







论文名称:LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents
论文ArXiv下载地址:https://arxiv.org/abs/2112.14731
论文官方AAAI论文预印版下载地址:https://www.aaai.org/AAAI22Papers/AAAI-10463.PaulS.pdf
官方GitHub项目:Law-AI/LeSICiN: Dataset and codes for the paper “LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents”, accepted and to be published at AAAI 2022.
数据集和预训练模型的下载地址:Dataset and additional files/softwares required for the paper “LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents” | Zenodo
1分钟的官方讲解视频:AAAI2022: LeSICiN: A Heterogeneous Graph-Based Approach for Automatic Legal Statute Identification from Indian Legal Documents
本文是2022年AAAI main track论文,提出了模型LeSICiN (Legal Statute Identification using Citation Network),关注 Legal Statute Identification (LSI) 任务,即给定案例的事实描述文本(或证据),预测该案例违反了什么法条(statutes或statutory laws)。
本文将该任务视为多标签文本分类任务,但是将其建模为了归纳式链路预测(inductive link prediction)范式来解决,这样能够充分利用案例事实与法条之间的引用关系网络。
LSI任务在一些别的工作(尤其是使用CAIL数据集的一系列经典LJP任务论文中)被称为law article prediction。
归纳式链路预测任务是预测一对节点之间是否存在链接,其中至少一个节点在训练模型时不可见。
本文提出了一个印度最高法院的英文数据集ILSI来实现这一任务。本博文在4.1部分介绍该数据集。
整体模型:
- 构建了一个引用网络(案例引用法条,法条之间的层级关系),将LSI任务视为新案例节点与法条之间的链路预测任务
- 因为新案例节点没有结构关系,因此这是inductive链路预测任务
- 解决方案:分别对案例和法条节点的特征(文本)和结构(图结构)进行表征,用MLP解码对两种节点匹配打分。训练时一共3种匹配方式,用链路预测/多标签文本分类任务的BCELoss用多任务学习的范式共优化3个分类任务;测试时由于案例节点缺乏结构信息,因此只使用2种匹配方式,用计算得分凭阈值(在验证集上试出来的)来选择最终预测结果
文章目录
1. Background与Motivation(模型构造思路)
当前的LSI模型仅利用了输入事实文本和法条信息,本文认为案例事实与法条之间的引用网络可以提供额外信息,但是以前的模型都没有利用该信息,所以本文提出了结合该信息的模型LeSICiN,并提出了一个新的大型数据集ILSI。
