







本文属于huggingface.transformers全部文档学习笔记博文的一部分。
全文链接:huggingface transformers包 文档学习笔记(持续更新ing…)
本部分网址:https://huggingface.co/docs/transformers/master/en/glossary
本部分介绍transformers包相关的术语,包括transformers模型通用的术语,和用于PreTrainedModel输入参数的术语。
文章目录
1. 通用术语
原文档是用首字母顺序排序的,本文则按照我认为比较合适的顺序来排序。
- deep learning:用很多层神经网络的机器学习算法。
- RNN / recurrent neural network:一种用a loop over a layer1来处理文本的模型。
- self-attention:输入的每一个元素找它们应该attend to2的输入其他元素。
- token:一句话的一部分,如一个word,或一个subword(不常见的words常被拆分为subwords)
- transformer:基于self-attention的deep learning模型架构。
- seq2seq / sequence-to-sequence:通过输入生成一个新序列的任务(如翻译模型或摘要模型,如Bart或T5)。
- multimodal:结合文本与其他形式的输入(如图像等)的任务。
- NLP / natural language processing:处理文本相关任务的泛称。
- NLG / natural language generation:生成文本的任务(如talk with transformers3和文本翻译)
- NLU / natural language understanding:理解文本内容的任务(如对整片文章、个别词语的分类)
- pretrained model:在一些数据(如全部Wikipedia数据)上进行预训练后得到的模型。预训练模型包含一些self-supervised objective,如下面的MLM和CLM。
- MLM / masked language modeling / autoencoding models:一种预训练任务,模型看到的是corrupted文本。实现方式一般是随机mask一些tokens,然后预测原文。
- CLM / causal language modeling / autoregressive models:一种预训练任务,模型按顺序阅读文本,预测下一个单词。实现方式一般是阅读整句话,但用mask隐藏当前timestamp的未来tokens。
2. PreTrainedModel输入参数
每个模型都有所不同,但也有其相通之处。因此绝大多数模型的输入参数是相同的,以下就举例列举:
2.1 Input IDs
Input IDs一般情况下是唯一需要输入模型的参数。
是token的索引,token的数值表示,构建输入模型的sequence。
每种tokenizer的工作方式不同,但其根本工作机制是一样的。以BertTokenizer(一种WordPiece4 tokenizer)为例:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("mypath/bert-base-cased")
sequence = "A Titan RTX has 24GB of VRAM"
Tokenizer致力于将sequence分解成词表中含有的tokens(words或subwords,非word开头的token前会加上##符号):
tokenized_sequence = tokenizer.tokenize(sequence)
print(tokenized_sequence)
输出:['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
这些tokens可以被转换为模型可读的索引(IDs):
inputs = tokenizer(sequence)
tokenizer返回一个字典,包含所有使对应模型可以运行的必要参数。token索引就在键input_ids下:
