







 本文介绍了CLIP模型,它是文字图片的多模态工作,迁移效果好,能在多个视觉下游任务取得有监督学习效果。其方法包括预训练和Zero - Shot推理分类,采用对比学习,训练效率高。此外,CLIP还可用于图像检索、视频理解、图像编辑、图像生成和自监督学习等。
本文介绍了CLIP模型,它是文字图片的多模态工作,迁移效果好,能在多个视觉下游任务取得有监督学习效果。其方法包括预训练和Zero - Shot推理分类,采用对比学习,训练效率高。此外,CLIP还可用于图像检索、视频理解、图像编辑、图像生成和自监督学习等。
1 贡献
CLIP是文字图片的多模态工作
CLIP的迁移效果非常好。不同风格数据集的ZeroShot推理能力超强
在分类 ,物体检测和分割,视频检索都很多视觉下游任务都可以用CLIP取得有监督学习的效果
采用利用自然语音信号的监督信号来进行训练
提出了高质量的文本图片对数据集
2 方法
2.1 预训练
输入是文字和图片的一个配对
CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer VIT。
如下图
图片经过图片编码器编码Text Encoder得到图片特征
句子经过文字编码器编码Image Encoder得到文字特征
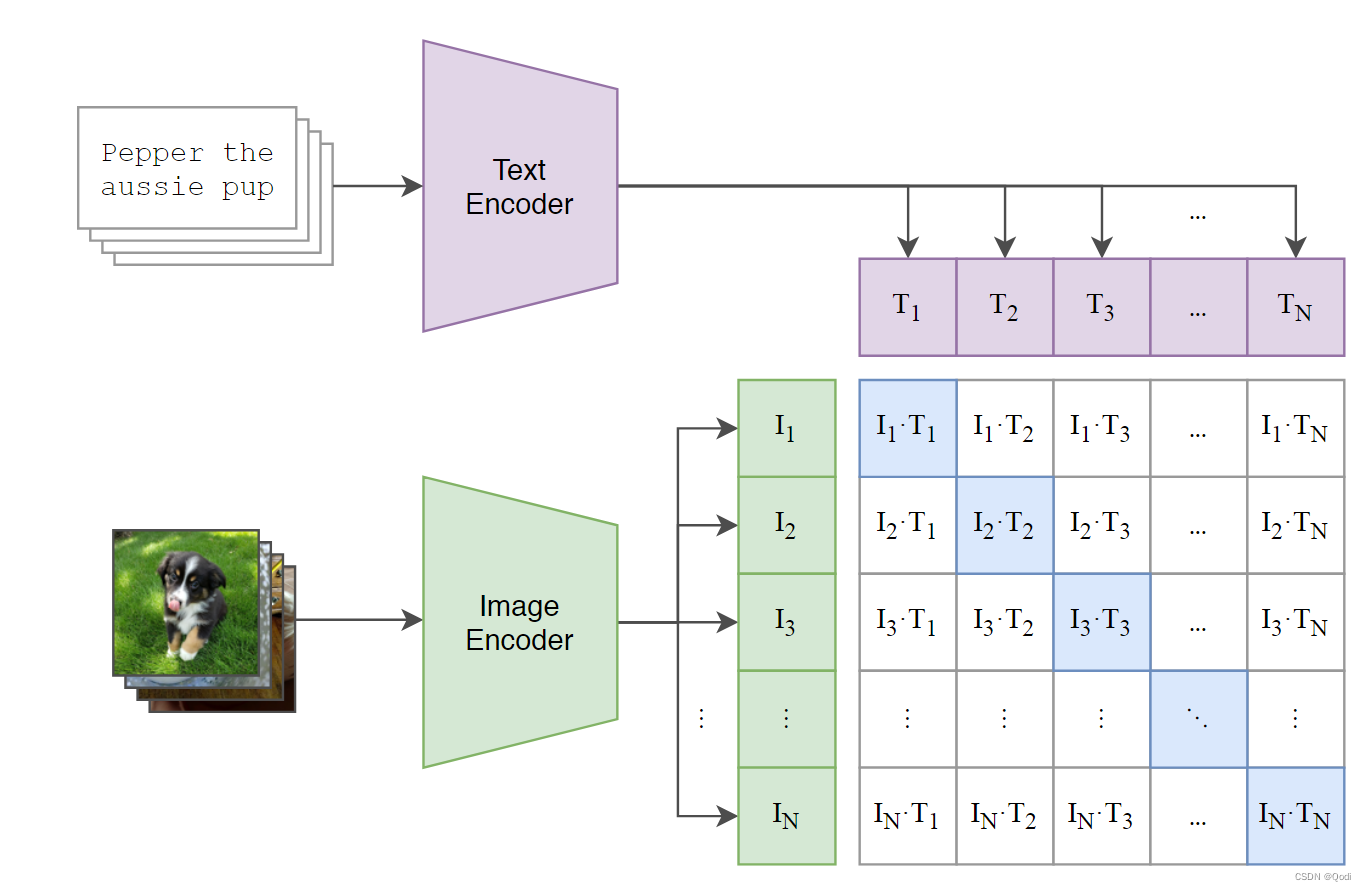
接下来要进行的就是配对任务了 所以作者爬了一个四个亿的数据集
这里用自然语言用来引导分类的好处:
(1)避免了大范围的标注工作,只需要下载图片和文字的配对即可,使得大规模数据集更容易获得
(2)标注是文本,而不是那种n选1的标签,模型的输入自由度就大了很多
(3)图片和文字绑定到一起,学习到了多模态的特征,容易Zeroshot迁移
正样本 负样本定义?
这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N^2−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N^2−N个负样本的相似度,对应的伪代码实现如下所示:

对比学习的高效性,比gpt的预训练的方式更高效
把预测性的目标函数(gpt)换成了对比性的目标函数,训练效率提高了4倍,
怎么去做推理?没有分类头
算相似度的方式,算有哪些物体
2.2 做Zero-Shot推理分类
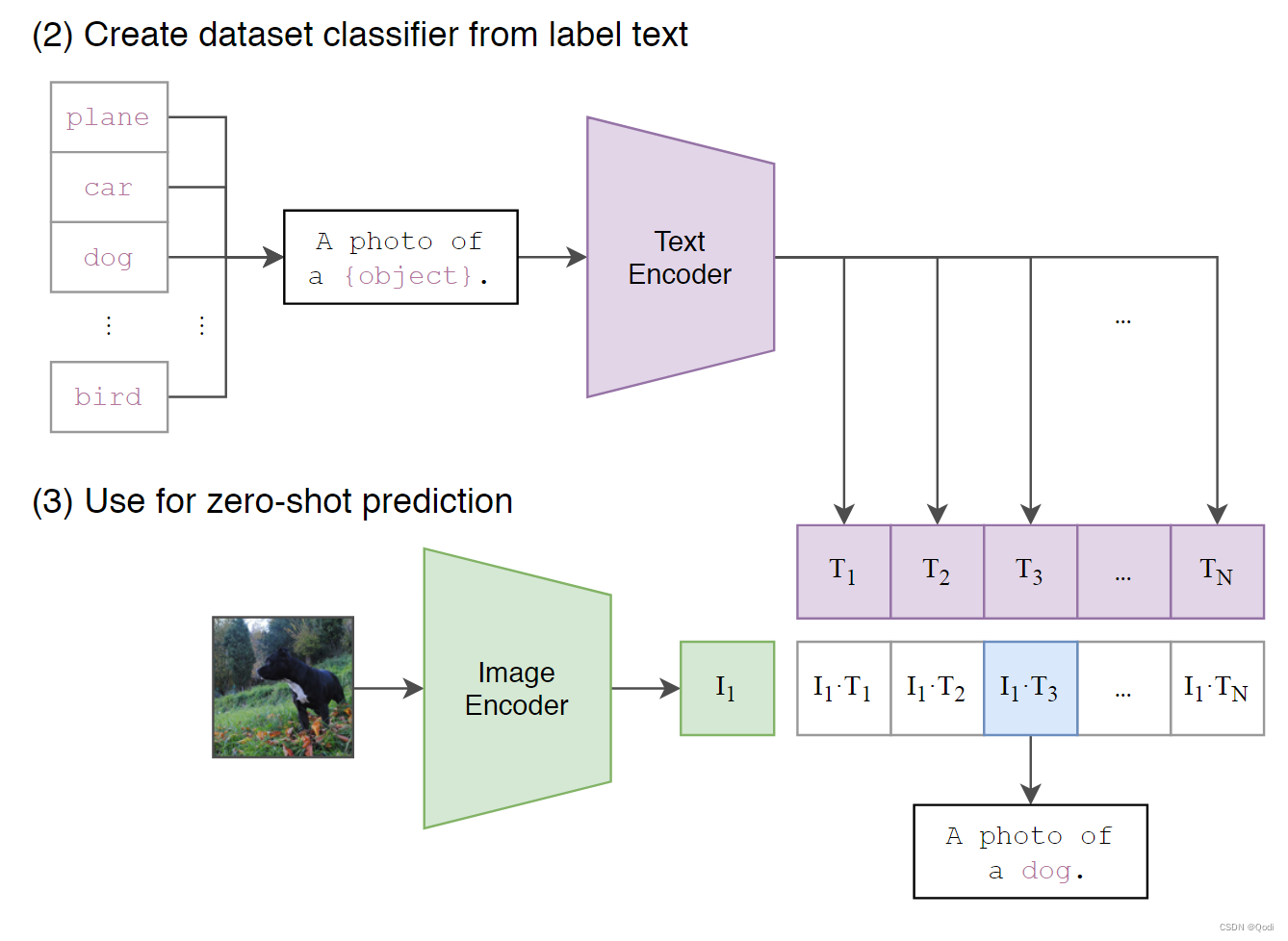
推理很简单,两步
(1)根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征。
因为预训练时候是句子(而且同时由于文本多义性),所以推理的时候,将单词改为句子A photo of {物体}
(2)将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
3.CLIP还可以做什么
图像检索
基于文本来搜索图像是CLIP最能直接实现的一个应用,其实CLIP也是作为DALL-E的排序模型,即从生成的图像中选择和文本相关性较高的。
视频理解
CLIP是基于文本-图像对来做的,但是它可以扩展到文本-视频,比如VideoCLIP就是将CLIP应用在视频领域来实现一些zero-shot视频理解任务。
图像编辑
CLIP可以用在指导图像编辑任务上,HairCLIP这篇工作用CLIP来定制化修改发型:
图像生成
CLIP还可以应用在图像生成上,比如StyleCLIP这篇工作用CLIP实现了文本引导的StyleGAN:
自监督学习
最近华为的工作MVP更是采用CLIP来进行视觉自监督训练:

















 2594
2594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









