







本文主要以模型被提出的时间为顺序,系统性介绍各种预训练模型的理论(尤其是相比之前工作的创新点)、调用方法(最佳实践)和表现效果。
代码实践部分主要见:
- Gitee:llm-throughtout-ages: LLM(预训练语言模型)的代码应用和最佳实践
- GitHub:PolarisRisingWar/llm-throught-ages: 预训练模型的简单实践代码
2023年
- (OpenAI)GPT系:GPT-1 / GPT-2/ GPT-3 / GPT-3.5 / ChatGPT / GPT-4
- GPT-1
(2018) Re45:读论文 GPT-1 Improving Language Understanding by Generative Pre-Training - GPT-2
- InstructGPT
- CodeX
- GPT-3原始论文:(2020) Language Models are Few-Shot Learners
- RLHF
对RLHF的改进:(2023 huggingface) Efficient RLHF: Reducing the Memory Usage of PPO
- GPT-1
- (谷歌)Bard
- (谷歌 DeepMind) Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
motivation是传统prompt策略都是手工完成的(比如CoT),这是sub-optimal的,因此本文提出自动化的Promptbreeder来让prompt自动改进。
Promptbreeder在一组task-specific prompt的基础上进行变换(LLM生成变换prompts,这个过程是会逐步进化的),在训练集上评估其表现。 - (Facebook)LLaMA
- (斯坦福) Alpaca
- Vicuna
- Dolly
- WizardLM
- Orca
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Orca-2: Teaching Small Language Models How to Reason - (百度)ERNIE系列和文心一言
- (科大讯飞)讯飞星火
- (阿里)通义千问
- 视频转文字:通义听悟
- https://huggingface.co/tiiuae/falcon-40b
- (清华)ChatGLM / VisualGLM1
- RWKV
我RNN天下无敌啊!
官方项目:BlinkDL/ChatRWKV: ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source.
博文:发布几个RWKV的Chat模型(包括英文和中文)7B/14B欢迎大家玩 - 知乎
论文:RWKV: Reinventing RNNs for the Transformer Era - (复旦)MOSS
- BELLE
- BiLLa
- MiniGPT-4
- gpt4all
- (微软)phi-1
原始论文:Textbooks Are All You Need:证明高质量数据可以打破scale law,在小模型上也能展现出涌现能力(数据集不是用GPT标注的,就是用GPT生成的,有点迷幻) - (微软) Adapting Large Language Models via Reading Comprehension
改用阅读理解来train LLM - (清华)GLM系
原始论文:(2022 ACL) GLM: General Language Model Pretraining with Autoregressive Blank Infilling - (浙大) KnowLM:知识图谱+LLM
DeepKE-LLM: A Large Language Model Based Knowledge Extraction Toolkit
GitHub中文文档网址:https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md - Unifying Large Language Models and Knowledge Graphs: A Roadmap