encoded_sequence = inputs["input_ids"]
print(encoded_sequence)
输出:[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
注意tokenizer会自动添加模型需要的special tokens(如BertTokenizer对应的就是BertModel所需的special tokens),解码input ids后可以看出加了什么:
decoded_sequence = tokenizer.decode(encoded_sequence)
print(decoded_sequence)
输出:[CLS] A Titan RTX has 24GB of VRAM [SEP]
2.2 Attention mask
这一参数表明哪些tokens应该被模型attend to,哪些不应该。2
以如下两句一长一短的sequence为例:
sequence_a = "This is a short sequence."
sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
两个sequence编码得到的数值序列长度不同:
len(encoded_sequence_a), len(encoded_sequence_b)
输出为:(8, 19)
因此,我们无法直接就这样把它们合并为一个tensor,要么把短句pad up到长句长度(在调用Tokenizer时使用入参padding),要么把长句truncate down到短句长度(在调用Tokenizer时使用入参truncation)。
一般来说,这种情况下我们会pad短句,因为truncate会出现信息损失。我们一般只在长句超过最长限长的时候才选择truncate操作。
pad up的情况:
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True)
print(encoded_input)
输出:{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0], [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102], [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
可以看到短句的token后面被加了0(padding token),以使其与长句的token sequence等长,这样就可以直接转换为tensor。
attention mask是一个二元collection,标明用于pad的索引,模型就不会attend to2它们。这和模型预训练时的操作一致。对BertTokenizer,1表明其对应的值需要被attend to,0表明其对应的值是padded value。
另,在此介绍truncation时的情况:
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, truncation=True)
print(encoded_input)
输出:{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102], [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102], [101, 1327, 1164, 5450, 23434, 136, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1]]}
当同时将padding和truncation入参置True时,意为将输入进行padding,但所有token序列长度不超过max_length入参(即truncate到max_length长度)。如不设置max_length入参,则truncation入参不会起作用,且输出:
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
如设置max_length入参则:
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences,padding=True,truncation=True,max_length=10)
print(encoded_input)
输出:{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0], [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 102], [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]}
全部的padding和truncation可选操作及对应代码(本部分文档见https://huggingface.co/docs/transformers/master/en/preprocessing#everything-you-always-wanted-to-know-about-padding-and-truncation):
- 不作truncation
- 不作padding:
tokenizer(batch_sentences) - padding到batch中最长句的长度:
tokenizer(batch_sentences, padding=True)或tokenizer(batch_sentences, padding='longest') - padding到模型的
max_length5:tokenizer(batch_sentences, padding='max_length') - padding到
max_length入参值:tokenizer(batch_sentences, padding='max_length', max_length=42)
- 不作padding:
- truncation到模型的
max_length5- 不作padding:
tokenizer(batch_sentences, truncation=True)或tokenizer(batch_sentences, truncation=STRATEGY) - padding到batch中最长句的长度:
tokenizer(batch_sentences, padding=True, truncation=True)或tokenizer(batch_sentences, padding=True, truncation=STRATEGY) - padding到模型的
max_length5(相当于固定sequence长度):tokenizer(batch_sentences, padding='max_length', truncation=True)或tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY) - padding到
max_length入参值:不可能
- 不作padding:
- truncation到
max_length入参值- 不作padding:
tokenizer(batch_sentences, truncation=True, max_length=42)或tokenizer(batch_sentences, truncation=STRATEGY, max_length=42) - padding到batch中最长句的长度:
tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)或tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42) - padding到模型的
max_length5:不可能 - padding到
max_length入参值(相当于固定sequence长度):tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)或tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)
- 不作padding:
(怎么有他妈的那么多种情况)
2.3 Token Type IDs
又名segment IDs。
有些模型的目标是对句子对做分类或QA(question answering),如识别quora上两个问题是否相同,或做natural language inference (NLI) 任务。
