






我和很多学python的同学聊过,至少有30%以上的人学Python是为了网络爬虫,也就是采集网站的数据,不得不说这确实是一个刚性需求。
但一个残酷的事实是,即使一部分人学了Python,掌握了requests、urllib、bs4等爬虫技术,也无法有效地获取标的网站的数据。
因为无论是淘宝、京东、亚马逊、Ebay这样的购物网站,还是小红书、领英、tiktok这样的社媒平台,都会有各种反爬机制、动态页面来阻止异常流量。
所以你得了解逆向、解锁、IP代理等各种知识,才能真正的采集到想要的数据,这次我专门录了一个视频教程,告诉你如何简洁、有效地搞定反爬和动态页面。
如下视频教程:
推荐一款强大的网络爬虫工具,搞定反爬不是问题
视频里会讲到我常用的一个爬虫平台-亮数据,它提供数据采集浏览器、网络解锁器、数据采集托管IDE三种方式,能通过简单的几十行Python代码实现复杂网络数据的采集,对于反爬、验证码、动态网页等进行自动化处理,完全不需要你操心。

比如说通过亮数据解锁器抓取亚马逊网站智能手机商品名称和价格信息,可以实现批量无忧抓取。
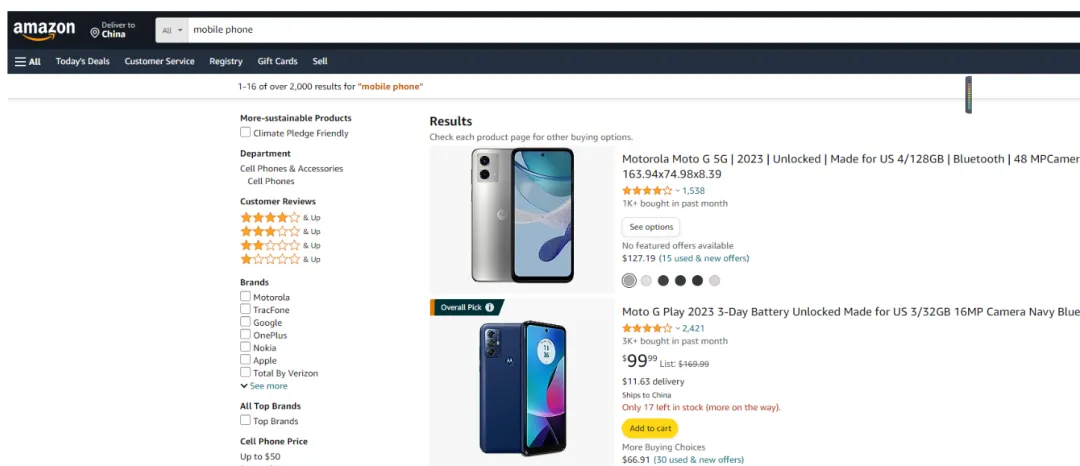
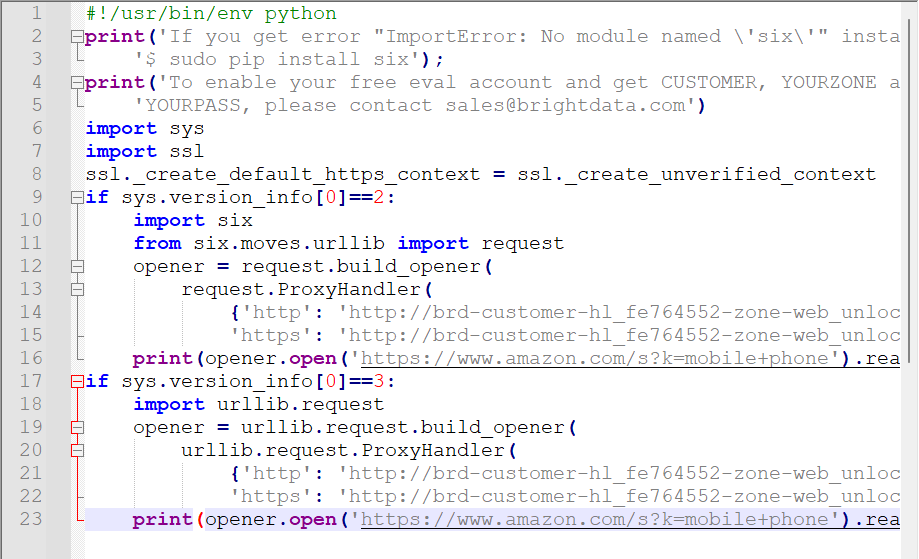
输出:

再比如使用亮数据浏览器抓取纽约时报新闻标题和发布时间数据
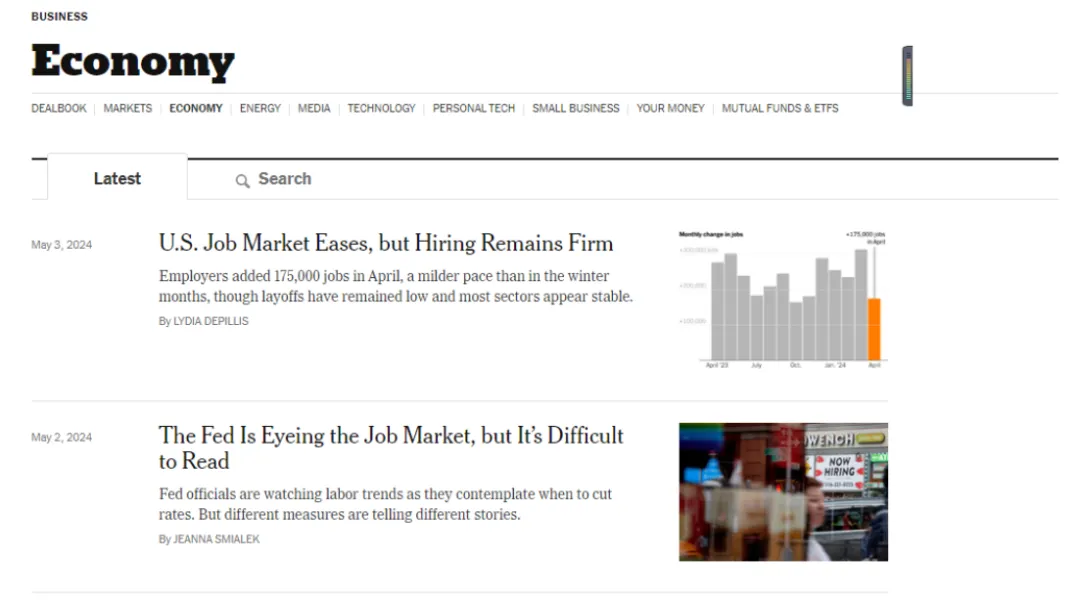
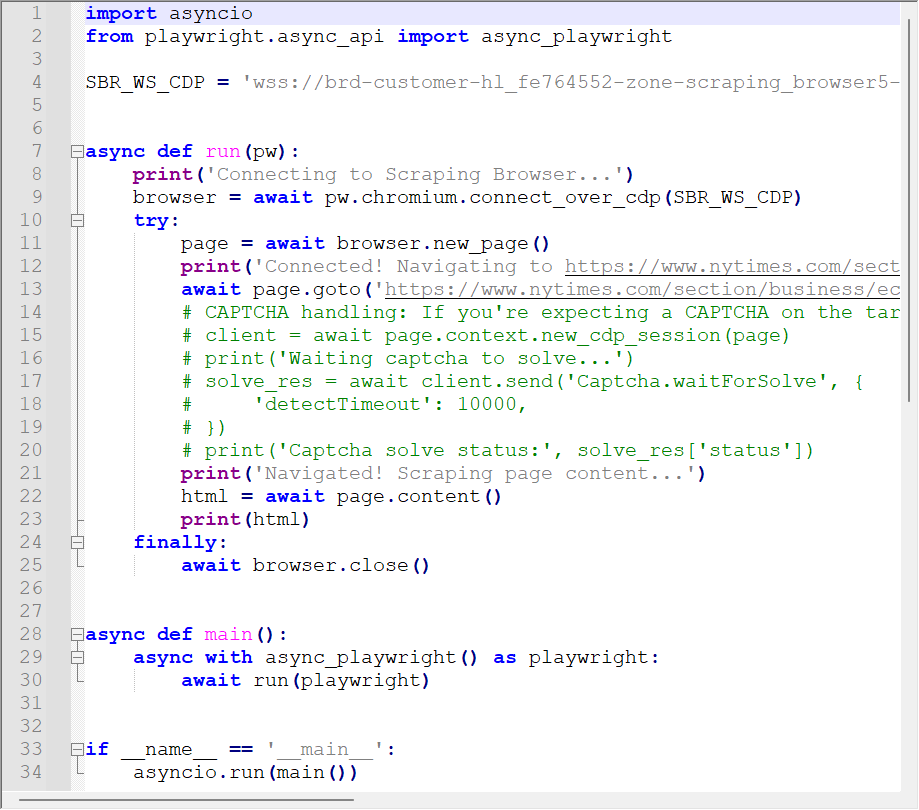

以上只是简单的示例,更复杂的数据抓取也都可以实现。
官网地址(点击原文链接也可查看):
https://get.brightdata.com/weijun
有数据抓取需求的可以试试,非常简单,能节省大量时间和精力!!!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











