







诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Mention Memory: incorporating textual knowledge into Transformers through entity mention attention
模型名称:TOME (Transformer Over Mention Encodings)
ArXiv网址:https://arxiv.org/abs/2110.06176
OpenReview网址:https://openreview.net/forum?id=OY1A8ejQgEX
官方代码:https://github.com/google-research/language/tree/master/language/mentionmemory
本文是2022年ICLR论文,作者来自南加州大学和谷歌。
本文也是关注如何在LM中引入实体知识。
mention memory:语料库中所有entity mention的表征(在使用LM时是冻结的)
TOME是从这个实体表征库里检索除稠密向量,然后融合到LLM中
模型能在未出现的实体上表现出泛化能力。
这篇读得比较简陋,很多内容还没看懂。只写了一些我认为比较重要且看懂了的要点。
1. 研究背景与研究内容
以前的方法:virtual knowledge base (VKB)构建实体mention的稠密表征以反应关系
本文将VKB应用于LM,作为外部知识库
TOME:mention encoder→构建英文维基百科中150M实体mention的表征库(mention memory)→通过sparse attention的方式将实体表征结合到Transformer中
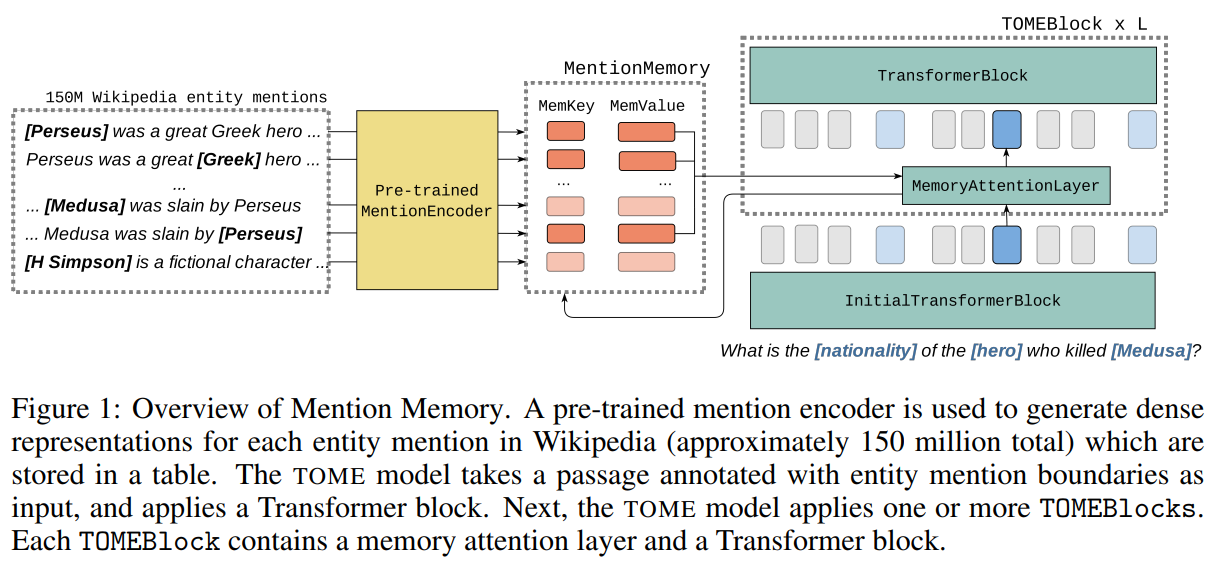
优势是不用对输入文本进行特殊处理,不用检索阅读长文本,省时间,而且也不用受上下文长度限制。而且不用监督信息(也可以监督)。
直接联合训练代价太大了,所以是分两步训练的:Mention Encoder(得到Mention Memory)→TOME
TOME中输入文本用NER系统对每个mention加了特殊tokens:What is the [Estart] nationality [Eend] of the [Estart] hero [Eend] who killed [Estart] Medusa [Eend]
span的表征是开头和结尾表征的线性转换:
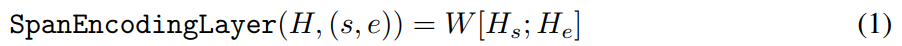
TOMEBlock:
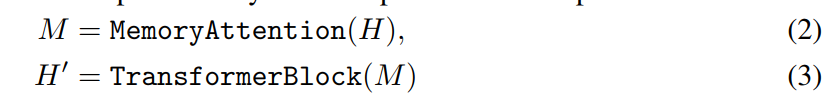
TOME:

TOME-1 & TOME-2
1. MemoryAttention

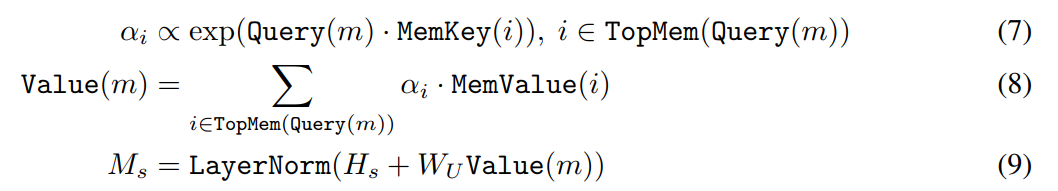
2. ANNS
3. Mention Encoder预训练
加了个TOME尾巴进行预训练
预训练目标:MLM+指代消解(根据表征相似性)
4. TOME预训练
预训练目标:预测实体
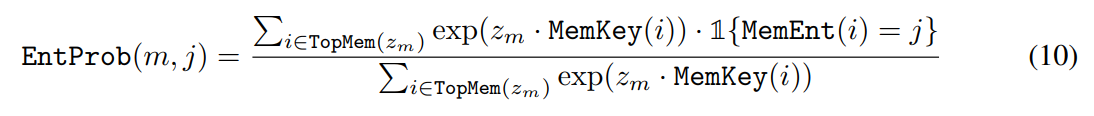
Disallowed same passage retrieval:删掉同文实体
2. 实验
claim verification:判断维基百科是否支持某一claim
没有使用参考检索章节
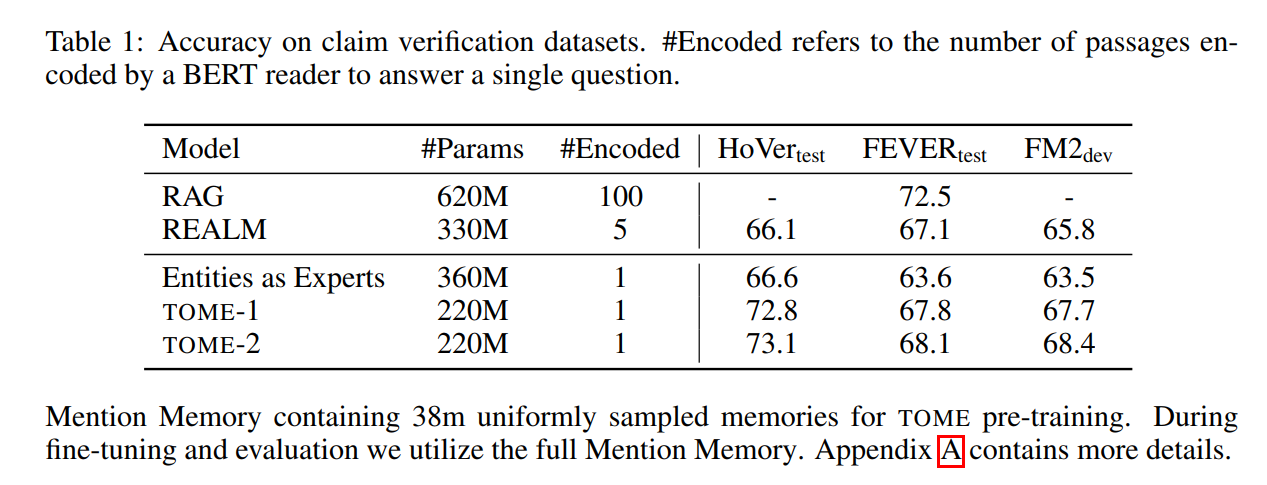
QA:只要有实体的
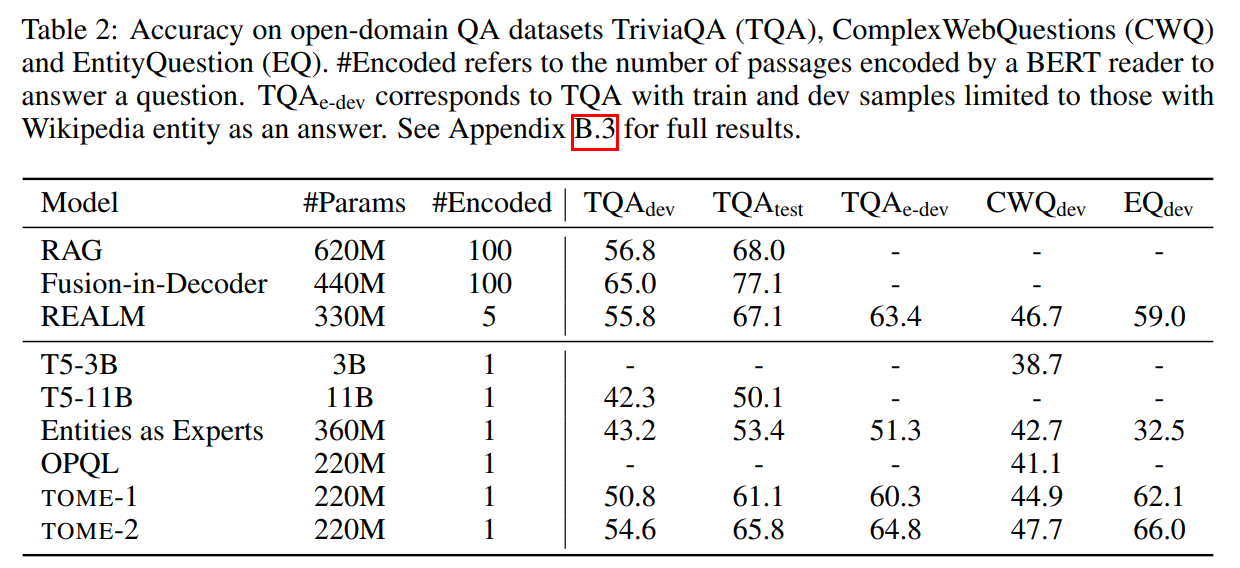