- DB-GPT
https://github.com/eosphoros-ai/DB-GPT/blob/main/README.zh.md - (波士顿大学) Platypus: Quick, Cheap, and Powerful Refinement of LLMs:对数据集进行了完善(解决了数据泄露问题),用Lora微调LLaMA 2
参考讲解博文:大模型榜单又被刷新了~~ - (UIUC+英伟达) RAVEN: In-Context Learning with Retrieval Augmented Encoder-Decoder Language Models:检索增强(上下文融合学习)+mask/prefix语言模型,解决数据漂移和文本长度限制
- SeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding:联合训练文本分类和命名实体识别,关注开放域自然语言理解任务
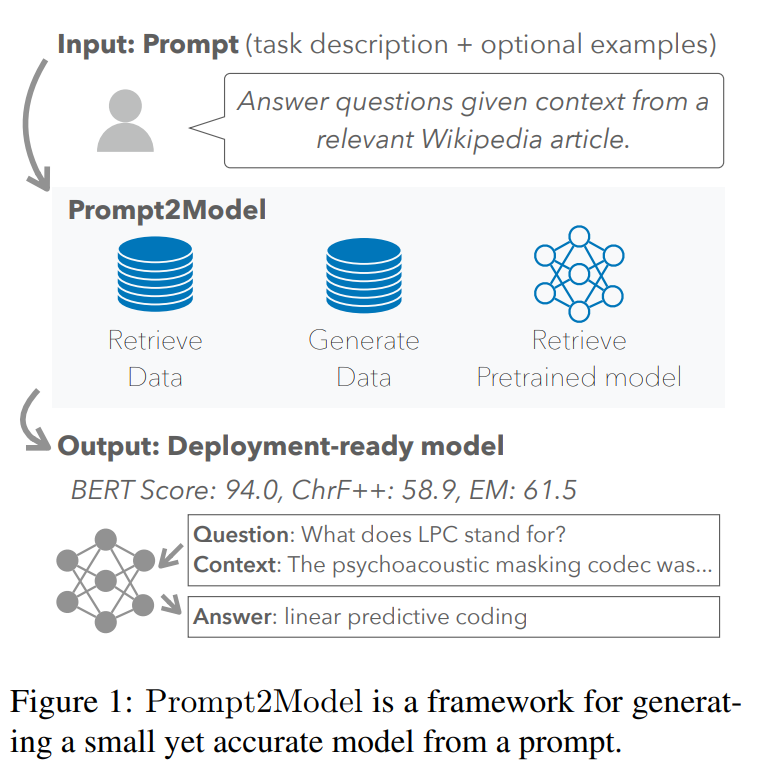
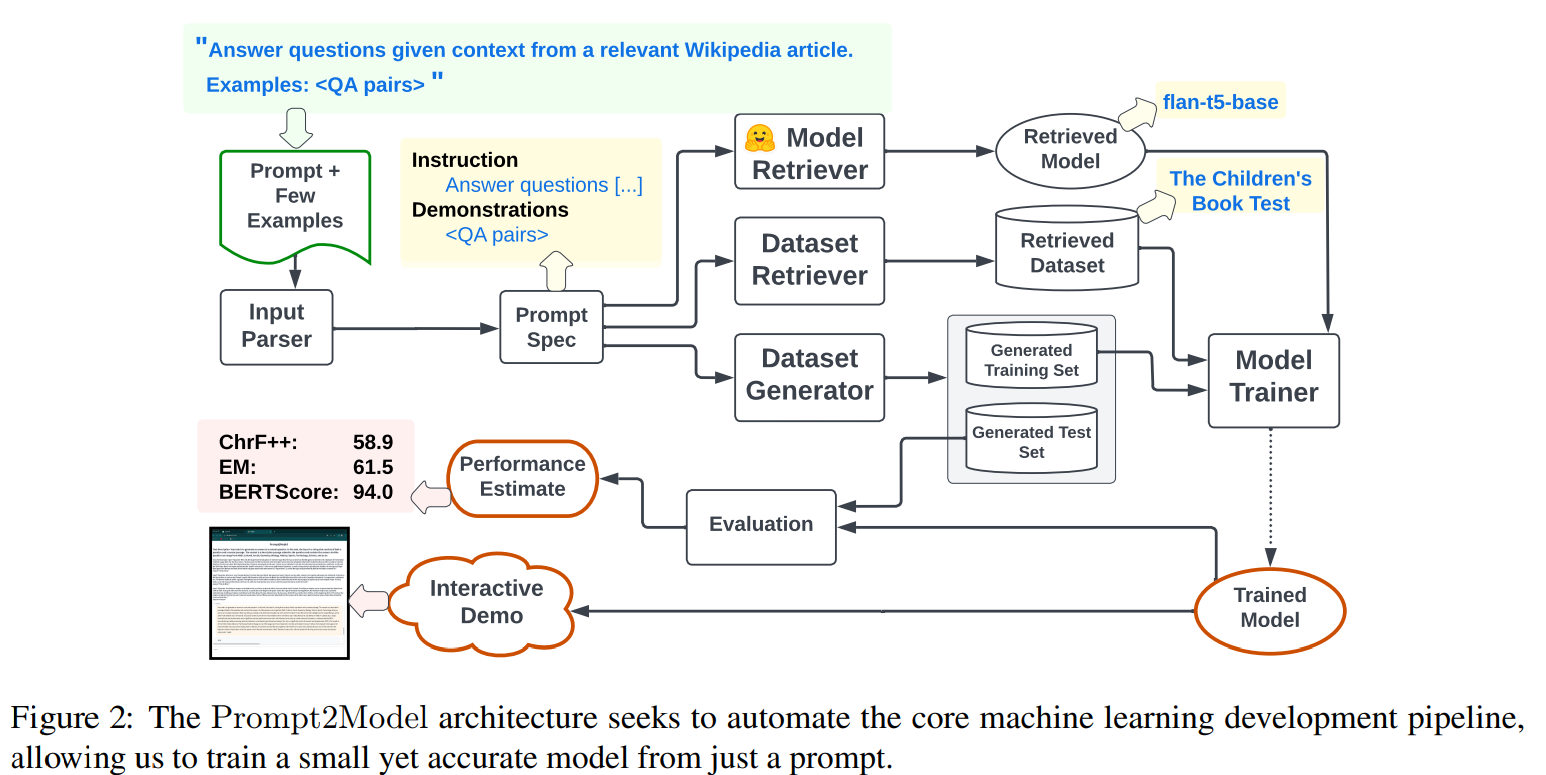
- (CMU+清华) Prompt2Model: Generating Deployable Models from Natural Language Instructions:输入自然语言形式的任务描述,训练特定目的且便于部署的小模型
检索现有数据集+检索LLM+使用LLM生成数据集→在student上微调
- (ACL) Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
- (DeepMind) Large Language Models can Learn Rules:这个有用呀,以后有时间就看一下 (✧◡✧)
- FLM-101B: An Open LLM and How to Train It with $100K Budget
- 信息检索
- (智源) 封神榜
IDEA-CCNL/Fengshenbang-LM: Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,成为中文AIGC和认知智能的基础设施。 - (谷歌) Universal Self-Consistency for Large Language Model Generation
- (谷歌) Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses:规划复杂的任务
- (伯克利) Starling-7B: Increasing LLM Helpfulness & Harmlessness with RLAIF
- https://www.llm360.ai/
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
- vivo-ai-lab/BlueLM: BlueLM(蓝心大模型): Open large language models developed by vivo AI Lab
- Parrot: Enhancing Multi-Turn Chat Models by Learning to Ask Questions
- (东北大学) neukg/TechGPT: TechGPT: Technology-Oriented Generative Pretrained Transformer
- (腾讯) AppAgent: Multimodal Agents as Smartphone Users:大概来说就是自动操纵APP的
2022年
- (谷歌) PaLM
博文:Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance – Google AI Blog
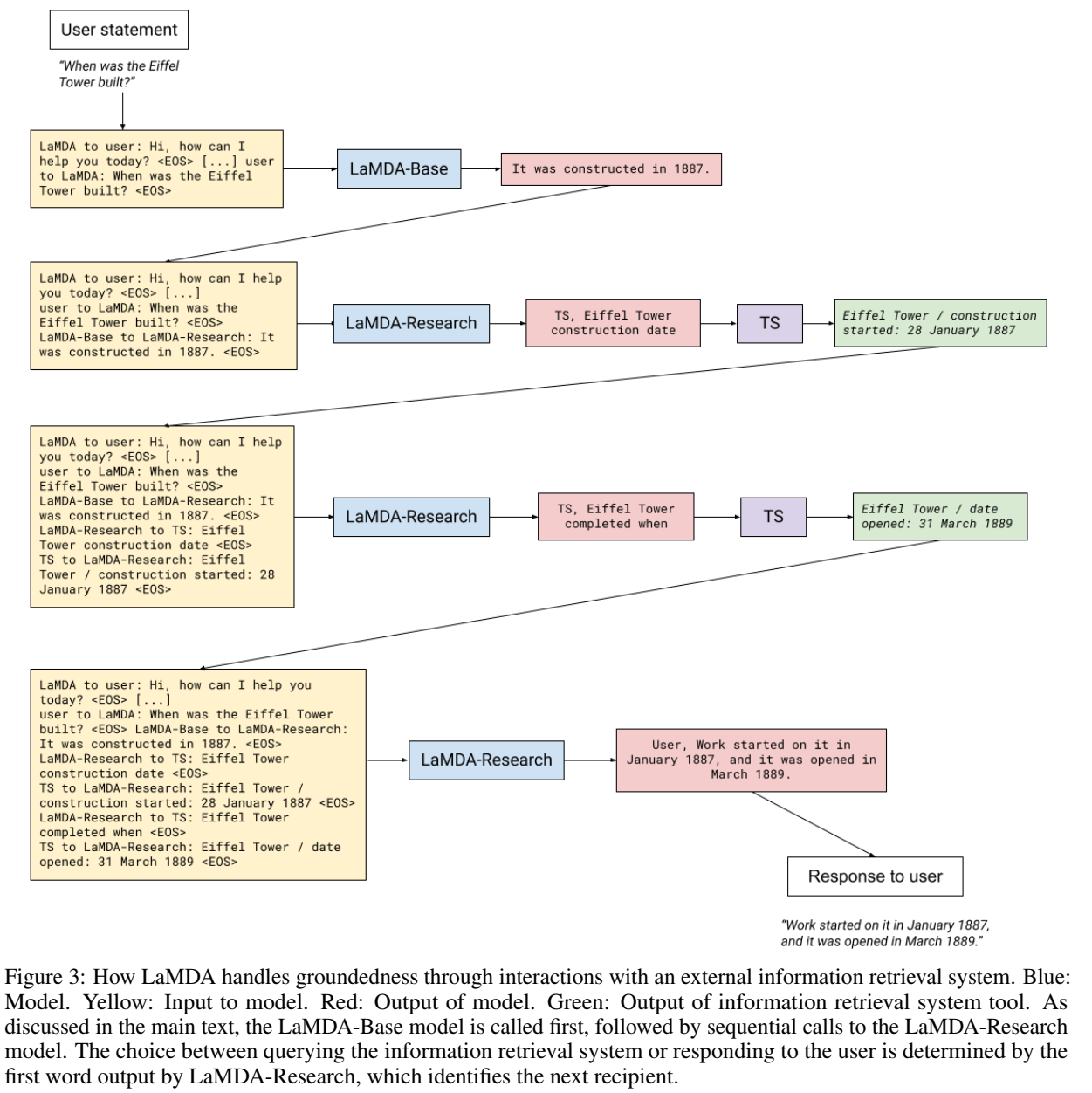
