







诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Training Verifiers to Solve Math Word Problems
GSM8K数据集原始论文
OpenAI 2021年的工作,关注解决MWP问题(具体场景是小学(grade school)数学题),训练模型关注其错误,重复尝试,直至找到正确解法。
因此本文训练verifier检测解决方案是否正确。
在小模型上,verifier可以使模型提升到与大模型靠近的程度。
数据集越大,verifier效果越好。小数据集上没用。
论文ArXiv链接:https://arxiv.org/abs/2110.14168
官方GitHub项目:openai/grade-school-math
官方博文:https://openai.com/research/solving-math-word-problems
verifier这个想法当然很好,除了成本看起来就很高之外……
另外就是看论文中的暗示,这个优秀的模型效果也是靠调参调出来的啊。哎调参嘛本来就是建模的一部分,我一点都没有在酸!
2024.5.26补:我复现完代码跟网友讨论了一下发现论文里很多地方说得非常含混。总之这个idea也许是可资借鉴的,但是这个代码是别指望能完全复现的。我的复现方案是可供参考的。
有些复现过程中的思考内容内容我补在本文了
文章目录
1. GSM8K数据集
含8.5K条数学题。
7.5K训练集,1K测试集
每个问题需要2-8步推理来求解。
数据集中的解法都是自然语言形式的。

此外还提供了一种“苏格拉底式提问”的数据(虽然在论文中压根没提这茬):
A carnival snack booth made $50 selling popcorn each day. It made three times as much selling cotton candy. For a 5-day activity, the booth has to pay $30 rent and $75 for the cost of the ingredients. How much did the booth earn