这就需要两个sequences在同一input_id tensor中传入模型,这一操作一般用special tokens实现,如classifier ([CLS])或separator ([SEP]) tokens。
举例来说,BertTokenizer就这样构建2个sequences的输入:# [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
通过将sequences作为2个入参(而非像之前所做的那样,以list形式组合sequences为1个入参),即可自动生成这样的数据:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("mypath/bert-base-cased")
sequence_a = "HuggingFace is based in NYC"
sequence_b = "Where is HuggingFace based?"
encoded_dict = tokenizer(sequence_a, sequence_b)
decoded = tokenizer.decode(encoded_dict["input_ids"])
decoded
输出:'[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]'
有一些模型以这样的数据输入形式就已经可知sequences的开始和结束位置,但对Bert等其他模型来说,还需应用token type IDs,一种区分2个sequences的二元mask。
encoded_dict["token_type_ids"]
输出:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
在QA任务中,第一句就是context(值为0),为第二句就是question(值为1)。
文档中这句话我有点没搞懂啥意思:
我没试过XLNetModel,我也懒得现在就去下文件研究,我觉得意思应该是其他模型可能会使用不同的special tokens。
比如之前在huggingface.transformers速成笔记中使用的sshleifer/distilbart-cnn-12-6模型,就是用<s></s>来作为special tokens的:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mypath/distilbart-cnn-12-6")
encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.",
"We hope you don't hate it.")
print(encoding)
print()
print(tokenizer.decode(encoding['input_ids']))
输出:
{'input_ids': [0, 170, 32, 182, 1372, 7, 311, 47, 5, 8103, 10470, 6800, 34379, 5560, 4, 2, 2, 170, 1034, 47, 218, 75, 4157, 24, 4, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
<s>We are very happy to show you the 🤗 Transformers library.</s></s>We hope you don't hate it.</s>
但是值得注意的是这个返回值没有token_type_ids键,这个我还没有看,以后再做具体了解。
另外,注意这里tokenizer的两个入参都可以是字符串序列,效果就是:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("mypath/bert-base-cased")
encoding = tokenizer(["We are very happy to show you the 🤗 Transformers library.",