PaLM: Scaling Language Modeling with Pathways - (谷歌) LaMDA:模型关心安全性和符合事实,用分类器判断回答是否安全,用外部知识源(如信息抽取系统、翻译器、计算器等)保证符合事实,构建了衡量二者的指标
论文:LaMDA: Language Models for Dialog Applications
- (谷歌) T0
(ICLR) Multitask Prompted Training Enables Zero-Shot Task Generalization
这篇关注将各种NLP任务都转换为prompt,然后训练得到模型:https://huggingface.co/bigscience/T0pp
prompt集锦:工具包 bigscience-workshop/promptsource: Toolkit for creating, sharing and using natural language prompts. 数据集 https://huggingface.co/datasets/bigscience/P3 - (谷歌) ST-MoE
ST-MoE: Designing Stable and Transferable Sparse Expert Models - (谷歌) UL2和Flan-UL2
UL2: Unifying Language Learning Paradigms
参考讲解内容:https://readpaper.com/paper/684903631811858432 - (EMNLP huggingface) TK
Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
基于transformers的encoder-decoder模型
基于T5构建
遵循in-context instrctions(任务定义、k-shot示例、解释等)来解决各种NLP任务 - (Meta) ATLAS
Atlas: Few-shot Learning with Retrieval Augmented Language Models
检索增强
密集检索器模块通过MoCo对比损失进行预训练
参考讲解博文:Meta发布全新检索增强语言模型Atlas,110亿参数反超5400亿的PaLM - 知乎 - (Meta) OPT
OPT: Open Pre-trained Transformer Language Models - (追一科技 苏神他们做的) RoFormer
RoFormer: Enhanced Transformer with Rotary Position Embedding:主要改进了位置编码
2021年
- RPT
- CPT
- (浪潮信息)源1.0
- (BigScience) [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745)
参考讲解内容:https://readpaper.com/paper/720818360680333312 - (JMLR 谷歌) Switch Transformer
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
①用稀疏FFN替换密集FFN ②简化MoE - (微软&英伟达) MT-NLG
官方博文:Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model - Microsoft Research - (ACL) AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization
- (OpenAI) CLIP
Learning Transferable Visual Models From Natural Language Supervision:关注文本-图片对应的多模态任务
开源版代码:mlfoundations/open_clip: An open source implementation of CLIP.