for 5 days after paying the rent and the cost of ingredients? How much did the booth make selling cotton candy each day? ** The booth made $50 x 3 = $<<50*3=150>>150 selling cotton candy each day. How much did the booth make in a day? ** In a day, the booth made a total of $150 + $50 = $<<150+50=200>>200. How much did the booth make in 5 days? ** In 5 days, they made a total of $200 x 5 = $<<200*5=1000>>1000. How much did the booth have to pay? ** The booth has to pay a total of $30 + $75 = $<<30+75=105>>105. How much did the booth earn after paying the rent and the cost of ingredients? ** Thus, the booth earned $1000 - $105 = $<<1000-105=895>>895.
质量控制是纯人工完成的,我好羡慕啊……
数据集是找人写了1000条(先用few-shot prompted 175B GPT-3 model生成seed问题),然后用Surge AI自动打标扩展,然后找人进行验证。
calculator annotation是由硬编码的逻辑和LLM联合生成的,在训练时就放在一起训练,在测试时直接用calculator(eval())重算答案(在检测到=出现后,调用calculator,计算figure 1中的红色部分左式,得到计算答案,覆盖红色部分),如果出现非法表达式将直接重新抽样
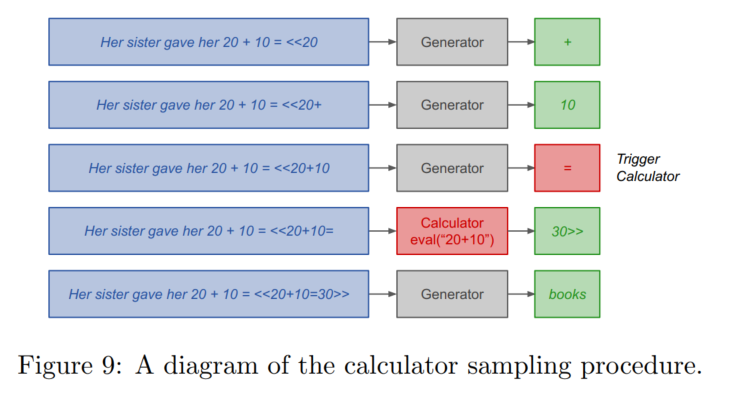