"We hope you don't hate it."],
["HuggingFace is based in NYC","Where is HuggingFace based?"])
encoding
输出:{'input_ids': [[101, 1284, 1132, 1304, 2816, 1106, 1437, 1128, 1103, 100, 25267, 3340, 119, 102, 20164, 10932, 2271, 7954, 1110, 1359, 1107, 17520, 102], [101, 1284, 2810, 1128, 1274, 112, 189, 4819, 1122, 119, 102, 2777, 1110, 20164, 10932, 2271, 7954, 1359, 136, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}

2.4 Position IDs
RNNs的token位置是自带的,但是transformers本身是无法知道token位置的(这个是transformers模型特点,看过这个模型的应该都能直接理解,这事实上也是模型的核心部分。我以后可能会写相应的模型详解博文),因此模型就需要用position IDs (position_ids)来识别每个token在sequence中的位置。
这是个可选的入参。如果不传入该参数,IDs将自动以absolute positional embeddings形式创建。
absolute positional embeddings在[0, config.max_position_embeddings - 1]中选择。有些模型使用其他形式的positional embeddings,如sinusoidal position embeddings或relative position embeddings。
2.5 Labels
这是个可选的入参。如果传入,模型将自行计算loss。这些labels是模型的期望预测值,模型会使用标准loss来计算真实预测值和期望值(labels)之间的loss。
labels因模型heads而有所不同,举例来说:
- 对sequence classification模型(如BertForSequenceClassification),labels应该是维度为
(batch_size)的、每个值是对应sequence的标签。 - 对token classification模型(如BertForTokenClassification),labels应该是维度为
(batch_size, seq_length)的、每个值是对应token的标签。 - 对masked language modeling模型(如BertForMaskedLM),labels应该是维度为
(batch_size, seq_length)的、每个值是对应token的标签(masked token的token ID,unmasked token的忽略(通常直接用-100)) - 对seq2seq模型(如BartForConditionalGeneration或MBartForConditionalGeneration),labels应该是维度为
(batch_size, tgt_seq_length)的、每个值是每个input sequence对应的target sequences。在训练的过程中,BART和T5模型都会自动生成合适的decoder_input_ids(见本文2.6部分介绍)和decoder attention masks,一般不需要手动提供。这跟Encoder-Decoder架构的模型不同,需要看特定模型的文档以了解所需labels的更多信息。
基础模型(如BertModel)不接受labels参数,因为它们是基础transformers模型,只输出特征。
2.6 Decoder input IDs
这个输入仅用于encoder-decoder模型(seq2seq任务,如翻译或摘要),包含了喂进decoder的input IDs,每个模型的构建形式都有所不同。
绝大多数encoder-decoder模型(如BART和T5)都会从labels入参中直接自动构建decoder_input_ids入参,因此建议在训练过程中传递labels入参。
