







系列文章目录
项目一:服装分类助手
文章目录
前言
随着人工智能的快速发展和深度学习算法的日益成熟,卷积神经网络(Convolutional Neural Network,简称CNN)作为一种高效而强大的模型,在图像处理任务中取得了巨大成功。其中一项重要应用领域是服装分类助手。借助CNN技术,我们可以建立一个自动的服装分类助手,为消费者提供更便捷、准确的服装推荐和选购指导。
通过使用卷积神经网络进行服装分类,我们可以从一张商品图片中提取出关键特征,如颜色、纹理、形状等。这些特征能够帮助我们识别不同类型的服装,如衬衫、裙子、裤子等。而卷积层和池化层的堆叠可以使网络更好地捕捉图像中的局部模式和整体结构,并具备对尺度和平移变换的鲁棒性。
在构建卷积神经网络的过程中,我们还可以通过引入预训练模型和数据增强技术来提高分类器的性能。预训练模型通常是在大规模图像数据集上训练得到的,并具备对于图像特征的良好抽取能力。而数据增强则可以通过对输入图像进行旋转、缩放、平移等变换,产生更多样化、丰富的训练数据,从而提升模型的泛化能力。
一、项目介绍
本项目应用机器学习模型采用卷积神经网络,部署在Web环境中,通过Fashion-MNIST数据集进行模型训练和改进,实现网页端服装类别精准识别。
二、总体设计
本部分包括系统整体结构和系统流程
2.1 系统整体结构
系统整体结构如图2-1所示:
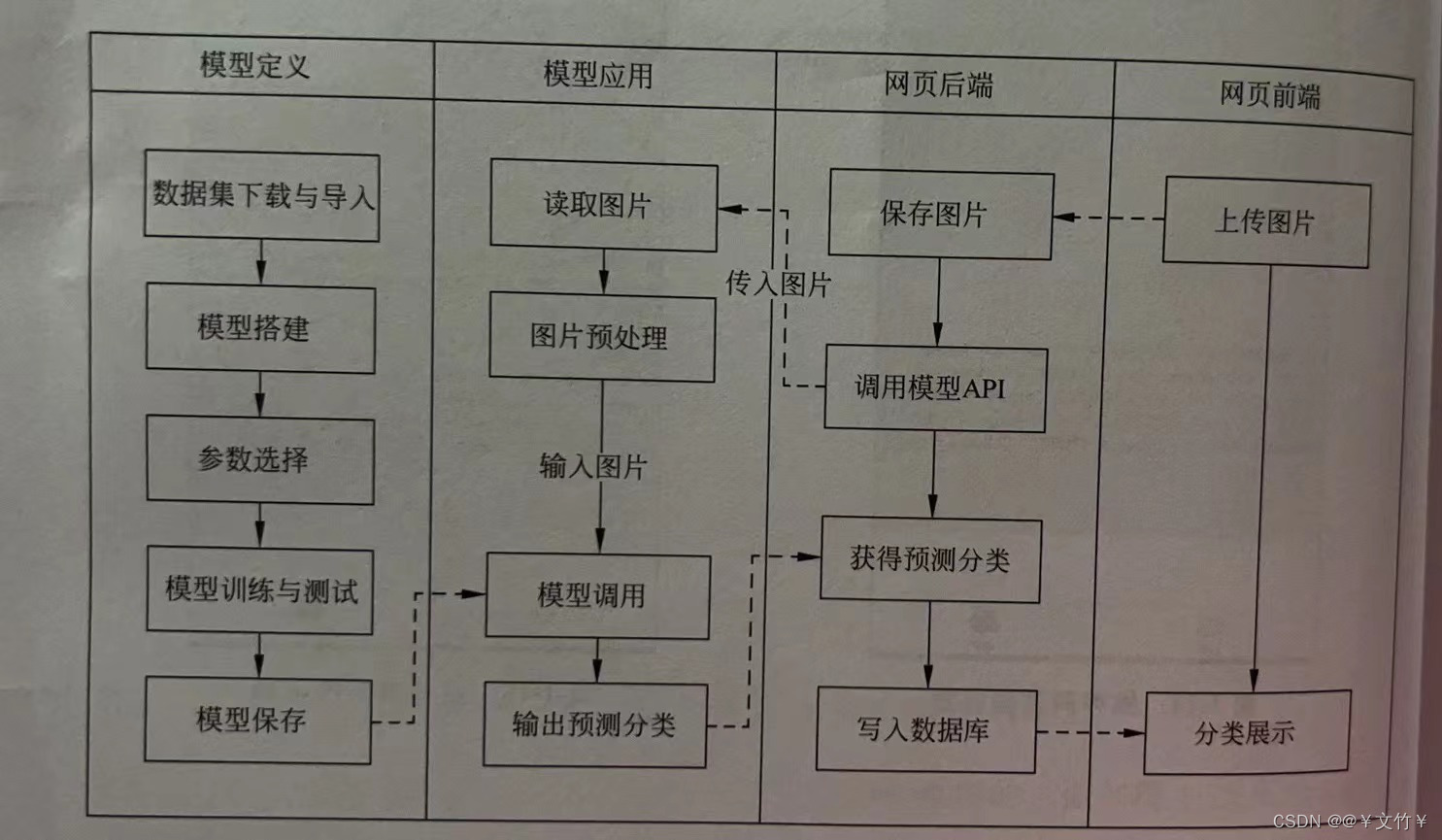
2.2 系统流程
系统流程如图2-2所示:
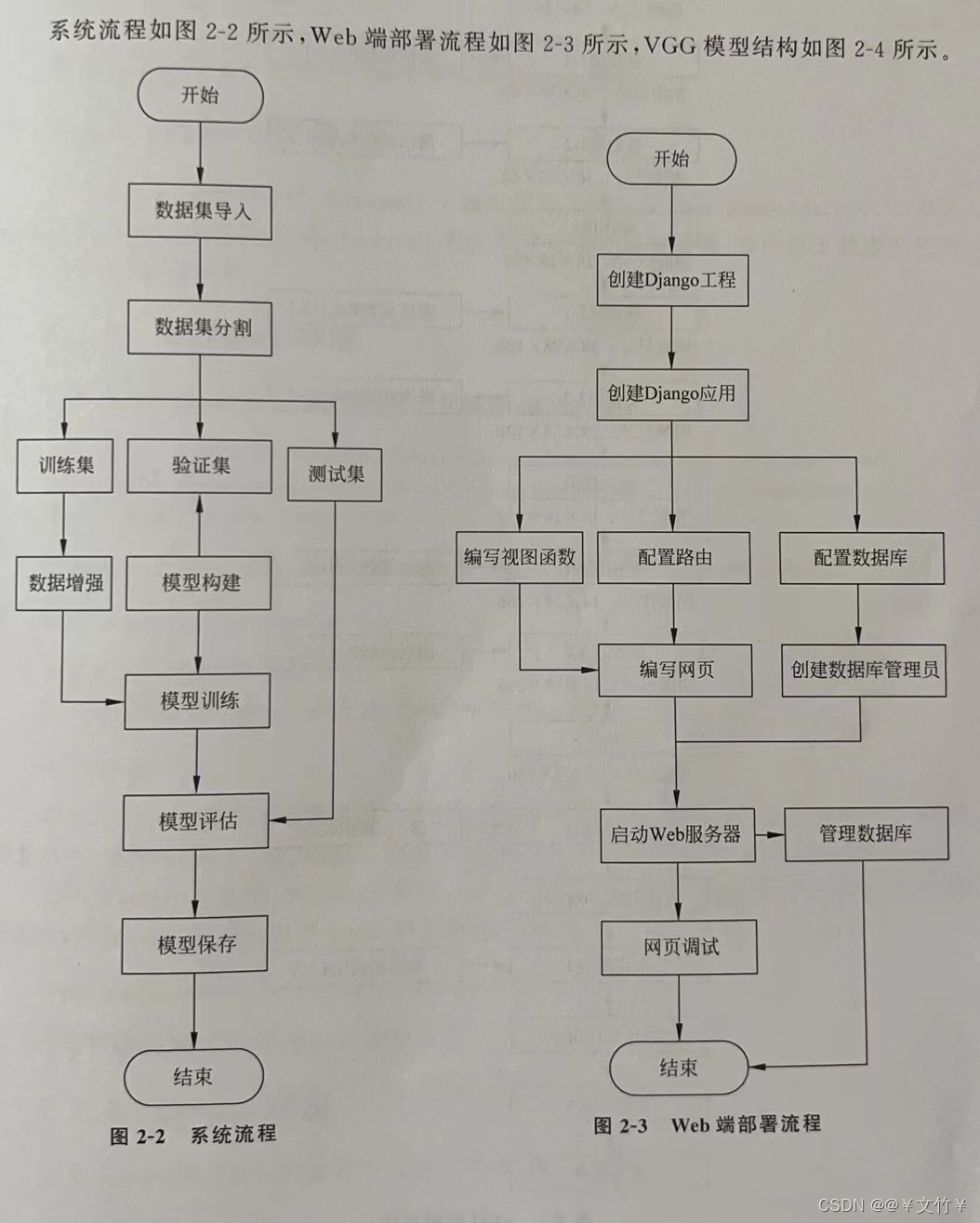
三、项目内容
3.1 获取数据集
记得直接在打开fashion-classify的目录,否则后面会报错
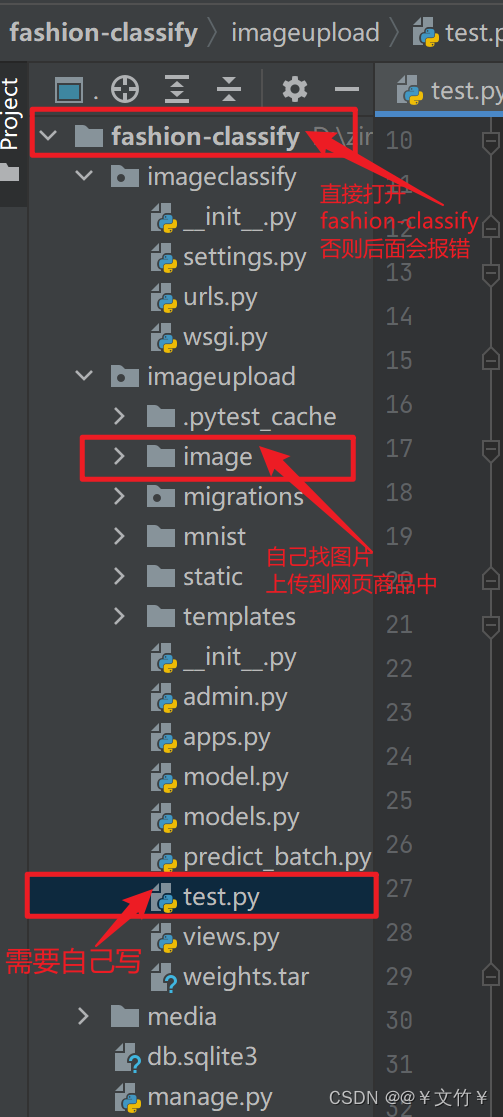
下面是数据集,有需要的自取就行 (若无法自取,留言我分享):
https://download.csdn.net/download/Q20011102/88053076
注意:
- 新建的test.py文件要导入predict_batch.py文件中的get_results函数,或者你直接在predict_batch.py的页面直接接着写,直接接着写的情况下
要进行测试就必须先注释你自己写的才能够进行网页测试,否则会报错,且你建立test.py文件必须和predict_batch.py文件是同一等级的目录,否则导入函数报红

- 上传的商品图片支持格式为
jpg、jpeg、png、bmp的图片
其中的test.py文件是我自己写的代码,你可以不用创建这个文件直接接着在predict_batch.py后面直接写入代码,test.py文件中的代码实现的目标是:
遍历每一张图片并比较真实标签和预测标签是否相等,相等则代表上传网页中图分类是正确的,不相等则表示分类不正确(简单来说就是你上传的是一个包但是网页分类到了鞋子,那就代表分类不正确)现在需要输出分类正确和分类不正确的概率
3.2 安装环境
本部分包括Python环境,PyTorch环境和Django环境
Python环境:
在Windows 系统中下载Anaconda,下载地址为:https://www.anaconda.com/。本项目采用Python 3.6版本(但是我采用的是3.9的版本,依个人需求就行),完成Anaconda的安装并配置好环境变量,也可以下载虚拟 Linux环境下运行代码
PyTorch环境:
打开Anaconda Prompt,添加清华仓库镜像,输入命令:
conda config--add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config--add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config-set show_channel_urls yes
创建新的 Python 环境,名称为PyTorch,Python版本号要对应,输人命令:
conda create -n pytorch python=3.6
有需要确认的地方,都输人y。
在Anaconda Prompt 中激活 PyTorch环境,输入命令:
activate pytorch
在PyTorch官网查看可供选择PyTorch版本、系统版本、安装方式以及编程语言,下载命令,还可选择CUDA加速,下载地址为:https://pytorch.org/get-started/locally
选用 Stable 1.4版本、Windows系统conda安装包、Python语言以及CUDA 10.1版本的PyTorch,在Anaconda Prompt 中安装,输入命令:
conda install pytorch torchvision cudatoolkit=10.1
有需要确认的地方,都输人y,安装完成(以上部分都是在终端安装的)
注意:这一部分安装我没有亲自试过,所以要注意参考,因为我之前有安装过Anaconda有相应的环境,所以就直接到官网相应的页面:https://pytorch.org/get-started/previous-versions/下载了torch为torch 1.7.1+cpu版的就可以运行了(我用Pycharm的版本的环境为:python3.9的Anaconda环境)
