边存在与否有着固定的概率,与其他连边无关。在概率方法中,这两种模型可用来证明满足各种性质的图的存在,也可为几乎所有图的性质提供严格的定义。
- 图机器学习 2.2-2.4 Properties of Networks, Random Graph - 云+社区 - 腾讯云
- 关于克罗内图:
直接用initiator matrix进行克罗内积后得到的克罗内图会出现重复性,因此选择引入随机性(stochastic Kronecker graph)。
尽管到目前为止讨论的Kronecker结构产生的图具有一系列所需的特性,但其离散性质在程度和频谱数量上会产生“阶梯效应”,这仅仅是因为单个值具有较大的多重性。例如,图邻接矩阵的特征值的度分布和分布以及主要特征向量分量的分布(即“网络”值)都受此影响。这些数量是多重分布的,这导致具有多个重复的单个值。下图说明了阶梯效应(这部分来自Jure等人的论文18)
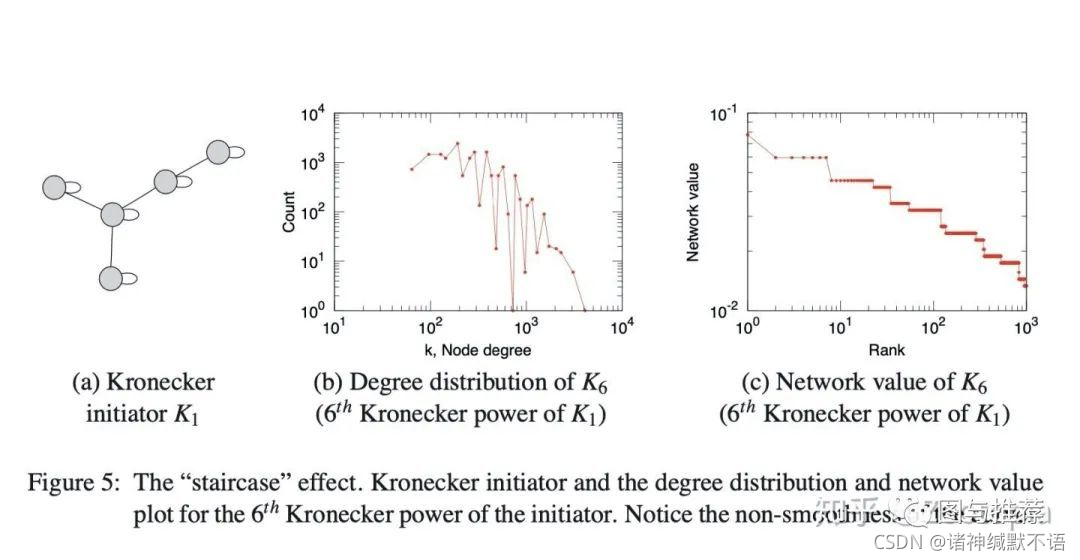
会发现得到的图邻近矩阵的结构是很规则的(因为邻近矩阵的元素都是1或者0),
类似于具有规则结构的网格一样,这样的当然好(利于我们分析),
可是这样的图结构就很难capture真实复杂网络的信息了,那么要怎么办?-----答案是引入随机性!
这里在初始矩阵引入随机性的意思是:放松初始矩阵–邻近矩阵只有0或者1元素的条件,而是可以有[0,1]之间的元素,也就是
(1)初始矩阵的每个元素反应的是特定边出现的概率
(2)对初始矩阵进行Kronecker积运算,以获得较大的随机邻接矩阵,在该矩阵中,大型矩阵的每个元素数值再次给出了特定边出现在大图中的概率,这样的随机邻接矩阵定义了所有图的概率分布
在随机克罗内积的矩阵中,每条边的生成概率就是 k k k 阶克罗内积矩阵中元素的生成概率,也就是 k k k 层initiator matrix中选择到对应象限的概率的累乘结果:
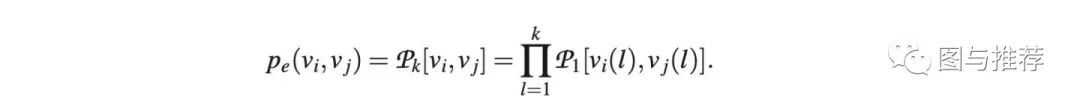
- 关于克罗内图:
我之前撰写的课程笔记:
cs224w(图机器学习)2021冬季课程学习笔记1 Introduction; Machine Learning for Graphs_诸神缄默不语的博客-CSDN博客
cs224w(图机器学习)2021冬季课程学习笔记2: Traditional Methods for ML on Graphs_诸神缄默不语的博客-CSDN博客 ↩︎ ↩︎这是我根据理解自己扯的定义,大概是这么个意思,但是很可能不严格。有缘的话我再去看看严格定义。
另外就是还有一个weakly还是strongly的connected component概念,这里没区分。这个可以参考4。不过这点应该问题不大,在有向图上需要区分的话一般会说明的吧。 ↩︎就以我对图算法的理解,我觉得DFS应该也可以? ↩︎
我之前写的笔记:cs224w(图机器学习)2021冬季课程学习笔记1 Introduction; Machine Learning for Graphs_诸神缄默不语的博客-CSDN博客 和 cs224w(图机器学习)2021冬季课程学习笔记16 Community Detection in Networks_诸神缄默不语的博客-CSDN博客脚注16。
另一个来自Connectivity (graph theory) - Wikipedia的对weakly connected component的定义:A directed graph is called weakly connected if replacing all of its directed edges with undirected edges produces a connected (undirected) graph。对strongly connected component的定义:It is strongly connected, or simply strong, if it contains a directed path from u to v and a directed path from v to u for every pair of vertices u, v. ↩︎ ↩︎ ↩︎有个所谓的六度分隔理论就是跟这个差不多的嘛。 ↩︎
原论文:Erdös, P. and Rényi, A. (1960) On the Evolution of Random Graphs. Publication of the Mathematical Institute of the Hungarian Academy of Sciences, 5, 17-61.