2.7 Feed Forward Chunking
在transformers的每个residual attention block中,self-attention层后一般跟着两个前馈 (feed forward) 层。前馈层的intermediate embedding size一般会比模型的hidden size更大(其实我没太看懂这是啥意思,以后学好transformers模型再回来重新理解),如bert-base-uncased模型。
对于一个维度为[batch_size, sequence_length]的输入张量,用于储存intermediate feed forward embeddings(维度为[batch_size, sequence_length, config.intermediate_size])可能会占用大量内存。Reformer: The Efficient Transformer作者发现,计算过程与sequence_length这一维度无关,计算2个完整的前馈层,与计算把2个前馈层分别拆成[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n(其中n = sequence_length),并分别计算其output embeddings,再将其concat为[batch_size, sequence_length, config.hidden_size]。这一计算方式增加了用时,减少了空间占用,在数学上结果是相同的。
对于应用了apply_chunking_to_forward()函数的模型,chunk_size入参定义了同时计算的output embeddings的数目,定义时间复杂度和空间复杂度之间的trade-off。如chunk_size置0,就不做feed forward chunking操作。
这部分内容我没看懂,原论文我还没看,等我经继续学习后再回来做分析吧
总之这个应该指的是这张著名图,大概就是,是一层神经网络,但是有个回环(输回前一个timestamp的hidden state):
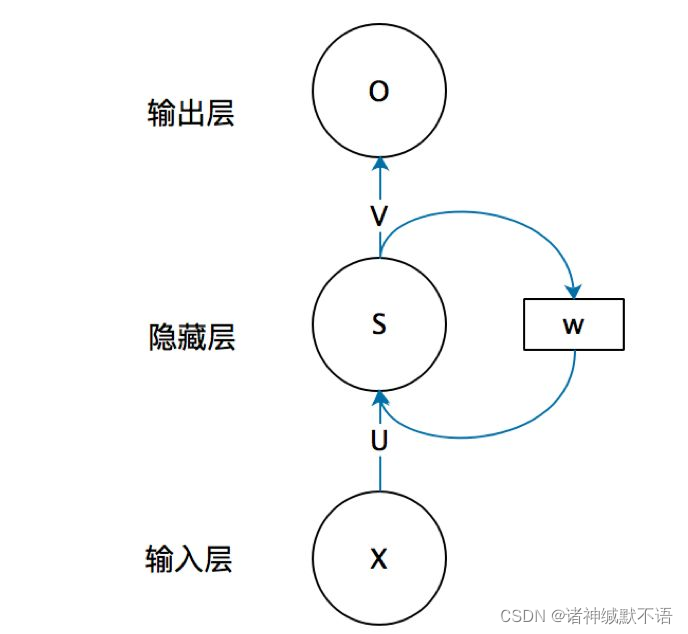
(图源:一文搞懂RNN(循环神经网络)基础篇 - 知乎) ↩︎这是个什么任务,我谷歌都谷歌不到,我怀疑是写错了。 ↩︎
原文档中此处给出的参考资料是:Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
这篇还没看,以后再看。
如下内容全部参考这篇科普文章,包括图片:WordPiece: Subword-based tokenization algorithm | Chetna | Towards Data Science:
大致来说,Wordpiece是一种subword-based tokenization algorithm(相对的是word级别和character级别)。
word-based tokenization的问题是词表太长,有大量OOV token,词语异义问题。character-based tokenization的问题是sequence太长,单独token无意义。subword-based tokenization会split不常用的单词,常用的算法有WordPiece, Byte-Pair Encoding (BPE)6, Unigram 和 SentencePiece。
WordPiece用于BERT, DistilBERT, Electra等语言模型中,有两种应用:bottom-up and top-bottom。原始的bottom-up方法是基于BPE的。BERT用的是top-bottom方法。本文将介绍bottom-up方法(即从characters聚合成pairs)。
WordPiece方法最早提出于Japanese and Korean Voice Search (Schuster et al., 2012)
BPE方法的介绍见6,以下对WordPiece的介绍在假设读者已经看过BPE部分介绍的基础上进行:
BPE方法的问题在于它可能有多种对同一单词的编码方式。