Django环境:打开 Anaconda Prompt,激活PyTorch环境,输入命令:
activate pytorch
下载Django,输人命令:
conda install Django
有需要确认的地方,都输入y,安装完成后村检查是否成功安装了Django,输入命令
conda list
若有显示结果,则Django 成功安装。
3.3 运行model.py文件
相应的代码已经放在数据集压缩包中了,如果数据集获取到了,环境都安装好了,再根据我分享的数据集运行里面的model.py 文件
路径:fashion-classify -> imageupload -> model.py
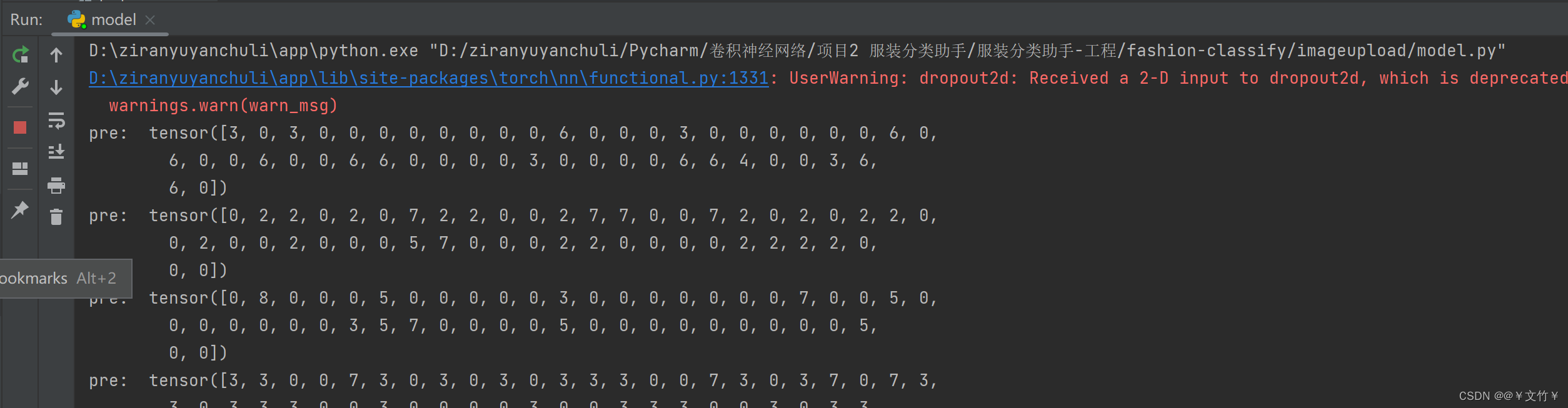
出现如下图所示的数据,表示环境都搭建成功,如果报错或者没有结果表示安装的环境有问题
注意:环境最好都搭配成一套,比如你在终端安装使用的是哪一个环境,你的运行环境必须和你终端中安装的那个环境是同一个环境否者很容易显示没有安装或者报错
(简单来说我在有Pycharm的工具,Python和Anaconda前提下,我就在Pycharm环境的终端中只安装了
1.7的torch和Django,然后运行model.py文件就出现下面的数据了,表示我的环境都安装成功了)
不用等一直运行完,只需要有下面数据出现就行,这只是一个测试作用,检查你的环境是否搭建成功。不报错有数据就行了
3.4 模型应用
本部分包括启动Web服务器、应用使用说明、测试结果示例、计算上传商品的正确率和错误率
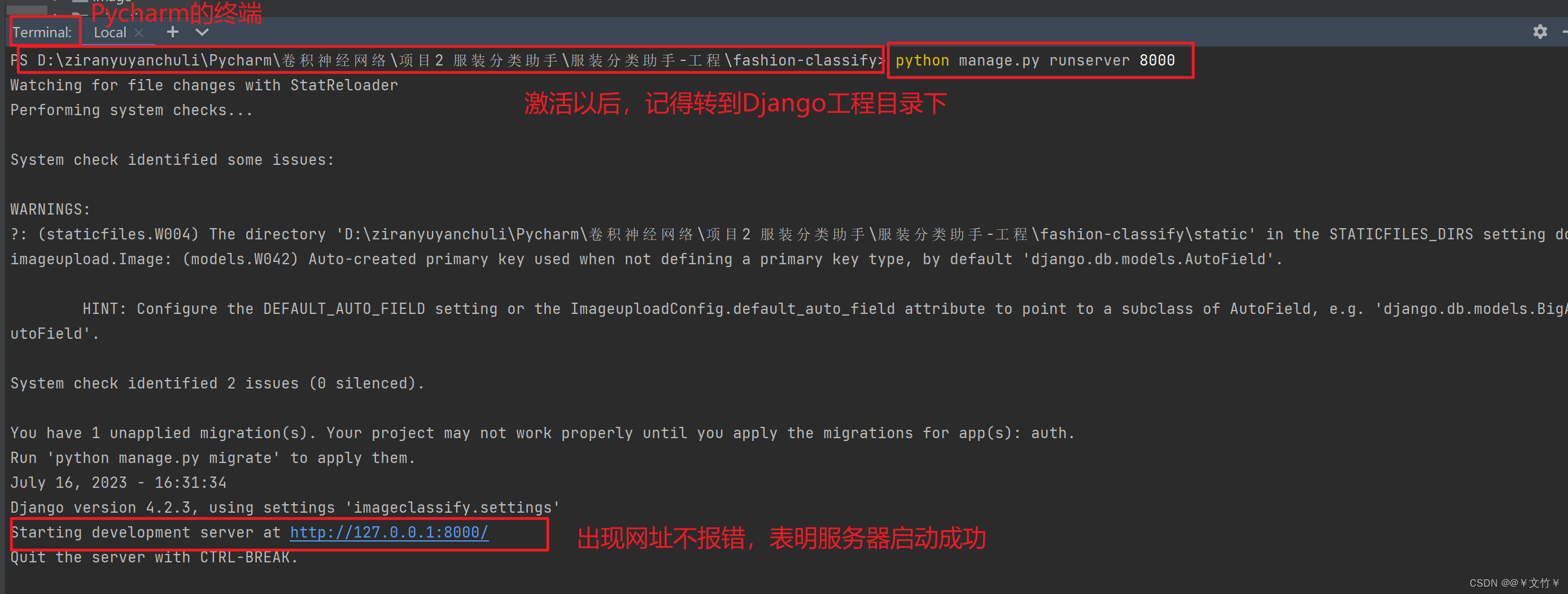
3.4.1 启动Web服务器
我是在Pycharm终端中激活环境,然后输入命令
或者你之前就在Anaconda Prompt中安装的torch和Django,那你就在Anaconda Prompt启用PyTorch环境,输入命令:
activate pytorch
转到Django工程目录下,运行代码,输入命令:
python manage.py runserver 8000
服务器启动成功则会出现如下图所示:
在浏览器中访问:http://127.0.0.1:8000+页面 URL,即可使用本应用
提示:要加页面URL才可以实现网页显示不然会报错
这里举例两个网址,可以用于网页跳转:
http://127.0.0.1:8000/index/create
http://127.0.0.1:8000/index
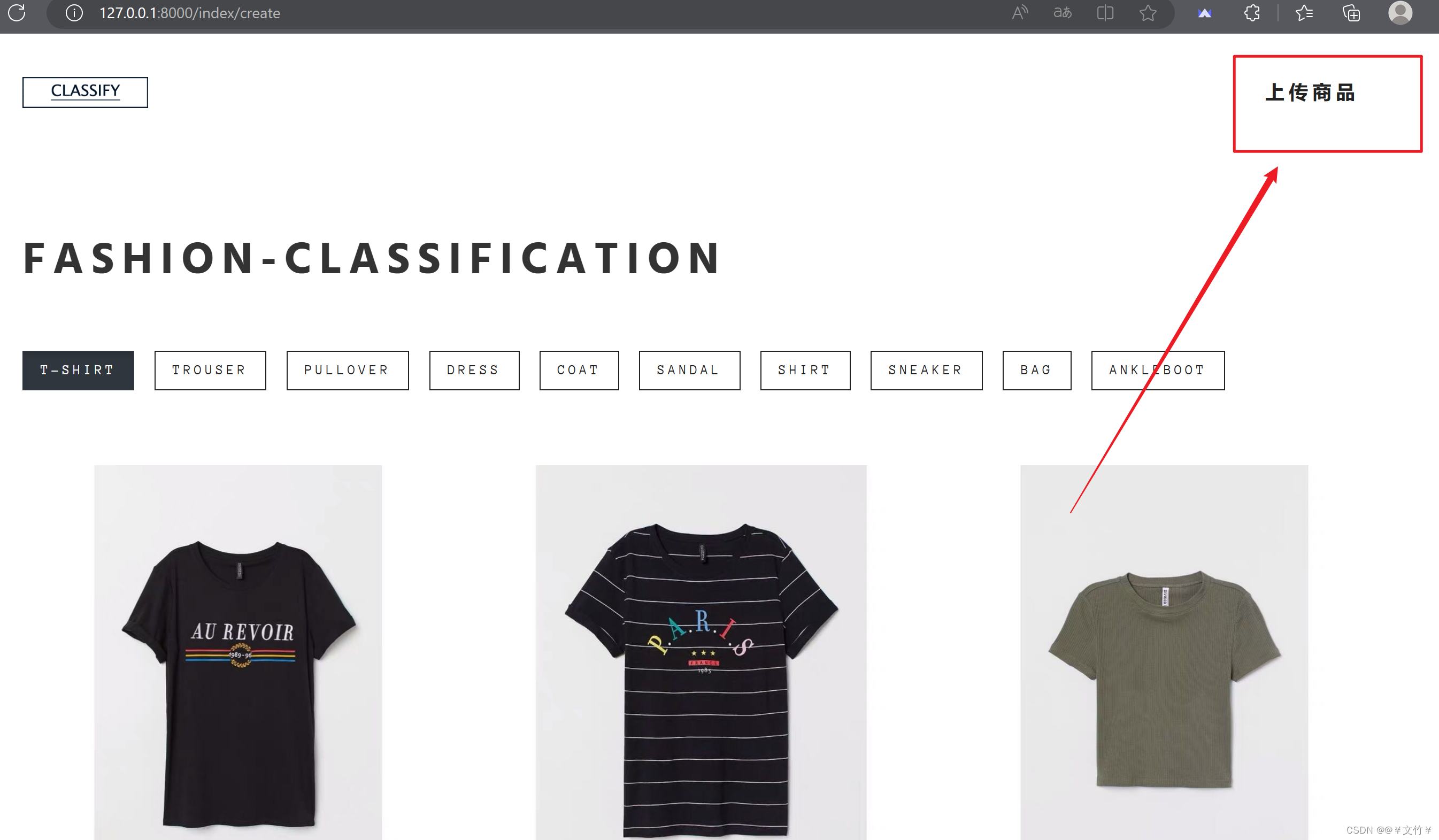
3.4.2 应用使用说明
