







前面我们介绍了PG中的Concurrent VACUUM,详细请参考PostgreSQL之Concurrent VACUUM,这篇我们继续来了解一下PG中的Full VACUUM。
我们了解Concurrent VACUUM允许在执行的时候仍然允许对正在VACUUM的表进行读取操作,因此这个操作对业务的影响也比较小。但是Full VACUUM在执行期间是不允许对相关表进行任何操作的,所以它对业务的影响也比较大,那么为什么还需要Full VACUUM呢?
我们假如以下一种场景,一个表有三个Page,每个Page里面有6条Tuple,如下图所示。
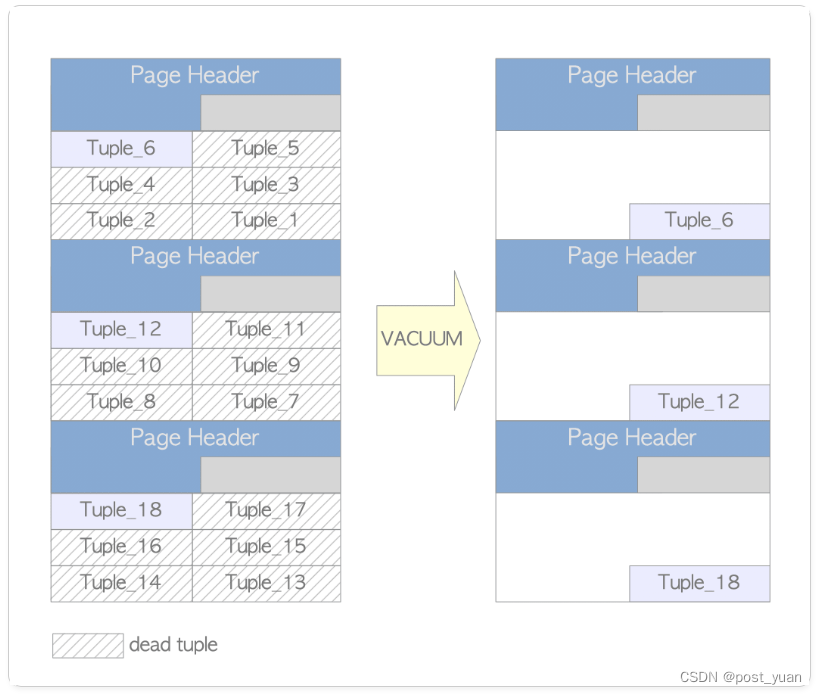
然后我们执行以下操作,
testdb=# DELETE FROM tbl WHERE id % 6 != 0;
testdb=# VACUUM tbl;
VACUUM结束后,我们发现每个页面中现在只剩下一条Tuple了,不过仍然还是有三个Page存在。如果我们想查询这三条数据,那么仍然需要访问三个Page。由于每个Page是大小固定的,因此表的SIZE仍然没有变化。所以,Concurrent VACUUM动作后只是可以让页面中的部分空间可以重用,但是并不能真正释放空间。
为了解决真实可以释放空间这个问题,因此才有了Full VACUUM。
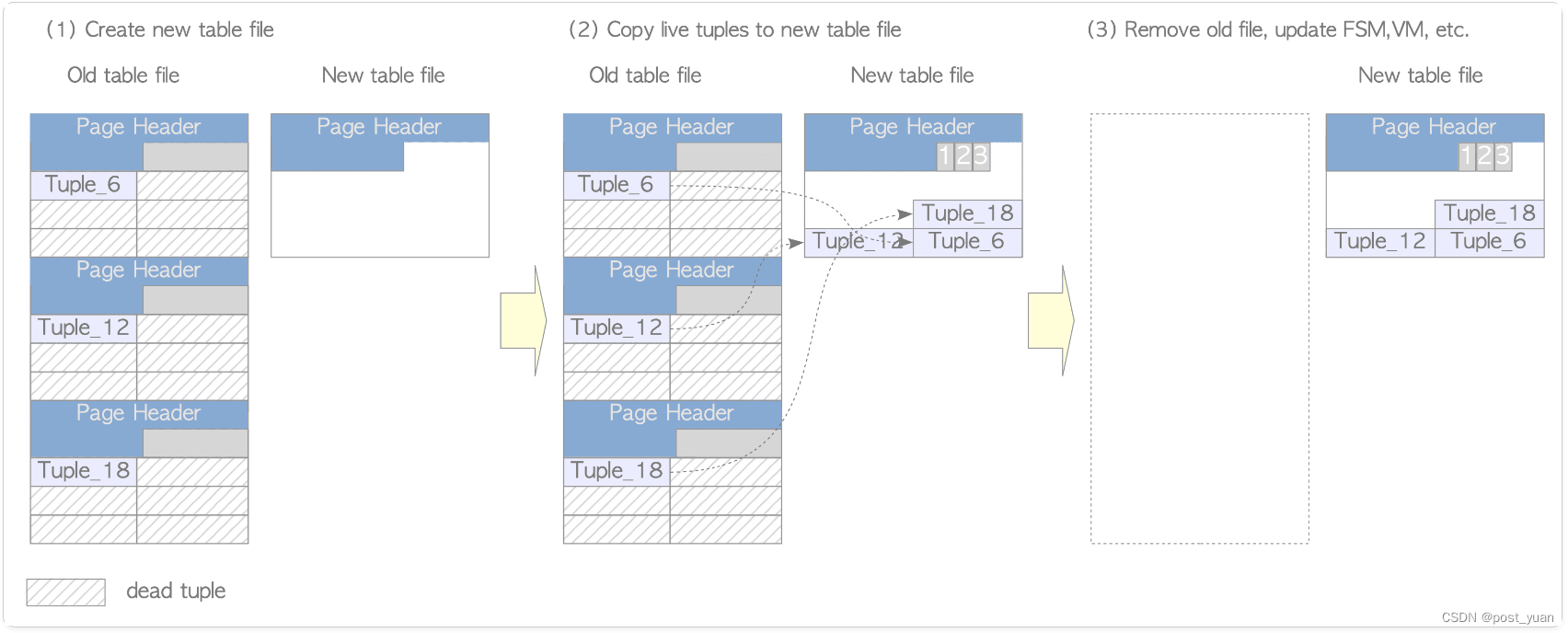 上图是Full VACUUM的整个过程,可以总结为以下步骤:
上图是Full VACUUM的整个过程,可以总结为以下步骤:
- 创建新文件 -当针对某个表调用VACUUM FULL命令时,首先会获取表上的AccessExclusiveLock锁,然后创建一个新的表文件(大小为8KB),此后表不能被读写。
- 将活跃的tuples拷贝到新文件 -将老文件中活跃的tuples拷贝到新的文件中。
- 删除老文件,重建索引,更新统计信息、FSM及VM -在完成拷贝活跃tuples到新文件后,删除老的文件,然后重建索引,更新表对应的FSM和VM文件,更新相关的统计信息及数据。
Full VACUUM步骤的伪代码如下:
(1) FOR each table
(2) Acquire AccessExclusiveLock lock for the table
(3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