LeSICiN将法条和训练集的案例文档建模为异质图,节点是案例事实(Fact)和法条(Section,Topics,Chapters,Act),边是案例事实引用法条(Fact引用Section)和法条内部的层次关系(Section
⊂
\subset
⊂Topics
⊂
\subset
⊂Chapters
⊂
\subset
⊂Act)。(Statute就是Section)
LeSICiN学习文本和图结构特征,并使二者互相关联,从而实现归纳式地预测测试集文档(不存在于训练得到的图中)和法条(已存在节点)之间的链接关系,从而实现LSI任务。
现存的有监督链路预测模型大多是transductive而非归纳式的,因此不适用于没出现在训练集中的out-of-sample nodes。而本文的setting中测试集节点的图结构(链接信息)正是需要预测的内容。因此在测试时只能使用案例事实和法条的文本信息、以及法条节点的图结构信息。
LeSICiN参考归纳式链路预测的DEAL模型1,使用hybrid学习机制,来学习每个节点的2种表征:attribute(文本)和structural(图结构)表征。模型会强制attribute表征紧密匹配structural表征,从而让测试节点在仅有文本信息的情况下生成更鲁棒、包含更多特征信息(图结构)的表征。
2. 问题定义与模型介绍
2.1 异质图构建与归纳式链路预测范式
F:Fact
S:Section
placeholder node types表示IPC的分层级别:Topic(T) Chapter(C) Act(A)
4种法条节点之间的层级关系示例:
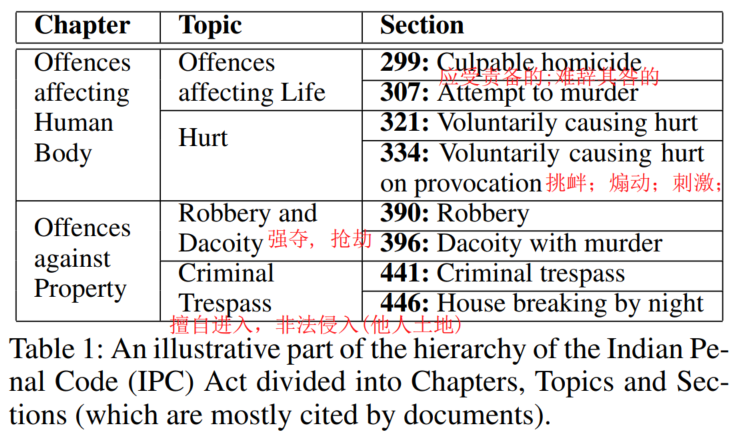
引用 cites ct
被引用 cited by ctb
includes inc
part of po
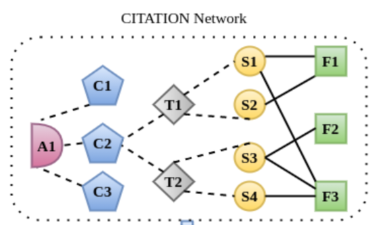

对每篇测试集案例,分别预测其与所有Section节点之间是否存在链接(引用关系)。
2.2 LeSICiN
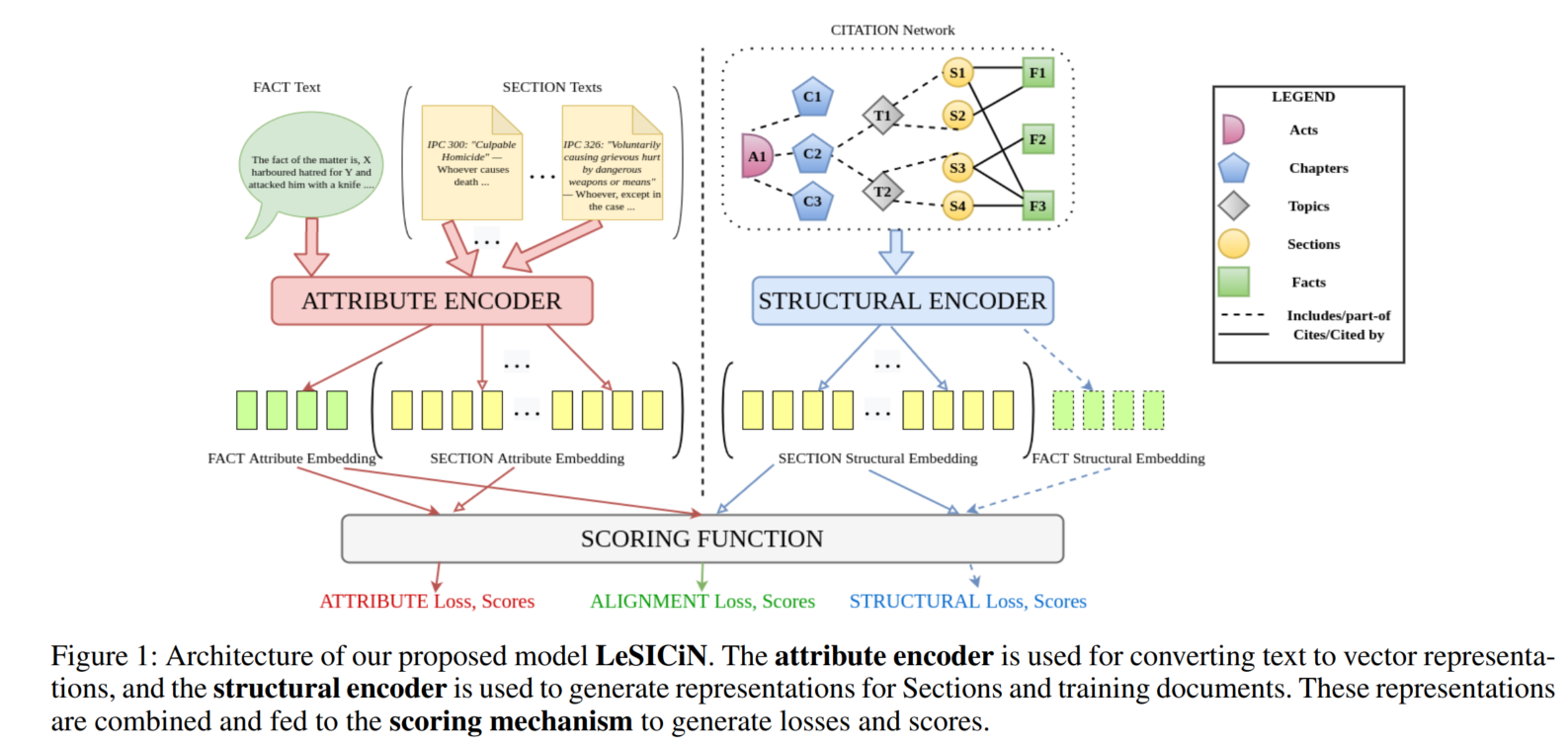
LeSICiN分别对两种节点,都通过2个encoder(attribute、structural),得到2种表征。
然后计算某一案例节点与所有Section节点的3种得分(attribute、structural、alignment)(在测试时事实没有structural得分,通过alignment得分关联attribute和structural得分,从而让测试案例节点也能获得结构信息),分别用交叉熵计算损失函数,加权求和作为总的损失函数,来进行训练。
在测试阶段计算attribute和alignment得分,加权求和,用阈值来预测是否存在边。
2.2.1 attribute encoder
输入事实文本是词句构成的nested sequence,本文用Hierarchical Attention Network (HAN)2建模文本。
2.2.2 structural encoder