在浏览器中访问http://127.0.0.1:8000/index/create,进入首页。左上角为网页图标,单击可刷新页面;右上方有“上传商品”按钮单击进人上传页面。首页默认显示T-shirt类标下上传并分类过的图片,另有9个标签可供选择,单击可查看不同标签的商品图片,当鼠标在页面移动时,停留处的商品图片会放大显示,下拉页面时,右下角出现向上箭头的按钮,单击可回到顶部,单击“上传商品”按钮进人上传图片页面
如下图:
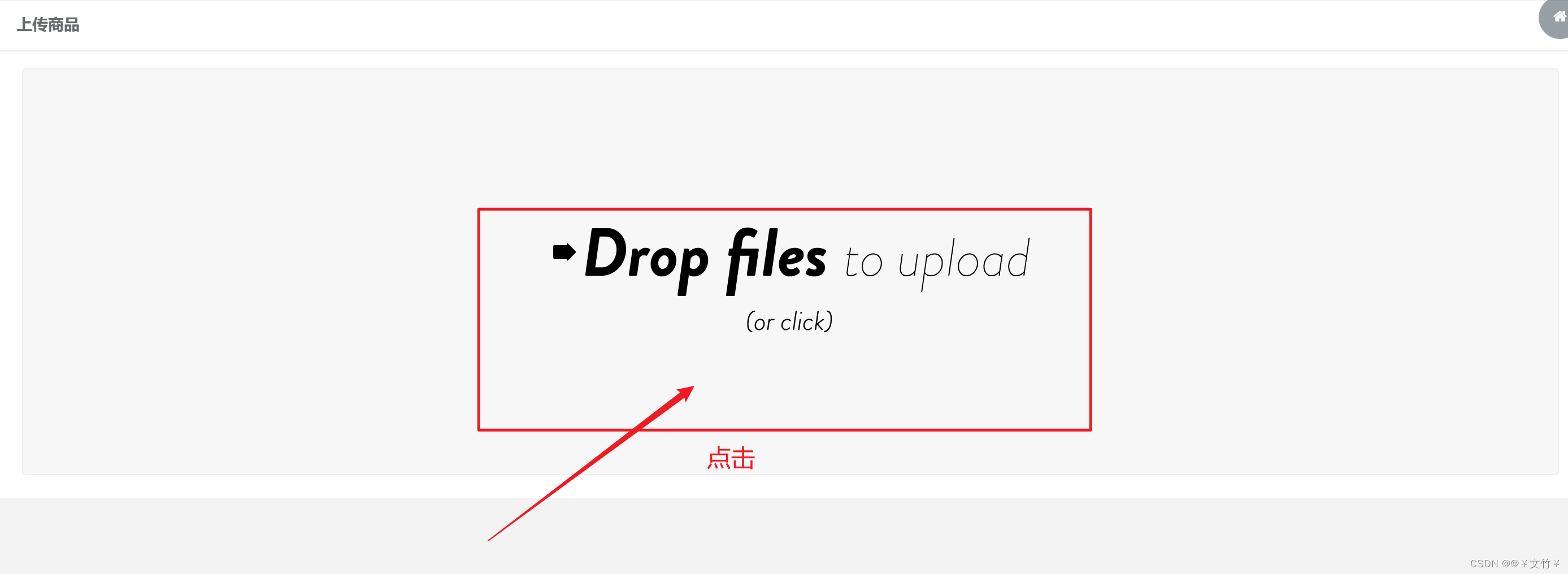
页面支持单击和拖拽两种方式上传图片,支持格式为jpg、jpeg、png、bmp的图片,上传完成后在本页面显示缩略图片、图片大小以及上传成功标志(显示为绿色对钩),可以同时上传单张或者多张图片,每次最多可上传10张图片,超出10张则会在第11张图片上显示“You can not upload any more files”,上传页面右上方图标在鼠标停留时显示“返回日商品页”,单击即可回到首页
如上传的图片格式不符合要求,则缩略图片位置显示为灰色,显示文件大小、文件名称以及上传失败标志(显示为红色叉号),鼠标停留在对应图片上时提示“You can’t uploac files of this type”。
3.4.3 测试结果示例
测试时我选择上传14张不同种类的商品图片,分别为包、裤子,套头衣服和连衣裙,返回首页,单击进入对应的标签页,可以看到上传的14张图片已成功分类至相应的标签页面下,但是还是有很多本该分类到对应标签下的商品却分类错误,如下图所示,连衣裙分类在了包类标签中
3.4.4 计算上传商品的正确率和错误率
创建一个test.py文件写入如下代码,计算相应的正确率和错误率
代码思路:
1.导入相应的文件函数,或者你可以不创建直接在predict_batch后面接着写,但是这样的话你进行Web服务器启动的时候要将这些代码注释掉,否则会报错,所以我们这里是新建文件,引入predict_batch里面的get_results函数就行
2.分别用变量初始化分类正确的商品和分类错误的商品,将图片定义在一个列表中作为预测标签,将肉眼可见的你上传的图片商品是什么样子的,作为真实标签
3.用for循环遍历每一张图片商品,比较预测标签和肉眼可见的真实标签是否相等,相等就正确个数加1,否者错误个数加1
4.用正确个数除以上传商品总数,就可以计算并输出正确率和错误率了
5.校验:从商品网页中数一数有几个上传分类正确的商品,让它除以上传商品总数,得出的结果看看是否和代码计算出的正确率是否一致,(同理错误率也这样比较,看你网页数出来的和你代码计算出来的是否一致)一致则代表代码实现成功,项目完成!