2. verifier
本文认为,LM的一个重要问题就在于容易因小错而产生失误(sensitivity,或者说不鲁棒),这是因为LM生成过程是autoregressive的,所以无法对之前生成的内容进行纠错。
verifier:评估模型生成解法的正确程度(token-level评估输出是否正确 + 联合训练语言模型目标函数)
verifier由generator初始化
(原理:分类一般比生成任务简单)
(存在推理错误,但是结果正确的场景)
在训练时同时训练验证任务和语言模型任务(训练时两种数据一样多,相当于对语言模型数据的100倍上采样)
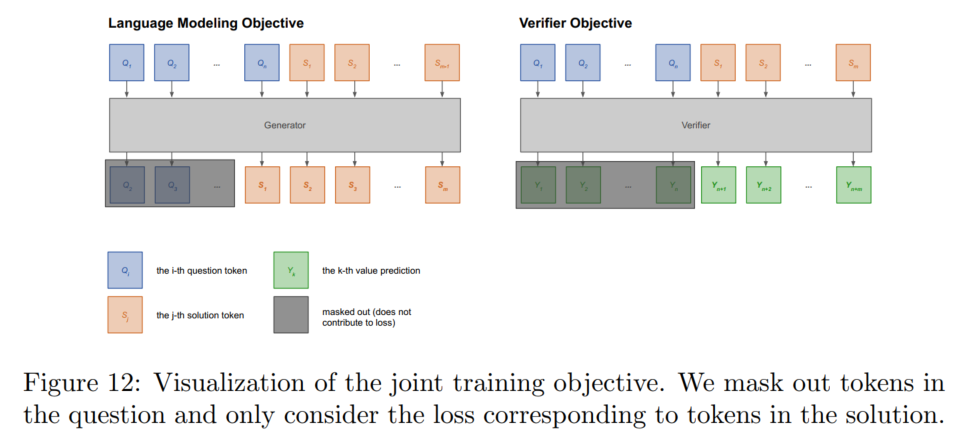
2024.5.26再补一下:我复现代码的时候LM学习目标加了mask,verifier学习目标忘加了。但是这个好加如果你们要复现的话自己加一下得了。
这个什么方法,细节又多,讲得又含混,又没给复现代码,真难整。
真受不了OpenAI啊,这里面有什么核心机密不能讲吗,我也没看GPT-4比其他几个大模型计算数学题的能力强到哪里去啊,有什么核心科技!
在测试时,让模型生成100个解决方案,选择verifier排序最高的解决方案,作为输出。
(或许这个verifier也可以被叫做,模型聚合。加强版投票吧感觉。不知道以前机器学习那边做模型聚合有没有用过这种第二阶段的验证器(或者叫排序器?打分器)哈,应该有的吧)
2024.5.26补一下:这个打分机制论文里没提到底用的是什么打的分,我在复现时直接忘记这个排序机制了,直接让verifier输出一个答案的……我复现用的是token-level分类头,如果用的是solution-level分类头,直接用这个分数来作为整个solution的分数似乎还挺合理的,但是token-level的话……怎么算出solution-level的分来的?
网友的猜测是每个token的打分求平均(哦好怪)
本文主要考虑两种解决方案:微调和验证(具体计算都用的是calculator,训练2个epoch(原因见第3节讲的figure 3))
微调:微调GPT-3并采样低temperature(0)结果