异质图的节点由metapath定义,节点 v v v 的 P P P metapath-based neighbourhood N v P \mathcal{N}_v^P NvP 是该节点可通过schema P P P 到达的所有节点(看后文,应该指的是终点),通过不同metapath实例能到达的同一个邻居节点在 N v P \mathcal{N}_v^P NvP 中会表示为多个节点。
本文定义的所有metapath schema:

节点表征通过结合intra- and inter-metapath aggregation来获得:
①对每类节点,给定一个 parameterized(我也不知道这是啥意思)初始化节点表征矩阵。
②对不同类型的节点分别进行线性转换,将其表征映射到同一维度和隐空间。
你要是问我为什么不直接在第一步就把所有类型的节点嵌入到同一维度,那我咋知道呢
③Intra-Metapath Aggregation:得到节点在某个metapath schema上的表征
指定一个节点
v
v
v,一个metapath schema
P
P
P,对一个metapath实例
P
(
v
,
u
)
P(v,u)
P(v,u),得到
v
v
v 的metapath-based neighbourhood
u
∈
N
v
P
u\in\mathcal{N}_v^P
u∈NvP。
本文使用relational rotation encoder构建了一个metapath instance encoder,来生成metapath实例的表征(参考文献:MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding):
对metapath实例上的每个节点,将其上一步得到的表征加上前一节点表征(第一个节点的表征就是上一步表征)与可学习的relation vector(这里公式表示这个向量每个关系只有一个,但是这个节点本身TMD怎么会有一个关系?难道是指该节点与上一节点之间的关系吗?)的哈达玛积:
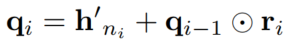
将最后一个节点的表征除以节点数,得到metapath实例的表征:
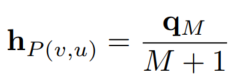
将所有这样的metapath实例的表征attentively结合起来,得到
v
v
v 对这个metapath schema的节点表征:
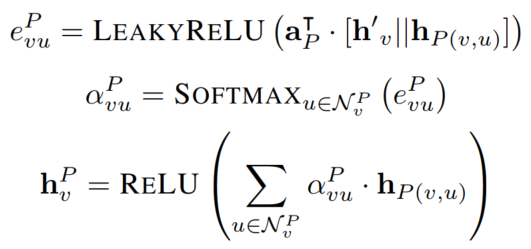
④Inter-Metapath Aggregation:得到节点表征(聚合不同的metapath schema)
第一步:聚合每个metapath schema所有起始节点类型的节点在该metapath schema上的表征:
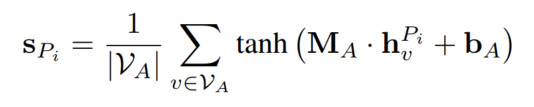
第二步:用metapath schema做attention,加权求和一个节点在每个metapath schema上的表征,得到最终的节点表征:
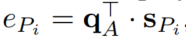
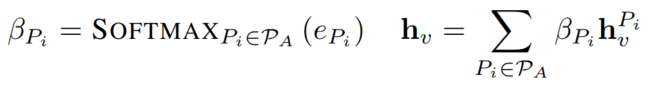
2.2.3 打分
对每个事实节点,我们可以计算其与每一Section节点之间的得分。
由于法条本身就有顺序和相关语义,所以首先用Bi-LSTM来contextualize Section节点表征。