下面是test.py文件代码:
from predict_batch import get_results
# 计算14张图片的准确率
# 进行比较输出正确率和错误率
a = 0
b = 0
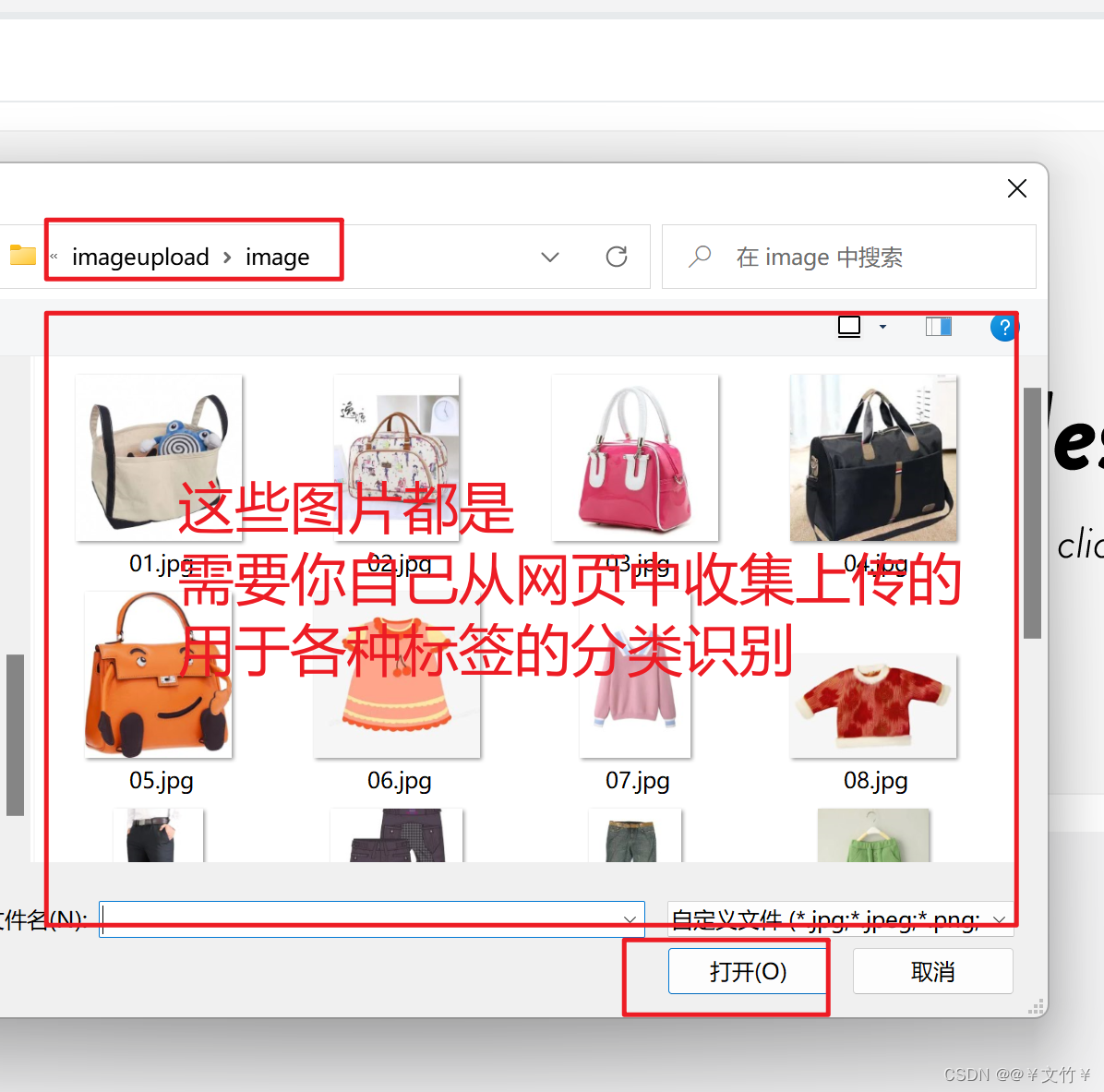
# 图片列表
image_list = ['./image/01.jpg', './image/02.jpg', './image/03.jpg', './image/04.jpg', './image/05.jpg',
'./image/06.jpg', './image/07.jpg', './image/08.jpg', './image/09.jpg', './image/10.jpg',
'./image/11.jpg', './image/12.jpg', './image/13.jpg', './image/14.jpg']
real_labels = ['Bag', 'Bag', 'Bag', 'Bag', 'Bag',
'Dress', 'Pullover', 'Pullover', 'Trouser', 'Trouser'
, 'Trouser', 'Trouser', 'Dress', 'Trouser']
# 使用for循环遍历image_list中的每一张图片,通过调用get_results函数获得预测标签class_label。
# 变量 i 代表当前元素的索引,变量 item 代表当前元素的值。