验证:采样一堆temperature(0.7)结果(generator),然后给每个输出进行打分(verifier),选择分值最高的结果(generator和verifier的尺寸一样,语言模型目标一样)
验证在训练时选择标签,是如果这个采样结果得到了正确答案就算正确。有时推导过程错误,但能得到正确结果(假阳性),但是这个问题本文不解决。先训练出generator,用generator生成100倍verifier训练样本,用以训练verifier
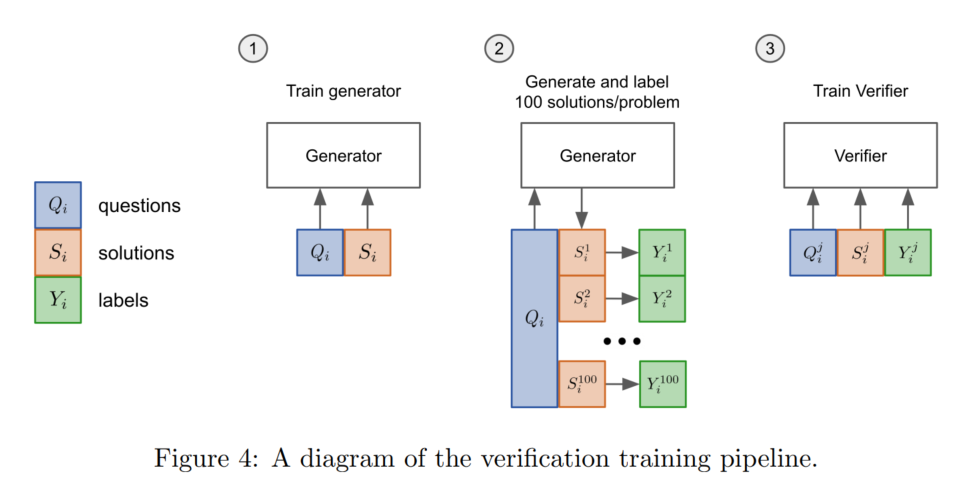
之前的工作中,有类似做法的:
- (2020 SIGGRAPH MIG) Collaborative Storytelling with Large-scale Neural Language Models:抽样→排序,根据人工偏好得到训练信号
- (2021 EMNLP Findings) Generate & Rank: A Multi-task Framework for Math Word Problems:联合训练生成和排序
本文选择不同的生成器和验证器,是为了防止生成器过拟合(但是原则上也可以一起train)
3. 实验结果
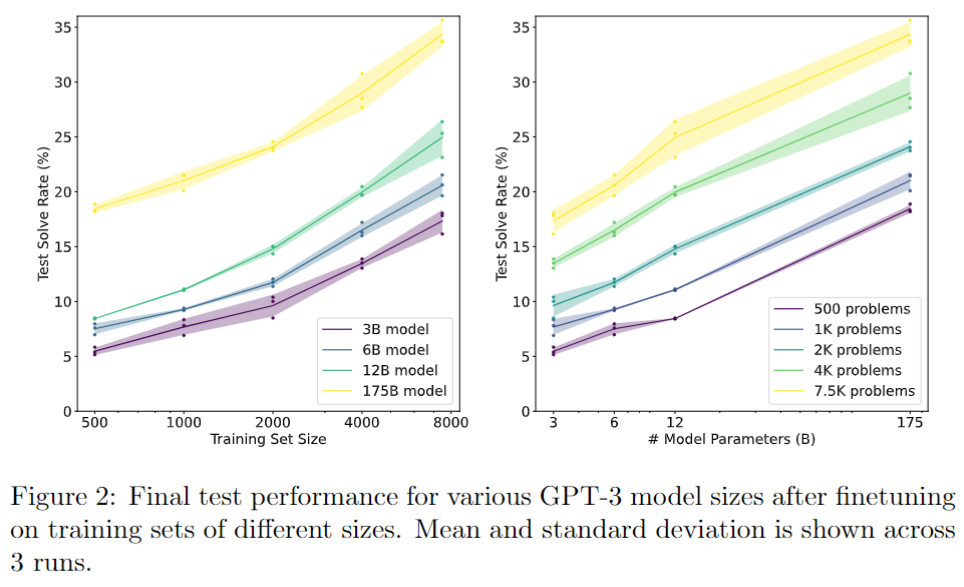
- GPT-3直接微调,在不同的训练集大小和不同的模型参数上,基本呈现出大力出奇迹的标准结局:
(这么大的模型还能算平均值和标准差,有钱真好啊)
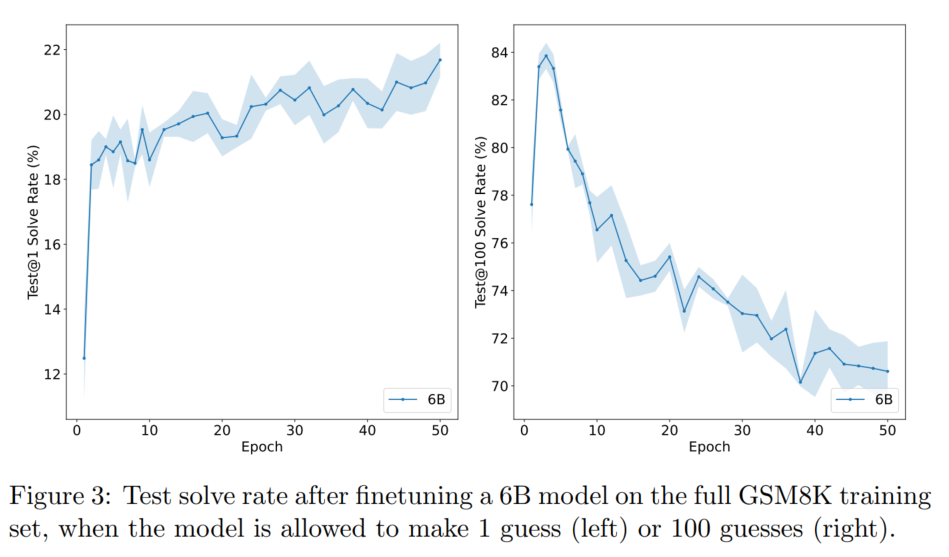
- 直接微调GPT-3后,test@N(N次测试中至少对一次)和迭代数之间的关系:test@1基本单调增长,但在测试集损失函数上过拟合;test@100迅速下降(本文认为是过拟合)
- 必须要先生成自然语言解释,再生成最终答案。如果直接生成最终答案,结果会从20.6%直接降到5.2%
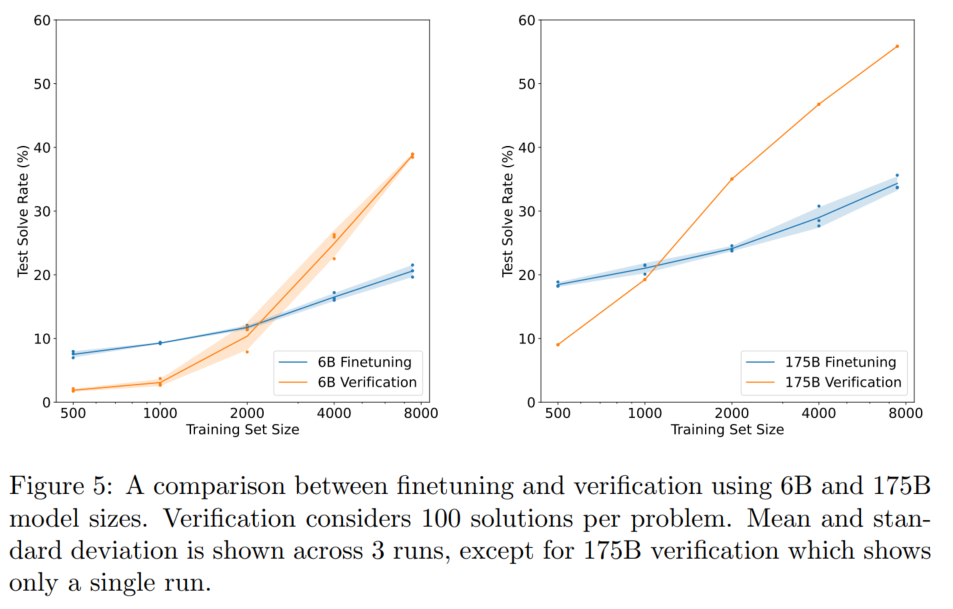
- 不同模型大小上verifier的实验结果(就算是OpenAI也没钱在175B的模型上算平均值和标准差了是吧)
在小数据集上verifier没用可能是因为过拟合
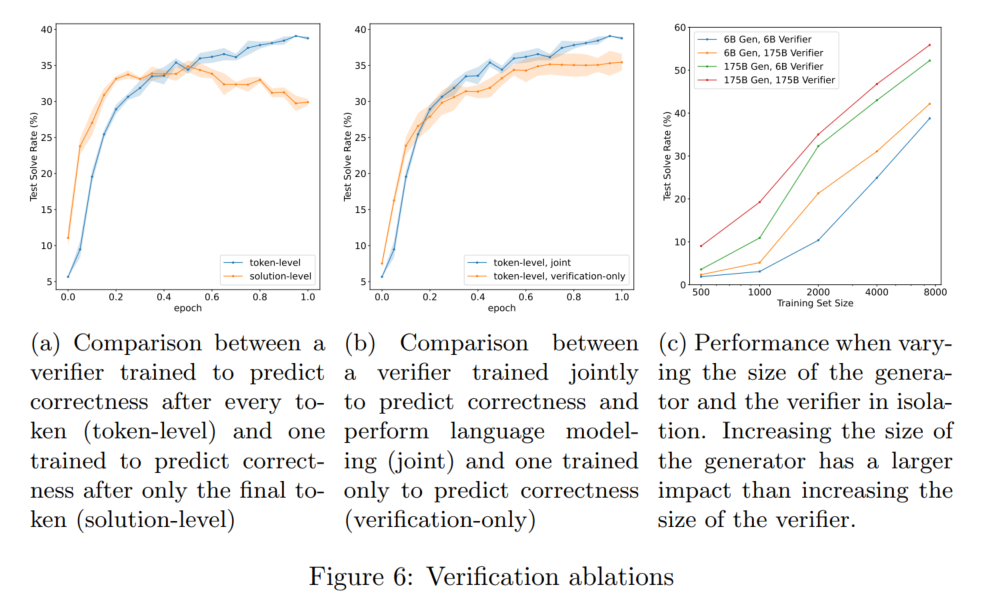