然后用自注意力机制得到所有Section的表征
h
S
\mathbb{h}_S
hS:
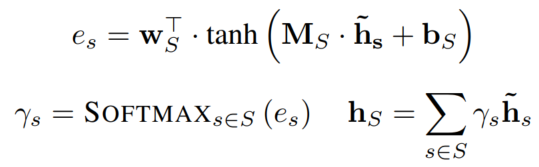
w
S
∈
R
d
s
\mathbf{w}_S\in\mathbb{R}^{d_s}
wS∈Rds是parameterized
每个事实节点和若干Section节点都可以计算得分,将事实表征与所有Section表征concat后过MLP,得到长度为Section数的向量,这个向量就是最终的预测表征:
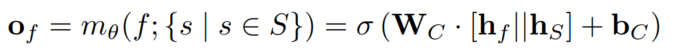
具体的三种得分:
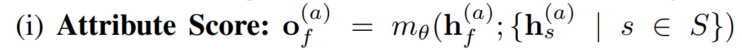
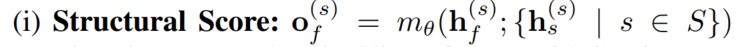
(测试阶段的事实节点无法计算structural score)
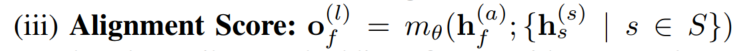
2.2.4 Dynamic Context
在structural encoder中将context vectors换成dynamically generated vectors(参考文献:Learning to predict charges for criminal cases with legal basis),在打分时用事实表征来生成这个dynamic context:
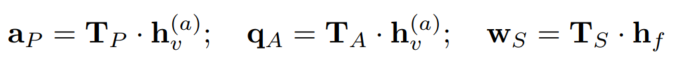
2.2.5 损失函数
损失函数包含3个部分,分别对应3种分数:
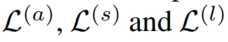
用Binary Cross Entropy Loss计算损失函数:
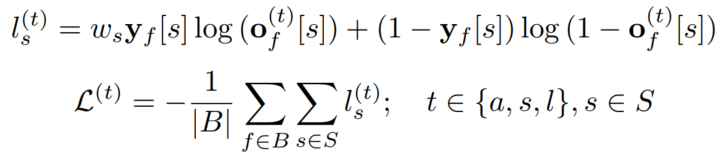
对这个权重的计算有两种策略:
①vanilla weighting scheme (VWS):
训练集案例数除以引用该Section的案例数
N
/
f
s
N/f_s
N/fs(稀有标签可能会导致权重过大)
②threshold-based weighting scheme (TWS):
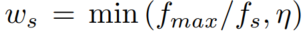
f
m
a
x
f_{max}
fmax是被引最多标签的被引数,
η
\eta
η是通过验证集计算出的阈值。
保证高频类的权重。
最终损失函数:
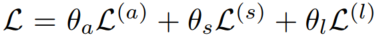
2.2.6 测试
测试案例没有structural score,因此使用另外两个得分加权求和,使用验证集上计算得到的阈值
τ
\tau
τ来作为阈值,预测案例事实与各Section节点是否有边:
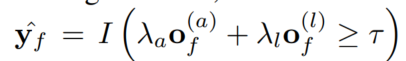
3. 模型原理:引用网络有效性
本文指出,这一网络可以提供海量的法律知识,已经在法律文书相似性任务中表现出有效性(参考文献:Re8:读论文 Hier-SPCNet: A Legal Statute Hierarchy-based Heterogeneous Network for Computing Legal Case)