# image_list 是一个列表,enumerate(image_list) 会返回一个枚举对象。,第一个元素是索引(从0开始)第二个元素是对应索引位置的列表元素。
# 这两个元素可以通过 i 和 item 来命名,在循环体内可以使用它们来获取当前元素以及其索引
for i, item in enumerate(image_list):
# 预测标签
class_label = get_results(item)
# 比较真实标签和预测标签
if real_labels[i] == class_label:
a += 1
else:
b += 1
# 打印输出正确率
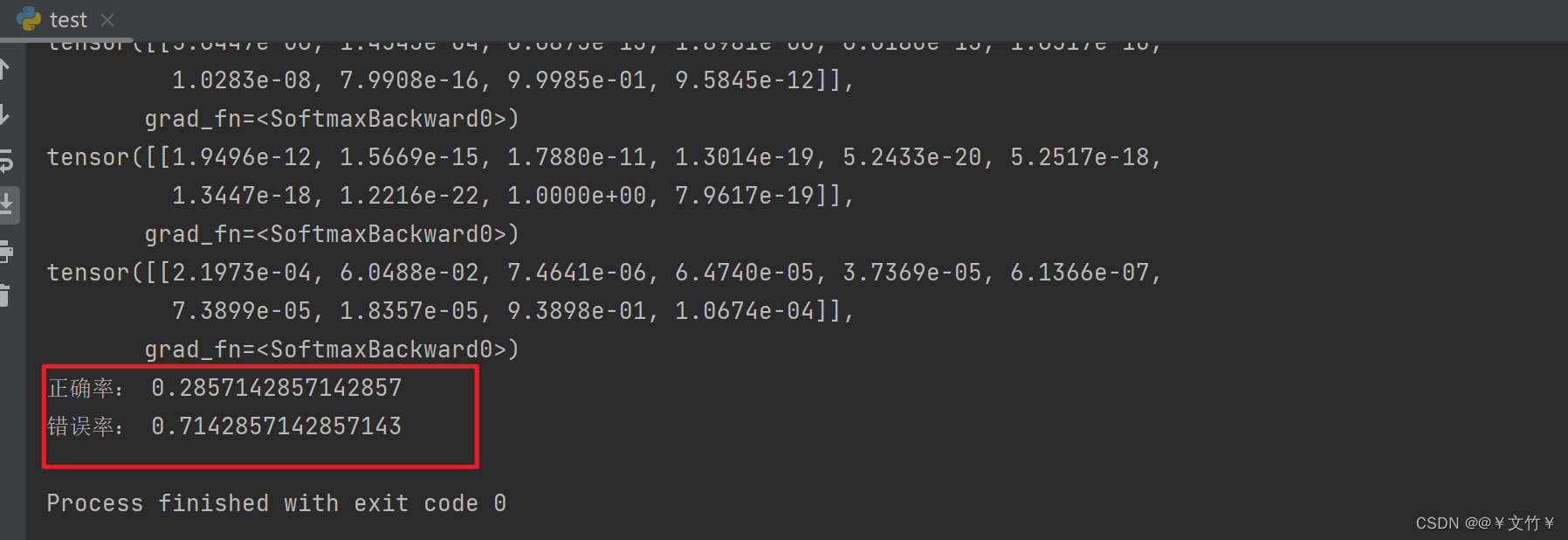
print("正确率:", a / len(image_list))
print("错误率:", b / len(image_list))
四、项目结果
五、项目bug
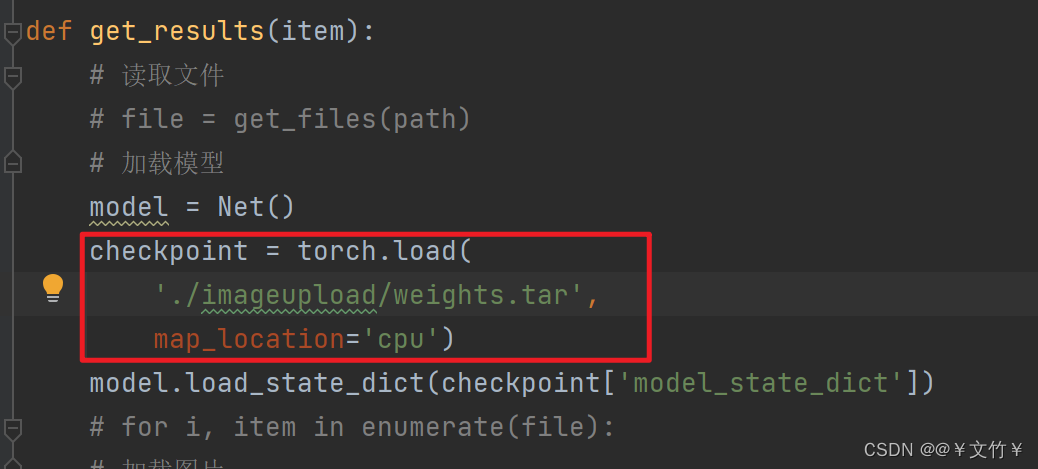
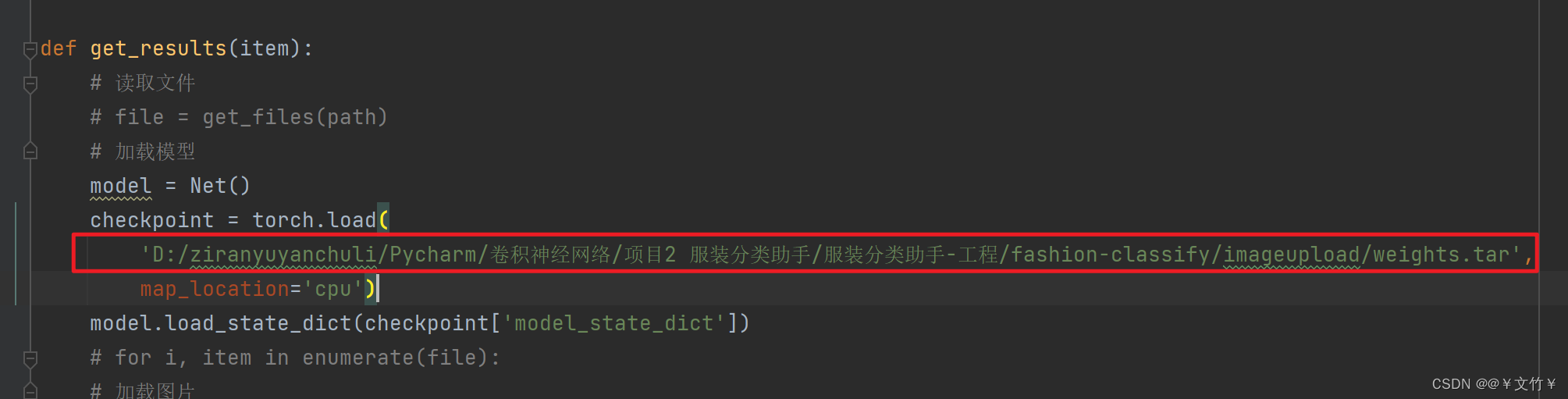
问题一(路径问题):
在predict_batch.py文件中的路径是商品上传的路径,需使用绝对路径不能使用下面的这种方式否则运行新建立的test文件会出现如下图所示的问题
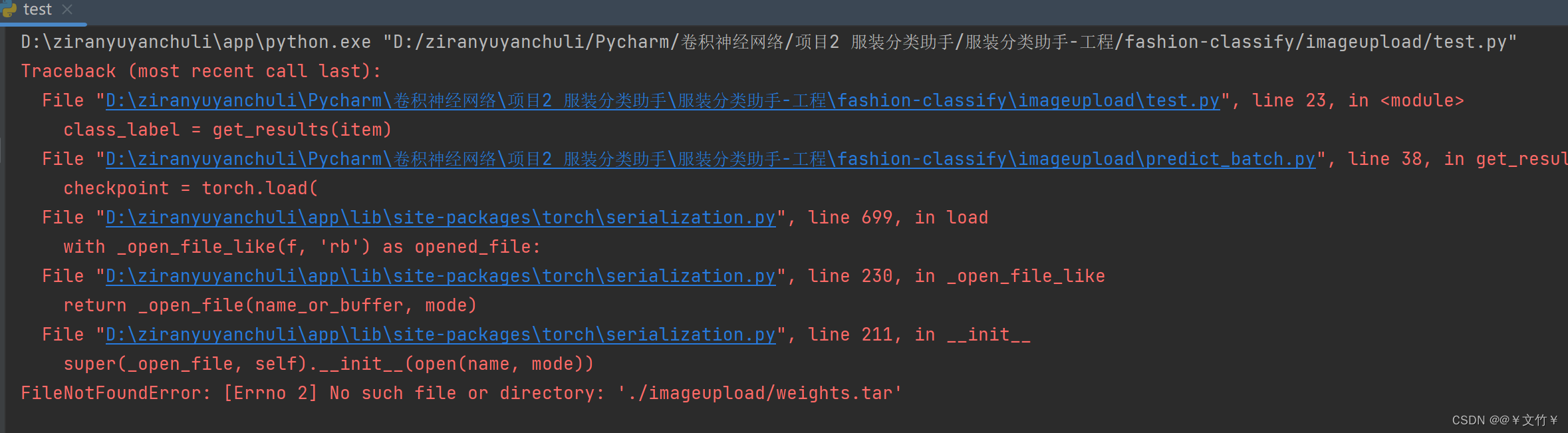
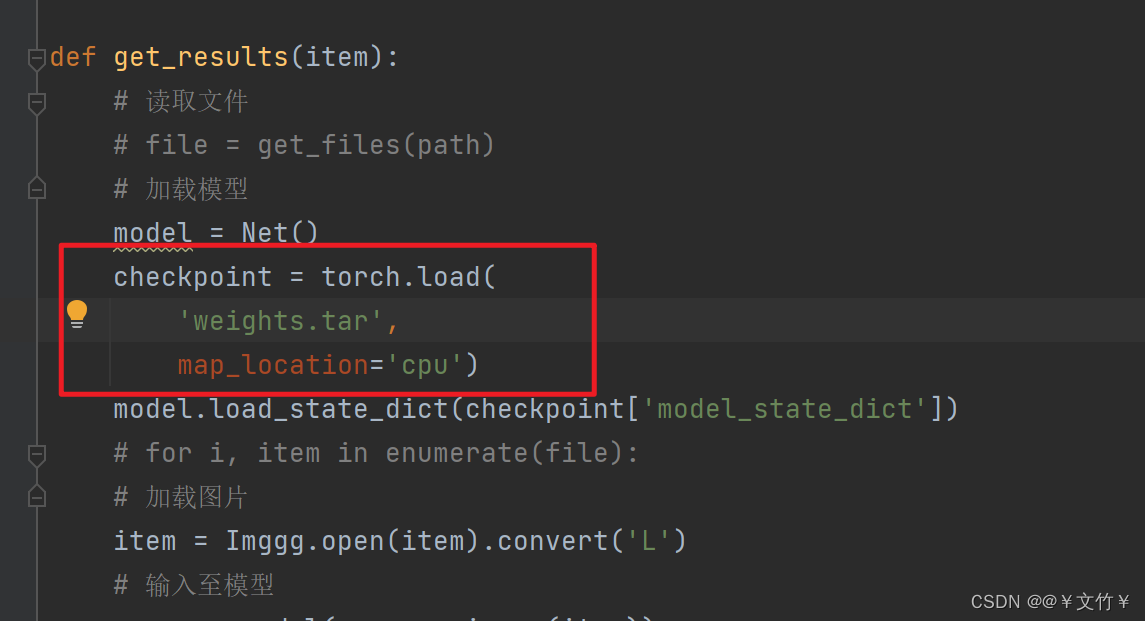
修正bug:
如图:将路径截断直接写,具体名字
或者写数据集的绝对路径