原文下载地址是这个:http://snap.stanford.edu/class/cs224w-readings/erdos60random.pdf
或者这个:https://old.renyi.hu/~p_erdos/1960-10.pdf
在我之前的笔记里面也写过这个模型:cs224w(图机器学习)2021冬季课程学习笔记15 Frequent Subgraph Mining with GNNs_诸神缄默不语的博客-CSDN博客 ↩︎ ↩︎但要说为什么会这样,我也不知道。 ↩︎
phase transition在物理学中指相变(可参考:Phase transition - definition of phase transition by The Free Dictionary)。
而在图论中:
Erdős and Rényi (1960) showed that for many monotone-increasing properties of random graphs, graphs of a size slightly less than a certain threshold are very unlikely to have the property, whereas graphs with a few more graph edges are almost certain to have it. This is known as a phase transition (Janson et al. 2000, p. 103).(出处:Phase Transition – from Wolfram MathWorld)
上文所提及的文献:
Erdős, P. and Rényi, A. “On the Evolution of Random Graphs.” Publ. Math. Inst. Hungar. Acad. Sci. 5, 17-61, 1960.6
Janson, S.; Łuczak, T.; and Ruciński, A. “The Phase Transition.” Ch. 5 in Random Graphs. New York: Wiley, pp. 103-138, 2000. 原书:Janson, S., Luczak, T. and Rucinski, A. (2000) Random Graphs. John Wiley & Sons, New York. http://dx.doi.org/10.1002/9781118032718这本书我没有找到免费的正版下载渠道,所以就算了。 ↩︎ ↩︎其实expansion这部分我也没搞懂,我只是将我的不充分不完整的理解姑且先写出来了。 ↩︎
关于社交网络的社区相关概念,可参考我之前写的笔记:cs224w(图机器学习)2021冬季课程学习笔记16 Community Detection in Networks_诸神缄默不语的博客-CSDN博客 ↩︎
这一部分我是属实没有看懂……
fact我就没搞懂,我能理解这个每两层节点之间的边数是之前节点总和乘以 α \alpha α(这就是expansion的定义嘛),但这个 S ′ S' S′ 和 S S S 是啥关系?这怎么推出来的复杂度和路径长度?虽然我知道树的深度是对数,但是这个对数到底是怎么推的对数啊?
Jure在视频中说这部分可以从数学上证明,但是证明内容对本课程来说超纲了,所以建议自己看论文。我搜了一下相关的资料,一个是The expansion of random regular graphs,一个是Random Graph Dynamics。都没看,有缘再说吧。 ↩︎D. Wattts and S. Strogatz, Collective dynamics of ’small-world’networks, Nature
这个不是免费的,但是浙大买了,所以我能下。如有需要,一般建议通过学校购买、或淘宝或sci-hub等特殊方式获取,实在弄不到可以私聊我。 ↩︎总结一下小世界模型这部分我没搞懂的内容:
①regular lattice graph和随机图这两种图是可以拿一块比的吗,是两种图的节点个数和平均度数固定的意思吗?
②lattice和ring两种表示形式是等价的吗?如果是,画成ring那样子是因为nature的文章就是要好看吗?
③小世界模型的summary都是什么鬼,它怎么就提供了clustering和small-world之间交互的见解了?它怎么就解释真实图中的高聚集系数了,这一点不是本身就已知的事实吗?还有就是小世界模型的度数分布与实际情况不同,这事在直觉上很好想象,要是相同了才不好想象,但是这个又咋证明呢? ↩︎原论文应该是这篇:Realistic, Mathematically Tractable Graph Generation and Evolution, Using Kronecker Multiplication
另外还有一篇也是Jure他们写的克罗内图相关的论文:Scalable Modeling of Real Graphs using Kronecker Multiplication ↩︎这个probability matrix的元素只要是0到1之间的概率就行,不需要加总为1的。
这个随机克罗内图会让我联想到随机邻接矩阵,但这个显然不是,就它不是转移矩阵,它就是每个元素单独地作为一个概率这样,所以没有每行或每列或所有元素加总为1的要求。 ↩︎PPT里给的论文路径是谷歌学术的,我最近不方便上谷歌学术,所以就去找了个Jure主页下的文件路径:Leskovec et al., Kronecker graphs: an approach to modeling networks., JMLR
也可以通过acm下载:https://dl.acm.org/doi/10.5555/1756006.1756039 ↩︎ ↩︎里面有一些我没见过的属性我去找了一下资料,还没看:
triangle participation / TPR: Defining and evaluating network communities based on ground-truth
scree plot碎石图
也可以直接看原论文的解释。 ↩︎















 3351
3351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