4. 实验
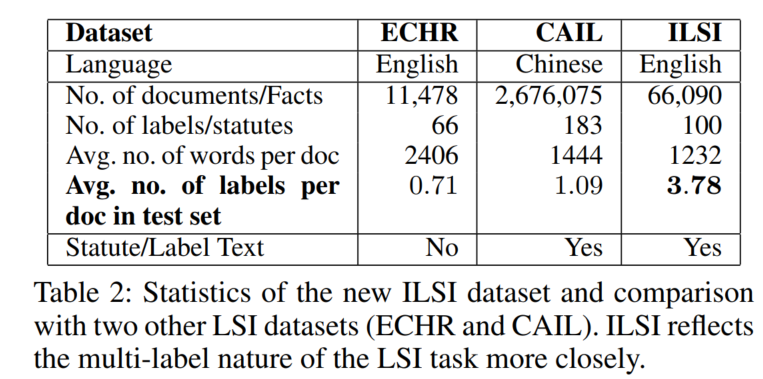
4.1 数据集
由于现存的LSI数据集ECHR规模小,而且不包含法条(标签)的文本信息;CAIL是中文,而且两个数据集的案例事实平均对应的法条数都很小,这使LSI任务趋于单标签分类,无法体现其多标签分类的特质。
本文提出了新数据集ILSI,其中法条来自印度主要刑法Sections of the Indian Penal Code (IPC)3,案例来自印度最高法院和6个主要的高级法院(网站是https://indiankanoon.org)。
案例本身包含事实、辩词、裁决等多部分的信息,本文中仅使用事实信息,因此使用Hier-BiLSTM-CRF分类器来抽取事实信息。(隔壁FLA4和CAIL数据集用的是正则表达式)(参考文献:Identification of Rhetorical Roles of Sentences in Indian Legal Judgments)
ILSI仅保存了100个被引频率最高的Sections,每个案例都至少引用了其中的一个法条。
文本中的命名实体都被mask,以减少模型的demographic bias。(参考文献:Neural Legal Judgment Prediction in English)
数据集划分比例为64:16:20,即42884个训练集案例,10203个验证集案例,13043个测试集案例。使用iterative stratification保证三个子集的标签分布是平衡的(参考文献:On the stratification of multi-label data)。
数据集统计信息:
数据集示例:

数据集文件格式示例等我服务器好了打印一下。
4.2 baseline
细节略。
FLA4
DPAM
HMN
LADAN5
HBERT
HLegalBERT
DEAL1
4.3 实验设置
所有模型:
- 100个epoch,用在验证集上表现最好的epoch来做测试。嵌入维度是200(HBERT是768), Adam Optimizer with learning rate in the range [0.01, 0.000001], (iii) dropout probability of 0.5, and (iv) batch size of 32
- 用在法律语料上训练的200维sent2vec(Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features)(除了HBERT和HLegalBERT)
- NVIDIA Tesla T4 with 16 GB GPU memory
- PyTorch + PyG(具体来说是torch_sparse)
LeSICiN:
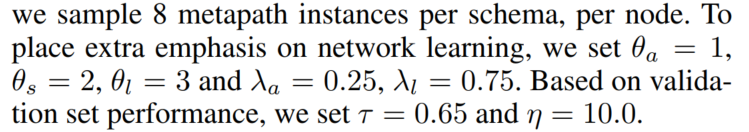
- sent2vec是本文自己训练的,细节略。
4.4 主实验结果
评估指标:macro-Precision macro-Recall macro-F1 Jaccard overlap(标签向量)

(最后一列是为了提升macro-R专门更换了一下预测阈值)
4.5 模型分析
4.5.1 Ablation Study
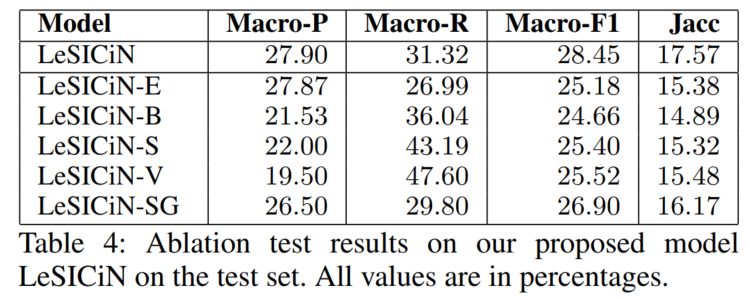