2020年
- Longformer:解决长文本的问题
序列长度必须是512的整数倍2- 中文版:ValkyriaLenneth/Longformer_ZH
tokenizer必须要用BertTokenizer3
- 中文版:ValkyriaLenneth/Longformer_ZH
- (ACL) BART
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension - (ACL) SenseBERT: Driving Some Sense into BERT:在语义层面弱监督
- Pegasus
- (EMNLP Findings) E-BERT: Efficient-Yet-Effective Entity Embeddings for BERT:向BERT中注入实体信息(Wikipedia2vec)
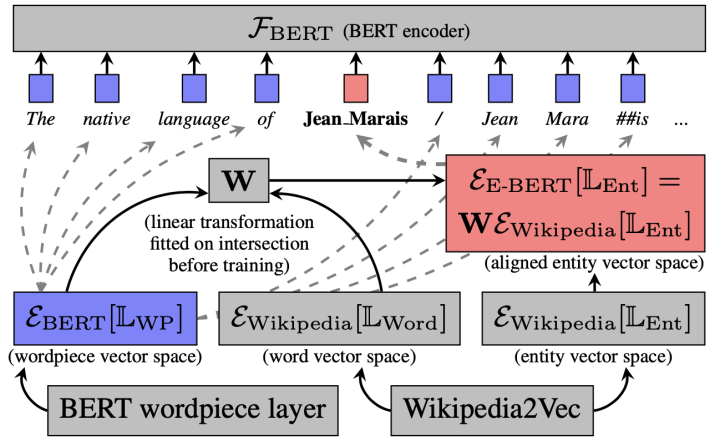
首先将Wikipedia2Vec中的词向量映射到BERT的token embedding的同一向量空间中,以学习一个映射矩阵 W W W ,然后使用 W W W 对Wikipedia2Vec中的实体向量进行映射,最后通过拼接的方式将实体信息注入到BERT的输入当中 - (微软) DeBERTa
DeBERTa: Decoding-enhanced BERT with Disentangled Attention:disentangled attention + enhanced mask decoder
有两个向量,分别通过编码内容和相对位置来表示标记/单词
DeBERTa 中的 self-attention 机制处理内容到内容、内容到位置、位置到内容的 self-attention,而 BERT 中的 self-attention 相当于只有前两个组成部分。作者假设还需要位置到内容的自注意力来全面建模一系列标记中的相对位置。
此外,DeBERTa 配备了增强型掩码解码器,其中令牌/单词的绝对位置以及相关信息也被提供给解码器。 - (微软) Turing-NLG
官方博文:Turing-NLG: A 17-billion-parameter language model by Microsoft - Microsoft Research - (JMLR 谷歌) T5:标准encoder-decoder架构的Transformer,在参数量上模仿BERT
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
中心思想大概是“所有任务都可以视为Text2Text任务,所以Text2Text模型可以解决所有问题”,这个“视为”就比较类似prompt的思想:
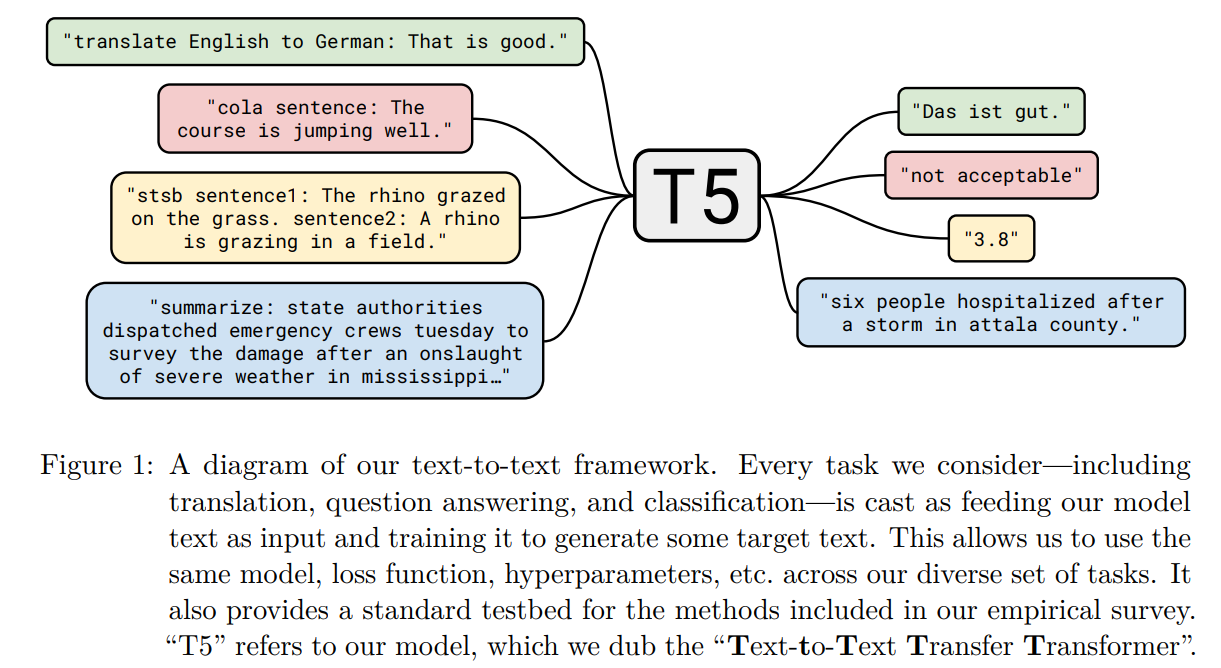