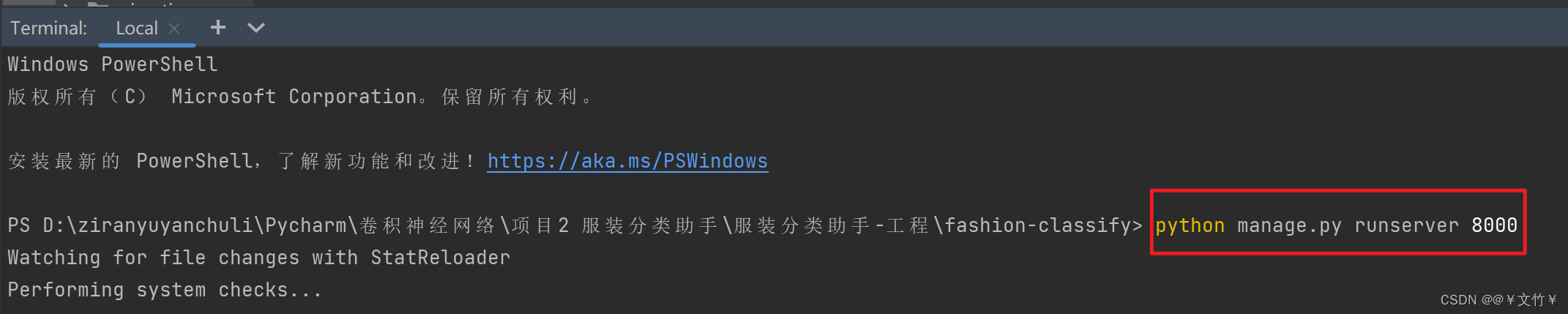
问题二(测试问题):
当你在终端中输入测试命令python manage.py runserver 8000时

会出现如下url的问题,那是因为你在导入url包时出现的问题


修正bug:
应将图片中的16行更改为from django.urls import re_path as url,并将原来错误的16行注释掉

再次验证在终端输入命令 python manage.py runserver 8000时出现这个网页的网址说明你的环境搭建和测试完成

问题三(测试问题):
predict_batch.py文件运行没问题,但是当你在终端中输入测试命令python manage.py runserver 8000时,出现如图所示问题,是因为你在predict_batch.py文件中添加了你自己写的代码

修正bug:
必须将你新写的代码注释掉才能进行终端命令测试python manage.py runserver 8000
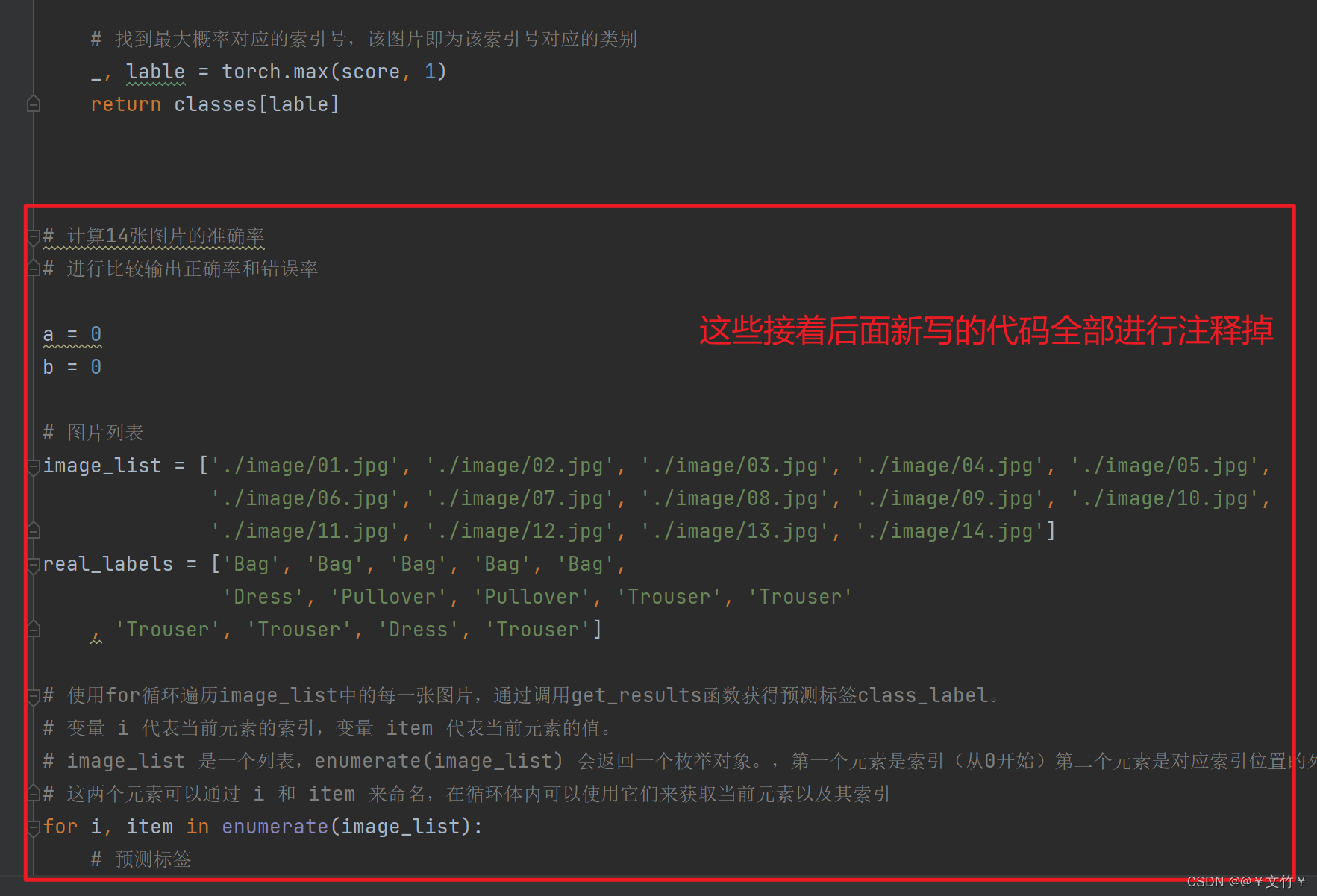
或者可以重新创建一个test.py文件,写入你的代码,实现实验目标
但要导入predict_batch.py文件中的get_results函数,否则运行test.py文件会报错,且你建立test.py文件必须和predict_batch.py文件是同一等级的目录,否则导入函数报红
再次验证在终端输入命令 python manage.py runserver 8000时出现这个网页的网址说明你的环境搭建和测试完成