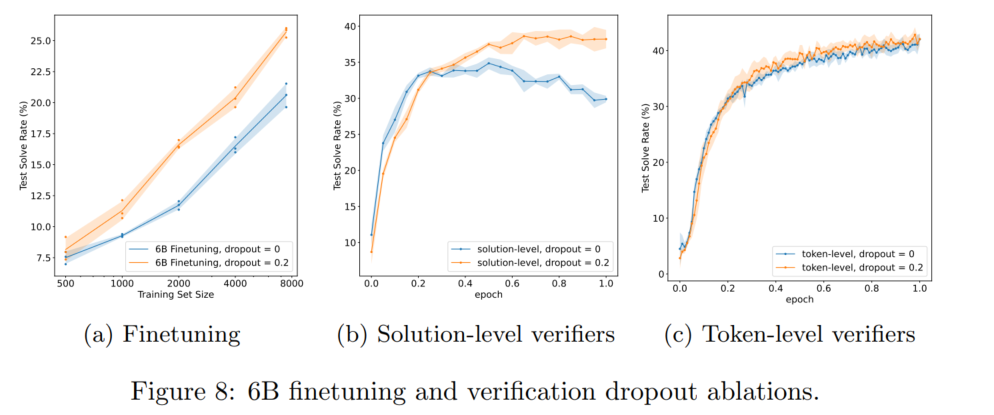
- ablation study
图a我不太确定,我的理解是token-level指的是将整个自然语言结果的每一个token都和生成结果算损失函数,solution-level指的是只考虑最后生成的数值是否正确。也就是说token-level的分类头是对每个token都有输出的
图b本文认为是因为模型了解语言分布有益于区别不同的生成结果
图c的结论比较意识流,本文认为这说明verifier是模糊启发式直觉选手,而不是认认真真在做验证
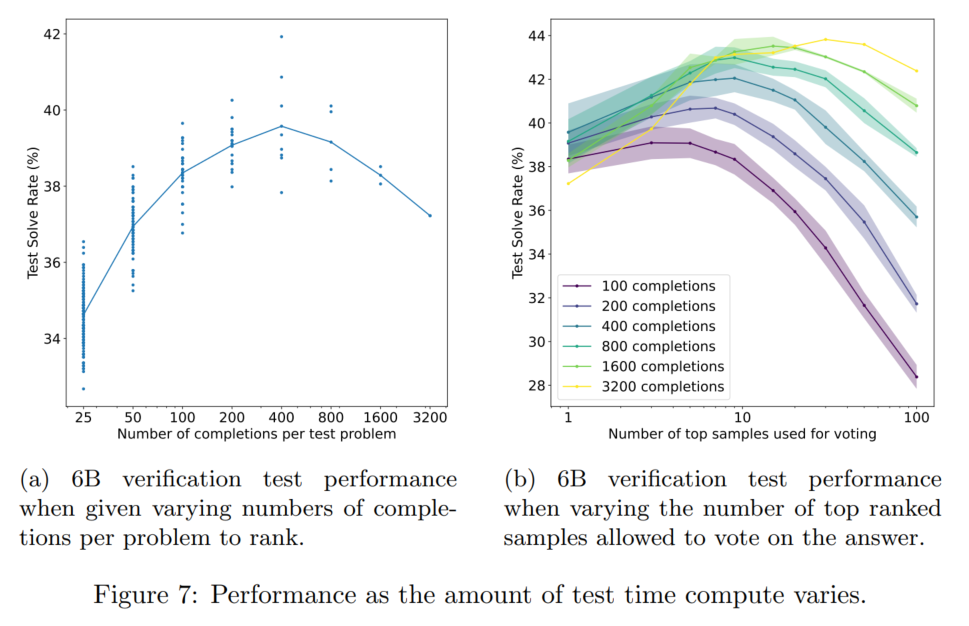
- 测试时的计算次数
图a就是直接在测试结果中选打分最高的一项
图b是选择排序最前的这么多测试结果,进行投票
- dropout正则化是牛逼的,但是verifier更加牛逼
residual dropout(transformer同款)因为GPT-3没有用dropout,所以本文在用dropout微调之前还加了用dropout预训练,以防数据漂移
dropout概率是hyperparameters sweep搜出来的,牛逼吧……有钱真好啊……
这句话我是真没搞懂:Note that we increase the batch size for token-level verifiers by a factor of 4, to better handle the more difficult objective and the noise from dropout.这是什么我不知道的理论吗? - 附录B的这个超参是啥意思我也没搞懂:

超参设置:

(2024.5.26补:我复现时候没意识到verifier的损失函数居然是MSE,我直接用了BCE,因为我是当多标签分类来做了。MSE的逻辑就是让logit更靠近0/1
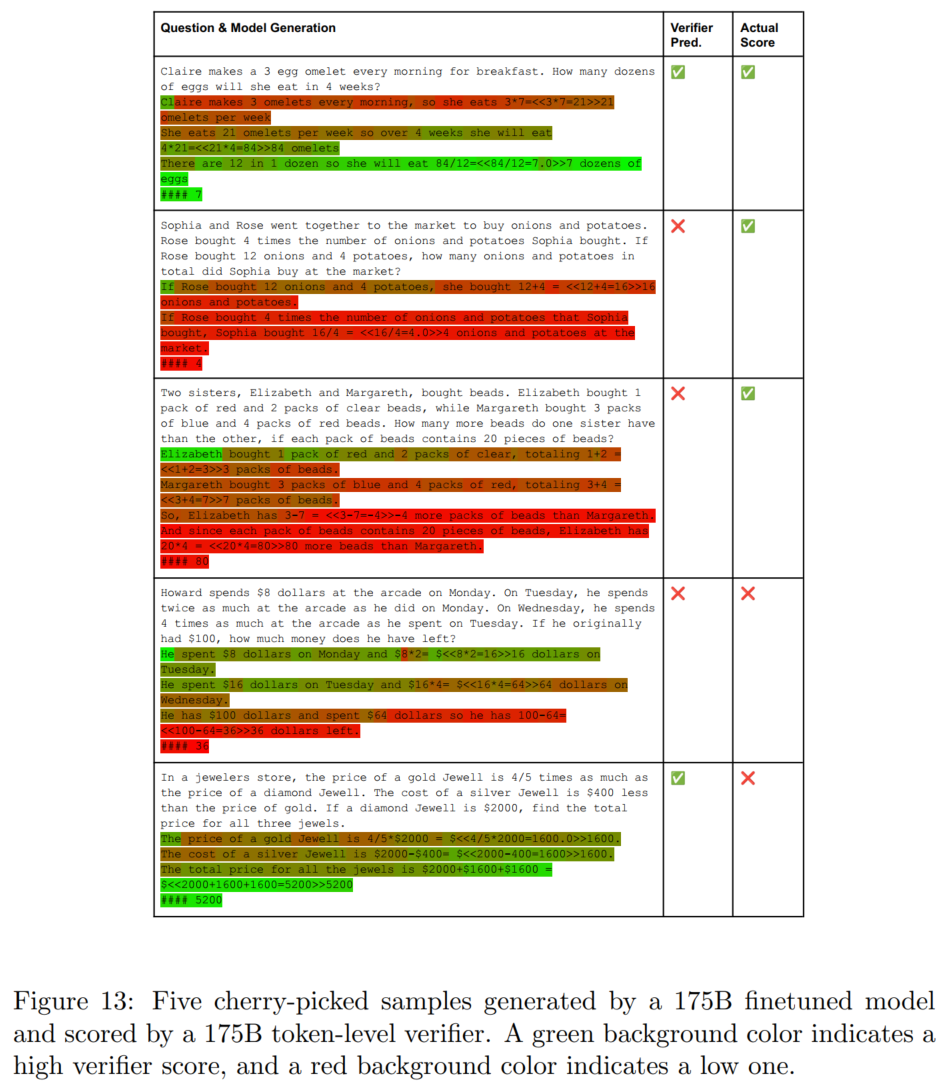
我不清楚多标签分类和用0/1回归损失函数的区别哈……总之大家如果需要跑代码的时候注意一下这点) - verifier可视化
4. 复现
1. 官方GitHub项目内容整理
没有给出具体的实验代码,只给了一些参考工具脚本(都没有经过优化,“又不是不能用.jpg”)