T5论文里面介绍了各种模式的框架,最后发现encoder-decoder架构(encoder上无mask,decoder上因果mask)的效果最好,所以最后T5模型也用得是这个框架。
mask模式:

模型架构是P1:
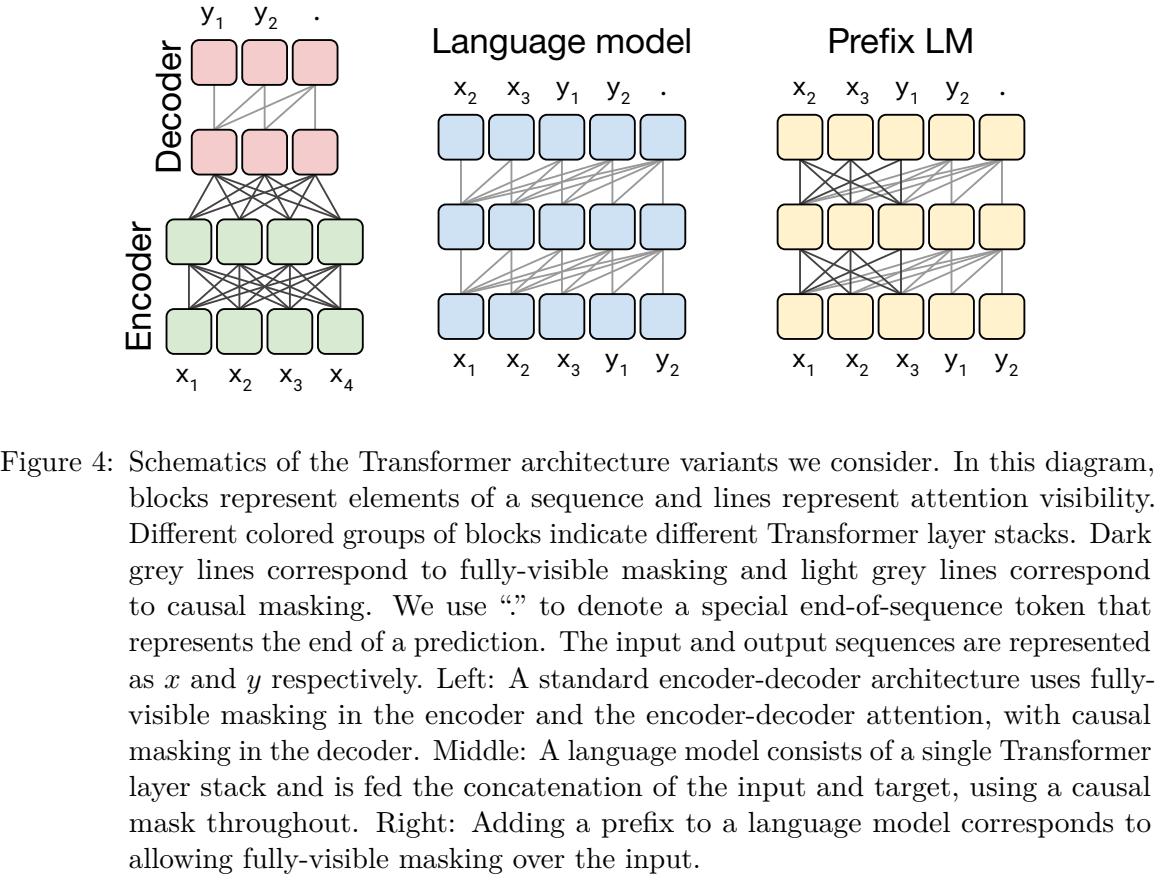
参考讲解博文:T5: Text-to-Text Transfer Transformer 阅读笔记 - 知乎
如何评价 Google 提出的预训练模型 T5? - 知乎:如果需要详尽理解T5,这个问题还是很值得看的
后续还有一个对模型的升级T5.1.14:将ReLU改成GeLU,decoder的prediction head不再与encoder和decoder的嵌入层共享权重,预训练阶段去掉dropout
(这都TMD什么纯纯实证经验啊) - (谷歌) mT5
mT5: A massively multilingual pre-trained text-to-text transformer
基于T5.1.1做的改进,主要将数据集改成多语言的了
参考博文:那个屠榜的T5模型,现在可以在中文上玩玩了 - 科学空间|Scientific Spaces - (ICLR 谷歌) ALBERT
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations:减小BERT参数量(词嵌入向量的因式分解,减小了表征维度;跨层参数共享),将NSP任务换成SOP(sentence order prediction)任务(因为NSP任务成预测主题了),去掉dropout,用LAMB优化器,用n-gram mask
参考讲解博文:Google ALBERT原理讲解 - 知乎 - (ICLR) ELECTRA
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
训练一个简单的MLM,找出难以预测的token,选为预测目标
用二分类范式来判断每个token是否被替换过5 - (ICLR) Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model:结合知识
- (TACL) SpanBERT: Improving Pre-training by Representing and Predicting Spans:简单讲就是将BERT mask的内容换成span(多个连续token)了

- (SIGGRAPH MIG) Collaborative Storytelling with Large-scale Neural Language Models:协作讲故事,AI代理和人类轮流添加内容。抽样→排序,根据人工偏好得到训练信号
- (追一科技 苏神) WoBERT
ZhuiyiTechnology/WoBERT: 以词为基本单位的中文BERT
官方博文:提速不掉点:基于词颗粒度的中文WoBERT - 科学空间|Scientific Spaces