举例来说,这是一个subword tokens表,假设这就是一个小语料的词表: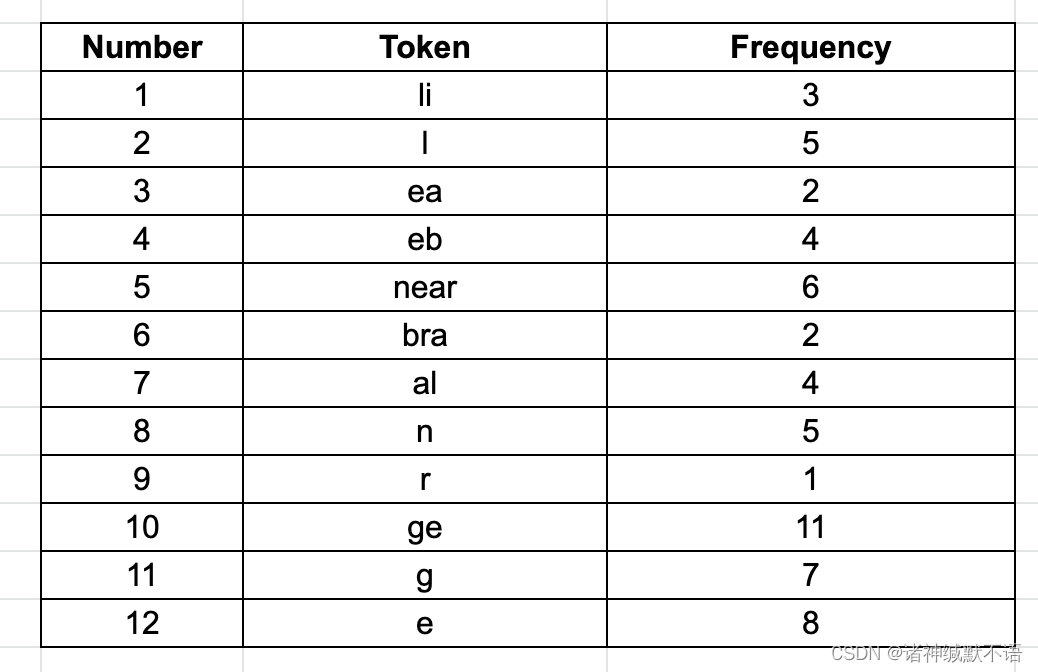
假设我们要tokenize短语linear algebra,我们有多种tokenize方式:
linear = li + near or li + n + ea + r
algebra = al + ge + bra or al + g + e + bra
有一种解决方法是,不像BPE只用频率,同时也考虑每一步特定byte-pair合并带来的影响。WordPiece和BPE的区别就在于每一步选择往词表中增加哪个byte-pair,WordPiece在每次迭代时会选择合并的likelihood增加最大的byte-pair。增加训练集的likelihood等同于找这样一个byte-pair,它的概率除以它的第一个token后面就是它的第二个token的概率
(这一段我其实没太看懂。我一开始以为是条件概率,后来看了资料,感觉意思应该是 P ( A B ) P ( A ) P ( B ) \frac{P(AB)}{P(A)P(B)} P(A)P(B)P(AB)。具体为什么要这么做,直觉上可以说是衡量合并tokens的价值,在理论上可以看这篇资料有他从信息论角度出发做的解释:7),所得的值比其他byte-pair都大。举例来说,如果es的概率比e的概率乘s的概率,要比其他byte-pair的大,那么我们就将es加入词表。
WordPiece的算法是迭代的(与BPE的类似,主要在第三步不同):
① 初始化word unit inventory(以characters为单位)
② 从①的word inventory中建立语言模型。
③ 从当前word inventory中合并2个unit为一个新unit,加入word inventory。这个新的word unit要是所有可能的word units中在增加到语言模型中后训练集的likelihood增加最多的。
④ 返回②,直至达到提前确定的word units总数限制或likelihood增加小于特定阈值。
WordPiece算法的计算代价较大(时间复杂度为 O ( K 2 ) O(K^2) O(K2),其中 K K K是当前word units数),每一次迭代都需要测试所有可能的byte-pair并建立语言模型。有一些加速tricks,如仅测试训练集中真实存在的byte-pair,仅测试有显著可能性是最好byte-pair的 (the ones with high priors) 那些byte-pairs(没说具体怎么做,我也还没查,不知道),每次迭代合并几个clustering steps(对一组不互相影响的pairs是有可能的)(没说具体怎么做,我也还没查,不知道)。
WordPiece也是贪心算法。
其他参考资料:WordPiece Tokenization - YouTube
本视频提及,WordPiece源代码未公开,因此只涉及在文献中讲述的内容。
视频中所写byte-pair的计算公式:
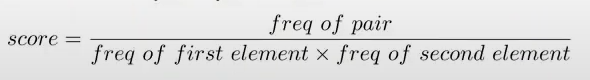
在视频中还画了WordPiece解码过程,直接从前到后遍历sequence,选择最长的可匹配的词表中的token即可。 ↩︎ ↩︎我觉得这个应该指的是Tokenizer的
model_max_length属性所对应的值。
验证依据见我撰写的另一篇博文:用huggingface.transformers微调预训练模型_诸神缄默不语的博客-CSDN博客 ↩︎ ↩︎ ↩︎ ↩︎我阅读的科普博文是:Byte-Pair Encoding: Subword-based tokenization | Towards Data Science 以下图片也出自该文。
大致来说,BPE是一种subword-based tokenization algorithm。
BPE用于GPT-2, RoBERTa, XLM, FlauBERT等语言模型。其中有些模型用space tokenization(应该是字面意思,就是英语用空格作为简单的分词方式)作为pre-tokenization method,有些用Moses, spaCY, ftfy提供的更先进的方法。