- 数据集
用于实验的数据:https://github.com/openai/grade-school-math/blob/master/grade_school_math/data/train.jsonl和https://github.com/openai/grade-school-math/blob/master/grade_school_math/data/test.jsonl
苏格拉底式提问的数据:https://github.com/openai/grade-school-math/blob/master/grade_school_math/data/train_socratic.jsonl和https://github.com/openai/grade-school-math/blob/master/grade_school_math/data/test_socratic.jsonl - 调用calculator的示例:https://github.com/openai/grade-school-math/blob/master/grade_school_math/calculator.py
- https://github.com/openai/grade-school-math/blob/master/grade_school_math/dataset.py:构建数据集的工具脚本
小编其实还蛮好奇为什么要在前缀也计算损失函数的,意思是在纯微调时就直接微调整个LM吗……但是OpenAI这么干想必有他们的道理……所以我就这么写了┓( ´∀` )┏ - GPT-2微调的代码:https://github.com/openai/grade-school-math/blob/master/grade_school_math/train.py
- GPT-2推理的代码:https://github.com/openai/grade-school-math/blob/master/grade_school_math/sample.py
2. 直接跑一遍GPT-2微调
LLM的部分跟别的LLM其实差不多,只是GSM8K多了一个调用calculator的部分。
参考官方代码和transformers的新功能。
我在我自己的集成项目里已经实现了GPT-2微调在GSM8K上的代码:
3. GPT-2 + verifier
GPT-3毕竟没有开源,所以只能拿GPT-2当代餐了。
然后这个代码也我自己写的,不一定符合OpenAI的意思。而且我用的是117M的小小GPT-2 233,所以效果嘛……
第一阶段:训练generator https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/finetune.py
第二阶段:生成verifier训练集 https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/verifier2_generate_verifier_train_data.py
第三阶段:训练verifier
https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/verifier3_train_verifier.py
第四阶段:测试verifier生成效果
https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/test_w_calculator.py
复现过程中不足之处:① 没用GPT-3,首先我没有GPT-3。② verifier数据集其实应该是100 × MWP数据集那么多,我没跑完。③ 训练verifier的过程中用的是BCELoss而不是MSELoss。……怎么会是MSE啊真奇怪啊。④ 训练verifier的过程中没给verifier的学习目标加mask ⑤ 推理时应该用verifier采样100个样本然后打分打出最高分样本,我完全忘了这茬直接推理了。但俺也不知道这个verifier到底怎么打分的,solution-level的好理解,token-level的是咋回事?经与网友讨论,我们一致怀疑,是求平均。真是搞不懂他们OpenAI


















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