2019年
- Bert衍生
SCIBERT - (Meta) Roberta
修改了BERT中的参数,如使用更大的mini-batch、删除NSP目标等 - NEZHA
- DistilBERT
- (ACL) Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context - (ACL) MT-DNN:BERT预训练+多任务continual pre-training
Multi-Task Deep Neural Networks for Natural Language Understanding
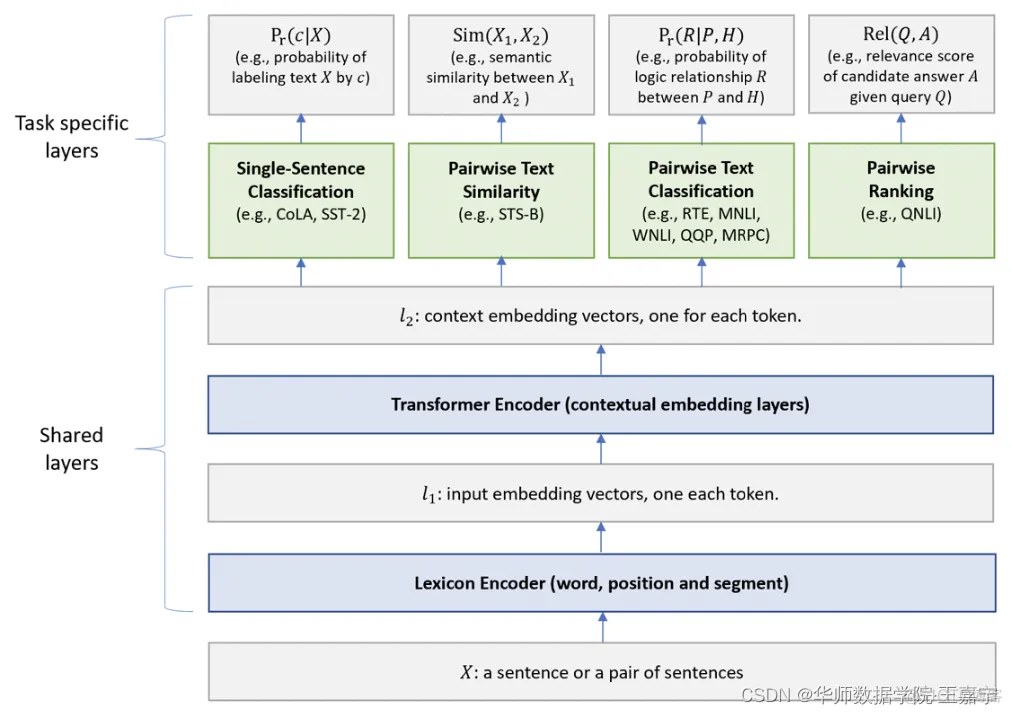
通过多任务学习提高泛化能力(将其视为正则化)
先预训练BERT,再微调多任务 - (NeurIPS) XLNet
XLNet: Generalized Autoregressive Pretraining for Language Understanding - (ICML) MASS:encoder-decoder架构的生成式模型
论文:MASS: Masked Sequence to Sequence Pre-training for Language Generation
预训练任务是mask连续片段,在decoder端作为目标输出
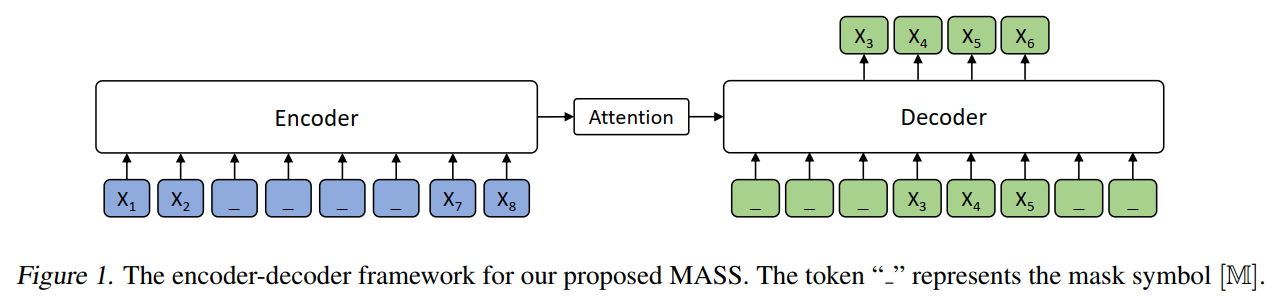
MASS论文中还给出了与BERT和GPT式语言模型的区别:

参考讲解博文:【论文精读】生成式预训练之MASS - 知乎 BERT生成式之MASS解读 - 知乎 - (微软) UniLM
【论文解读】UniLM:一种既能阅读又能自动生成的预训练模型 - (清华) ERNIE
- (ICLR) Universal Transformers
图灵完备的概念我没搞懂反正,主旨是能够解决所有可解决的计算问题。可以参考这个知乎问题下的回答:什么是图灵完备? - 知乎
然后UT的主旨就是图灵完备了,解决了transformer的问题
ACT机制也还没看
在transformers的基础上,一是具体block数可以自适应,二是增加了全局共享的transition函数
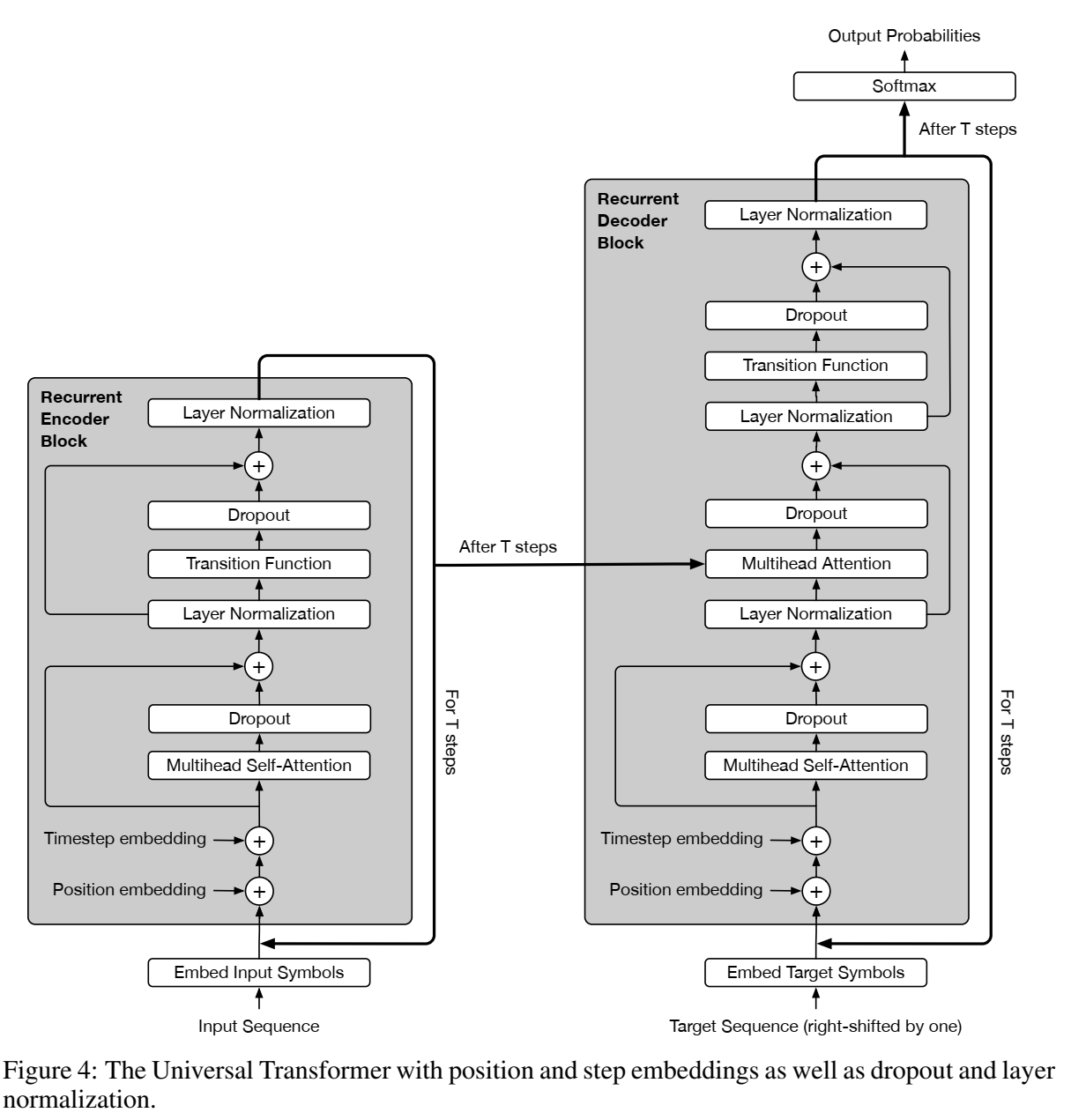
参考讲解博文:Universal Transformers原理解读 - 知乎 - (创新工场) ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations
- StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
将语言结构纳入预训练 - KnowBert