memory尺寸越大,效果越好:
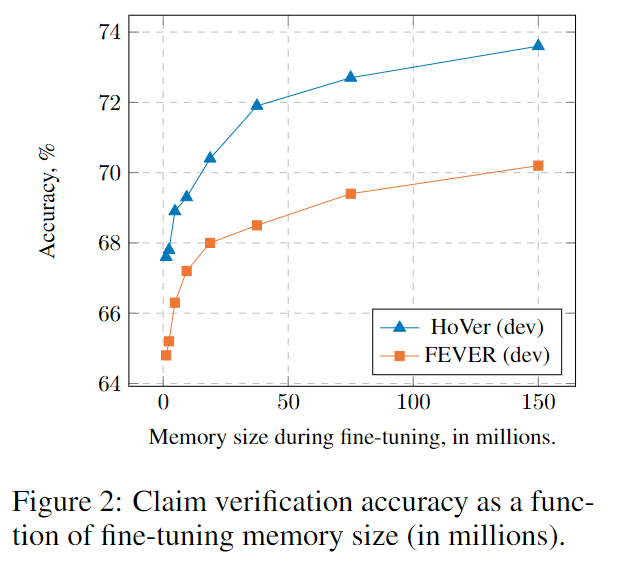
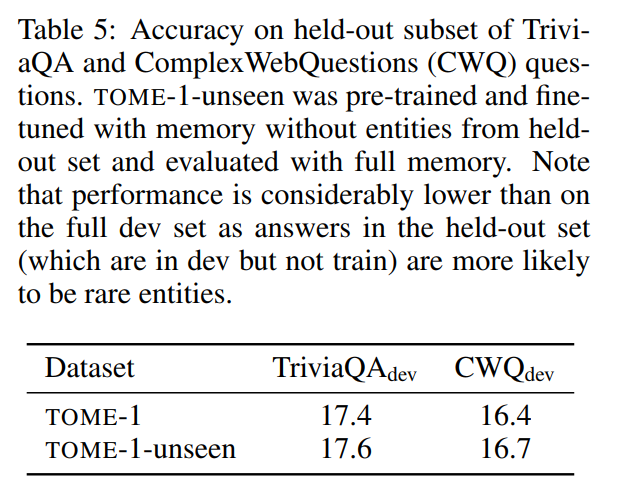
零样本泛化能力:
3. 其他
这个附录里面ANNS这块我还挺感兴趣的,但是有点太底层了,如果以后需要研究的话可以回来看看。
看了一下openreview上的评价,有两点比较在乎:
Reviewers generally found the paper is solid. However, the novelty appears to be limited and is mainly in the combination of existing models.… 还行吧这还不够novel
这个Bender rule我去查了一下,意思是说,不要以为研究英语就能代表研究所有语言了,如果你的论文只研究了英语,你应该指明你只研究了英语。
(打击文化霸权,我辈义不容辞!)
参考资料:NLP被英语统治?打破成见,英语不应是「自然语言」同义词(原文:https://thegradient.pub/the-benderrule-on-naming-the-languages-we-study-and-why-it-matters/)
















 2602
2602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