- 把 metapath-based aggregation network 换成 a simple node embedding lookup table(类似DEAL)
- 把3个分换成1个分
- 去掉 structural loss
- 用VWS代替TWS
- 把异质图换成同质图
4.5.2 不同频率标签和不同地区法院的表现差异
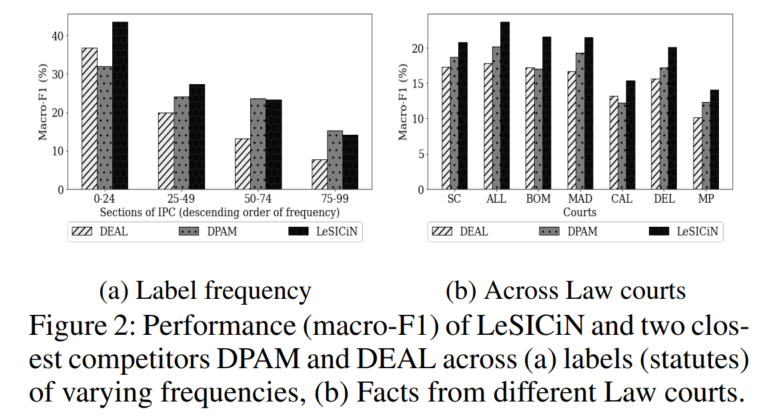
细节略。
5. 代码复现
感觉是比较好调的一个代码。占的内存不大,而且挺快的。
这个代码写得挺神奇的……
具体的,其实我还没有看懂,感觉还是挺值得学习的一份代码。
MAGNN本身是不能用于有一种边完全缺失的inductive场景(因为它需要用metapath实例来进行运算,直接缺失一种metapath实例还算个锤子)(我flag就放在这里,以后HGNN一定要做不同transductive/inductive的解决方案,读者快来给我做!),DEAL可以实现。但是LeSICiN怎么做到用MAGNN+DEAL呢?因为它在测试节点上不跑MAGNN,它的MAGNN仅应用于训练场景,那当然不缺边了!
这种简单的问题我想了半天、还得亲手改完代码才能想出来,我知道这是因为我傻,无所谓了。
我提的复现相关问题,作者没有回复过……
https://github.com/Law-AI/LeSICiN/issues/1
https://github.com/Law-AI/LeSICiN/issues/2
常规Python 3 + PyTorch + torch_sparse的组合就能跑。
除了configs/data_path.json把文件地址改一下之外,别的似乎都不需要改。
主要容易出bug的地方在于好几个地方写死了GPU ID为0,如果想改,需要改:
generate_label_weights()(自带dev入参,直接改就行)- run.py第192行
.cuda() MultiLabelMetrics()(自带dev入参,直接改就行)train_dev_pass()(需要改cuda()
Re9:读论文 DEAL Inductive Link Prediction for Nodes Having Only Attribute Information ↩︎ ↩︎
Hierarchical attention networks for document classification ↩︎
印度本身的法律体系还是挺复杂的,可参考商务部发的:http://policy.mofcom.gov.cn/page/nation/India.html 但是在本文中可以不考虑这些情况,直接当成大陆法系来做就完了。 ↩︎
Re7:读论文 FLA/MLAC Learning to Predict Charges for Criminal Cases with Legal Basis ↩︎ ↩︎
Re27:读论文 LADAN Distinguish Confusing Law Articles for Legal Judgment Prediction ↩︎
















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