问题四(网页进不去问题):
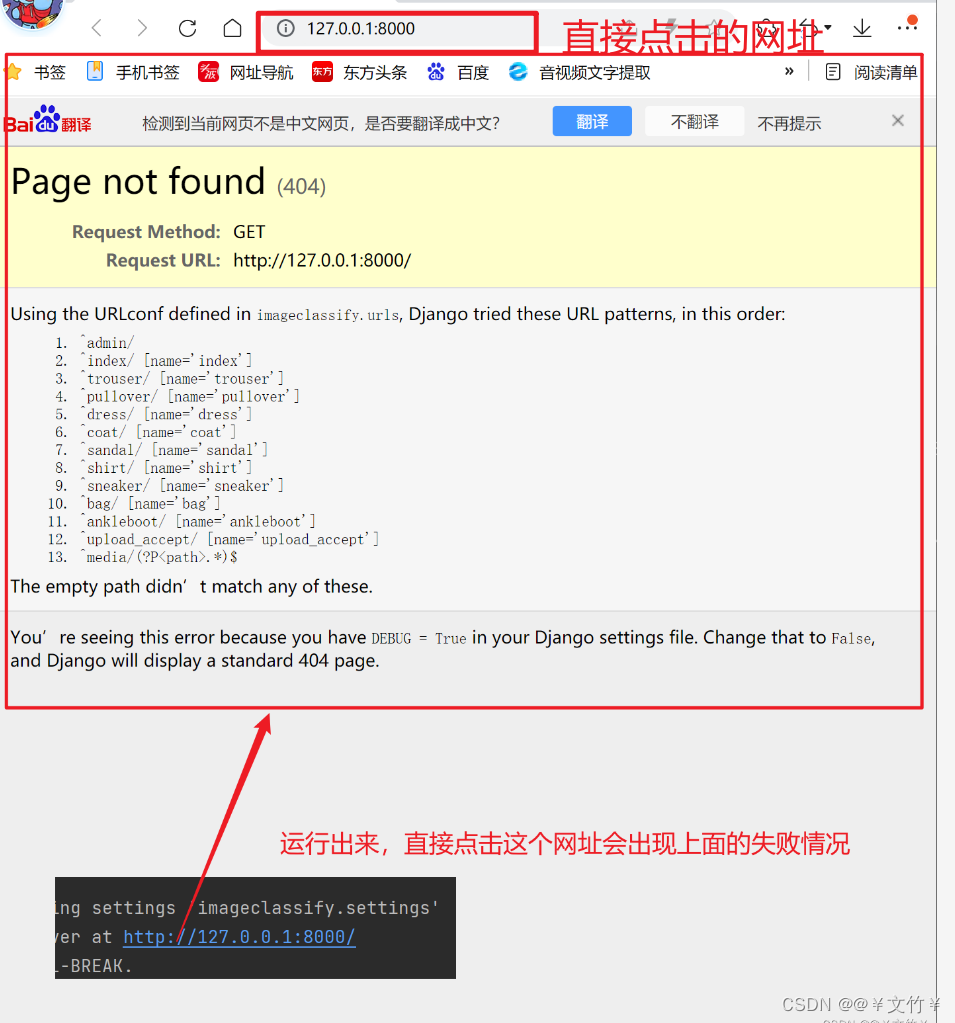
修正bug:
要将网址修改一下,直接在网址后面加上 index,如果还是进不去就再加上 /create,如下两个网址,进不去的话两个网址都可以试一下
http://127.0.0.1:8000/index/
或
http://127.0.0.1:8000/index/create
修改之后,进去网站之后就是如下图所示的样子啦
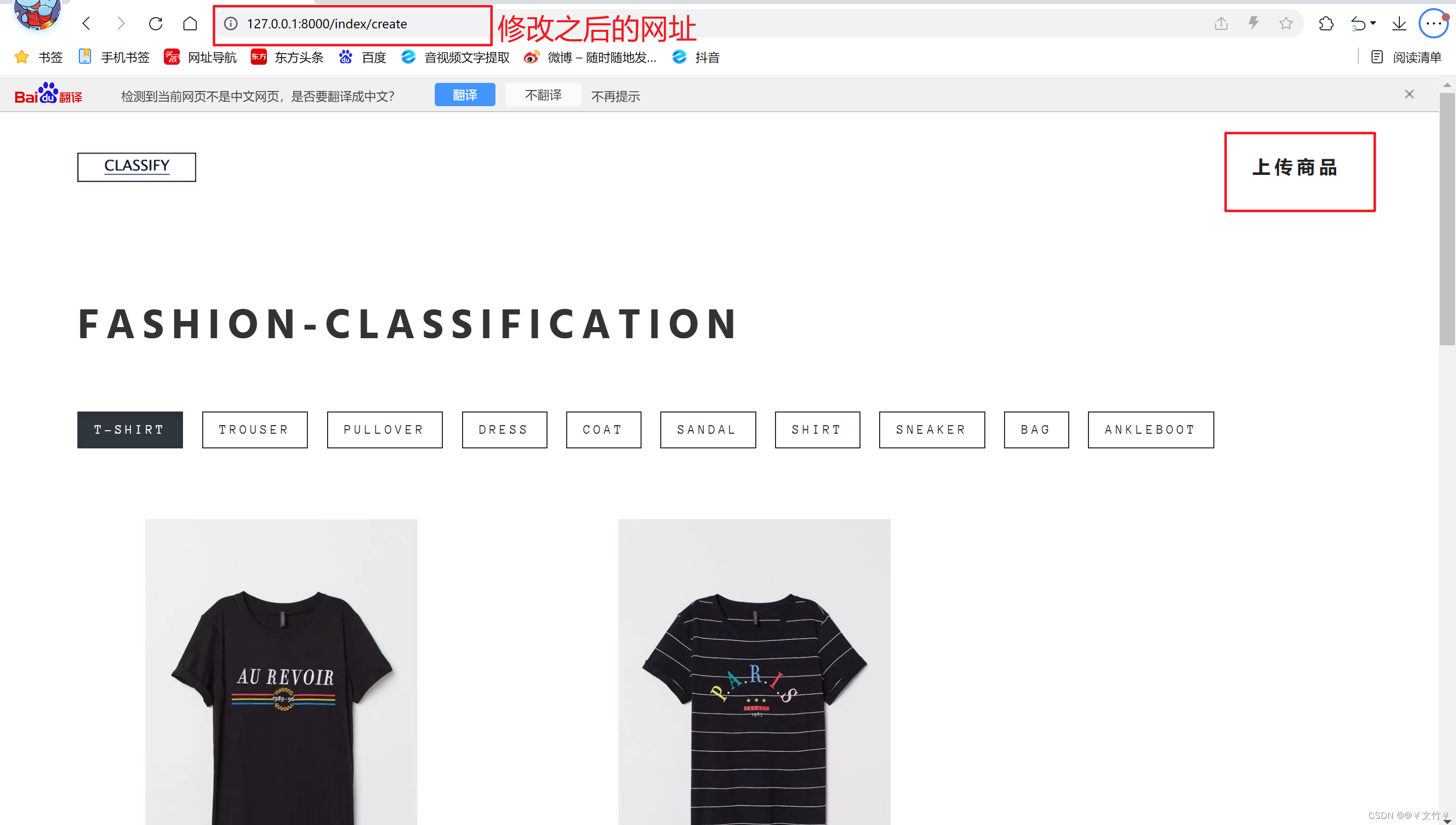
问题五(商品上传不上去问题):
在你的predict_batch.py文件中的路径是商品上传的路径,如果你之前写的都是绝对路径商品是可以上传成功的,如果之前写的地址是直接文件名的地址就会导致商品上传不成功,应该将其修正过来
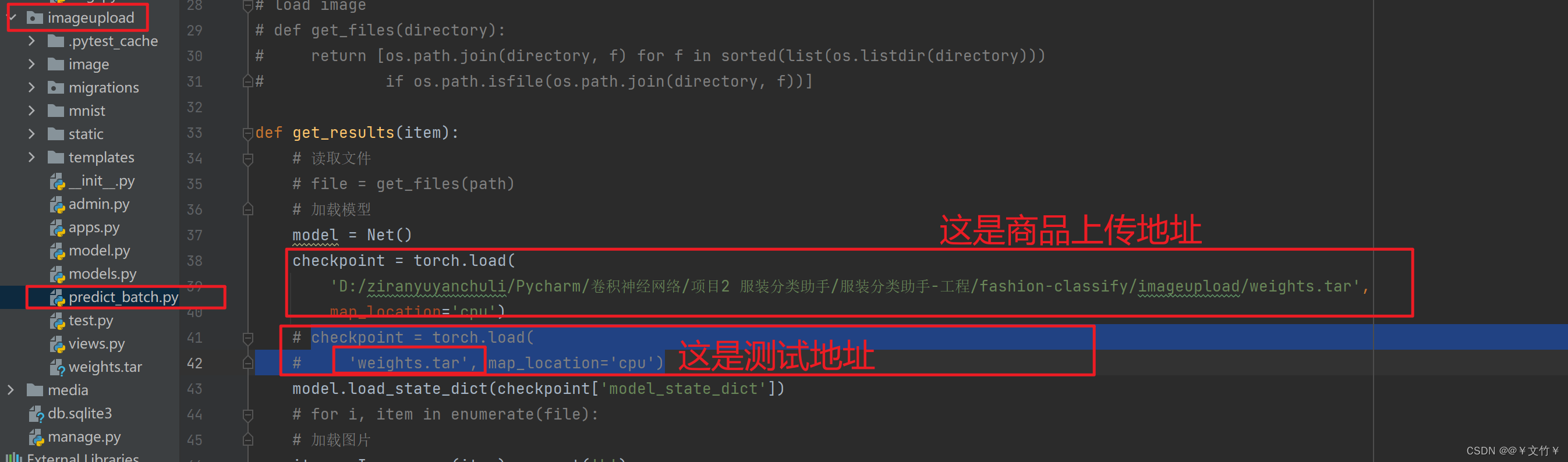
修正bug:
直接将地址修改为绝对地址就可以了(原先地址要注释掉)
修改之后商品就可以上传成功了
总结
以上就是应用机器学习模型采用卷积神经网络,部署在Web环境中,通过Fashion-MNIST数据集进行模型训练和改进,实现网页端服装类别精准识别的全部过程了,虽然会发现安装时会出现很多问题但是一个一个解决就可以实现最终目标,所以要坚持加油哦!!😁😁
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