BPE是一种简单的数据压缩算法,将数据中最常用的byte pair(连续的两个字节)替换成数据中未出现的一个byte(注意下文一个byte指一个token)。最早提出于A New Algorithm for Data Compression。此博文转引BPE维百的示例:原数据aaabdaaabac,用Z替换aa,就得到了ZabdZabac;再用Y替换ab,就得到了ZYdZYac;再用X替换ZY,就得到了XdXac;自此就不能再继续压缩了。
NLP中用的BPE算法保证常用词在词典中是一个token,非常用词则被分割为2至多个subword tokens,这是符合subword-based tokenization思想4的。
以示例的形式讲解算法运行过程:
①假设我们有一个经过space tokenization后得到的语料单词和频率对应表:{“old”: 7, “older”: 3, “finest”: 9, “lowest”: 4}
②在每个单词后加上一个特殊token</w>(用于识别word边界。文中阐释了一些这个token如何重要的理由,我觉得这个比较明显,此处就略去),得到:{“old</w>”: 7, “older</w>”: 3, “finest</w>”: 9, “lowest</w>”: 4}
③接下来将所有词拆成characters和</w>token,计算其频率:
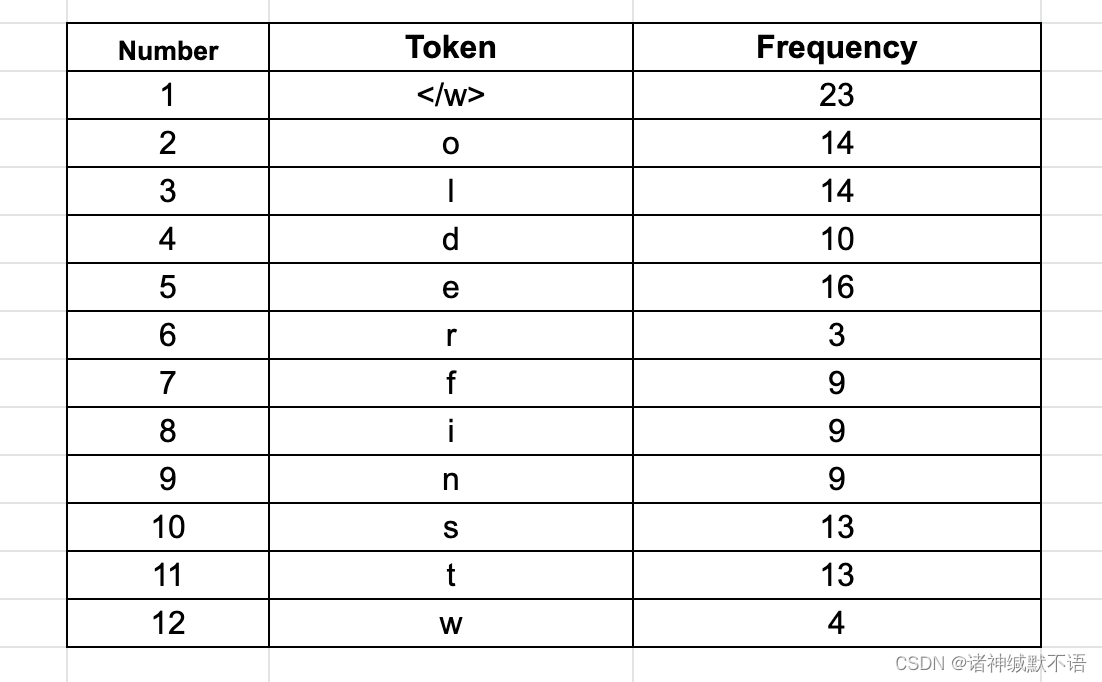
④据此计算出现频率最高的byte pair,将其合并。如此循环迭代,直到抵达token limit或iteration limit。
合并能帮助你用最少的token数来代表整个语料,达成压缩功效。
具体步骤:
Ⅰ 最常见的byte pair是es(出现了13次),将其合并为一个新token,更新表为: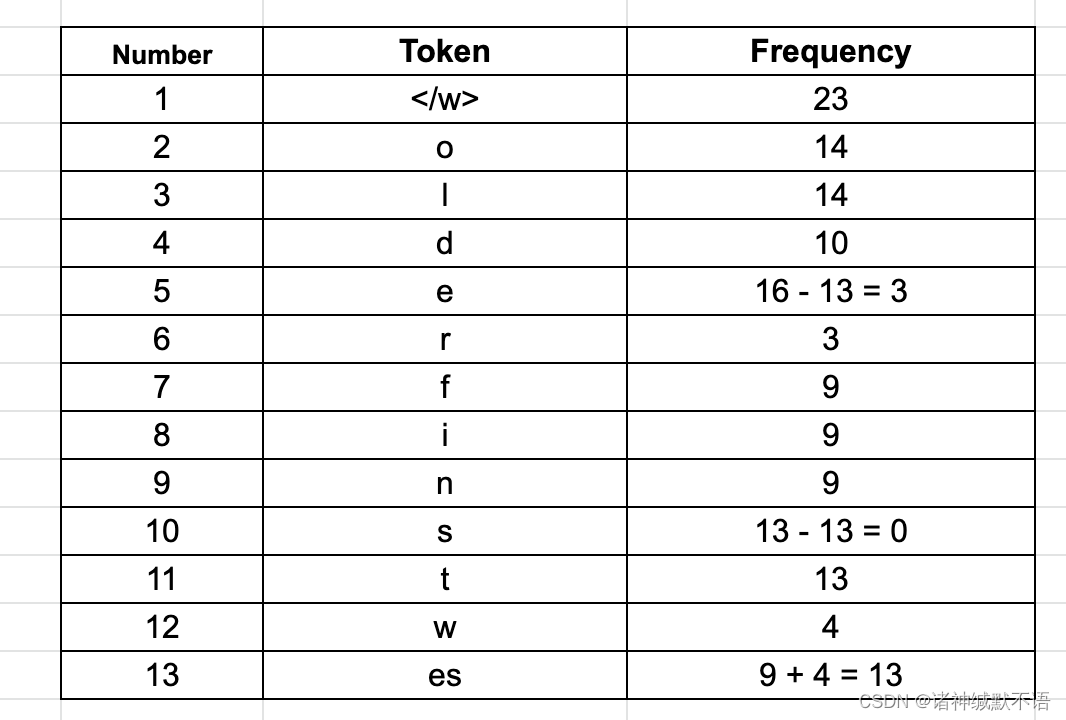
Ⅱ 此时最常见的byte pair是est(出现了13次):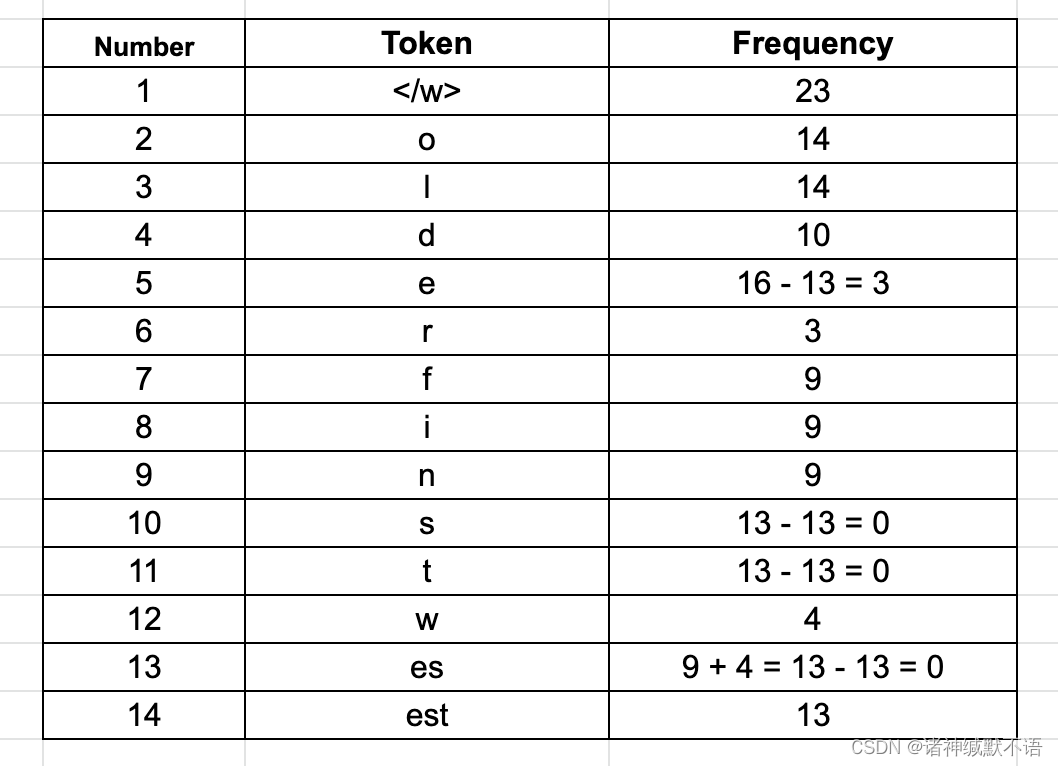
Ⅲ 此时最常见的byte pair是est</w>(出现了13次):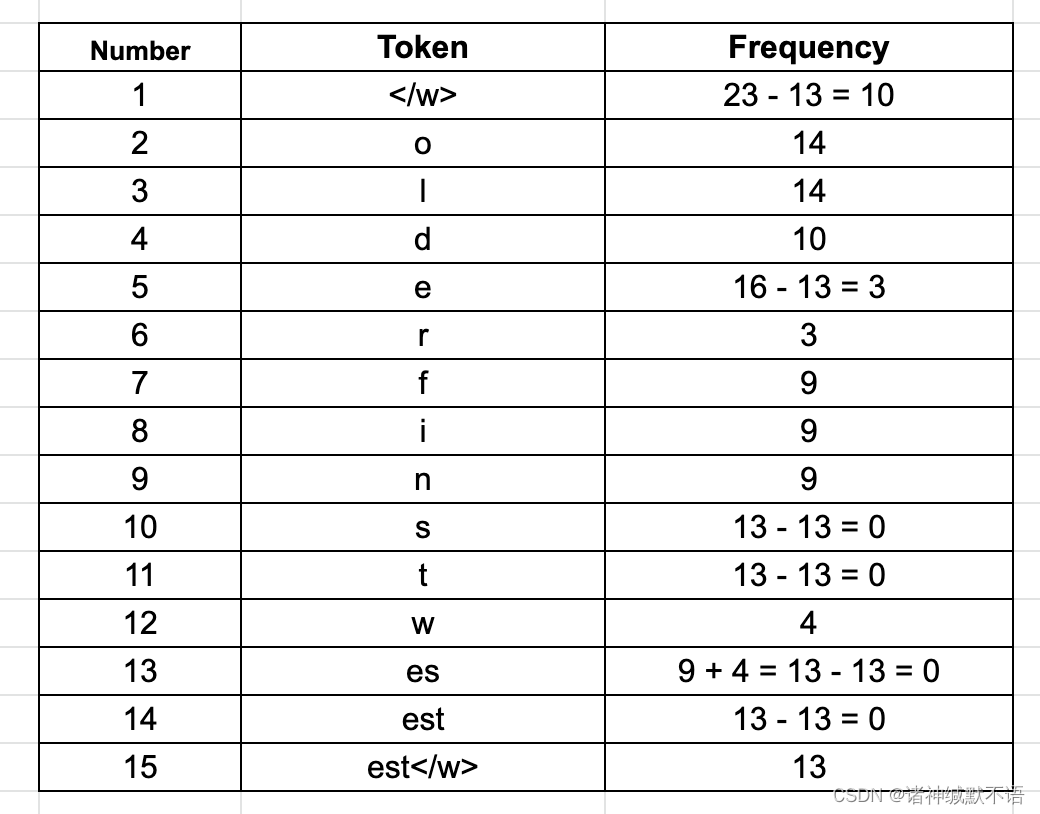
Ⅳ 此时最常见的byte pair是ol(出现了10次):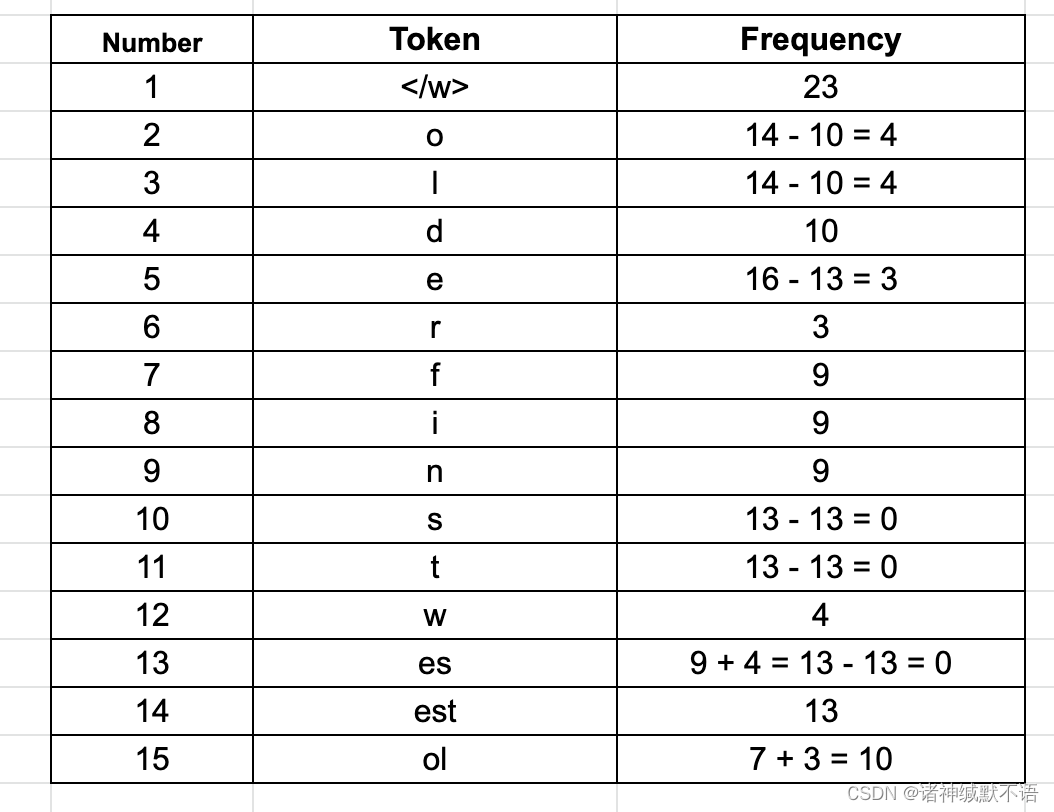
Ⅴ 此时最常见的byte pair是old(出现了10次):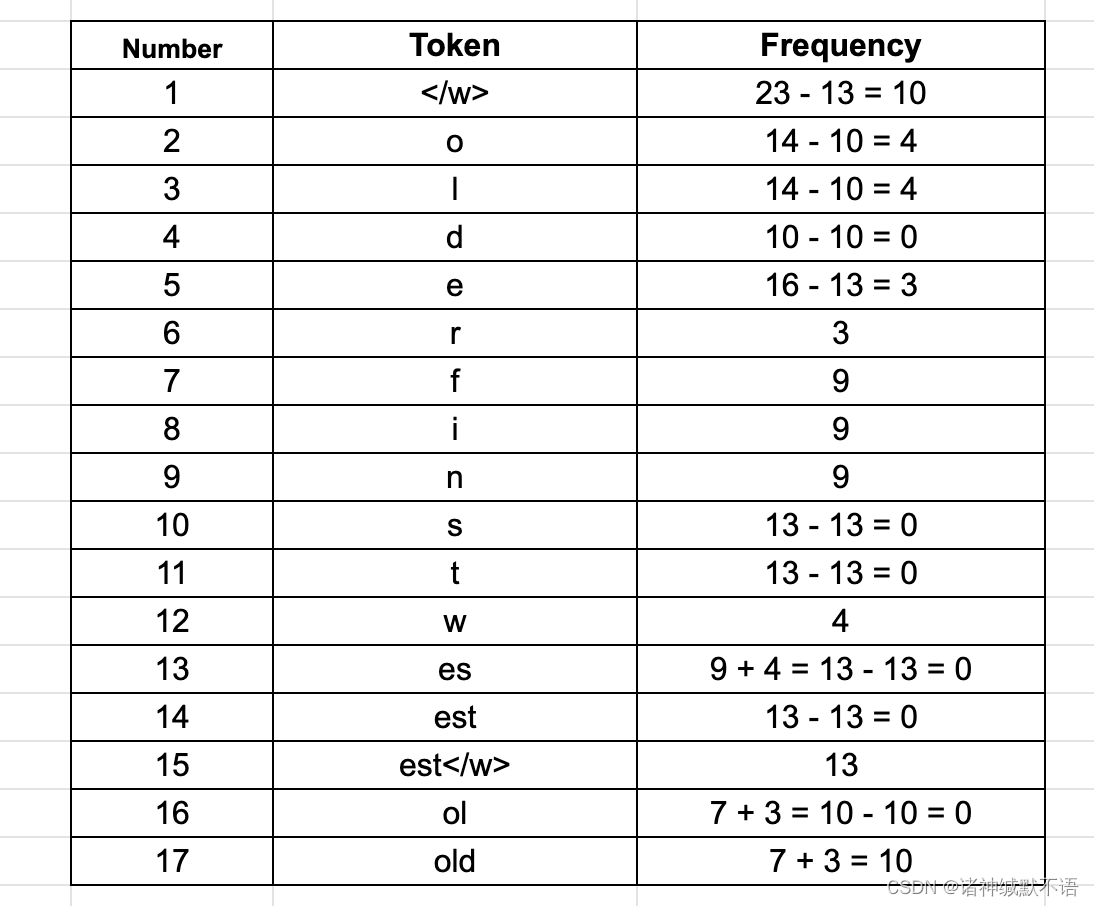
Ⅵ 此时最常见的byte pair是fin(出现了9次),但只有一个单词有这些characters,所以不合并。去掉频率为0的token,最后得到: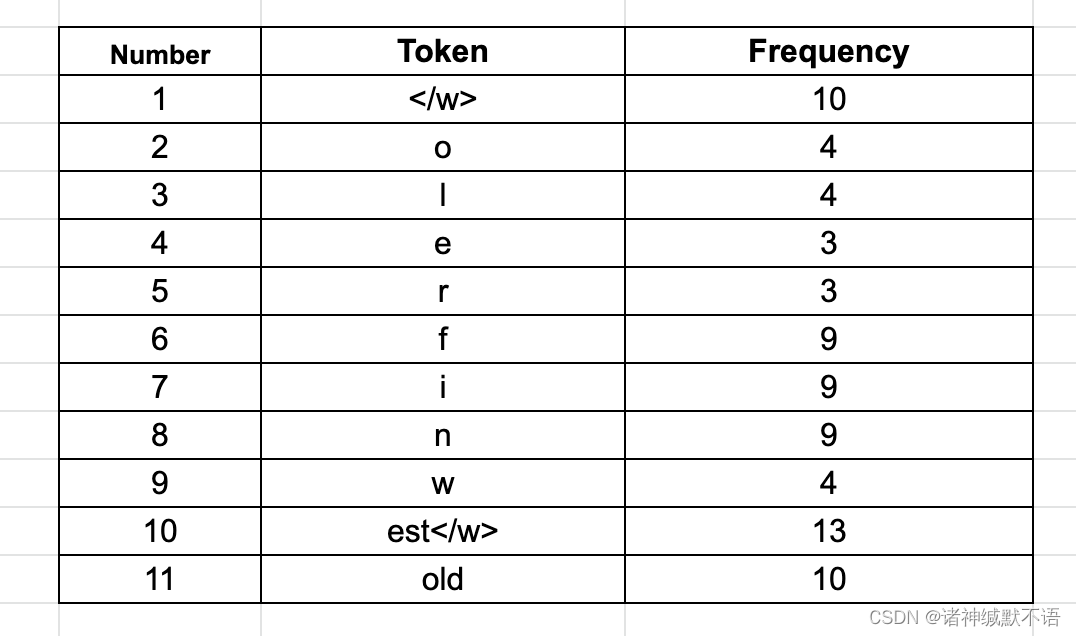
总共有11个token,少于最初的12个token。
在实践中,随着合并、增加token的过程,总的token数会先增后减。停止标准可以是token数或迭代次数。
⑤完成合并迭代后,进行编码和解码工作。
解码只需合并token为整个的单词即可,如序列[“the</w>”, “high”, “est</w>”, “range</w>”, “in</w>”, “Seattle</w>”],可以解码为[“the”, “highest”, “range”, “in”, “Seattle”](注意</w>token)。
编码过程则在计算上代价较高。如单词序列为[“the</w>”, “highest</w>”, “range</w>”, “in</w>”, “Seattle</w>”],我们需要迭代词表中从最长到最短的token来替代单词序列中的substrings。如果最后会剩下一些词表中没有的substrings(训练过程中没有出现过),用unknown tokens代替。
BPE是贪心算法,是应用最广泛的subword-tokenization algorithms之一。 ↩︎ ↩︎理解tokenizer之WordPiece: Subword-based tokenization algorithm - 知乎
原文中讲解相关原理的部分: ↩︎
↩︎


















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