(EMNLP) Knowledge Enhanced Contextual Word Representations:嵌入KB(用attention更新表征) - (EMNLP) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
2018年
- (2018 谷歌)Bert
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
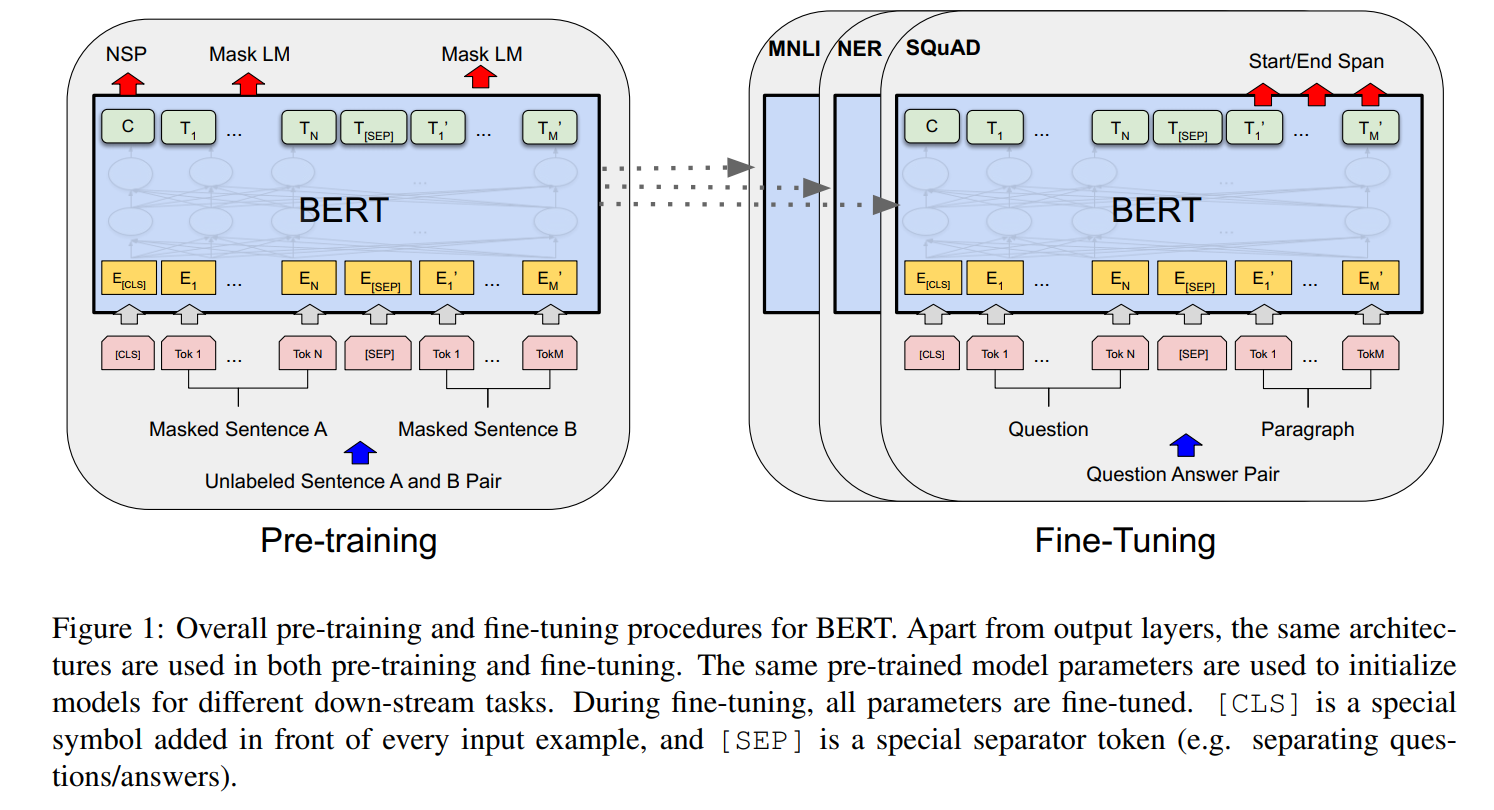
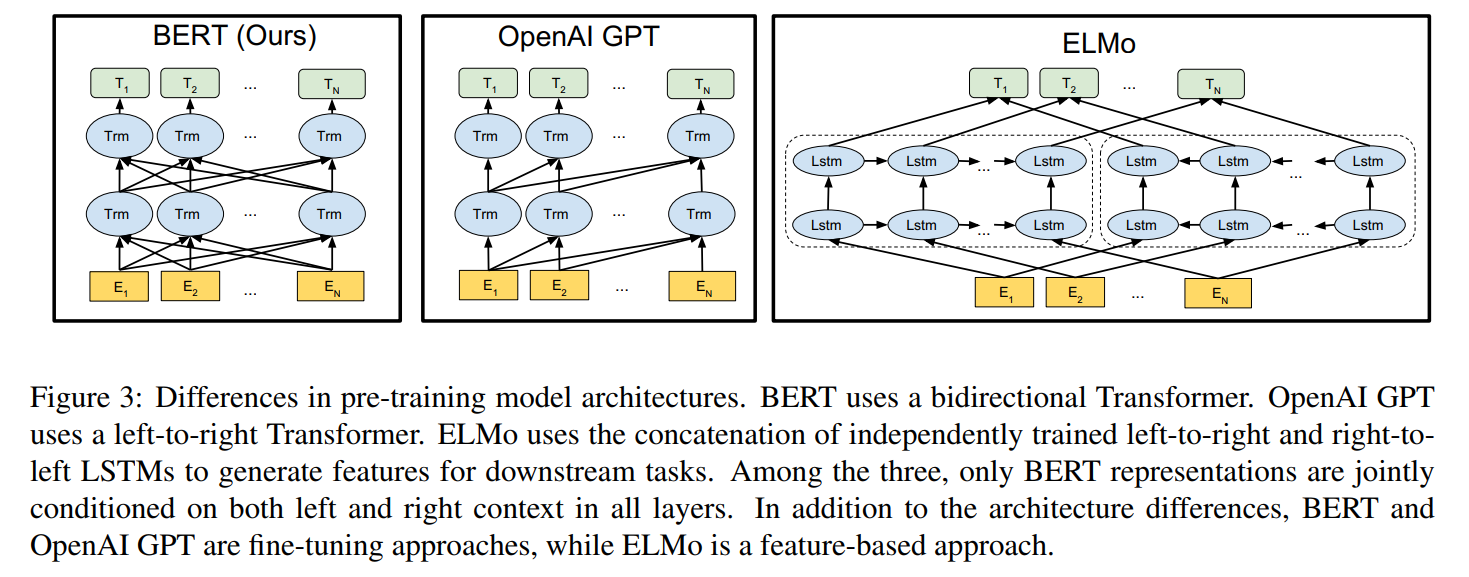
预训练语言模型的万恶之源。
模型结构:基本上就是Transformer
模型输入编码:
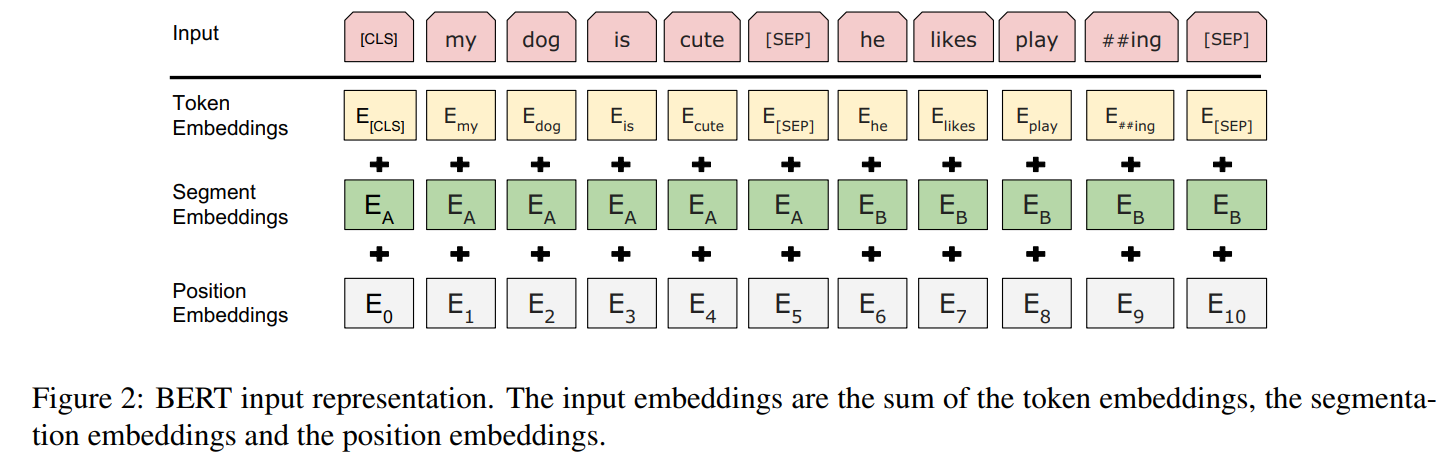
预训练任务:随机mask token并预测;next sentence prediction(输出2个句子是否是上下句) - (2018 NAACL) ELMo
原论文里没有配图,可以直接参考上面BERT给出的配图:大意来说就是模型框架是Bi-LSTM,在下游任务重直接使用Bi-LSTM得到token的表征作为词向量
Deep contextualized word representations
参考讲解博文:动态词向量算法 — ELMo - 简书 - (2018 ACL) ULFMiT
Universal Language Model Fine-tuning for Text Classification
2013年
工具包
- 框架
- PyTorch
- TensorFlow
- Keras
- transformers
- OpenBMB
- LangChain
- PEFT
- BMTools
- Megatron
NVIDIA/Megatron-LM: Ongoing research training transformer models at scale
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism - MLC LLM | Home:将LLM本地部署到任何硬件后端和本地应用程序上
- LlamaIndex - Data Framework for LLM Applications
- 大模型量化:OpenGVLab/OmniQuant: OmniQuant is a simple and powerful quantization technique for LLMs.
- vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs
- SwanHub - 创新的AI开源社区
- 文本表征:https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
- 本地部署聊天机器人:https://dify.ai/
- turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs
- 大模型评估:OpenCompass
- zejunwang1/LLMTuner: 大语言模型指令调优工具(支持 FlashAttention)
- swift/README_CN.md at main · modelscope/swift
- alibaba/data-juicer: A one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs! 🍎 🍋 🌽 ➡️ ➡️🍸 🍹 🍷为大语言模型提供更高质量、更丰富、更易”消化“的数据!
其他在本文撰写过程中使用的参考资料
- 还没看完
- 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎
- DSXiangLi/DecryptPrompt: 总结Prompt&LLM论文,开源数据&模型,AIGC应用
- BERT时代与后时代的NLP - 知乎:太长了,看了一点,没撑下去,以后慢慢看吧
- 想以后看所有顶会顶刊、高引、大机构、名人的论文,然后做超全面的检索……感觉不太可能,不如调教LLM帮我实现这件事。
ACL2023:LLM相关论文总结 - 知乎 - Generalized Language Models | Lil’Log
- 图解BERT、ELMo(NLP中的迁移学习)| The Illustrated BERT, ELMo, and co._图解bert, elmo, and co.-CSDN博客
- Top 15 Pre-Trained NLP Language Models
GLM官方推文介绍:【发布】多模态 VisualGLM-6B,最低只需 8.7G 显存 ↩︎
见https://github.com/huggingface/transformers/blob/main/src/transformers/models/longformer/modeling_longformer.py:
 ↩︎
↩︎参考我在该项目下提出的issue:如直接使用LongformerTokenizer会报此错,是否需要使用BertTokenizer? · Issue #2 · ValkyriaLenneth/Longformer_ZH ↩︎
text-to-text-transfer-transformer/released_checkpoints.md at main · google-research/text-to-text-transfer-transformer ↩︎
如何评价NLP算法ELECTRA的表现? - 知乎:很多内容还没看 ↩︎















 1247
1247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











