







 参考了N篇博客和机器学习实战写出来这个。1.关于分类和聚类:共同点是都是对数据进行分类。不同点:分类是事先知道分类数据具有哪些类型(特点、属性),然后对数据进行归类。聚类的已知信息只有数据,然后根据对数据的特点、属性将数据分出类别。2.Kmeans:(1)Kmeans算法原理: 初始条件:给出数据和**指定的K值**,K值是指这些数据需要分出多少类,**这里的类也被叫做簇**。
参考了N篇博客和机器学习实战写出来这个。1.关于分类和聚类:共同点是都是对数据进行分类。不同点:分类是事先知道分类数据具有哪些类型(特点、属性),然后对数据进行归类。聚类的已知信息只有数据,然后根据对数据的特点、属性将数据分出类别。2.Kmeans:(1)Kmeans算法原理: 初始条件:给出数据和**指定的K值**,K值是指这些数据需要分出多少类,**这里的类也被叫做簇**。
参考了N篇博客和机器学习实战写出来这个。
1.关于分类和聚类:
共同点是都是对数据进行分类。
不同点:
分类是事先知道分类数据具有哪些类型(特点、属性),然后对数据进行归类。
聚类的已知信息只有数据,然后根据对数据的特点、属性将数据分出类别。
2.Kmeans:
(1)Kmeans算法原理:
初始条件:给出数据和**指定的K值**,K值是指这些数据需要分出多少类,**这里的类也被叫做簇**。
分类的依据:根据数据之间的相似程度,一般来说是把**数据点之间的距离大小作为数据间的相似程度**。
算法思想:
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数(2)簇的介绍:
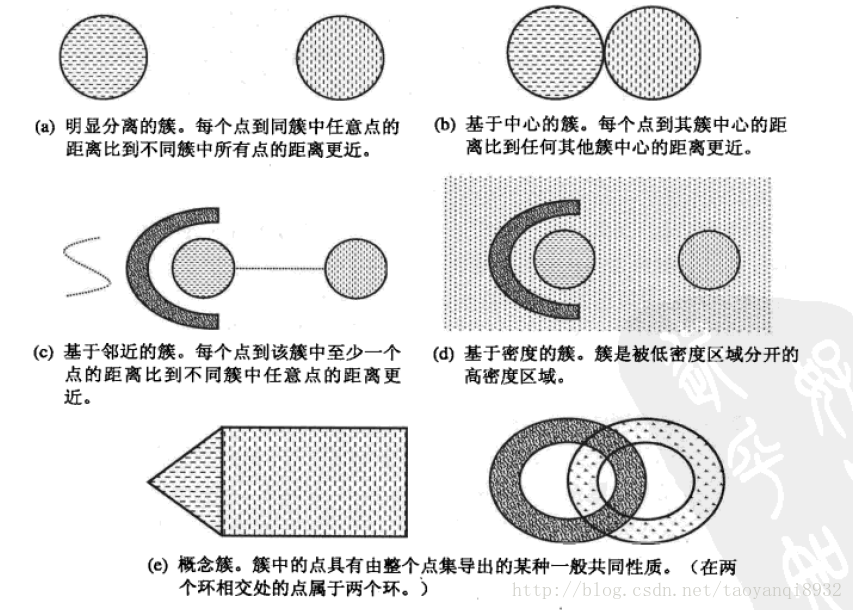
明显分离的
可以看到(a)中不同组中任意两点之间的距离都大于组内任意两点之间的距离,明显分离的簇不一定是球形的,可以具有任意的形状。
基于原型的
簇是对象的集合,其中每个对象到定义该簇的原型的距离比其他簇的原型距离更近,如(b)所示的原型即为中心点,在一个簇中的数据到其中心点比到另一个簇的中心点更近。这是一种常见的基于中心的簇,最常用的K-Means就是这样的一种簇类型。
这样的簇趋向于球形。
基于密度的
簇是对象的密度区域,(d)所示的是基于密度的簇,当簇不规则或相互盘绕,并且有早上和离群点事,常常使用基于密度的簇定义。
(3)距离类型的介绍:
常见的距离:

(4)质心的重新计算:
根据SSE公式来计算质心,全称是误差平方和公式,SSE值越小说明该质心越符合这些数据点的中心。
最后的结果是取所有簇内点的平均值作为新的质点。
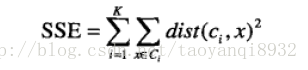
k表示k个聚类中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









