




 本文详细介绍了在深度学习中如何进行迁移学习,特别是如何冻结网络层以节省计算资源。通过实例展示了在Tensorflow/Keras环境下,利用LSTM构建的网络模型,如何通过迭代或指定层名来实现网络层的冻结。这在微调预训练模型时非常关键,以防止底层特征学习的破坏。
本文详细介绍了在深度学习中如何进行迁移学习,特别是如何冻结网络层以节省计算资源。通过实例展示了在Tensorflow/Keras环境下,利用LSTM构建的网络模型,如何通过迭代或指定层名来实现网络层的冻结。这在微调预训练模型时非常关键,以防止底层特征学习的破坏。
迁移学习之网络层冻结
一、意义和目的
在得到训练好的模型后,常采用迁移学习将模型应用到其他任务中,迁移学习的步骤为:在初次训练的基础上对额外的新数据再训练,微调网络参数。迁移学习的这种方式可以不从头训练网络 ,节约大量的计算资源和时间开销。在用新数据对模型进行微调的过程中,往往需要冻结大多数的网络层。如何冻结网络层是本文要解决的问题。
总而言之,迁移学习的步骤就是:
①训练模型
②冻结模型部分层(一般指除全连接层外的所有层)←(本章内容)
——————————————————————————————
③在冻结的层后增加或替换层
④使用新数据重新训练,这时候学习率要很小(俗称微调fine-turning)
二、本文实现工具
本章着重讲下如何实现冻结网络层,后续操作都建立在训练获得某个网络的前提下进行(即①中部分已实现),实现工具和示例网络如下。
| 算法实现语言 | Python |
|---|---|
| 神经网络框架 | Tensorflow/Keras |
| 所用网络 | LSTM |
PS:Keras是Tensorflow2.0以上版本的高阶API。
三、冻结网络的代码实现
3.1 导入包
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import *
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import Model
import pickle, random
3.2 构建网络(2层2LSTM)
num_classes = 10
input=Input(shape=(32, 32))
layer1 = LSTM(32, return_sequences=True)(input)
layer2 = LSTM(32, return_sequences=True)(layer1)
x = Flatten()(layer2)
layer_dense1 = Dense(num_classes, name="dense1")(x)
layer_softmax = Activation('softmax')(layer_dense1)
output = Reshape([num_classes])(layer_softmax)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'],experimental_run_tf_function=False)
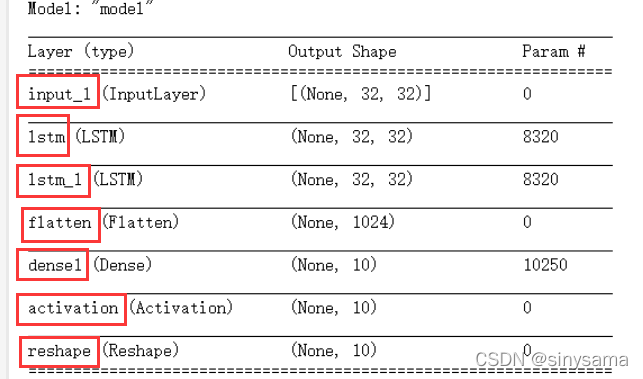
model.summary()
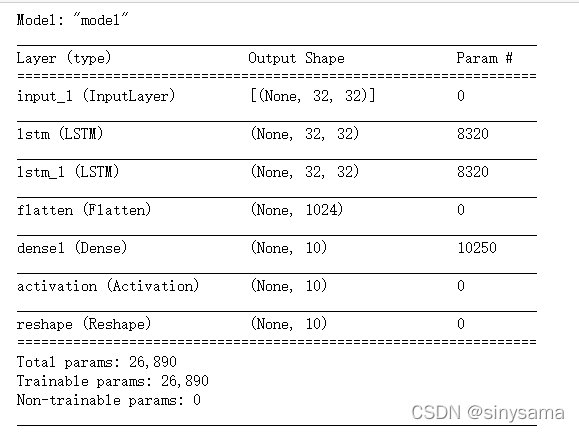
3.3 冻结网络层
假设前面构建好的网络已经训练好了(训练与否并不影响,因为只是模型权重参数不同而已,操作都一样,实际应用的时候记得训练即可)
在冻结前,可以看到所有层都是可训练。
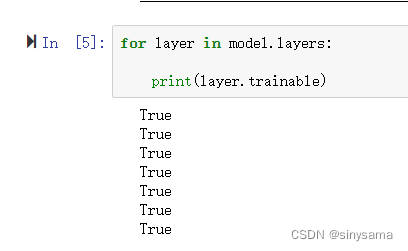
3.3.1 方式一:迭代冻结层
for layer in model.layers:
# model.get_layer('lstm').trainable= False
model.trainable = False
print(layer.trainable)
trainable表示可训练的层,冻结后
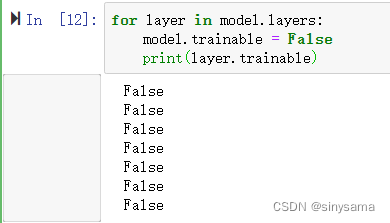
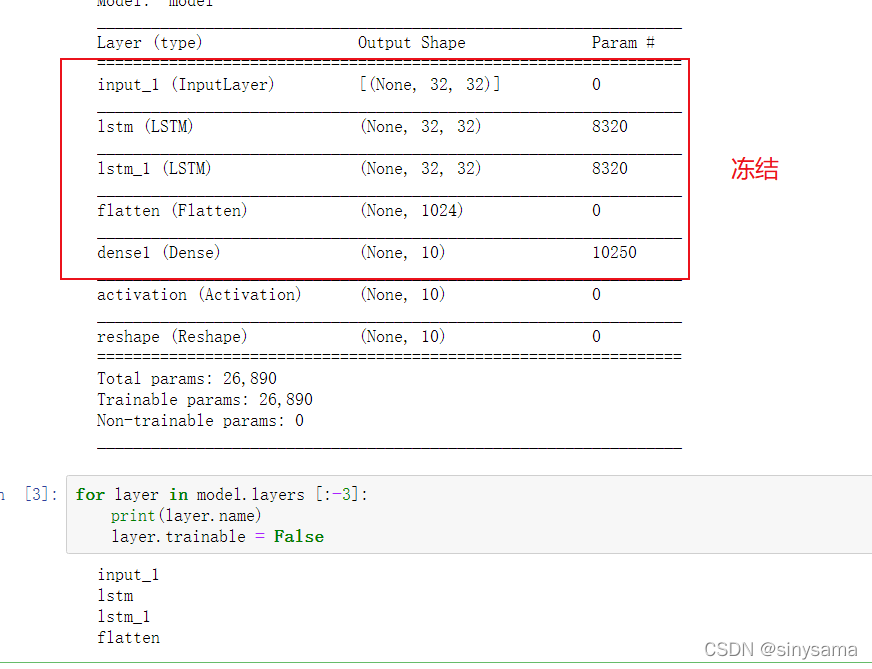
一般来说,迁移学习中会选择冻结除全连接层之前的所有层(如下图圈中部分)。对于本文的2层LSTM模型结构,冻结方式如下
for layer in model.layers [:-3]:
print(layer.name)
layer.trainable = False
3.3.2 方式二:冻结指定层(扩展内容)
这个方式看看就好,在层比较少的情况下可以使用。重点关注方式一
冻结指定层需要知道层的名称,以下生成的图例表格中第一列中可以知道(去括号)
如果要冻结lstm_1所在层,只需输入lstm_1的名称:
model.get_layer('lstm_1').trainable= False



















 3021
3021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











